PyTorch项目实战---Unet实现道路裂纹缺陷检测
目录
1.数据集下载
2.数据准备
3.数据处理
4.Unet代码
5.训练代码
6.测试代码
1.数据集下载
下载地址:
https://github.com/cuilimeng/CrackForest-dataset
|
|
|


数据集共155张图像,样本尺寸大小为320*480
2.数据准备
数据集里的groundTruth是.mat的文件格式,需要转换为.png图像格式,转换代码如下:
# -*- coding: utf-8 -*-
from os.path import isdir
from scipy import io
import os, sys
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
if __name__ == '__main__':
file_path = './CrackForest-dataset-master/groundTruth/'
png_img_dir = './CrackForest-dataset-master/groundTruthPngImg/'
if not isdir(png_img_dir):
os.makedirs(png_img_dir)
image_path_lists = os.listdir(file_path)
images_path = []
for index in range(len(image_path_lists)):
image_file = os.path.join(file_path, image_path_lists[index])
#print(image_file)#./CrackForest-dataset-master/groundTruth/001.mat
images_path.append(image_file)
image_mat = io.loadmat(image_file)
segmentation_image = image_mat['groundTruth']['Segmentation'][0]
segmentation_image_array = np.array(segmentation_image[0])
image = Image.fromarray((segmentation_image_array -1) * 255)
png_image_path = os.path.join(png_img_dir, "%s.png" % image_path_lists[index][0:3])
#print(png_image_path)#./CrackForest-dataset-master/groundTruthPngImg/001.png
image.save(png_image_path)
plt.figure()
plt.imshow(image)
#plt.pause(2)
plt.pause(0.001)
#plt.show()
groundTruth文件下的label是.mat的文件格式:

groundTruthPngImg文件夹下为转换后的label是.png的图像格式:

3.数据处理
# -*- coding: utf-8 -*-
import os, sys
import numpy as np
import cv2 as cv
import torch
from torch.utils.data import Dataset,DataLoader
import matplotlib.pylab as plt
class SegmentationDataset(object):
def __init__(self, image_dir, mask_dir):
self.images = []
self.masks = []
files = os.listdir(image_dir)
sfiles = os.listdir(mask_dir)
for i in range(len(sfiles)):
img_file = os.path.join(image_dir, files[i])
mask_file = os.path.join(mask_dir, sfiles[i])
# print(img_file, mask_file)
self.images.append(img_file)
self.masks.append(mask_file)
def __len__(self):
return len(self.images)
def num_of_samples(self):
return len(self.images)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
image_path = self.images[idx]
mask_path = self.masks[idx]
else:
image_path = self.images[idx]
mask_path = self.masks[idx]
img = cv.imread(image_path, cv.IMREAD_GRAYSCALE) # BGR order
mask = cv.imread(mask_path, cv.IMREAD_GRAYSCALE)
#print(img.shape)
# 输入图像
img = np.float32(img) / 255.0
img = np.expand_dims(img, 0)
# 目标标签0 ~ 1, 对于
mask[mask <= 128] = 0
mask[mask > 128] = 1
mask = np.expand_dims(mask, 0)
sample = {'image': torch.from_numpy(img), 'mask': torch.from_numpy(mask),}
return sample
"""显示图像"""
def imshow_image(mydata_loader):
plt.figure()
for (cnt, i) in enumerate(mydata_loader):
image = i['image']
label = i['mask']
for j in range(8): #一个批次设为:8
# ax = plt.subplot(2, 4, j + 1)
# ax.axis('off')
ax1=plt.subplot(121)
ax2=plt.subplot(122)
# permute函数:可以同时多次交换tensor的维度
# print(image[j].permute(1, 2, 0).shape)
ax1.imshow(image[j].permute(1, 2, 0), cmap='gray')
ax1.set_title('image')
ax2.imshow(label[j].permute(1, 2, 0), cmap='gray')
ax2.set_title('mask')
# plt.pause(0.005)
plt.show()
if cnt == 6:
break
plt.pause(0.005)
if __name__ == '__main__':
image_dir='./CrackForest-dataset-master/image/'
mask_dir = './CrackForest-dataset-master/groundTruthPngImg/'
dataloader=SegmentationDataset(image_dir=image_dir,mask_dir=mask_dir)
