1.基于深度学习的知识追踪研究进展_刘铁园
基于深度学习的知识追踪研究进展_刘铁园
1.知识追踪改进方向
- 针对可解释问题的改进
- 针对长期依赖问题的改进
- 针对缺少学习特征问题的改进
2.基于深度学习的知识追踪 DLKT
2.1 符号定义
2.2 DLKT基本模型
DKT以RNN为基础结构,RNN是一种具有记忆性的序列模型,序列结构使其符合学习中的近因效应并保留了学习轨迹信息。这种特性使 RNN(LSTM和门控循环网络)等变体成为了 DLKT领域使用最广泛的模型。
在 DKT中,RNN的隐藏状态ht被解释为学生的知识状态,ht被进一步通过 一个Sigmoid激活的线性层得到预测结果yt。yt的长度等于题目数量,其每个元素代表学生正确回答对应问题的预测概率.具体的计算过程为:
h t = t a n h ( W h x x t + W h h h t − 1 + b h ) , y t = S i g m o i d ( W y h h t + b y ) h_{t}=tanh(W_{hx}x_{t}+W_{hh}h_{t-1}+b_{h}),\newline y_{t}=Sigmoid(W_{yh}h{t}+by) ht=tanh(Whxxt+Whhht−1+bh),yt=Sigmoid(Wyhht+by)
3.DKT的改进方法
DKT存在问题:隐藏状态ht在本质上很难被解释为知识状态,而且 DKT模型没有对知识交互进行深入分析,导致其可解释性很差.

3.1 针对可解释性问题的改进
3.1.1 Ante-hoc可解释性方法
Ante-hoc可解释性指模型本身内置可解释性。在深度学习中,一种有效的可解释性模块就是注意力机制.此外,Ante-hoc可解释性还可以
通过采用结构简单、易于理解的自解释模型实现。
1)引入注意力机制
① A-DKT(attention-DKT)
使用了 Jaccard系数计算 KC之间的注意力权重.设ka,kb为不同的 KC,两者间的权重值为
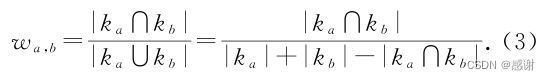
在时刻t,计算当前 KC与之前所有 KC的注意力权重,然后相加,得到总的注意力值 wt :

3.1.2 注意力值
最后,结合 LSTM与注意力值得到预测结果:

② DKVMN(dynamic key- value memory network)
DKVMN使用矩阵 Mkey存储 KC,Mkey的每 一列代表一个 KC;使用矩阵 Mvalue存储知识状态,Mvalue的每一列表示 Mkey中对应 KC的掌握程度
引入注意力机制的模型还有:③ DKVMN-CA(concept-aware DKVMN),④ EERNN(exercise-enhanced RNN)
⑤ EKT(exercise-awareKT),见原文。
2)自解释模型
① KQN(knowledge query network)
KQN模型:向量点积来模拟知识状态与 KC的相互作用
假设知识状态与 KC都为2维向量,如图5所示,在知识状态由v2转变到v3的过程中,学生对 KCk1的掌握程度由v2*
k1=1增长到了v3*k1=2.这种向量化的表示与运算使 KQN具有直观性和可解释性.
② Deep-IRT(deep item response theory)
3.1.2 Post-hoc可解释性方法
Post-hoc可解释性也称事后可解释性,发生在模型训练之后,旨在利用解释方法或构建解释模型,解释学习模型的工作机制、决策行为和决策依据
1)LRP(layer-wise relevance propagation)
Lu等人应用分层相关性传播方法,通过将相关性从模型的输出层反向传播到输入层,来解释基于 RNN的 DLKT模型.**LRP的核心是利用反向传播将高层的相关性分值递归地传播到低层直至传播到输入层.**具体来说,将 RNN不同单元之间的连接分为加权连接和乘法连接并分别定义两者相关性的传播.如图6所示,通过计算2种类型连接的反向传播相关性,就可以对基于 RNN的 DLKT模型进行解释.
