【目标检测】12、TOOD: Task-aligned One-stage Object Detection
文章目录
-
- 一、背景
- 二、动机
- 三、方法
-
- 3.1 Task-aligned Head
- 3.2 Task Alignment Learning
-
- 3.2.1 Task-aligned sample assignment
- 3.2.2 Task-aligned Loss
- 四、效果

论文:https://arxiv.org/pdf/2108.07755.pdf
代码:https://github.com/fcjian/TOOD
出处:ICCV2021
一、背景
目标检测一直是计算机视觉中的重要任务。目前的方法大都是并行的实现对目标的分类和定位。分类的目标是学习目标的具有区分力的特征,定位的目标是对目标的边界进行准确的定位。所有这个两个任务有很大的不同,也会导致这两个任务的不对齐。
二、动机
现有的单阶段方法都通过一定的手段来实现两个任务的统一,也就是使用目标的中心点。他们加上目标中心点的 anchor 能够给分类和定位提供更准确的预测。例如 FCOS/ATSS 都使用 centerness 分支来提高在物体中心附近的anchor的分类得分,并且给对应的anchor的定位 loss 更多的权重。但这些方法大都有两个问题:
问题一:分类和定位是被独立对待的
现有单阶段检测方法,将分类和定位分为两个分支,这样可能回导致两个任务的互相交互很少,导致预测的不一致性。如图1所示,ATSS 检测器识别出了一个餐桌,但是对披萨的定位确非常准确。
问题二:Task-agnostic 的样本分配(对任务无差别的样本分配)
大多数 anchor-free 的检测室使用基于几何的分配方法来选择里中心点近的 anchor-point,但 anchor-based 方法通常计算anchor box 和 gt box 的 IoU 来确定 anchor。但是,分类和定位的最优 anchor 通常是不一致的,而且和目标的形状和特征有很大的关系。所以,对不同任务都使用相同的样本分配方法难以对这两个任务起到相同的作用。
如图1中 ATSS(第一行) 的 score 和 IoU,result 列展示出了一个问题,即定位最优的anchor的位置并不一定在目标的中心,而且和最好的分类得分的框不是同一个。所以,定位的准确的框可能会被 NMS 干掉。

基于此,作者提出了一个 Task-aligned one-stage object detection 方法 TOOD,通过设计一个新的 head 结构来更好的将分类和定位任务对齐。
三、方法
总览:
类似于现有的 one-stage 方法,本文提出的 TOOD 也采用了 “backbone-FPN-head” 的结构,并且为了高效性,TOOD 采用了类似于 ATSS 的anchor生成方法,即在每个位置生成一个anchor,这里的 anchor 在 anchor-free 方法中表示 anchor-point,在 anchor-based 方法中表示 anchor-box。
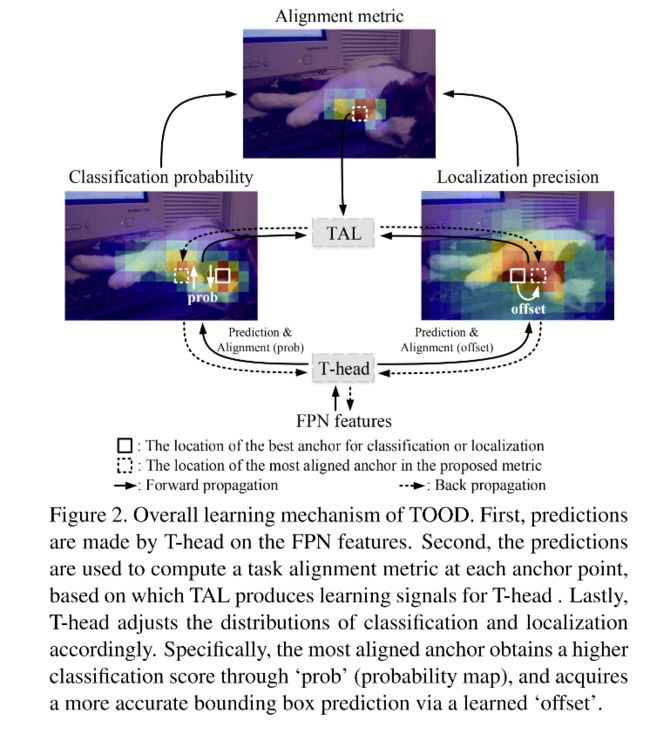
本文提出了 Task-aligned head (T-head) 和 Task Alignment Learning (TAL) 来解决分类和定位对不齐的问题,如图2所示。T-head 和 TAL 可以合作起来来实现对这个两个任务的对齐。
- 首先,T-head 在 FPN 输出特征中进行分类和定位
- 然后,TAL 基于 alignment metric 来计算两者的 alignment signal
- 最后,T-head 在反向传播的时候再使用 alignment signal 来动态调整分类的得分和定位的位置
3.1 Task-aligned Head
为了实现一个高效的结构来提升 head 的设计(如图3a),作者:
- 加强了两个任务的交互
- 提升的检测器学习对齐与否的能力
T-head 的结构如图3b所示,由一个简单的特征提取器和两个 Task-aligned Predictors 构成。
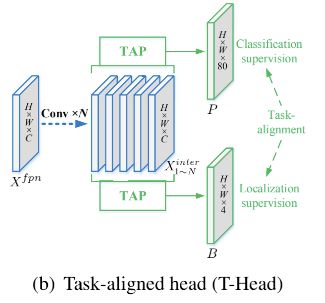
- 为了加强两个任务的交互,作者使用了一个特征提取器来从卷积层中学习 task-interactive 特征,如图3b所示,这样的设计不仅仅可以加强任务的交互,而且可以给这两个任务提供多尺度感受野的多级特征。因此,可以使用单个分支从 FPN 特征中获得丰富的多尺度特征。
- 之后,将会把计算得到的 task-interactive feature 送入两个TAP 来对齐分类和定位
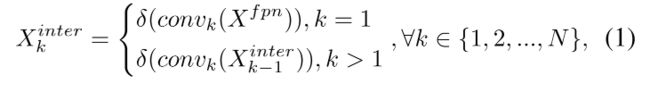
Task-aligned Predictor (TAP):
作者在计算 task-interactive features 的时候,会同事使用分类和定位的特征,这样也会使得每个任务更好的感知对方的状态。然而,由于是单个branch,task-interactive features 会不可避免的引入两个任务的特征冲突,因为两个任务的注意点是不同的。于是,作者提出了一个 layer attention 机制,通过动态计算 task-specific 的特征来进行任务的分解,如图3c所示。

