【测试记录】基于pdf论文提取论文doi—pdf2doi包的安装与使用
1. pdf2doi下载与安装
2. 安装问题记录
3. pdf2doi的使用
1. pdf2doi简介与下载安装
pdf2doi是一个 Python 库/命令行工具,用于从出版物的 .pdf 文件(或从包含多个 .pdf 文件的文件夹)自动提取 DOI 或其他标识符(例如 arXiv ID),并检索书目信息。它利用多种方法(详细说明见下文)来查找 pdf 文件的有效标识符,并通过对公共档案(例如http://dx.doi.org)的 Web 查询验证任何结果。验证过程还返回原始 bibtex 信息,可用于进一步处理,例如生成 BibTeX 条目(pdf2bib)或自动重命名 pdf 文件(pdf-renamer)。
pdf2doi 可以从命令行使用,也可以在python 脚本中使用,或者仅适用于 Windows,直接从pdf 文件或文件夹的右键单击上下文菜单中使用。
自动将 DOI 或其他标识符(例如 arXiv ID)关联到 pdf 文件可能是非常容易或非常困难(有时几乎不可能)的任务,这取决于在制作文件时投入了多少注意力。在最简单的情况下(通常适用于最近的出版物),查看文件元数据就足够了。对于较旧的出版物,标识符通常可以在 pdf 文本中找到,并且可以借助正则表达式进行提取。在最不幸的情况下,剩下的唯一方法是搜索出版物的一些详细信息(例如标题或文本的部分内容),并希望在第一个结果中包含一个有效的标识符。
pdf2doi依次应用所有这些方法(从最简单的方法开始),直到找到并验证有效标识符。具体来说,对于给定的 .pdf 文件,它将按顺序,
1. 查看 .pdf 文件的元数据(通过PyPDF2库提取)并检查其中是否包含与 DOI 或 arXiv ID 模式匹配的字符串。优先考虑标签中包含单词“doi”的元数据。
2. 检查 pdf 文件的名称是否包含与 DOI 或 arXiv ID 的模式匹配的任何子字符串。
3. 扫描 .pdf 文件中的文本,并检查与 DOI 或 arXiv ID 模式匹配的任何字符串。使用库PyPDF2和textract提取文本。
4. 尝试找到可能的出版物标题。在当前版本中,可能的标题通过库pdftitle和文件名来识别。对于每个可能的标题,都会执行 google 搜索,并扫描第一个结果的纯文本以查找有效标识符。
5. 作为最后的绝望尝试,pdf 文本的前 N=1000 个字符用作 google 搜索的查询。扫描第一个结果的纯文本以查找有效标识符。
每当找到潜在标识符时,也会通过查询相关网站(例如,对于 DOI 的http://dx.doi.org和对于 arxiv ID的http://export.arxiv.org )进行验证。当标识符有效时,此验证过程还会返回原始BibTeX信息。
当使用不同于第一个方法的任何方法找到有效标识符时,该标识符也存储在 pdf 文件的元数据中。这样,以后对同一文件的查找将能够使用第一种方法提取标识符,从而加快搜索速度(用户可以禁用此功能,以防不希望对 pdf 文件进行编辑)。
库远非完美。通常,特别是对于旧出版物,当前实施的方法都不起作用。有时可能会提取错误的 DOI:例如,如果另一篇论文的 DOI 出现在 pdf 文本中并且它出现在正确的 DOI 之前,则可能会发生这种情况。一个快速而肮脏的解决方案是手动查找标识符,然后将其添加到文件的元数据中,使用此处显示的方法(来自 python 控制台)或此处(来自命令行)。通过这种方式,pdf2doi在将来分析同一文件时将始终检索正确的 DOI,这在pdf2doi 用于自动化大量文件的书目程序时非常有用(例如,通过pdf2bib或 pdf 重命名器)。
目前,仅支持2007 年 4 月 1 日之后使用的 arXiv 标识符格式。
pip install pdf2doipdf2doi 链接地址
2. 问题记录
pdf2doi安装成功后可能会出现anaconda中的spyder启动不了的情况,输入以下命令
spyder --new-instance报错
C:\Users\sun78>spyder --new-instance
Traceback (most recent call last):
File "C:\Users\sun78\anaconda3\lib\site-packages\qtpy\QtWebEngineWidgets.py", line 22, in
from PyQt5.QtWebEngineWidgets import QWebEnginePage
ImportError: DLL load failed while importing QtWebEngineWidgets: 找不到指定的程序。
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\sun78\anaconda3\Scripts\spyder-script.py", line 10, in
sys.exit(main())
File "C:\Users\sun78\anaconda3\lib\site-packages\spyder\app\start.py", line 224, in main
from spyder.app import mainwindow
File "C:\Users\sun78\anaconda3\lib\site-packages\spyder\app\mainwindow.py", line 65, in
from qtpy import QtWebEngineWidgets # analysis:ignore
File "C:\Users\sun78\anaconda3\lib\site-packages\qtpy\QtWebEngineWidgets.py", line 26, in
from PyQt5.QtWebKitWidgets import QWebPage as QWebEnginePage
ModuleNotFoundError: No module named 'PyQt5.QtWebKitWidgets' 这是因为安装过程中将原有环境中的包进行了版本更新或降低,导致安装后环境中PyQt的版本将为PyQt5 5.15.7,而在 PyQt 5.6(+) 版本中, 新增 QtWebEngineWidgets 代替QtWebKitWidgets。因此报错,No module named 'PyQt5.QtWebKitWidgets'。
pdf2doi的项目依赖如下
(pdf2doi) C:\Users\sun78>pip install pdf2doi
