基于ANN和LSTM的时间序列预测
如何使用python开发一个基于Keras+ANN+LSTM的时间序列预测程序?
本文的目的是解释人工神经网络(ANN)和长期短期记忆递归神经网络(LSTM RNN),使您能够在现实生活中使用它们,并为预测时间序列构建最简单的ANN和LSTM递归神经网络。
数据
股票代码VIX是著名的芝加哥期权交易所波动率指数,它是衡量S&P500(标准普尔500)指数期权并预示股市波动预期的一种流行指标。 它由芝加哥期权交易所(CBOE)实时计算和传播。
VOLATILITY S&P500指数数据集可以从这里下载,我们设置日期范围从2011年2月11日到2019年2月11日。我们的目标是使用ANN和LSTM预测VOLATILITY S&P500波动率。
首先,我们需要导入以下库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import r2_score
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import EarlyStopping
from keras.optimizers import Adam
from keras.layers import LSTM
%matplotlib inline然后将数据加载到Pandas dataframe中,并且查看前几行数据:
df = pd.read_csv(path+"vix_2011_2019.csv")
df.head()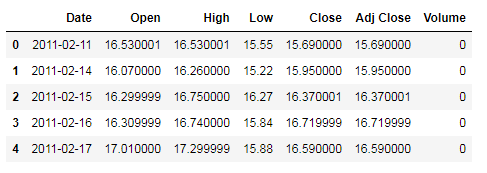
我们要删除不需要的列,然后将“Date”列转换为datetime数据类型,并将“Date”列设置为index。
df.drop(['Open', 'High', 'Low', 'Close', 'Volume'], axis=1, inplace=True)
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index(['Date'], drop=True)
df.head(10)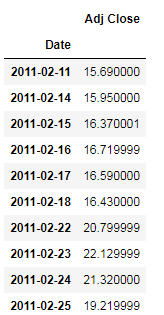
接下来我们根据date画出adj close的趋势图
plt.figure(figsize=(10, 6))
df['Adj Close'].plot();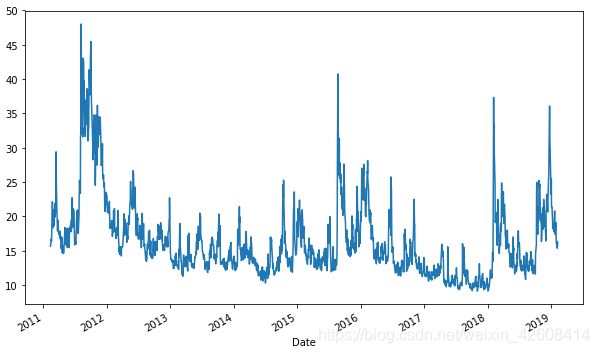
从图中可以看出adj close一直呈现锯齿形的波动,非常不稳定。既没有上升趋势也没有下降趋势。
接下来我们通过拆分数据来创建训练集和测试集,我们以2018-01-01为界,2018-01-01之前的数据拆分为训练集,2018-01-01之后的数据拆分为测试集。并将训练集和测试集可视化。
split_date = pd.Timestamp('2018-01-01')
df = df['Adj Close']
train = df.loc[:split_date]
test = df.loc[split_date:]
plt.figure(figsize=(10, 6))
ax = train.plot()
test.plot(ax=ax)
plt.legend(['train', 'test']);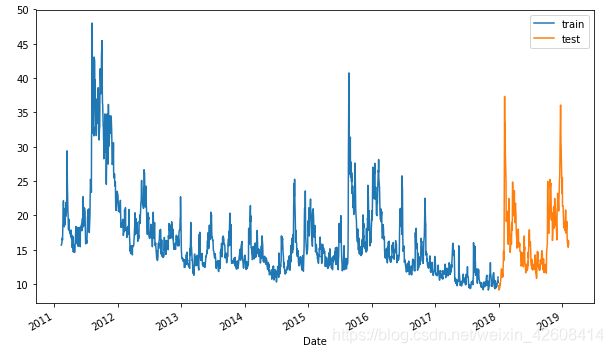
数据拆分完成以后我们要对数据进行归一化处理,将数据值缩放到[-1,1]范围内。
scaler = MinMaxScaler(feature_range=(-1, 1))
train_sc = scaler.fit_transform(train.values.reshape(-1,1))
test_sc = scaler.transform(test.values.reshape(-1,1))通过数据平移的方式提取数据标签,这里要说明一下的是时间序列数据(如股票数据)本身不带有标签,要获取数据标签可以通过平移数据的方式如下图所示:
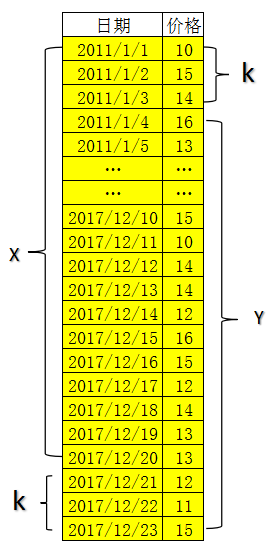
假如数据集的总量是N,我想预测未来k天的价格,那么我的训练数据就是数据集的前N-K条数据(如上图中的X),标签数据就是数据集的后N-K条数据(如上图中的Y),在本例中我们要预测后一天的数据,K=1。
predict_days = 1
X_train = train_sc[:-predict_days]
y_train = train_sc[predict_days:]
X_test = test_sc[:-predict_days]
y_test = test_sc[predict_days:]为时间序列数据构建一个简单的神经网络(ANN)
- 创建Sequential模型
- 通过.add()方法添加层
- 将input_dim参数传递给第一层
- 设置激活函数为Relu
- 设置损失函数为均方误差mean_squared_error,优化器为adam
- 当监控到损失loss不再减少时停止训练
- patience=2表示损失没有改善的训练周期数,在这之后将停止训练
- ANN将训练100个周期,batch_size设置为1
- 配置完上述参数后,编译模型
nn_model = Sequential()
nn_model.add(Dense(12, input_dim=1, activation='relu'))
nn_model.add(Dense(1))
nn_model.summary()
nn_model.compile(loss='mean_squared_error', optimizer='adam')
early_stop = EarlyStopping(monitor='loss', patience=2, verbose=1)
history = nn_model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1, callbacks=[early_stop], shuffle=False)我们没有输出所有的训练周期,我只输出最后一个训练周期,当训练到第22个周期时损失不在降低,训练结束。
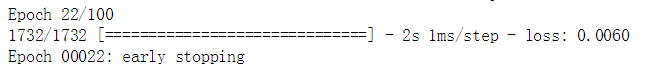
y_pred_test_nn = nn_model.predict(X_test)
y_train_pred_nn = nn_model.predict(X_train)
