【目标检测】yolo系列yolo x学习笔记(2021年旷视)
目录
一、速度和检测效果
二、yoloX的改进点
2.1 Decoupled Head(解耦头)
2.2数据增强:Mosaic + MixUp
2.3 Anchor Free
2.4 Label Assignment(样本匹配)
作者尝试了3种正样本选择方式:
SimOTA优点:
simOTA(Optimal Transport Assignment)整体代码逻辑:
☆dynamic top-k 的计算过程:
yoloX的精度指标
一、速度和检测效果
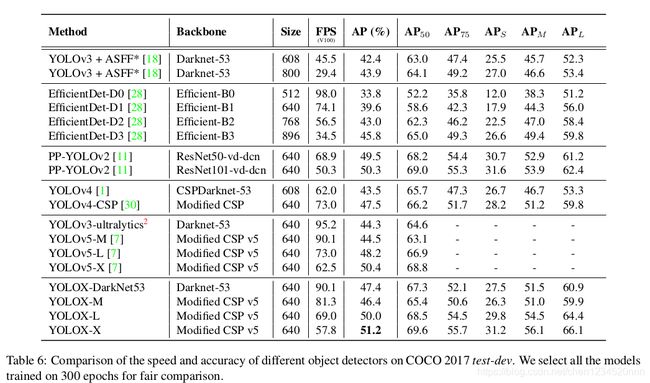
1、YOLOX-L和YOLOv4-CSP、YOLOv5-L有差不多参数量的情况下,YOLOX-L在COCO上取得50.0%AP(比YOLOv5-L高出1.8%的AP),且YOLOX-L在单张Tesla V100上能达到68.9FPS。
2、YOLOX-Tiny和YOLOX-Nano(只有0.91M参数量和1.08G FLOPs)比对应的YOLOv4-Tiny和NanoDet3分别高出10% AP和1.8% AP
3、在Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) 只使用YOLOX-L模型取得第一名。
二、yoloX的改进点
2.1 Decoupled Head(解耦头)
将网络分类头和回归头解耦。
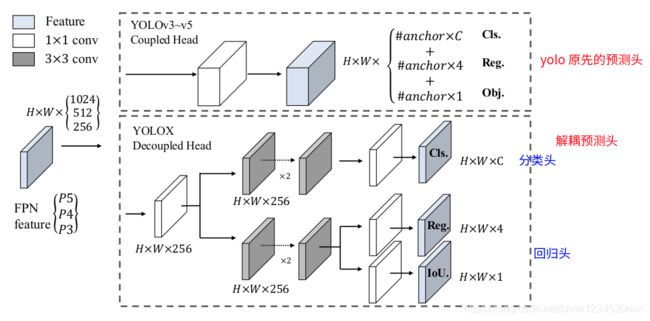 yoloX解耦了分类头和回归头
yoloX解耦了分类头和回归头
1)解耦头的好处:
- 精度带来提升:相比较于非解耦的端到端方式,解耦能带来4.2%AP提升;
- 收敛速度也明显加快:将预测分支解耦提升了收敛速度;
2)解耦时控制计算量:
为了权衡速度和性能,使用 1个1x1 的卷积先进行降维,并在分类和回归分支里各使用了 2个3x3 卷积,最终调整到仅仅增加一点点参数。
2.2数据增强:Mosaic + MixUp
YOLOX继续给baseline增加了Mosaic和Mix-up两个数据增强手段。在训练的最后15个epoch,这两个数据增强会被关闭掉。
1)Mosaic增强:Mosaic 经过 YOLOv5 和 v4 的验证,证明其在极强的 baseline 上能带来显著涨点。
2)MixUp:用在目标检测中大概的方式是:两张图以一定的比例对rgb值进行混合,同时需要模型预测出原本两张图中所有的目标。目前MixUp在各大竞赛、各类目标检测中属于稳定提点的策略。
3)Mosaic 配上 Copypaste,依然有不俗的提升;
- Copypaste 的实现依赖于目标的 mask 标注,而 mask 标注在常规的检测业务上是稀缺的资源。而由于 MixUp 和 Copypaste 有着类似的贴图的行为,还不需要 mask 标注,因此可以让 YOLOX 在没有 mask 标注的情况下吃到 Copypaste 的涨点。不过我们实现的 Mixup,没有原始 Mixup 里的 Bernoulli Distribution 和 Soft Label ,有的仅是 0.5 的常数透明度和 Copypaste 里提到的尺度缩放。
- Data Augmentation 里面需要强调的一点是:训练结束前的15个 epoch 关掉 Mosaic 和Mixup ,这对于 YOLOX 非常重要。因为Mosaic+Mixup 生成的训练图片,远远脱离自然图片的真实分布,并且 Mosaic 大量的 crop 操作会带来很多不准确的标注框;
 Mosaic+MixUp:马赛克是将几张图片缩放然后拼在一起,MixUp是将两张图片调整透明度然后叠加在一起
Mosaic+MixUp:马赛克是将几张图片缩放然后拼在一起,MixUp是将两张图片调整透明度然后叠加在一起
2.3 Anchor Free
将原有一个特征图预测3组不同尺寸anchor减少成只预测1组,直接预测4个值(左上角xy坐标和box高宽)。减少了参数量和GFLOPs,使速度更快,且表现更好。
Anchor Free 的优点:
- 1)Anchor Based 检测器为了追求最优性能通常会需要对anchor box 进行聚类分析,这增加了算法工程师的时间成本,且在不同场景应用中缺乏较好的泛化性;
- 2)Anchor 增加了检测头的复杂度,会生成大量的预测框,将大量检测结果从NPU搬运到CPU上对于某些边缘设备是无法容忍的。
- 3)Anchor Free 的解码代码逻辑更简单,使用起来更方便。
2.4 Label Assignment(样本匹配)
作者尝试了3种正样本选择方式:
1)只将物体中心点所在的位置认为是正样本,一个gt最多只会有一个正样本。AP达到42.9%。
2)Multi positives:将中心3*3区域都认为是正样本,即从策略1中每个gt有1个正样本增长到9个正样本。且AP提升到45%,已经超越U版yolov3的44.3%AP。
3)SimOTA
OTA(Optimal Transport Assignment):在目标检测中,有时候经常会出现一些模棱两可的anchor,如图3,即某一个anchor,按照正样本匹配规则,会匹配到两个gt,而retinanet这样基于IoU分配是会把anchor分配给IoU最大的gt,而OTA作者认为,将模糊的anchor分配给任何gt或背景都会对其他gt的梯度造成不利影响,因此,对模糊anchor样本的分配是特殊的,除了局部视图之外还需要其他信息。因此,更好的分配策略应该摆脱对每个gt对象进行最优分配的惯例,而转向全局最优的思想,换句话说,为图像中的所有gt对象找到全局的高置信度分配。(和DeTR中使用使用匈牙利算法一对一分配有点类似)
SimOTA优点:
- 1、simOTA能够做到自动的分析每个gt要拥有多少个正样本。
- 2、能自动决定每个gt要从哪个特征图来检测。
- 3、相比较OTA,simOTA运算速度更快。
simOTA(Optimal Transport Assignment)整体代码逻辑:
1、确定正样本候选区域。
2、计算anchor与gt的iou。
3、在候选区域内计算cost(损失)。
4、使用iou确定每个gt的dynamic_k。
5、为每个gt取cost排名最小的前dynamic_k个anchor作为正样本,其余为负样本。
6、使用正负样本计算loss。
☆dynamic top-k 的计算过程:
- 1.为每个grid分配正样本
1)判断grid是否在gt-box的内部,如果在则为正样本fg_mask;
2)同时判断grid在不在gt-box中心点2.5个像素点区域内(论文是3个像素点)
3)如果上面两个条件同时满足则用is_in_boxes_and_center 表示,这一步是一个筛选的过程选更靠近gt的grid为正样本。
- 2. 计算代价矩阵
cost = (
pair_wise_cls_loss # Lcls
+ 3.0 * pair_wise_ious_loss # λ*Lreg,实际代码中把λ设置为了3
+ 100000.0 * (~is_in_boxes_and_center) # 把不在考虑范围内的anchor置为很大的数值
)1)代码中pair_wise_cls_loss和pair_wise_ious_loss是通过fg_mask选取的gird与gt的分类loss和IoU loss;
2)代码第3项可以看到cost 里面有100000.0 * (~is_in_boxes_and_center)的计算,发现当grid不在is_in_boxes_and_center 里面的代价cost是非常大的值。
- 3. dynamic_k_matching
1)获取与当前gt的IoU值前10的预测结果,将这top10的IoU值相加的总和值,就为当前gt的dynamic_k。dynamic_k最小值为1,保证一个gt至少有一个正样本。
由于前期模型预测不准,导致iou基本比较小,因此模型训练前期dynamic_k大多为1。
2)取cost排名最小的前dynamic_k个anchor作为gt的正样本,其余为负样本。
yoloX的精度指标

参考链接:
https://zhuanlan.zhihu.com/p/394392992
https://zhuanlan.zhihu.com/p/392221567