踩实底子|每日学习|02-特征工程和文本特征提取【下】
前文说到,特征工程是为了预测结果数据的处理步骤,也简单用了一两个实例说明了文本特征的提取,其中字典特征提取和文本特征主要是将特征数据化,也就是one-hot编码。为了不让一篇博文显得长篇大论,后面两个部分的视频,就另开了一篇来记录,前面三篇主要讲的是 ,这一片主要讲的是文本特征抽取以及中文问题。
,这一片主要讲的是文本特征抽取以及中文问题。
目录
1.文本特征抽取以及中文问题
1.文本特征抽取
2.tf-df分析问题
1.文本特征抽取以及中文问题
1.文本特征抽取
对于文本数据的特征抽取是怎样一个步骤呢?和字典类似,接下来看看其作用及语法:



文本特征抽取的作用,就是对文本数据进行特征值化,值化就是把文本转为数字,常用的包有feature_extraction里面的text下的countVectorizer。对应的语法流程参看上图。
接下来来跟一个实例练习:
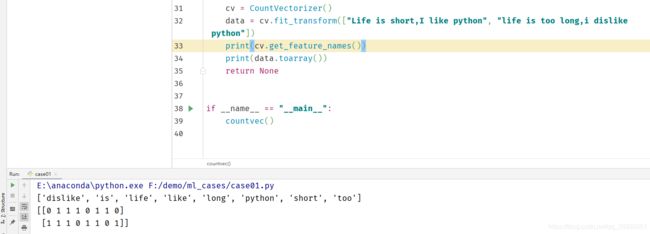
使用的样例语句是:
["Life is short,I like python", "life is too long,i dislike python"]老师的运行结果,
进行分析一下,第一个工作是:统计了所有文章当中所有的词,重复的只出现一次,词表;第二个工作是,对每篇文章进行在词列表中进行统计每个词出现的次数。
注意:单个字母(例如:I)没有统计
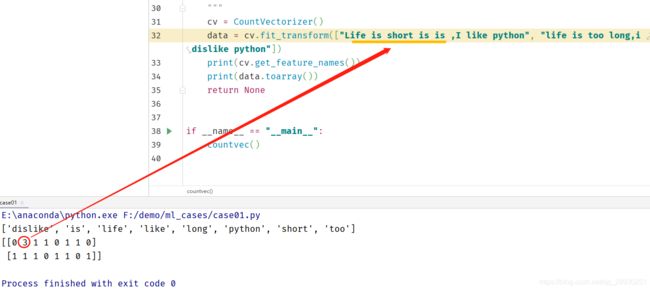
修改第一篇,佐证确实是统计单词“is”的次数。
对于文本特征抽取的用途,还是比较多的,比如上面这个实例,Count(计数)可应用于文本分类。
举个中文的案例,修改处理的语句为中文:

发现分割词语并没有英文支持的那么好,其实分词使用的就是空格来做的分词。那么中文如果想要做较好的词表,可以使用结巴工具,之前了解过的,这里直接应用。

这部分其实就是一个衍生代码的扩展,继续贴我的练习及结果:

from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def dictvec():
'''
字典数据抽取
:return: None
'''
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
data = dict.fit_transform(
[{'city': '北京', 'temperature': 100}, {'city': '天津', 'temperature': 65}, {'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}, {'city': '杭州', 'temperature': 40}])
print(dict.get_feature_names())
print(dict.inverse_transform(data))
print(data)
return None
def countvec():
"""
对文本进行特征值化
:return: None
"""
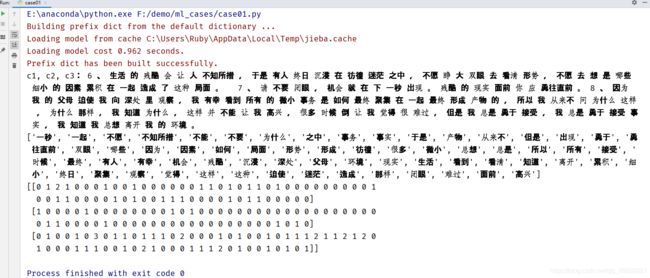
c1, c2, c3 = cutword()
print("c1, c2, c3:",c1, c2, c3)
cv = CountVectorizer()
# data = cv.fit_transform(["Life is short is is ,I like python", "life is too long,i dislike python"])
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names())
print(data.toarray())
return None
def cutword():
con1 = jieba.cut("6、生活的残酷会让人不知所措,于是有人终日沉浸在彷徨迷茫之中,不愿睁大双眼去看清形势,不愿去想是哪些细小的因素累积在一起造成了这种局面。 ")
con2 = jieba.cut("7、请不要闭眼,机会就在下一秒出现。残酷的现实面前你应勇往直前。")
con3 = jieba.cut("8、因为我的父母迫使我向深处里观察,我有幸看到所有的微小事务是如何最终聚集在一起最终形成产物的,所以我从来不问为什么这样,为什么那样,我知道为什么,这样并不能让我高兴,很多时候倒让我觉得很难过,但是我总是勇于接受,我总是勇于接受事实,我知道我总想离开我的环境。")
# 转换成列表
sonten1 = list(con1)
sonten2 = list(con2)
sonten3 = list(con3)
# 把列表转换成字符串 记住是空格连接 分词依据
c1 = ' '.join(sonten1)
c2 = ' '.join(sonten2)
c3 = ' '.join(sonten3)
return c1, c2, c3
def hanzivec():
"""
中文特征值化
:return: None
"""
return None
if __name__ == "__main__":
countvec()
运行结果为:使用空格去间隔中文,使其变成英文单词句段的形式,再导入特征化,使用词表+出现频次统计这种方式展示,就是一种特征值化的操作。
至于另一种方法,留待明天来学习,因为晚上要去上课了~
2.tf-df分析问题
11/17 补
无闹钟的7::59醒来,却又闭上眼睛不愿起从而晚来两个小时,而周三四五的早上六点半七点起来却总能很好的做到,还是没有一个明确的目标啊。目的地驱动我们前进,那么,没有规律的作息,应该用什么来修复呢?大概是一直向前的惯性吧!话不多说,开始今天的学习,昨天学习了分词及文本特征值化,其实毕业论文里的手动标注,就是做的这个工作,只是根据领域知识先处理生成了一张关联词表,然后根据命中率选取部分的特征。后面就是一些统计分析的工作了。
那么今天的练习又是在讲什么内容呢?第二种提取,先来看一下案例导入:
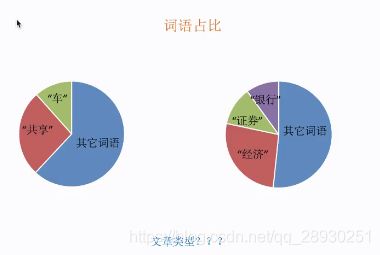 通过左侧图来分辨两篇词语占比的分析来确定文章类型;
通过左侧图来分辨两篇词语占比的分析来确定文章类型;
对于一些中性词:比如“所以,我们,明天”这些,就没有办法去判别出文章类型,那么如何解决呢?
引入咱们的tf idf,一般用朴素贝叶斯来解决:

TF所代表的就是词频,就是代表出现的次数,IDF则是逆文档频率(inverse document frequency),那么分析一下这个公式,log后跟的输入的数值越小,结果越小
th*idf 所代表的就是我们词的重要性程度,每篇文章又有不同的词,所对应的不同的重要性,就有一个重要性排序。
第二种特征抽取的方式就是TF-IDF:

对于我们来说,和上一种抽取方式类似,作用适用于评估一个字词对于文件集或语料库其中一份文件的重要程度,而使用的则是sklearn特征抽取中text工具里的TfidfVectorizer。

它的语法和上一种类似,实例来说明,
增加一个方法处理
def tfidvec():
"""
中文特征值化
:return: None
"""
c1,c2,c3 = cutword()
print(c1,c2,c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1,c2,c3])
print(tf.get_feature_names())
print(data.toarray())
return None老师的结果如下,我的结果在右图,和老师有区别的地方在于,我选择了一个《风雨哈佛路》影片的台词,老师选的是马云演讲的节选。
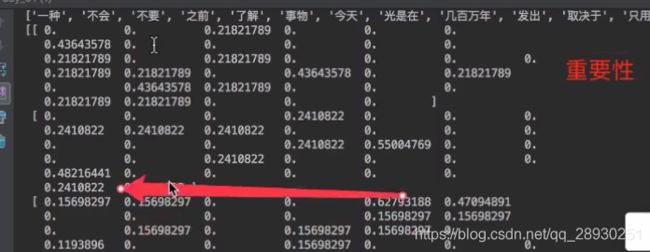

为什么会需要TF-IDF呢?是因为机器学习中有分类需要,而在日常学习中,一般第二种方法也用的多一些,因为值化的效果较好。

以上就是特征工程与文本特征提取的学习。
刻意练习,每日精进~冲啊