Requirement already satisfied: pdf2doi in c:\users\sun78\anaconda3\lib\site-packages (1.3)
Requirement already satisfied: feedparser>=6.0.2 in c:\users\sun78\anaconda3\lib\site-packages (from pdf2doi) (6.0.10)
Requirement already satisfied: textract==1.6.4 in c:\users\sun78\anaconda3\lib\site-packages (from pdf2doi) (1.6.4)
Requirement already satisfied: easygui in c:\users\sun78\anaconda3\lib\site-packages\easygui-0.98.0_unreleased-py3.8.egg (from pdf2doi) (0.98.0-unreleased)
Requirement already satisfied: pdftitle>=0.3 in c:\users\sun78\anaconda3\lib\site-packages (from pdf2doi) (0.5)
Requirement already satisfied: requests>=2.25.1 in c:\users\sun78\anaconda3\lib\site-packages (from pdf2doi) (2.25.1)
Requirement already satisfied: pyperclip in c:\users\sun78\anaconda3\lib\site-packages (from pdf2doi) (1.8.2)
Requirement already satisfied: pypdf2==2.0.0 in c:\users\sun78\anaconda3\lib\site-packages (from pdf2doi) (2.0.0)
Requirement already satisfied: google>=3.0.0 in c:\users\sun78\anaconda3\lib\site-packages (from pdf2doi) (3.0.0)
Requirement already satisfied: typing-extensions in c:\users\sun78\anaconda3\lib\site-packages (from pypdf2==2.0.0->pdf2doi) (3.7.4.3)
Requirement already satisfied: python-pptx~=0.6.18 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (0.6.21)
Requirement already satisfied: docx2txt~=0.8 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (0.8)
Requirement already satisfied: six~=1.12.0 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (1.12.0)
Requirement already satisfied: extract-msg<=0.29.* in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (0.28.7)
Requirement already satisfied: EbookLib==0.* in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (0.17.1)
Requirement already satisfied: pdfminer.six==20191110 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (20191110)
Requirement already satisfied: chardet==3.* in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (3.0.4)
Requirement already satisfied: SpeechRecognition~=3.8.1 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (3.8.1)
Requirement already satisfied: xlrd~=1.2.0 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (1.2.0)
Requirement already satisfied: argcomplete~=1.10.0 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (1.10.3)
Requirement already satisfied: beautifulsoup4~=4.8.0 in c:\users\sun78\anaconda3\lib\site-packages (from textract==1.6.4->pdf2doi) (4.8.2)
Requirement already satisfied: lxml in c:\users\sun78\anaconda3\lib\site-packages (from EbookLib==0.*->textract==1.6.4->pdf2doi) (4.6.3)
Requirement already satisfied: sortedcontainers in c:\users\sun78\anaconda3\lib\site-packages (from pdfminer.six==20191110->textract==1.6.4->pdf2doi) (2.3.0)
Requirement already satisfied: pycryptodome in c:\users\sun78\anaconda3\lib\site-packages (from pdfminer.six==20191110->textract==1.6.4->pdf2doi) (3.15.0)