mydata_loader = DataLoader(dataloader, batch_size=8, shuffle=False)
imshow_image(mydata_loader)
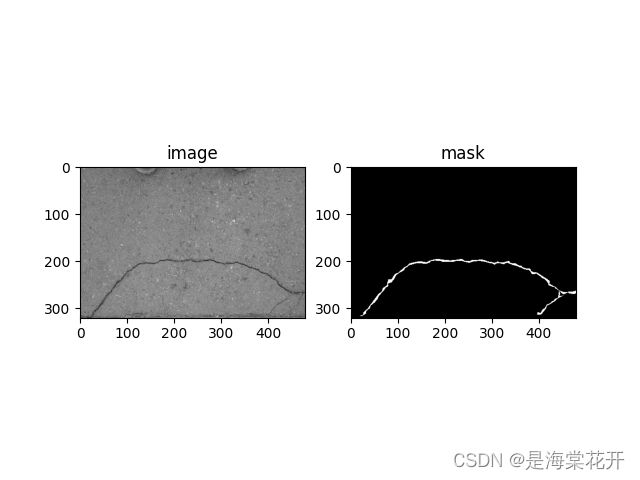
4.Unet代码
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from torchsummary import summary
device = "cuda" if torch.cuda.is_available() else "cpu"
#定义卷积块
class DoubleConv(nn.Module):
def __init__(self,in_channel,out_channel):
super(DoubleConv,self).__init__()
self.conv=nn.Sequential(nn.Conv2d(in_channel,out_channel,kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Conv2d(out_channel,out_channel,3,1,1,bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
)
def forward(self,input):
out=self.conv(input)
return out
#定义Unet网络
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
"""定义下采样网络"""
self.encoder1 = DoubleConv(1,32)
self.encoder1_down=nn.MaxPool2d(kernel_size=2, stride=2)
self.encoder2 = DoubleConv(32,64)
self.encoder2_down=nn.MaxPool2d(2,2)
self.encoder3 = DoubleConv(64,128)
self.encoder3_down=nn.MaxPool2d(2,2)
self.encoder4 = DoubleConv(128,256)
self.encoder4_down=nn.MaxPool2d(2,2)
self.encoder5 = DoubleConv(256,512)
"""定义上采样网络"""
self.decoder1 = nn.Sequential(nn.ConvTranspose2d(512,256, kernel_size=2, stride=2))
self.decoder1_up = DoubleConv(512,256)
self.decoder2 = nn.Sequential(nn.ConvTranspose2d(256,128, 2, stride=2))
self.decoder2_up = DoubleConv(256,128)
self.decoder3 = nn.Sequential(nn.ConvTranspose2d(128,64, 2, stride=2))
self.decoder3_up = DoubleConv(128,64)
self.decoder4 = nn.Sequential(nn.ConvTranspose2d(64,32, 2, stride=2))
self.decoder4_up = DoubleConv(64,32)
self.decoder_output = nn.Conv2d(32,2, kernel_size=5, stride=1, padding=2)
def forward(self,x):
e1 = self.encoder1(x)
e1_down=self.encoder1_down(e1)
e2 = self.encoder2(e1_down)
e2_down=self.encoder2_down(e2)
e3 = self.encoder3(e2_down)
e3_down=self.encoder3_down(e3)
e4 = self.encoder4(e3_down)
e4_down=self.encoder4_down(e4)
e5 = self.encoder5(e4_down)
d1 = self.decoder1(e5)
d1 = torch.cat((d1,e4), dim=1)
d1 = self.decoder1_up(d1)
d2 = self.decoder2(d1)
d2 = torch.cat((d2,e3), dim=1)
d2 = self.decoder2_up(d2)
d3 = self.decoder3(d2)
d3 = torch.cat((d3,e2), dim=1)
d3 = self.decoder3_up(d3)
d4 = self.decoder4(d3)
d4 = torch.cat((d4,e1), dim=1)
d4 = self.decoder4_up(d4)
out = self.decoder_output(d4)
# print(out.shape)
return out
if __name__ == '__main__':
summary(Unet().to(device),input_size=(1,320,480),batch_size=-1)
5.训练代码
# -*- coding: utf-8 -*-
import os, sys
import cv2 as cv
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import lr_scheduler, optimizer
import torchvision
from torch.utils.data import DataLoader, sampler
"""加载自己定义的.py文件"""
#from image_process import *
from read_dataset import *
from Unet_model import *
device="cuda" if torch.cuda.is_available() else "cpu"
image_dir = './CrackForest-dataset-master/image/'
mask_dir = './CrackForest-dataset-master/groundTruthPngImg/'
dataloader = SegmentationDataset(image_dir, mask_dir)#数据读取
train_loader = DataLoader(dataloader, batch_size=8, shuffle=False)
#print("样本数量:", dataloader.num_of_samples(), len(dataloader), train_loader.dataset)
if __name__ == '__main__':
index = 0
num_epochs = 50
train_on_gpu = True
unet = Unet().to(device)#Uet网络
optimizer = torch.optim.SGD(unet.parameters(), lr=0.01, momentum=0.9)
for epoch in range(num_epochs):
