时序分析28 - 时序预测 格兰杰因果关系(中) python实践1
时序分析28 - 时序预测 - 格兰杰因果关系(中)
Python 实践 1
上一篇文章我们介绍了格兰杰因果关系的基本概念、背景以及相关统计检验法。本篇文章我们使用Python编程实践一下。
实践1:股票价格数据之间的格兰杰因果关系
问题:苹果公司今天的股价是否可以用来预测明天的特斯拉的股价? 数据:来自雅虎财经
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
读入数据¶
df_apple = pd.read_csv('AAPL.csv')
df_walmart = pd.read_csv('WMT.csv')
df_tesla = pd.read_csv('TSLA.csv')
df = pd.merge(df_apple[['Date', 'Adj Close']], df_walmart[['Date', 'Adj Close']], on='Date', how='right').rename(columns = {'Adj Close_x':'apple', 'Adj Close_y':'walmart'})
df = df.merge(df_tesla[['Date', 'Adj Close']], on='Date', how='right').rename(columns={'Adj Close':'tesla'})
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date').rename_axis('company', axis=1)
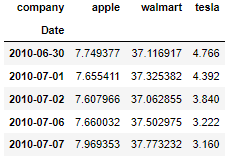
df.head()
可视化¶
df.plot(figsize=(16,8))

苹果和沃尔玛的股价趋势比较类似,而特斯拉在2020年增长了700%。
平稳性检测1:ADF Test
原假设:时序是不平稳的
备选假设:时序是平稳的
n_obs = 20
df_train, df_test = df[0:-n_obs], df[-n_obs:]
from statsmodels.tsa.stattools import adfuller
def adf_test(df):
result = adfuller(df.values)
print('ADF Statistics: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical values:')
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
print('ADF Test: Apple time series')
adf_test(df_train['apple'])
print('ADF Test: Walmart time series')
adf_test(df_train['walmart'])
print('ADF Test: Tesla time series')
adf_test(df_train['tesla'])

p值很大所以不能拒绝原假设,所以这三个时序都是不平稳的。
平稳性检验2:KPSS检验¶
原假设:时序是平稳的
备选假设:时序是非平稳的
from statsmodels.tsa.stattools import kpss
def kpss_test(df):
statistic, p_value, n_lags, critical_values = kpss(df.values)
print(f'KPSS Statistic: {statistic}')
print(f'p-value: {p_value}')
print(f'num lags: {n_lags}')
print('Critial Values:')
for key, value in critical_values.items():
print(f' {key} : {value}')
print('KPSS Test: Apple time series')
kpss_test(df_train['apple'])
print('KPSS Test: Walmart time series')
kpss_test(df_train['walmart'])
print('KPSS Test: Tesla time series')
kpss_test(df_train['tesla'])

这次p值都是小于0.05的,所以拒绝原假设,时序是不平稳的。
进行差分
import plotly.express as px
df_train_transformed = df_train.diff().dropna()
fig = px.line(df_train_transformed, facet_col="company", facet_col_wrap=1)
fig.update_yaxes(matches=None)
fig.show()

对差分后数据再次进行平稳性检验
print('ADF Test: Apple time series transformed')
adf_test(df_train_transformed['apple'])
print('ADF Test: Walmart time series transformed')
adf_test(df_train_transformed['walmart'])
print('ADF Test: Tesla time series transformed')
adf_test(df_train_transformed['tesla'])

ADF的结果告诉我们可以拒绝原假设,接受时序是平稳的这个结论。
print('KPSS Test: Apple time series transformed')
kpss_test(df_train_transformed['apple'])
print('KPSS Test: Walmart time series transformed')
kpss_test(df_train_transformed['walmart'])
print('KPSS Test: Tesla time series transformed')
kpss_test(df_train_transformed['tesla'])

KPSS检验的结果与ADF有些不同,它对Walmart的检验结果表明不能拒绝原假设,此时序仍然是非平稳的。
VAR 模型
我们先采用向量自回归模型(VAR,Vector AutoRegression),选择AIC最小的。
from statsmodels.tsa.api import VAR
model = VAR(df_train_transformed)
for i in [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]:
result = model.fit(i)
print('Lag Order =', i)
print('AIC : ', result.aic)
print('BIC : ', result.bic)
print('FPE : ', result.fpe)
print('HQIC: ', result.hqic, '\n')