Requirement already satisfied: sgmllib3k in c:\users\sun78\anaconda3\lib\site-packages (from feedparser>=6.0.2->pdf2doi) (1.0.0)
Requirement already satisfied: idna<3,>=2.5 in c:\users\sun78\anaconda3\lib\site-packages (from requests>=2.25.1->pdf2doi) (2.10)
Requirement already satisfied: certifi>=2017.4.17 in c:\users\sun78\anaconda3\lib\site-packages (from requests>=2.25.1->pdf2doi) (2020.12.5)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in c:\users\sun78\anaconda3\lib\site-packages (from requests>=2.25.1->pdf2doi) (1.26.4)
Requirement already satisfied: soupsieve>=1.2 in c:\users\sun78\anaconda3\lib\site-packages (from beautifulsoup4~=4.8.0->textract==1.6.4->pdf2doi) (2.2.1)
Requirement already satisfied: compressed-rtf>=1.0.6 in c:\users\sun78\anaconda3\lib\site-packages (from extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (1.0.6)
Requirement already satisfied: ebcdic>=1.1.1 in c:\users\sun78\anaconda3\lib\site-packages (from extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (1.1.1)
Requirement already satisfied: tzlocal>=2.1 in c:\users\sun78\anaconda3\lib\site-packages (from extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (4.2)
Requirement already satisfied: olefile>=0.46 in c:\users\sun78\anaconda3\lib\site-packages (from extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (0.46)
Requirement already satisfied: imapclient==2.1.0 in c:\users\sun78\anaconda3\lib\site-packages (from extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (2.1.0)
Requirement already satisfied: XlsxWriter>=0.5.7 in c:\users\sun78\anaconda3\lib\site-packages (from python-pptx~=0.6.18->textract==1.6.4->pdf2doi) (1.3.8)
Requirement already satisfied: Pillow>=3.3.2 in c:\users\sun78\anaconda3\lib\site-packages (from python-pptx~=0.6.18->textract==1.6.4->pdf2doi) (8.2.0)
Requirement already satisfied: backports.zoneinfo in c:\users\sun78\anaconda3\lib\site-packages (from tzlocal>=2.1->extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (0.2.1)
Requirement already satisfied: tzdata in c:\users\sun78\anaconda3\lib\site-packages (from tzlocal>=2.1->extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (2022.2)
Requirement already satisfied: pytz-deprecation-shim in c:\users\sun78\anaconda3\lib\site-packages (from tzlocal>=2.1->extract-msg<=0.29.*->textract==1.6.4->pdf2doi) (0.1.0.post0)使用如下命令独立安装WebEngine
pip install PyQtWebEngine -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
报错如下,报错原因spyder版本过低
spyder 4.2.5 requires pyqt5<5.13, but you have pyqt5 5.15.7 which is incompatible.
spyder 4.2.5 requires pyqtwebengine<5.13, but you have pyqtwebengine 5.15.6 which is incompatible.尝试更新spyder版本
pip install --upgrade spyder更新完成后可正常使用
3. pdf2doi的使用
3.1 pdf2doi可选参数列表
$ pdf2doi --h
usage: pdf2doi [-h] [-v] [-nws] [-nwv] [-nostore] [-id IDENTIFIER] [-google GOOGLE_RESULTS] [-s FILENAME_IDENTIFIERS] [-clip] [-install--right--click] [-uninstall--right--click] [path [path ...]]