task-specific 特征对每个任务的计算方式如下:
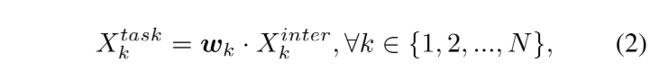
- w k w_k wk 是第 k element of the learned layer attention w ∈ R N w\in R^N w∈RN
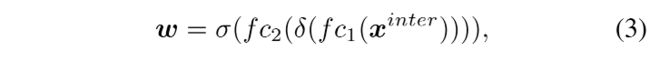
- x i n t e r x^{inter} xinter 是对 X i n t e r X^{inter} Xinter 使用 average pooling 后得到的
最终,分类或定位的结果从每个 X t a s k X^{task} Xtask 来得到:
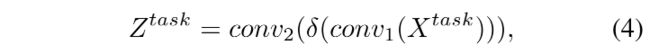
- c o n v 1 conv1 conv1:1x1 conv
- Z t a s k Z^{task} Ztask:将会通过 sigmoid 函数被转换为得分 P ∈ R H × W × 4 P\in R^{H \times W \times 4} P∈RH×W×4,通过 distance-to-box 转换为 bounding-box B ∈ R H × W × 4 B\in R^{H \times W \times 4} B∈RH×W×4
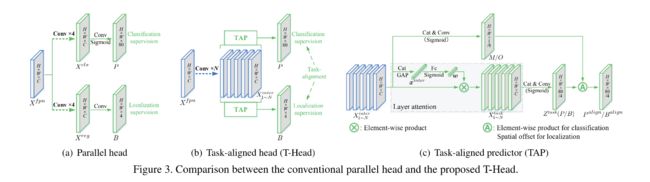
Prediction alignment:
在预测阶段,作者通过这个两个预测(P and B)的空间分布来进一步更精确的对齐这个两个任务
方法:计算 task-interactive feature,且对两个任务的对齐方法是不同的。
-
分类:如图3c,作者使用空间概率图 M ∈ R H × W × 1 M\in R^{H\times W\times 1} M∈RH×W×1来调节分类预测,M 是从交互特征图中计算得到的,使得 M 能够学习这两个任务在每个空间位置上的一致性的梯度。
-
定位:作者从交互特征图中学习 spatial offset 图 O ∈ R H × W × 8 O\in R^{H\times W\times 8} O∈RH×W×8,来对每个位置上的 bbox 进行调整。这些学习到的offset能够使得 aligned anchor point 识别出其周围最好的预测框。

其中c是channel,上式是通过双线性差值实现的,而且这种计算量很小,因为 B 的channel 维度很小。
值得注意的一点是,每个通道的offset的学习都是独立的,也就是说每个 boundary 都能学到自己的 offset。这就能使得4条边界线都能学的准确,因为它们都是独立从离它们近的anchor point 学习到的。所以,本文的方法不仅仅能够对齐分类和定位的任务,还能提升定位准确性。
alignment maps M M M 和 O O O 是从一堆 interactive feature 中学习到的,学习的方式是通过 TAL 学习:

注意:T-Head是独立于 TAL 的,可以作为一个即插即用的模块来提升单阶段目标检测的性能
3.2 Task Alignment Learning
TAL 在这里被提出来是为了进一步引导 T-Head 来做 task-aligned 的预测
3.2.1 Task-aligned sample assignment
对于实例的 anchor 分配应该满足以下规则:
- well-aligned 的anchor 应该能够同时预测得到高的分类得分和准确的定位
- misaligned 的anchor应该有一个低的分类得分,而且逐渐被抑制
基于上述两个目标,作者设计了一个新的 anchor alignment metric 来在 anchor level 衡量 task-alignment 的水平。
并且,alignment metric 被集成在了 sample 分配和 loss function里边,来动态的优化每个 anchor 的预测。
Anchor alignment metric:
我们已知,分类得分和 IoU表示了这两个任务的预测效果,所以,作者使用分类得分和IoU的高阶组合来衡量 task-alignment的程度。
方法:使用下列的方式来对每个实例计算 anchor-level 的对齐程度
![]()
- s and u 分别为分类得分和 IoU 值
- α \alpha α and β \beta β 分别为权重
从上边的公式可以看出来,t 可以同时控制得分和iou的优化来实现 task-alignment,可以引导网络动态的关注于高质量的anchor。
Training sample assignment:
对每个实例,作者选取 m 个前 t 大的value作为正样本
3.2.2 Task-aligned Loss
Classification objective:
为了精准的提升 aligned anchor 的分类得分,降低 misaligned anchor 的分类得分,作者在训练过程中使用 t t t 来替换positive anchor 的 binary label。但是这种方法,当这个label(比如 t)随着 α \alpha α 和 β \beta β 的增大而减小的时候。所以,作者使用了 normalized t t t,称为 t ^ \hat t t^,来代替正样本的binary label。
t t t 规范化的原则:
- 保证能够更好更高效的学习难样本(这类样本通常对应的 t 比较小)
- 能够较好的保留(基于预测框准确率)不同实例的差别
t ^ \hat t t^ 的获得原则(instance level):
- t ^ \hat t t^ 的最大值等于最大的 IoU 值
Binary Cross Entropy 对正样本的分类任务计算方式如下:
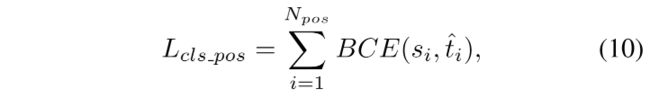
- i i i 是一个实例对应的所有正 anchor 的第 i i i 个 anchor
作者又使用了 focal loss 来弥补正负样本的不平衡:
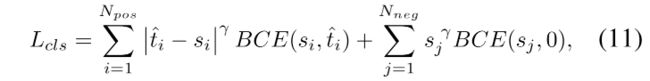
- j j j 是第 j j j 个负 anchor
- γ \gamma γ 是平衡参数
Localization objective:
well-aligned anchor(比如有较大的 t)预测出来的 bbox 通常会同时具有高的分类得分和准确的定位框,这样的 bbox 通常也会在 NMS 过程中保留下来。
t t t 也可以通过给 loss 来加权来选择高质量的bbox,即也可以衡量bbox的质量,所以在bbox的回归过程中,作者通过聚焦在well-aligned anchor (t 较大)并且抑制 misaligned anchor (t 较小)的方法,来促进任务对齐和回归预测。所以作者对回归任务的 loss 也做了加权,GIoU loss 的加权版本如下: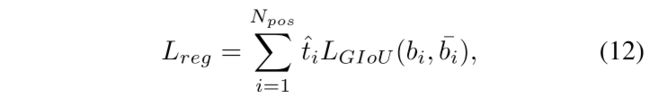
- b b b:预测的 bbox
- b ^ \hat b b^:真实的 bbox
TAL 的整体 loss 为分类和定位 loss 之和
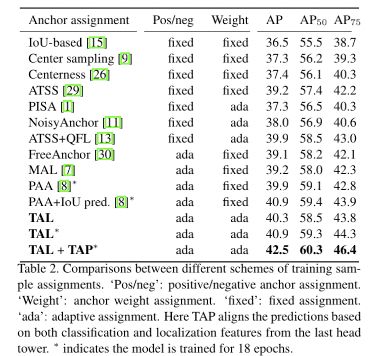
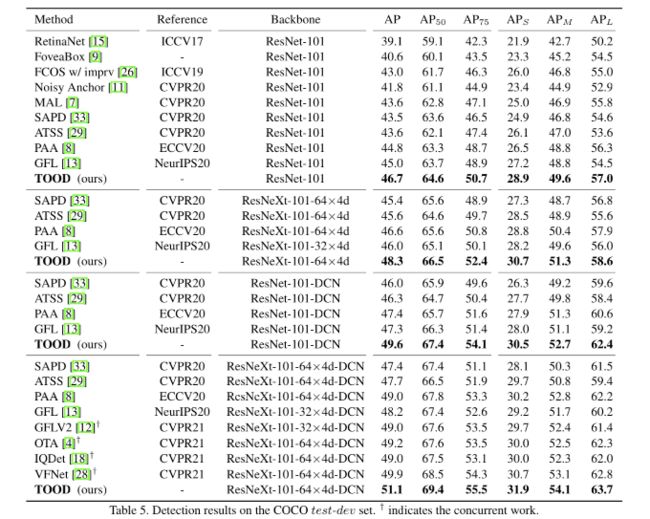
四、效果