…

results = model.fit(maxlags=15, ic='aic')
results.summary()
Summary of Regression Results
Model: VAR
Method: OLS
Date: Mon, 21, Mar, 2022
Time: 21:31:54
No. of Equations: 3.00000 BIC: 2.48026
Nobs: 2602.00 HQIC: 2.28193
Log likelihood: -13760.4 FPE: 8.75181
AIC: 2.16925 Det(Omega_mle): 8.30359
Results for equation apple
coefficient std. error t-stat prob
const 0.051964 0.016711 3.110 0.002
L1.apple -0.113389 0.022943 -4.942 0.000
L1.walmart -0.075488 0.017381 -4.343 0.000
L1.tesla 0.004845 0.004390 1.104 0.270
L2.apple -0.059288 0.023295 -2.545 0.011
L2.walmart -0.026432 0.017454 -1.514 0.130
L2.tesla 0.035496 0.004548 7.805 0.000
L3.apple -0.003051 0.023074 -0.132 0.895
L3.walmart -0.018981 0.017455 -1.087 0.277
L3.tesla 0.010515 0.004570 2.301 0.021
L4.apple 0.036423 0.023047 1.580 0.114
L4.walmart -0.064684 0.017453 -3.706 0.000
L4.tesla -0.001913 0.004607 -0.415 0.678
L5.apple 0.120294 0.023054 5.218 0.000
L5.walmart -0.032945 0.017523 -1.880 0.060
L5.tesla -0.022685 0.004599 -4.932 0.000
L6.apple -0.020840 0.023179 -0.899 0.369
L6.walmart 0.015391 0.017540 0.877 0.380
L6.tesla 0.000055 0.004675 0.012 0.991
L7.apple 0.091117 0.023229 3.923 0.000
L7.walmart 0.003089 0.017510 0.176 0.860
L7.tesla -0.005036 0.004670 -1.078 0.281
L8.apple -0.069914 0.023116 -3.024 0.002
L8.walmart -0.057101 0.017480 -3.267 0.001
L8.tesla 0.018022 0.004602 3.916 0.000
L9.apple 0.076160 0.023249 3.276 0.001
L9.walmart 0.018826 0.017526 1.074 0.283
L9.tesla -0.008462 0.004643 -1.822 0.068
L10.apple -0.070705 0.023322 -3.032 0.002
L10.walmart -0.039168 0.017570 -2.229 0.026
L10.tesla 0.019748 0.004621 4.273 0.000
L11.apple -0.095942 0.023370 -4.105 0.000
L11.walmart 0.002333 0.017561 0.133 0.894
L11.tesla 0.020593 0.004598 4.479 0.000
L12.apple 0.071664 0.023634 3.032 0.002
L12.walmart -0.025126 0.017564 -1.431 0.153
L12.tesla -0.013584 0.004647 -2.923 0.003
L13.apple 0.092046 0.023527 3.912 0.000
L13.walmart 0.005416 0.017561 0.308 0.758
L13.tesla -0.036568 0.004613 -7.927 0.000
L14.apple 0.094866 0.023734 3.997 0.000
L14.walmart -0.005898 0.017580 -0.335 0.737
L14.tesla -0.034932 0.004671 -7.478 0.000
L15.apple -0.046101 0.024021 -1.919 0.055
L15.walmart -0.005970 0.017522 -0.341 0.733
L15.tesla 0.003776 0.004729 0.799 0.425
Results for equation walmart
coefficient std. error t-stat prob
const 0.046477 0.020091 2.313 0.021
L1.apple -0.131216 0.027583 -4.757 0.000
L1.walmart -0.094210 0.020896 -4.508 0.000
L1.tesla 0.022162 0.005277 4.199 0.000
L2.apple 0.004741 0.028006 0.169 0.866
L2.walmart -0.032661 0.020984 -1.556 0.120
L2.tesla 0.007806 0.005467 1.428 0.153
L3.apple 0.017352 0.027741 0.625 0.532
L3.walmart -0.019084 0.020986 -0.909 0.363
L3.tesla 0.020965 0.005494 3.816 0.000
L4.apple -0.009350 0.027709 -0.337 0.736
L4.walmart -0.064853 0.020984 -3.091 0.002
L4.tesla 0.015744 0.005538 2.843 0.004
L5.apple 0.116771 0.027717 4.213 0.000
L5.walmart -0.041144 0.021067 -1.953 0.051
L5.tesla -0.008102 0.005529 -1.465 0.143
L6.apple 0.027990 0.027868 1.004 0.315
L6.walmart -0.030674 0.021088 -1.455 0.146
L6.tesla 0.003520 0.005621 0.626 0.531
L7.apple 0.095280 0.027927 3.412 0.001
L7.walmart 0.003876 0.021052 0.184 0.854
L7.tesla -0.012184 0.005614 -2.170 0.030
L8.apple -0.097662 0.027792 -3.514 0.000
L8.walmart -0.049246 0.021015 -2.343 0.019
L8.tesla 0.023160 0.005533 4.186 0.000
L9.apple 0.039667 0.027952 1.419 0.156
L9.walmart 0.048133 0.021071 2.284 0.022
L9.tesla 0.010389 0.005582 1.861 0.063
L10.apple -0.061275 0.028039 -2.185 0.029
L10.walmart 0.008151 0.021124 0.386 0.700
L10.tesla 0.004807 0.005556 0.865 0.387
L11.apple -0.043766 0.028097 -1.558 0.119
L11.walmart 0.047349 0.021112 2.243 0.025
L11.tesla 0.009937 0.005528 1.798 0.072
L12.apple 0.021889 0.028414 0.770 0.441
L12.walmart -0.034822 0.021116 -1.649 0.099
L12.tesla 0.007104 0.005587 1.271 0.204
L13.apple -0.012082 0.028286 -0.427 0.669
L13.walmart 0.011464 0.021114 0.543 0.587
L13.tesla -0.022868 0.005546 -4.123 0.000
L14.apple -0.047027 0.028534 -1.648 0.099
L14.walmart 0.008554 0.021136 0.405 0.686
L14.tesla -0.013390 0.005616 -2.384 0.017
L15.apple -0.040683 0.028880 -1.409 0.159
L15.walmart -0.019187 0.021066 -0.911 0.362
L15.tesla 0.002257 0.005686 0.397 0.691
Results for equation tesla
coefficient std. error t-stat prob
const 0.181504 0.082774 2.193 0.028
L1.apple -0.710340 0.113643 -6.251 0.000
L1.walmart -0.059560 0.086092 -0.692 0.489
L1.tesla 0.004835 0.021743 0.222 0.824
L2.apple -0.282365 0.115385 -2.447 0.014
L2.walmart -0.017891 0.086454 -0.207 0.836
L2.tesla 0.109113 0.022526 4.844 0.000
L3.apple 0.029439 0.114292 0.258 0.797
L3.walmart -0.030903 0.086462 -0.357 0.721
L3.tesla 0.129175 0.022636 5.707 0.000
L4.apple 0.207196 0.114161 1.815 0.070
L4.walmart -0.281576 0.086452 -3.257 0.001
L4.tesla -0.021823 0.022818 -0.956 0.339
L5.apple 0.530873 0.114193 4.649 0.000
L5.walmart -0.071527 0.086796 -0.824 0.410
L5.tesla -0.225666 0.022781 -9.906 0.000
L6.apple -0.336502 0.114814 -2.931 0.003
L6.walmart 0.166983 0.086882 1.922 0.055
L6.tesla -0.043649 0.023158 -1.885 0.059
L7.apple 0.432467 0.115061 3.759 0.000
L7.walmart -0.141216 0.086734 -1.628 0.103
L7.tesla -0.015612 0.023131 -0.675 0.500
L8.apple 0.462981 0.114502 4.043 0.000
L8.walmart 0.021005 0.086583 0.243 0.808
L8.tesla -0.062643 0.022796 -2.748 0.006
L9.apple 0.418652 0.115162 3.635 0.000
L9.walmart 0.276013 0.086811 3.179 0.001
L9.tesla -0.017033 0.022999 -0.741 0.459
L10.apple 0.034413 0.115520 0.298 0.766
L10.walmart -0.050803 0.087031 -0.584 0.559
L10.tesla 0.083882 0.022891 3.664 0.000
L11.apple -0.511340 0.115759 -4.417 0.000
L11.walmart 0.086088 0.086983 0.990 0.322
L11.tesla 0.143331 0.022774 6.294 0.000
L12.apple 0.333524 0.117064 2.849 0.004
L12.walmart 0.098182 0.086998 1.129 0.259
L12.tesla -0.047291 0.023019 -2.054 0.040
L13.apple 0.966669 0.116537 8.295 0.000
L13.walmart -0.203999 0.086987 -2.345 0.019
L13.tesla -0.072500 0.022851 -3.173 0.002
L14.apple 0.097180 0.117562 0.827 0.408
L14.walmart 0.026838 0.087079 0.308 0.758
L14.tesla -0.179990 0.023139 -7.779 0.000
L15.apple 0.267944 0.118983 2.252 0.024
L15.walmart -0.296672 0.086791 -3.418 0.001
L15.tesla -0.121926 0.023426 -5.205 0.000
Correlation matrix of residuals
apple walmart tesla
apple 1.000000 0.321701 0.431945
walmart 0.321701 1.000000 0.122985
tesla 0.431945 0.122985 1.000000
Apple & Tesla之间的相关性最大,值为 0.43
Durbin-Watson 检验
Durbin-Watson检验可以检查残差之间的自相关性。
from statsmodels.stats.stattools import durbin_watson
out = durbin_watson(results.resid)
for col, val in zip(df.columns, out):
print(col, ':', round(val, 2))
apple : 2.0
walmart : 2.0
tesla : 2.0
值为2表示没有检测出自相关性
格兰杰因果测试
from statsmodels.tsa.stattools import grangercausalitytests
maxlag=15
test = 'ssr_chi2test'
def grangers_causation_matrix(data, variables, test='ssr_chi2test', verbose=False):
df = pd.DataFrame(np.zeros((len(variables), len(variables))), columns=variables, index=variables)
for c in df.columns:
for r in df.index:
test_result = grangercausalitytests(data[[r, c]], maxlag=maxlag, verbose=False)
p_values = [round(test_result[i+1][0][test][1],4) for i in range(maxlag)]
if verbose: print(f'Y = {r}, X = {c}, P Values = {p_values}')
min_p_value = np.min(p_values)
df.loc[r, c] = min_p_value
df.columns = [var + '_x' for var in variables]
df.index = [var + '_y' for var in variables]
return df
grangers_causation_matrix(df_train_transformed, variables = df_train_transformed.columns)

上表中行y表示响应变量,x表示预测变量。每一个单元中的值表示p值;例如第一行第二列的p值为0 < 0.05,代表我们可以拒绝原假设,认为walmart_x对apple_y有格兰杰因果关系。上面的数据表明三个序列互为格兰杰因果关系。
预测
之前我们把数据进行了差分,现在我们需要将它转换回来。
lag_order = results.k_ar
df_input = df_train_transformed.values[-lag_order:]
df_forecast = results.forecast(y=df_input, steps=n_obs)
df_forecast = (pd.DataFrame(df_forecast, index=df_test.index, columns=df_test.columns + '_pred'))
def invert_transformation(df, pred):
forecast = df_forecast.copy()
columns = df.columns
for col in columns:
forecast[str(col)+'_pred'] = df[col].iloc[-1] + forecast[str(col)+'_pred'].cumsum()
return forecast
output = invert_transformation(df_train, df_forecast)
combined = pd.concat([output['apple_pred'], df_test['apple'], output['walmart_pred'], df_test['walmart'], output['tesla_pred'], df_test['tesla']], axis=1)
combined.head()

from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
rmse = mean_squared_error(combined['apple_pred'], combined['apple'])
mae = mean_absolute_error(combined['apple_pred'], combined['apple'])
print('Forecast accuracy of Apple')
print('RMSE: ', round(np.sqrt(rmse),2))
print('MAE: ', round(mae,2))
Forecast accuracy of Apple
RMSE: 7.31
MAE: 6.0
rmse = mean_squared_error(combined['walmart_pred'], combined['walmart'])
mae = mean_absolute_error(combined['walmart_pred'], combined['walmart'])
print('Forecast accuracy of Walmart')
print('RMSE: ', round(np.sqrt(rmse),2))
print('MAE: ', round(mae,2))
Forecast accuracy of Walmart
RMSE: 5.05
MAE: 4.52
rmse = mean_squared_error(combined['tesla_pred'], combined['tesla'])
mae = mean_absolute_error(combined['tesla_pred'], combined['tesla'])
print('Forecast accuracy of Tesla')
print('RMSE: ', round(np.sqrt(rmse),2))
print('MAE: ', round(mae,2))
Forecast accuracy of Tesla
RMSE: 125.16
MAE: 113.18