print("The R2 score on the Train set is:\t{:0.3f}".format(r2_score(y_train, y_train_pred_nn)))
print("The R2 score on the Test set is:\t{:0.3f}".format(r2_score(y_test, y_pred_test_nn)))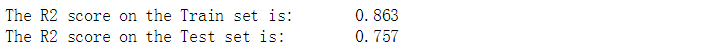
LSTM
在构造LSTM时,我们将使用pandas shift函数将整列往后移动1个位置.以便得到训练数据和标签数据.然后我们需要将所有训练数据和标签数据转换成3维张量。
train_sc_df = pd.DataFrame(train_sc, columns=['Y'], index=train.index)
test_sc_df = pd.DataFrame(test_sc, columns=['Y'], index=test.index)
for s in range(1,2):
train_sc_df['X_{}'.format(s)] = train_sc_df['Y'].shift(s)
test_sc_df['X_{}'.format(s)] = test_sc_df['Y'].shift(s)
X_train = train_sc_df.dropna().drop('Y', axis=1)
y_train = train_sc_df.dropna().drop('X_1', axis=1)
X_test = test_sc_df.dropna().drop('Y', axis=1)
y_test = test_sc_df.dropna().drop('X_1', axis=1)
X_train = X_train.as_matrix()
y_train = y_train.as_matrix()
X_test = X_test.as_matrix()
y_test = y_test.as_matrix()
X_train_lmse = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test_lmse = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
print('Train shape: ', X_train_lmse.shape)
print('Test shape: ', X_test_lmse.shape)
LSTM网络创建和模型编译与前面的ANN创建过程类似
- LSTM有1个输入层
- 1个带有7个LSTM神经元的隐藏层
- 一个进行单值预测的输出层
- LSTM神经元的激活函数为relu
- 设置早期停止当损失值不再改善时
- 模型训练100个周期,bach_size=1
lstm_model = Sequential()
lstm_model.add(LSTM(7, input_shape=(1, X_train_lmse.shape[1]), activation='relu', kernel_initializer='lecun_uniform', return_sequences=False))
lstm_model.add(Dense(1))
lstm_model.compile(loss='mean_squared_error', optimizer='adam')
early_stop = EarlyStopping(monitor='loss', patience=2, verbose=1)
history_lstm_model = lstm_model.fit(X_train_lmse, y_train, epochs=100, batch_size=1, verbose=1, shuffle=False, callbacks=[early_stop])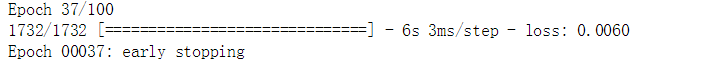
从上图中的输出结果可以看出模型训练到了第37个周期后停止训练,损失不再发生变化
下面开始评估我们的模型:
y_pred_test_lstm = lstm_model.predict(X_test_lmse)
y_train_pred_lstm = lstm_model.predict(X_train_lmse)
print("The R2 score on the Train set is:\t{:0.3f}".format(r2_score(y_train, y_train_pred_lstm)))
print("The R2 score on the Test set is:\t{:0.3f}".format(r2_score(y_test, y_pred_test_lstm)))
LSTM的训练集R^2和测试集的R^2均高于ANN模型
模型比较
我们比较两个模型在测试集上的均方误差MSE
nn_test_mse = nn_model.evaluate(X_test, y_test, batch_size=1)
lstm_test_mse = lstm_model.evaluate(X_test_lmse, y_test, batch_size=1)
print('NN: %f'%nn_test_mse)
print('LSTM: %f'%lstm_test_mse)
预测效果
plt.figure(figsize=(10, 6))
plt.plot(y_test, label='True')
plt.plot(y_pred_test_nn, label='NN')
plt.title("ANN's Prediction")
plt.xlabel('Observation')
plt.ylabel('Adj Close Scaled')
plt.legend()
plt.show();
plt.figure(figsize=(10, 6))
plt.plot(y_test, label='True')
plt.plot(y_pred_test_lstm, label='LSTM')
plt.title("LSTM's Prediction")
plt.xlabel('Observation')
plt.ylabel('Adj Close scaled')
plt.legend()
plt.show();
最后,总结一下,在此文中我们学习了如何在Python中利用keras搭建ANN和LSTM的神经网络,并利用他们去预测时间序列数据,并且我们也学会了如何从时间序列数据中提取训练数据和标签数据。您可以在这下载本文的完整代码!