train_loss = 0.0
for i_batch, sample_batched in enumerate(train_loader):
images_batch, target_labels = sample_batched['image'], sample_batched['mask']
# print(target_labels.min())#tensor(0, dtype=torch.uint8)
# print(target_labels.max())#tensor(1, dtype=torch.uint8)
if train_on_gpu:
images_batch, target_labels = images_batch.to(device), target_labels.to(device)
#images_batch, target_labels = images_batch.cuda(), target_labels.cuda()
optimizer.zero_grad()
"""forward pass: compute predicted outputs by passing inputs to the model"""
#print("输入样本的形状:",images_batch.shape)#输入样本的形状: torch.Size([8, 1, 320, 480])
m_label_out_ = unet(images_batch)
#print(m_label_out_.shape)#torch.Size([8, 2, 320, 480])
# calculate the batch loss
target_labels = target_labels.contiguous().view(-1)#执行contiguous()这个函数,把tensor变成在内存中连续分布的形式
m_label_out_ = m_label_out_.transpose(1,3).transpose(1, 2).contiguous().view(-1, 2)
target_labels = target_labels.long()
loss = torch.nn.functional.cross_entropy(m_label_out_, target_labels)
print(loss)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()
if index % 100 == 0:
print('step: {} \tcurrent Loss: {:.6f} '.format(index, loss.item()))
index += 1
# test(unet)
# 计算平均损失
train_loss = train_loss / dataloader.num_of_samples()
# 显示训练集与验证集的损失函数
print('Epoch: {} \tTraining Loss: {:.6f} '.format(epoch, train_loss))
# test(unet)
# save model
unet.eval()
torch.save(unet.state_dict(), './CrackForest-dataset-master/save_model_dir/unet_road_model.pkl')
torch.save(unet.state_dict(), './CrackForest-dataset-master/save_model_dir/unet_road_model.pt')
6.测试代码
# -*- coding: utf-8 -*-
import os,sys
import torch
import torchvision
import numpy as np
import cv2 as cv
from Unet_model import *
device="cuda" if torch.cuda.is_available() else "cpu"
model_path='./CrackForest-dataset-master/save_model_dir/unet_road_model.pt'
unet = Unet().to(device)
model_dict=unet.load_state_dict(torch.load(model_path))
#print(model_dict)
def test(unet):
#model_dict=unet.load_state_dict(torch.load(model_path))
root_dir = './CrackForest-dataset-master/test/'
fileNames = os.listdir(root_dir)
# print(fileNames)
for f in fileNames:
image = cv.imread(os.path.join(root_dir, f), cv.IMREAD_GRAYSCALE)
# print(image)
h, w = image.shape
# print(image.shape)
img = np.float32(image) /255.0
img = np.expand_dims(img, 0)
x_input = torch.from_numpy(img).view( 1, 1, h, w)
#probs = unet(x_input.cuda())
probs = unet(x_input.to(device))
#print(probs,probs.shape)#torch.Size([1, 2, 320, 480])
m_label_out_ = probs.transpose(1, 3).transpose(1, 2).contiguous().view(-1, 2)
#print(m_label_out_,m_label_out_.shape)#torch.Size([153600, 2])
grad, output = m_label_out_.data.max(dim=1)
#print(m_label_out_.data.max(dim=1))
output[output > 0] = 255
predic_ = output.view(h, w).cpu().detach().numpy()
# print(predic_)
# print(predic_.max())
# print(predic_.min())
#print(predic_.argmax(-1))
# print(predic_.shape)
"""显示测试结果"""
result = cv.resize(np.uint8(predic_), (w, h))
# cv.imshow("input", image)
#
# cv.imshow("unet-segmentation-demo", result)
# cv.waitKey(0)
"""将结果保存在测试seg目录下"""
#result = cv.resize(np.uint8(predic_), (w, h))
result_image_path = os.path.join('./CrackForest-dataset-master/png_img_dir', f)#存放测试结果
cv.imwrite(result_image_path, result)
# cv.destroyAllWindows()
if __name__ == '__main__':
test(unet)
测试结果:
