(CNS复现)CLAM——Chapter_03
(CNS复现)CLAM——Chapter_03
CLAM: A Deep-Learning-based Pipeline for Data Efficient and Weakly Supervised Whole-Slide-level Analysis
文章目录
- (CNS复现)CLAM——Chapter_03
- 前言
-
-
- Step-01: imports
- Step-02:初始化配置信息
- Step-03:调试代码
-
- Step-03.01初始化函数
- Step-03.02 初始化模型
- Step-03.03 主函数调试
-
- 总结
前言
(CNS复现)CLAM——Chapter_00
(CNS复现)CLAM——Chapter_01
(CNS复现)CLAM——Chapter_02
(CNS复现)CLAM——Chapter_03
在上一个章节中讲到一个很重要的点就是:
由于每一个WSI的大小是不一样的,因此patch(也就是特征/通道)的个数也不一样,这就给模型构建提升了很大的难度
这种情况下,解决方法一般有两种:
-
构建一个自适应模型,根据不同的输入,生成不同的模型
-
构建两个model,第一个model用于进一步的提取特提取,第二个model用于分类
那么显然,第二种方法执行起来更简单
对应到官方的手册,则是使用:extract_features_fp.py 进行特征提取和处理
Step-01: imports
# imports
import torch
import torch.nn as nn
from math import floor
import os
import random
import numpy as np
import pandas as pd
import pdb
import time
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms, utils, models
from PIL import Image
import h5py
import openslide
import warnings
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# my imports
from models.resnet_custom import resnet50_baseline # 读取imageNet的resnet50网络
from utils.file_utils import save_hdf5 # 用于保存h5文件,上一次使用过
# other options
warnings.filterwarnings("ignore")
Step-02:初始化配置信息
主要是根据 args 中给出的信息进行配置
# Feature Extraction
data_h5_dir = '/media/yuansh/14THHD/CLAM/toy_test' # h5 存放地址
data_slide_dir = '/media/yuansh/14THHD/CLAM/DataSet/toy_example' # 元数据地址
slide_ext = '.svs' # 元数据后缀类型
csv_path = '/media/yuansh/14THHD/CLAM/Step_2.csv' # Step2.csv 的地址,这个的生成方法已经在 第0章节中讲解过
feat_dir = '/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY' # 输出地址
batch_size = 512 # 训练时候的batch
no_auto_skip = False # 自动条过已经处理过的文件
custom_downsample = 1 # 下采样因子(没用)
target_patch_size = -1 # 缩放因子(没用)
Step-03:调试代码
这一部分只调试 compute_w_loader,函数定义如下:
不过这里涉及到了很多的内嵌函数,得一个个讲
Step-03.01初始化函数
# 主函数
def compute_w_loader(file_path, output_path, wsi, model,
batch_size=8, verbose=0, print_every=20, pretrained=True,
custom_downsample=1, target_patch_size=-1):
"""
args:
file_path: directory of bag (.h5 file)
output_path: directory to save computed features (.h5 file)
model: pytorch model
batch_size: batch_size for computing features in batches
verbose: level of feedback
pretrained: use weights pretrained on imagenet
custom_downsample: custom defined downscale factor of image patches
target_patch_size: custom defined, rescaled image size before embedding
"""
dataset = Whole_Slide_Bag_FP(file_path=file_path, wsi=wsi, pretrained=pretrained,
custom_downsample=custom_downsample, target_patch_size=target_patch_size)
x, y = dataset[0]
kwargs = {'num_workers': 4,
'pin_memory': True} if device.type == "cuda" else {}
loader = DataLoader(dataset=dataset, batch_size=batch_size,
**kwargs, collate_fn=collate_features)
if verbose > 0:
print('processing {}: total of {} batches'.format(file_path, len(loader)))
mode = 'w'
for count, (batch, coords) in enumerate(loader):
with torch.no_grad():
if count % print_every == 0:
print('batch {}/{}, {} files processed'.format(count,
len(loader), count * batch_size))
batch = batch.to(device, non_blocking=True)
mini_bs = coords.shape[0]
features = model(batch)
features = features.cpu().numpy()
asset_dict = {'features': features, 'coords': coords}
save_hdf5(output_path, asset_dict, attr_dict=None, mode=mode)
mode = 'a'
return output_path
# 用于读取csv文件中的样本id
class Dataset_All_Bags(Dataset):
def __init__(self, csv_path):
self.df = pd.read_csv(csv_path)
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
return self.df['slide_id'][idx]
class Whole_Slide_Bag_FP(Dataset):
def __init__(self,
file_path,
wsi,
pretrained=False,
custom_transforms=None,
custom_downsample=1,
target_patch_size=-1
):
"""
Args:
file_path (string): Path to the .h5 file containing patched data.
pretrained (bool): Use ImageNet transforms
custom_transforms (callable, optional): Optional transform to be applied on a sample
custom_downsample (int): Custom defined downscale factor (overruled by target_patch_size)
target_patch_size (int): Custom defined image size before embedding
"""
self.pretrained = pretrained
self.wsi = wsi
if not custom_transforms:
self.roi_transforms = eval_transforms(pretrained=pretrained)
else:
self.roi_transforms = custom_transforms
self.file_path = file_path
with h5py.File(self.file_path, "r") as f:
print('\n')
dset = f['coords']
print(dset)
print('\n')
self.patch_level = f['coords'].attrs['patch_level']
self.patch_size = f['coords'].attrs['patch_size']
self.length = len(dset)
if target_patch_size > 0:
self.target_patch_size = (target_patch_size, ) * 2
elif custom_downsample > 1:
self.target_patch_size = (
self.patch_size // custom_downsample, ) * 2
else:
self.target_patch_size = None
self.summary()
def __len__(self):
return self.length
def summary(self):
hdf5_file = h5py.File(self.file_path, "r")
dset = hdf5_file['coords']
for name, value in dset.attrs.items():
print(name, value)
print('\nfeature extraction settings')
print('target patch size: ', self.target_patch_size)
print('pretrained: ', self.pretrained)
print('transformations: ', self.roi_transforms)
def __getitem__(self, idx):
with h5py.File(self.file_path, 'r') as hdf5_file:
coord = hdf5_file['coords'][idx]
img = self.wsi.read_region(
coord, self.patch_level, (self.patch_size, self.patch_size)).convert('RGB')
if self.target_patch_size is not None:
img = img.resize(self.target_patch_size)
img = self.roi_transforms(img).unsqueeze(0)
return img, coord
# 用于获取候选特征图
def collate_features(batch):
img = torch.cat([item[0] for item in batch], dim = 0)
coords = np.vstack([item[1] for item in batch])
return [img, coords]
# 输出模型结构
def print_network(net):
num_params = 0
num_params_train = 0
print(net)
for param in net.parameters():
n = param.numel()
num_params += n
if param.requires_grad:
num_params_train += n
print('Total number of parameters: %d' % num_params)
print('Total number of trainable parameters: %d' % num_params_train)
# image 标准化
def eval_transforms(pretrained=False):
if pretrained:
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
else:
mean = (0.5, 0.5, 0.5)
std = (0.5, 0.5, 0.5)
trnsfrms_val = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
]
)
return trnsfrms_val
Step-03.02 初始化模型
文章使用的是 ImageNet 中的标准的resnet50架构
因为对模型架构可视化后的图片太大了,因此没有展示出来
%%capture
print('initializing dataset')
csv_path = csv_path
if csv_path is None:
raise NotImplementedError
# 这个是继承了dataset的类方法
# 读取csv文件中的数据
bags_dataset = Dataset_All_Bags(csv_path)
os.makedirs(feat_dir, exist_ok=True)
os.makedirs(os.path.join(feat_dir, 'pt_files'), exist_ok=True)
os.makedirs(os.path.join(feat_dir, 'h5_files'), exist_ok=True)
dest_files = os.listdir(os.path.join(feat_dir, 'pt_files'))
print('loading model checkpoint')
# 调用ImageNet的 resnet50架构
model = resnet50_baseline(pretrained=True)
# 可视化模型结构
import hiddenlayer as h
vis_graph = h.build_graph(model, torch.zeros([1 ,3, 256, 256])) # 获取绘制图像的对象
vis_graph.theme = h.graph.THEMES["blue"].copy() # 指定主题颜色
vis_graph.save("/home/yuansh/Desktop/demo1.png") # 保存图像的路径
model = model.to(device)
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
model.eval()
total = len(bags_dataset)
Step-03.03 主函数调试
这一部分涉及到一个 for 循环,这一部分的作用是迭代所有的样本,因此,只需要调试其中一个样本即可
在这个步骤中,需要读取两个数据:
-
原WSI文件,后缀为
.svs -
WSI文件对应的patch文件,后缀为
.h5
bag_candidate_idx = 1
slide_id = bags_dataset[bag_candidate_idx].split(slide_ext)[0]
bag_name = slide_id+'.h5'
h5_file_path = os.path.join(data_h5_dir, 'patches', bag_name)
slide_file_path = os.path.join(
data_slide_dir, slide_id+slide_ext)
output_path = os.path.join(feat_dir, 'h5_files', bag_name)
初始化wsi对象
time_start = time.time()
wsi = openslide.open_slide(slide_file_path)
接下来的话需要拆解两个嵌套函数
-
compute_w_loader -
Whole_Slide_Bag_FP
初始化配置参数
file_path: patch 的路径 .h5
output_path: 筛选后的 patch 的路径 .h5
model: 定制化模型(下面流程使用的是resnet)
Custom_downsample:自定义图像补丁的降尺度因子
Target_patch_size:自定义,在嵌入前重新缩放图像大小
file_path = h5_file_path
output_path
wsi
batch_size = 256
verbose = 1
print_every = 20
custom_downsample=1
target_patch_size=-1
构建特在图迭代对象,这个基本上和平时做模型的创建的dataset类一模一样。只是wsi对象要进行特殊的处理而已
# Whole_Slide_Bag_FP
class Whole_Slide_Bag_FP(Dataset):
def __init__(self,
file_path,
wsi,
pretrained=False,
custom_transforms=None,
custom_downsample=1,
target_patch_size=-1
):
# 读取与训练模型
self.pretrained = pretrained
# 导入wsi 对爱嗯
self.wsi = wsi
# 使用默认处理模式,就是resnet50使用的标准化方式和将其转化为torch对象
if not custom_transforms:
self.roi_transforms = eval_transforms(pretrained=pretrained)
else:
self.roi_transforms = custom_transforms
# 读取文件路径
self.file_path = file_path
# 读 .h5 文件
with h5py.File(self.file_path, "r") as f:
# 获取patch坐标
dset = f['coords']
# 一些patch属性
self.patch_level = f['coords'].attrs['patch_level']
self.patch_size = f['coords'].attrs['patch_size']
self.length = len(dset)
# 这一部分都是false就不用管了
# 不过这里的意思是对每一个patch进行调整下采样和缩放
if target_patch_size > 0:
self.target_patch_size = (target_patch_size, ) * 2
elif custom_downsample > 1:
self.target_patch_size = (
self.patch_size // custom_downsample, ) * 2
else:
self.target_patch_size = None
self.summary()
# 这一部分是记录数据大小的 Dataset 类必写
def __len__(self):
return self.length
# summary
def summary(self):
hdf5_file = h5py.File(self.file_path, "r")
dset = hdf5_file['coords']
for name, value in dset.attrs.items():
print(name, value)
print('\nfeature extraction settings')
print('target patch size: ', self.target_patch_size)
print('pretrained: ', self.pretrained)
print('transformations: ', self.roi_transforms)
# 生成迭代器
def __getitem__(self, idx):
with h5py.File(self.file_path, 'r') as hdf5_file:
coord = hdf5_file['coords'][idx]
# 读取patch所对应的wsi区域
# 第一个参数是patch对应的坐标,下采样水平,patch大小,然后将其转为RGB
img = self.wsi.read_region(
coord, self.patch_level, (self.patch_size, self.patch_size)).convert('RGB')
if self.target_patch_size is not None:
img = img.resize(self.target_patch_size)
img = self.roi_transforms(img).unsqueeze(0)
return img, coord
hdf5_file = h5py.File(file_path, "r")
coord = hdf5_file['coords'][1]
patch_level = hdf5_file['coords'].attrs['patch_level']
patch_size = hdf5_file['coords'].attrs['patch_size']
wsi.read_region(
coord, patch_level, (patch_size, patch_size)).convert('RGB')
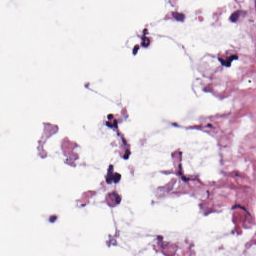
从上面的结果,我们可以知道,Whole_Slide_Bag_FP 这个函数的作用就是使用之前存下来的patch的坐标信息,在整个wsi图片上进行裁减,最后得到若干张固定大小和固定通道的patch
接着,继续看后续的步骤
# dataset 就是上一步返回的patch的image 以及对应的坐标
x, y = dataset[0]
# 读取数据
kwargs = {'num_workers': 12, 'pin_memory': True} if device.type == "cuda" else {}
loader = DataLoader(dataset=dataset, batch_size=batch_size,
**kwargs, collate_fn=collate_features)
# 输出进度
if verbose > 0:
print('processing {}: total of {} batches'.format(file_path, len(loader)))
mode = 'w'
for count, (batch, coords) in enumerate(loader):
with torch.no_grad():
if count % print_every == 0:
print('batch {}/{}, {} files processed'.format(count,
len(loader), count * batch_size))
batch = batch.to(device, non_blocking=True)
mini_bs = coords.shape[0]
# 保存模型预测特在
features = model(batch)
features = features.cpu().numpy()
asset_dict = {'features': features, 'coords': coords}
save_hdf5(output_path, asset_dict, attr_dict=None, mode=mode)
mode = 'a'
‘/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY/h5_files/C3L-00503-21.h5’
‘/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY/h5_files/C3L-00503-21.h5’ ‘/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY/h5_files/C3L-00503-21.h5’ ‘/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY/h5_files/C3L-00503-21.h5’ ‘/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY/h5_files/C3L-00503-21.h5’
‘/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY/h5_files/C3L-00503-21.h5’
‘/media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY/h5_files/C3L-00503-21.h5’
截至到这里,数据预处理也都结束了
不过,其实单纯的看代码也不知道是什么意思。
比如写到这里,我说已经吧每个image的特在图取出来了一共1024
但是这样就很奇怪,他到底如何筛选的特征图的呢?
于是我进一步的尝试以下看一下每一张图的特在图结构如何
for bag_candidate_idx in range(5):
slide_id = bags_dataset[bag_candidate_idx].split(slide_ext)[0]
bag_name = slide_id+'.h5'
h5_file_path = os.path.join(data_h5_dir, 'patches', bag_name)
slide_file_path = os.path.join(
data_slide_dir, slide_id+slide_ext)
print(slide_id)
if not no_auto_skip and slide_id+'.pt' in dest_files:
continue
output_path = os.path.join(feat_dir, 'h5_files', bag_name)
time_start = time.time()
wsi = openslide.open_slide(slide_file_path)
output_file_path = compute_w_loader(h5_file_path, output_path, wsi,
model=model, batch_size=batch_size, verbose=1, print_every=20,
custom_downsample=custom_downsample, target_patch_size=target_patch_size)
time_elapsed = time.time() - time_start
file = h5py.File(output_file_path, "r")
features = file['features'][:]
print('features size: ', features.shape)
print('coordinates size: ', file['coords'].shape)
features = torch.from_numpy(features)
bag_base, _ = os.path.splitext(bag_name)
torch.save(features, os.path.join(
feat_dir, 'pt_files', bag_base+'.pt'))
C3L-00081-26
features size: (2681, 1024)
coordinates size: (2681, 2)
C3L-00503-21
features size: (1703, 1024)
coordinates size: (1703, 2)
C3L-00503-22
features size: (1755, 1024)
coordinates size: (1755, 2)
C3L-00568-21
features size: (1924, 1024)
coordinates size: (1924, 2)
C3L-00568-22
features size: (1525, 1024)
coordinates size: (1525, 2)
总结
根据上面输出的特征图的大小,可以知道他是将256256的特征图压缩成11024的样子。
意思就是,这一步仅仅只是将图片弄到宽度相等的样子而已
这就很有意思了,它后面到底是如何利用这些压缩后的特征图进行分析的呢?
给大家5秒钟的时间思考:
5
4
3
2
1
…
文章最后要做的任务是提取出注意力模块,也就是说其实是一种变相语义分割模型,因此文章是对后续的每张图片的每一行单独的训练,不同模型 的训练输出不同。这一点可以根据文章最后所使用的简单的前馈神经网络得到作证:
CLAM_MB(
(attention_net): Sequential(
(0): Linear(in_features=1024, out_features=512, bias=True)
(1): ReLU()
(2): Attn_Net_Gated(
(attention_a): Sequential(
(0): Linear(in_features=512, out_features=256, bias=True)
(1): Tanh()
)
(attention_b): Sequential(
(0): Linear(in_features=512, out_features=256, bias=True)
(1): Sigmoid()
)
(attention_c): Linear(in_features=256, out_features=2, bias=True)
)
)
(classifiers): ModuleList(
(0): Linear(in_features=512, out_features=1, bias=True)
(1): Linear(in_features=512, out_features=1, bias=True)
)
(instance_classifiers): ModuleList(
(0): Linear(in_features=512, out_features=2, bias=True)
(1): Linear(in_features=512, out_features=2, bias=True)
)
(instance_loss_fn): CrossEntropyLoss()
)
因此,这篇文章总体来说还是比较简单的,大头的难点都在数据处理。
不过他的这个idea确实很有意思,值得参考。
那么,这次的 Natrue文章复现就到此为止!
如果我的博客您经过深度思考后仍然看不懂,可以根据以下方式联系我:
Best Regards,
Yuan.SH
---------------------------------------
School of Basic Medical Sciences,
Fujian Medical University,
Fuzhou, Fujian, China.
please contact with me via the following ways:
(a) e-mail :yuansh3354@163.com