2)不确定性评估
通过为模型的每一个预测值y提供一个不确定性评分u(由模型输出),以减轻预测过程中的不透明性,增加模型的可解释性.不缺定性分为2种:
①随机不确定性(或数据不确定性)
.由随机事
件或观测中的固有噪声导致.由于神经网络的固定权值,因此输入x的噪声会传播给输出y.用D表示噪声,则模型的输出为
y ^ = y t D + σ D ϵ , ϵ D ∽ N ( 0 , I ) \hat{y}=y^{D}_{t}+\sigma^{D}\epsilon, \epsilon_{D}\backsim N(0,I) y^=ytD+σDϵ,ϵD∽N(0,I)
其中,σD表示yDt的偏差值,由模型输出.由于 y ^ \hat{y} y^的期望很难确定,因此使用蒙特卡洛方法近似,最大化期望对数似然相当于最小化二元交叉熵,最终的损失函数为
L = L B C E ( y , y ^ ) + α L 1 + β L 2 L=L_{BCE}(y,\hat{y})+\alpha L_{1}+\beta L_{2} L=LBCE(y,y^)+αL1+βL2
其中,L1,L2均为优化计算的正则项,由超参数α,β平衡权重
②认知不确定性(或模型不确定性)
由数据不足导致,这种不确定性可以通过使用更多的数据来降低.针对深度学习模型的不确定性建模的贝叶斯方法是假设这些模型的权重不是固定的,而是从分布中取样的.最后的预测是通过综合所有可能的权重得到的.对于分类任务,预测正确的概率可以近似为
P c = 1 S ∑ t = t 1 t T S o f t m a x ( y t D ) P_{c}=\frac{1}{S}\sum_{t=t_{1}}^{t^{T}} {Softmax(y_{t}^{D})} Pc=S1t=t1∑tTSoftmax(ytD)
其中,c表示预测正确的题目,S表示取样总数。不确定性可以用熵概括:
H ( p c ) = − ∑ c p c × log p c H(p_{c})=-\sum_{c}{}{p_{c}}\times \log p_{c} H(pc)=−c∑pc×logpc
####3.2 针对长期依赖问题的改进
3.2.1 基于 LSTM的扩展模型
1)Hop-LSTM
Hop-LSTM是一种改进的 LSTM,可以根据隐藏单元之间的相关性进行跳跃连接。LSTM单元依据顺序关系跳跃连接
2)NKT (neural KT)
RNN的层层叠加可以减轻 LSTM中长期依赖关系的学习困难。基于这个结论,Sha等人提出了 NKT模型,设计了一种2层堆叠的LSTM,并使用残差连接减小训练难度。实验证明,这种叠加的 LSTM可以有效扩大序列学习的容量
3.2.2 基于 Transformer的模型
自注意力机制(self-attention mechanism)是注意力机制的 一个变体。根据其提出了 Transformer模型。由于Transformer模型不依赖 RNN框架,因此不存在长期依赖问题。
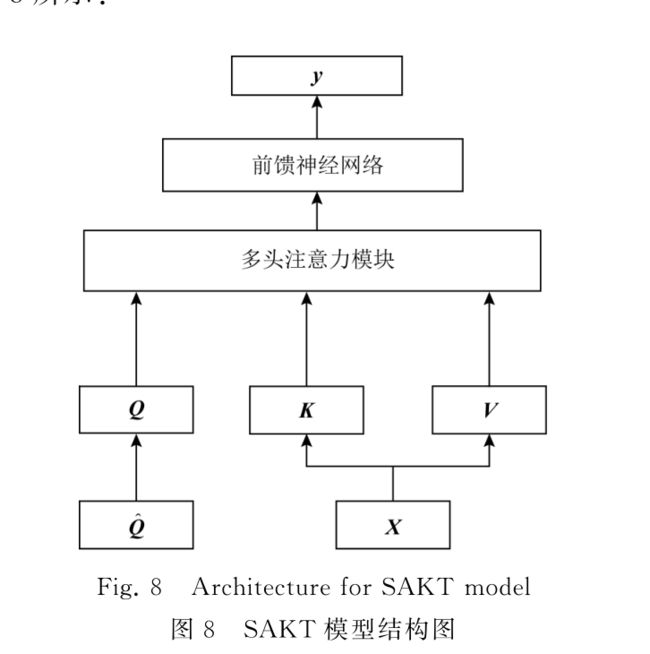
1)SAKT (self attention KT)
在 Transformer中,计算注意力所使用的 Q,K,V这3个参数由输入序列乘以不同的权重矩阵所得.而在 SAKT中,Q和K,V分别由题目的嵌入
序列和交互的嵌入序列投影得到.
