Pytorch 神经网络实践
目录
1. 定义神经网络结构 (2种方法)
2. 神经网络的输入与输出、损失函数定义
3. 优化器的定义、损失函数、更新网络参数
4. 五步过程全部代码
1. 定义神经网络结构 (2种方法)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
# 定义网络类
class Net1(nn.Module):
def __init__ (self):
super(Net1, self).__init__()
#定义第一层卷积层, 输入维度=1, 输出维度=6, kernel_size=3 卷积核大小3*3
self.conv1 = nn.Conv2d(1, 6, 3)
#定义第二层卷积层, 输入维度=6, 输出维度=16, 卷积核大小3*3
self.conv2 = nn.Conv2d(6, 16, 3)
#定义第三层全连接神经网络
self.fc1 = nn.Linear(16*6*6, 120) #576=16*6*6??
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) #输出是10分类
def forward(self, x):
#注意:任意卷积层后面要加激活层, 池化层
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) #(2, 2)??
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
#经过卷积层的处理后,张量要进入全连接层,进入前需要调整张量的形状
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
# Method 1_Net
net1 = Net1()
print(net1)
# Method 2_Net
#定义网络结构
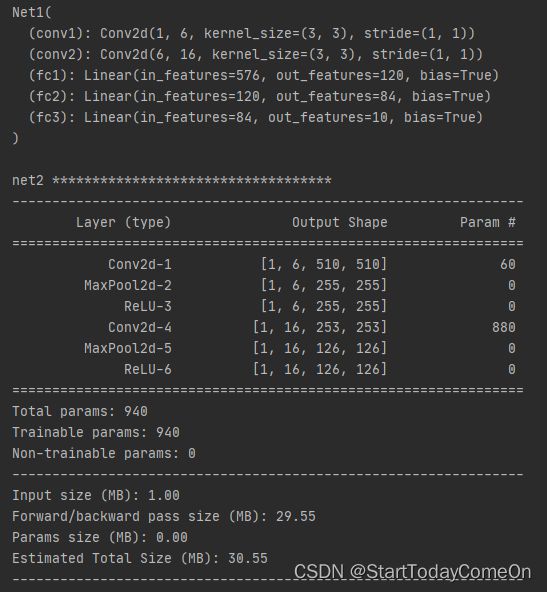
net2 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=3),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(6, 16, kernel_size=3),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True))
summary(net2, (1, 512, 512), batch_size=1, device="cpu")运行结果:
2. 神经网络的输入与输出、损失函数定义
# input size 4D tensor = [nSample, nChannels, Height, Width]; 3D转4D tensor input.unsqueeze(0)
input = torch.randn(1, 1, 32, 32)
out = net1(input)
# output size [10 class], so target size [10 class]
target = torch.randn(10)
target = target.view(1, -1)
criterion = nn.MSELoss() # 均方差
loss = criterion(out, target)
print('input:***', input)
print('out:***', out)
print('target:***', target)
print('loss:***', loss)
# 反向传播
# 关于方向传播的链条: 如果我们跟踪loss反向传播的方向,使用arad fn属性打印,将可以看到一张完整的计算图如下:
# input -> conv2d -> relu-> maxpoo12d-> conv2d-> relu-> maxpool2d-> view -> linear -> relu-> linear-> relu-> linear -> MSELOSS -> loss
# 当调用lossbackward()时,整张计算图将对loss进行自动求导,所有属性requires_grad=True的Tensors都将参与梯度求导的运算,并将梯度累加到Tensors中的grad属性中.
print(loss.grad_fn) # MSELOSS
print(loss.grad_fn.next_functions[0][0]) #Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) #ReLU运行结果:

3. 优化器的定义、损失函数、更新网络参数
import torch.optim as optim
optimizer = optim.SGD(net1.parameters(), lr=0.001, momentum=0.9)
net1.zero_grad() # pytorch 中首先要执行梯度清零的操作
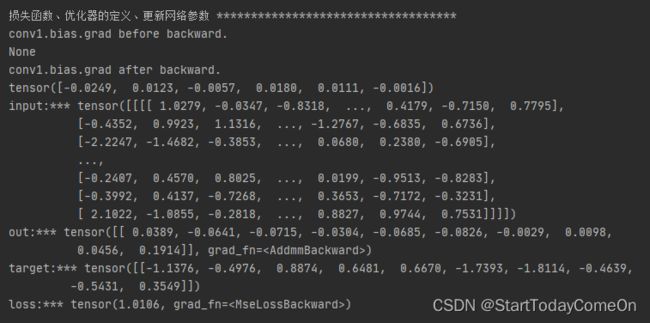
print('conv1.bias.grad before backward.')
