【无标题】RADICAL ANALYSIS NETWORK FOR ZERO-SHOT LEARNING IN PRINTED CHINESE CHARACTER RECOGNITION
印刷体汉字识别中零次学习的部件分析网络
(RADICAL ANALYSIS NETWORK FOR ZERO-SHOT LEARNING IN PRINTED CHINESE CHARACTER RECOGNITION)
摘要
汉字有一套庞大的汉字类别,超过20000个,随着越来越多的新奇汉字不断被创造出来,这个数字还在不断增加。然而,这些巨大的字符可以被分解成一个大约500个基本和结构部件的紧凑集合。本文介绍了一种新的部件分析网络(RAN),通过识别部件并分析其中的二维空间结构来识别印刷体汉字。我们所提出的RAN首先通过使用卷积神经网络作为编码器从输入中提取视觉特征。然后采用基于循环神经网络的解码器,通过空间注意机制检测部件和二维结构来生成汉字序列。将汉字视为部件而非单个字符类的组合的方式大大减少了词汇的大小,并使RAN能够识别未见过的汉字类,即零次学习。
1.引言
汉字的识别是一个复杂的问题,因为存在大量的汉字类别(超过20000个)、不断增加的新汉字(例如成龙创造的“Duang”字)和复杂的内部结构。然而,大多数传统方法[1]只能识别大约4000个常用字符,而无法处理未看到的或新创建的字符。
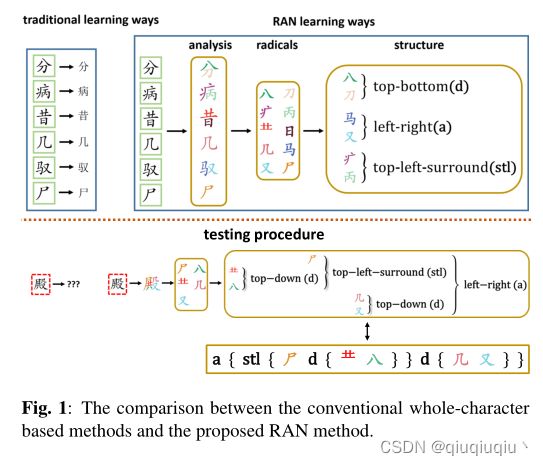
此外,每个字符样本被视为一个整体,而不考虑不同字符之间的相似性和内部结构。众所周知,所有汉字都是由称为部件的基本结构组成部分组成的。只有大约500个部首[2]足以描述20000多个汉字。因此,将汉字分解为部首并将其空间结构描述为用于识别的序列是一种直观的方法。在本文中,我们提出了一种新的部件分析网络(RAN)来生成用于汉字识别的序列。与传统方法相比,RAN具有两个显著的特点:1)与字符词汇相比,部件词汇的大小大大减小;2) 这是一种新颖的汉字零次学习,它可以在识别阶段识别看不见的汉字,因为相应的部件和空间关系是在训练阶段从其他看到的汉字中学习的。图1显示了识别汉字的传统方法和RAN之间的清晰对比。在传统方法中,分类器将字符输入作为单个图片,并尝试学习输入图片和预定义类之间的映射。如果测试字符类在训练样本中不可见,如图1中红色虚线矩形中的字符,则将被错误分类。而RAN试图模仿中国学习者识别汉字的方式。例如,在要求孩子记住和识别汉字之前,汉语老师首先教他们识别部件,理解部件的含义,并掌握它们之间可能的空间结构。这种学习方式更具生成性,有助于提高学生学习如此多汉字的记忆能力,这在RAN中得到了完美的应用。如图1右上部分的示例所示,六个训练样本包含十个不同的部件,并显示出上下、左右和左上环绕的空间结构。当在测试过程中遇到不可见的字符时,RAN仍然可以生成该字符的相应序列(即图1的右下矩形),因为它已经学习了基本的部件和结构。从技术上讲,巨大的汉字以及新创造的汉字都可以通过在训练阶段学习的一组紧凑的部件和空间结构来识别。
在过去的几十年里,人们为基于部件的汉字识别做出了很多努力。[3] 将字符过度分段为候选部件,只能处理左右结构。[4] 首先检测单独的部件,然后采用分级部件匹配方法来识别汉字。最近,[5]还尝试使用具有多标记学习的深度残差网络来检测位置依赖性自由基。通常,这些方法在处理部首之间的复杂2D结构时有困难,并且不专注于识别不可见的字符类。
关于网络架构,所提出的RAN是[6]中基于注意力的编码器模型的改进版本。我们使用卷积神经网络(CNN)[7]作为编码器,从输入的汉字中提取高级视觉特征。解码器是具有门控递归单元(GRU)[8]的循环神经网络,其将高级视觉特征转换为输出字符序列。我们采用解码器中构建的基于覆盖的空间注意力模型来同时检测部首和内部二维结构。基于GRU的解码器也表现得像一个潜在的语言模型,目的是在成功检测到部首和结构后掌握编写汉字序列的规则。本研究的主要贡献总结如下:
•我们提出RAN用于汉字识别的零次学习,解决了处理不可见或新创建的字符的问题。
•我们描述了如何根据对汉语部首和结构的详细分析为汉字加上序列。
•我们通过实验演示了RAN在识别可见/不可见汉字方面的表现,并通过注意力可视化展示了其效率。
2.部件分析
与庞大的汉字类别相比,部件类别的数量相当有限。中国国家语言文字委员会发布的GB13000.1标准[2]规定,20902个汉字由560个不同的部件组成。
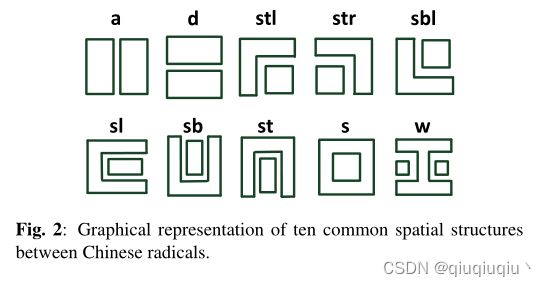
遵循这种cjk编码方式 ,我们将汉字分解为相应的序列。关于部件之间的空间结构,我们在图2中显示了十种常见的结构,其中“a”表示左右结构,“d”表示上下结构,“stl”表示左上环绕结构,“str”表示右上环绕结构、“sbl”表示右下环绕结构,“sb”表示底部环绕结构,“st”表示顶部环绕结构,”s”表示环绕结构,而“w”表示内部结构。
我们使用一对大括号来约束字符标题中的单个结构。以“stl”为例,其标题为“stl{部件-1部件-2}”。通常,像上面提到的常见例子一样,一个结构由两个不同的部件描述。然而,对于一些独特的结构,它们用三个或更多的部件来描述。
3.RAN的网络架构
基于注意力的编码器-解码器模型首先学习将输入编码为高级表示。然后通过对高级表示进行加权求和来生成固定长度的上下文向量。注意力用作加权系数,以便它可以从整个输入中选择最相关的部分来计算上下文向量。最后,解码器使用该上下文向量逐字生成可变长度输出序列。该框架已广泛应用于许多应用,包括机器翻译[9]、图像字幕[10,11]、视频处理[12]和手写识别[13-15]。
3.1.CNN编码器
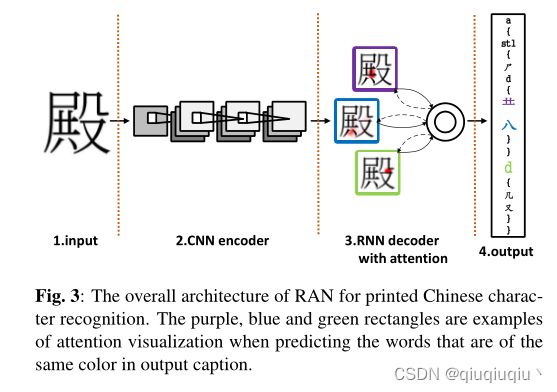
在本文中,我们评估了印刷汉字的RAN。输入是灰度图像,像素值在0和1之间归一化。RAN的总体架构如图3所示。我们使用CNN作为编码器,这被证明是从图像中提取高质量视觉特征的强大模型。
我们没有在完全连接的层之后提取特征,而是使用了一个仅包含卷积、池化和激活层的CNN框架,称为完全卷积神经网络.
这是有意义的,因为后续解码器可以通过从所有提取的视觉特征中选择特定部分来选择性地关注图像的某些像素。
假设CNN编码器提取由尺寸为H×W×D的三维阵列表示的高级视觉表示,则CNN输出是L个元素的可变长度网格,L=H×W。这些元素中的每一个都是对应于图像的局部区域的D维注释向量。
![]()
5.结论和未来工作
在本文中,我们介绍了一种用于汉字识别零次学习的新模型——部件分析网络。我们从实验结果表明,RAN能够通过空间注意力的可视化来识别不可见的汉字,并且在可见汉字识别方面优于传统的基于全字符的方法。在未来的工作中,我们计划研究RAN识别手写汉字或自然场景中汉字的能力。我们还将探讨结构/部件和汉字之间的映射关系在提高RAN性能中的作用