Q = Q ^ W Q , K = X ^ W K , V = X ^ W V Q=\hat{Q}W^{Q},K=\hat{X}W^{K},V=\hat{X}W^{V} Q=Q^WQ,K=X^WK,V=X^WV
其中, Q ^ \hat{Q} Q^为题目嵌入矩阵, X ^ = X ⨁ P \hat{X}=X \bigoplus P X^=X⨁P,由交互嵌入矩阵 X X X与位置嵌入矩阵 P P P连接得到.SAKT不是时序模型,所以需要位置嵌入以保留输入序列的位置信息.注意力被计算h次,使得模型能够在不同的表示子空间中学习相关信息,并将h次的结果连接,称为多头注意力(multiGheadattention,MHA):
H M H A = [ H 1 ⨁ H 2 ⨁ ⋯ ⨁ H h ] W M H A , H i = A t t e n t i o n ( Q i , K i , V i ) = S o f t m a x ( Q i K i T d ) H_{MHA}=[H_{1}\bigoplus H_{2}\bigoplus \cdots \bigoplus H_{h}]W^{MHA}, \newline H_{i}=Attention(Q_{i},K_{i},V_{i})=Softmax\bigg(\frac{Q_{i}K^{T}_{i}}{\sqrt{d}} \bigg) HMHA=[H1⨁H2⨁⋯⨁Hh]WMHA,Hi=Attention(Qi,Ki,Vi)=Softmax(dQiKiT)
其中,d为嵌入向量的维度.最终,通过 一个前馈神经网络层和 一个Sigmoid激活的线性层得到预测结果:
F = R e L U ( H M H A W 1 + b 1 ) W 2 + b 2 , y t = S i g m o i d ( F t W + b ) . F=ReLU(H_{MHA}W_{1}+b_{1})W_{2}+b_{2}, \newline y_{t}=Sigmoid(F_{t}W+b). F=ReLU(HMHAW1+b1)W2+b2,yt=Sigmoid(FtW+b).
2)SAINT(separated self-attention neural KT)
,SAINT主要由编码器 (encoder)和解码器(decoder)两部分组成.编码器的输入为题目的嵌入矩阵 Q ^ = ( q 1 , q 2 , ⋯ , q t ) \hat{Q}=(q_{1},q_{2},\cdots,q_{t}) Q^=(q1,q2,⋯,qt),q由题目嵌入和位置嵌入连接得到,解码器以编码器的输出以及回答嵌入矩阵 A = ( a 1 , a 2 , ⋯ , a t ) A=(a_{1},a_{2},\cdots,a_{t}) A=(a1,a2,⋯,at)为输入.编码器与解码器都是多头注意力模块和前馈神经网络的组合,不同之处在于解码器叠加了 2个注意力模块,以进一步捕捉题目与回答之间的复杂关系.
3)DKT+Transformer
Pu等人改进了 Transformer的结构,在其中加入了题目的结构信息和答题的时间信息.改进后的 Transformer模型结构与 SAINT大致相同,
都由编码器和解码器组成,主要区别在于自注意力的计算.
F E = E n c o d e r ( X ^ , t ˊ ) , F D = D e c o d e r ( Q ^ , t ˊ , F E ) , F_{E}=Encoder(\hat{X},\acute{t}),\newline F_{D}=Decoder(\hat{Q},\acute{t},F_{E}), FE=Encoder(X^,tˊ),FD=Decoder(Q^,tˊ,FE),
其中, t ˊ = ( t 1 , t 2 , ⋯ , t n ) \acute{t}=(t_{1},t_{2},\cdots,t_{n}) tˊ=(t1,t2,⋯,tn)为时间戳信息,注意力机制的计算为:
H i j = Q i K i + b × ( t j − t i ) d V i H_{ij}=\frac{Q_{i}K_{i}+b\times(t_{j}-t_{i})}{\sqrt{d}}V_{i} Hij=dQiKi+b×(tj−ti)Vi
其中, b × ( t j − t i ) b\times(t_{j}-t_{i}) b×(tj−ti)表示时间间隔偏置,目的是通过 x j x_{j} xj与 x i x_{i} xi之间的间隔时间来调整注意力权重,在计算时,使i≤j以保证不会学习后面时间的权重.
3.3 针对缺少学习特征问题的改进
3.3.1 嵌入方式
嵌入方式指将学习特征添加到模型的输入嵌入向量中,或作为额外的计算因子嵌入到计算过程中的方式
1)DKT-FE(DKT with feature engineering)
采用特征工程(featureengineering)的方式,使用人工分析选择特征并离散化
2)DKT-DT(DKT with decisiontrees)
DKTGDT模型使用了分类与回归树 (classification andregression trees,CART)对 one-hot编码的额外特征(标题、答题次数、答题时 间)ft进行预处理.