print(net1.conv1.bias.grad)
input = torch.randn(1, 1, 32, 32)
target = torch.randn(10) # output size [10 class], so target size [10 class]
target = target.view(1, -1)
out = net1(input)
criterion = nn.MSELoss()
loss = criterion(out, target)
loss.backward() # 在pytorch中实现一次反向传播
print('conv1.bias.grad after backward.')
print(net1.conv1.bias.grad)
optimizer.step() # 参数的更新通过一行标准代码来执行
print('input:***', input)
print('out:***', out)
print('target:***', target)
print('loss:***', loss)运行结果:
4. 五步过程全部代码
# 1:使用torchvision下载CIFAR10数据集
# 2:定义卷积神经网络
# 3:定义损失函数
# 4:在训练集上训练模型
# 5:在测试集上测试模型
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
# 定义网络类
class Net(nn.Module):
def __init__ (self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) #定义第一层卷积层, 输入维度=3RGB, 输出维度=6, kernel_size=5 卷积核大小5*5
self.conv2 = nn.Conv2d(6, 16, 5) #定义第二层卷积层, 输入维度=6, 输出维度=16, 卷积核大小5*5
self.pool = nn.MaxPool2d(2, 2)
#定义第三层全连接神经网络
self.fc1 = nn.Linear(16*5*5, 120) #576=16(filter)*5*5(kernel size)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) #输出是10分类
def forward(self, x):
#注意:任意卷积层后面要加激活层, 池化层
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
#经过卷积层的处理后,张量要进入全连接层,进入前需要调整张量的形状
x = x.view(-1, 16*5*5) # conv2后 weight参数的个数
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 1:使用torchvision下载CIFAR10数据集
# 导入torchvision包来辅助下载数据集
# 下载数据集并对图片进行调整,因为torchvision数据集的输出是PILImage格式数据域在 [0, 1],将其转换为标准数据域[-1, 1]的张量格式.
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=0) # shuffle打乱,2个线程
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=1, shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# # 展示若干训练集的图片
# import matplotlib.pyplot as plt
# import numpy as np
# #构建展示图片的函数
# def imshow(img):
# img = img / 2 + 0.5
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
# #从数据迭代器中读取一张图片
# dataiter = iter(trainloader)
# images, labels = dataiter.next()
# # 展示图片
# imshow(torchvision.utils.make_grid(images))#打印标签label
# print(" ".join('%5s' % classes[labels[j]] for j in range(4)))
# 3:定义损失函数
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 4:在训练集上训练模型: 采用基于梯度下降的优化算法,都需要很多个轮次的迭代训练.
for epoch in range(2): #loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
#data中包含输入图像张量inputs,标签张量labels
inputs, labels = data
# 首先将优化器梯度归零
optimizer.zero_grad()
# 输入图像张量进网络,得到输出张量outputs
outputs = net(inputs)
#利用网络的输出outputs和标签labels计算损失值
loss=criterion(outputs, labels)
#反向传播+参数更新,是标准代码的标准流程
loss.backward()
optimizer.step()
# 打印轮次和损失值
running_loss += loss.item()
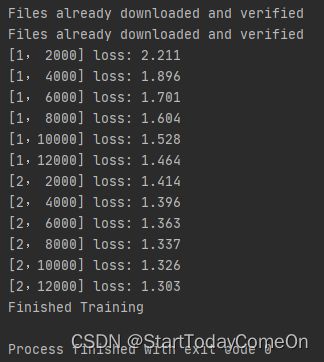
if (i+1) % 2000 == 0: # 每隔2000个图片打印一次
print('[%d,%5d] loss: %.3f' % (epoch+1, i+1, running_loss/2000))
running_loss = 0.0
print('Finished Training')
# 保存模型
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
# 5:在测试集上测试模型
PATH = './cifar_net.pth'
net = Net() # 实例化模型的类对象
net.load_state_dict(torch.load(PATH)) # 加载训练阶段保存的模型的状态字典
torch.no_grad()
for i, data in enumerate(testloader, 0):
input, label = data
out = net(input)
_, pred = torch.max(out, 1)
print('predict: %d target: %d' % (pred, label))
运行结果:cat plane horse truck


参考视频课程: P16-2.1Pytorch构建神经网络-第2步-损失函数_哔哩哔哩_bilibili