3)DKVMN-DT(DKVMN with decision trees)
基于 DKVMN模型添加特征,提出了 DKVMN-DT(DKVMN with ecision trees)模型.其使用了与 DKT-DT相同的方法,不再赘述.
4)DKT+forgetting
在 DKT模型中加入了遗忘特征
5)EERNN(exercise enhanced RNN)
Su等人关注到题目文本描述中包含的丰富信息,并使用双向 LSTM提取文本描述的语义特征
6)AKT(adaptable KT)
Cheng等人在其模型 AKT中使用了与EERNN模型相同的文本特征提取方法,并进一步从提出的语义特征中挖掘出学生的猜测(掌握了KC却没有答对题目)和失误(没掌握 KC却答对了题目)行为.
7)EHFKT(exercise hierarchical feature enhanced KT)
Tong等人在其模型 EHFKT中使用了BERT从题目的文本描述中提取了知识分布、语义特征和题目难度等信息
8)LSTMCQ(LSTM based contextualized Q-matrix)
Huo等人在其模型 LSTMCQ中提出了 一种带有上下文信息的题目编码方法
9) DKT-DSC(DKT with dynamic student classification)/DSCMN(dynamic student classification monmemory networks)
提出了 一种根据能力分类学生,并将分类后的学生分组训练的方法,相当于在模型的输入中隐式地嵌入了学生能力信息.应用于
DKT与 DKVMN,分别称为 DKT-DSC和 DSCMN.
3.3.2 损失函数限制
损失函数限制指将额外的学习特征作为限制条件,编码到损失函数中的方式.
1)Colearn
Chaudhry等人关注到了学习交互系统中学生的提示获取 (hint-taking)行为,并将其作为知识追踪的子任务,提出了 一个多任务模型 Colearn
2)PDKT-C (prerequisite-driven DKT with constraint modeling)
Chen等人将 KC之间的先后序关系引入了知识追踪模型,提出了PDKT-C模型
3)DKT-S(DKT with side information)
Wang等人[70]提出了 DKTS模型,通过在加入一个用来捕获题目之间关系的 Side Layer,将题目之间的关系纳入学生知识状态建模.
4)DHKT(deep hierarchical KT)
Wang等人关注到了题目之间的层次结构关系,提出了 DHKT模型。其通过 KC嵌入和题目嵌入之间的内积铰链损失(hingeloss)来对层次关系建模
5)qDKT(question-centric DKT)
包含同样 KC的题目之间存在着差异,解决这些题目对知识状态的贡献也是不同的
3.3.3 新结构
新结构指通过使用新的模型结构,将额外学习特征纳入模型计算过程中的方式
1)GKT(graph based KT)
Nakagawa等人提出了 GKT模型,通过将KC间的关系表示为 1个有向图,知识追踪任务转化为了图神经网络 (graph neural network,GNN)中的时间序列节点级分类问题.
2)CKT ( convolutional KT)
Shen等人]提出了 CKT模型,率先在知识追踪领域使用了卷积神经网络
3) SKVMN (sequential keyGvalue memory networks)
Abdelrahman等人在 SKVMN模型中使用三角隶属度函数(triangular membership function)来计算 KC之间的相关性
4)DeepFM(deep factorization machines)
Vie率先将 DeepFM算法应用到知识追踪领域,其优势在于对稀疏特征的添加与利用
5)KTM-DLF(knowledge tracing machine by modeling cognitive item difficulty and learning and forgetting)
Gan等人提出了一种结合学习者能力、认知项目难度、学习和遗忘等特征的建模方法,并使用 KTM在高维中嵌入这些特征,所提出的模型称为DKM-DLF
6)DynEMb
Xu等人结合了矩阵分解和 RNN,提出了DynEmb模型,用矩阵分解做嵌入,用 RNN对学习过程建模
7)BDKT(Bayesian neural network DKT)
Li等人提出了 BDKT模型,使用贝叶斯神经网络来对丰富的学习特征建模
8)Q-Embedding
Nakagawa等人提出了无需 KC标签信息的Q-Embedding模型,可以自动学习题目与 KC的嵌入.
4 DLKT模型对比与分析
4.1 数据集介绍