Retrieves the DOI or other identifiers (e.g. arXiv) from pdf files of a publications.
positional arguments:
path Relative path of the target pdf file or of the targe folder.
optional arguments:
-h, --help show this help message and exit
-v, --verbose Increase verbosity. By default (i.e. when not using -v), only a table with the found identifiers will be printed as output.
-nws, --no_web_search
Disable any method to find identifiers which requires internet searches (e.g. queries to google).
-nwv, --no_web_validation
Disable the online validation of identifiers (e.g., via queries to http://dx.doi.org/).
-nostore, --no_store_identifier_metadata
By default, anytime an identifier is found it is added to the metadata of the pdf file (if not present yet). By using this additional option, the identifier is not stored in the file metadata.
-id IDENTIFIER Stores the string IDENTIFIER in the metadata of the target pdf file, with key '/identifier'. Note: when this argument is passed, all other arguments (except for the path to the pdf file) are ignored.
-google GOOGLE_RESULTS
Set how many results should be considered when doing a google search for the DOI (default=6).
-s FILENAME_IDENTIFIERS, --save_identifiers_file FILENAME_IDENTIFIERS
Save all the identifiers found in the target folder in a text file inside the same folder with name specified by FILENAME_IDENTIFIERS. This option is only available when a folder is targeted.
-clip, --save_doi_clipboard
Store all found DOI/identifiers into the clipboard.
-install--right--click
Add a shortcut to pdf2doi in the right-click context menu of Windows. You can copy the identifier and/or bibtex entry of a pdf file (or all pdf files in a folder) into the clipboard by just right clicking on it!
NOTE: this feature is only available on Windows.
-uninstall--right--click
Uninstall the right-click context menu functionalities. NOTE: this feature is only available on Windows.
3.2 命令行中调用
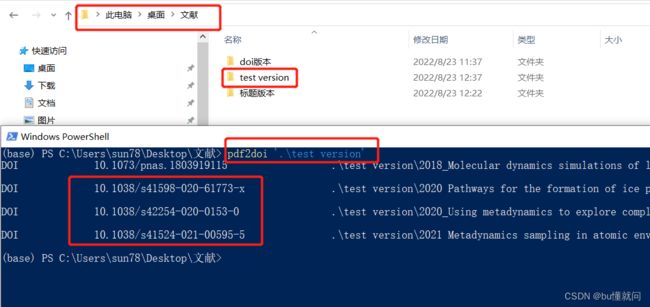
在目标文件夹的上一级目录中执行如下命令
pdf2doi '.\目标文件夹名' # 如pdf2doi '.\test version'即可获取doi号
3.3 在脚本中调用pdf2doi
import pdf2doi
import os
pdf2doi.config.set('verbose',True)
target_path = os.getcwd() # 获取文件当前工作目录路径(绝对路径)
results = pdf2doi.pdf2doi(target_path)
print(results)
for result in results:
print(result['identifier'])输出结果

注意下面参数的意义
result['identifier'] = DOI or other identifier (or None if nothing is found)
result['identifier_type'] = string specifying the type of identifier (e.g. 'doi' or 'arxiv')
result['validation_info'] = Additional info on the paper. If config.get('webvalidation') = True, then result['validation_info']
will typically contain raw bibtex data for this paper. Otherwise it will just contain True
result['path'] = path of the pdf file
result['method'] = method used to find the identifier3.4 获取文件当前工作目录路径
import os
target_path = os.getcwd() # 获取文件当前工作目录路径(绝对路径)
for filename in os.listdir(target_path):
print(os.path.join(filename))3.5 基于pdf2doi获取[filename](url)markdown格式
import pdf2doi
import os
pdf2doi.config.set('verbose',True)
target_path = os.getcwd() # 获取文件当前工作目录路径(绝对路径)
doi_results = pdf2doi.pdf2doi(target_path)
pdf_filenames = os.listdir(target_path)
print(pdf_filenames, doi_results)
for filename, result in zip(pdf_filenames, doi_results): # 同步遍历多个列表
print(os.path.join(filename),result['identifier'])
doi = result['identifier']
if doi != None:
mark_str = '['+os.path.join(filename)+']'+'('+ 'https://doi.org/'+ doi +')'+ '\n' #markdowm 格式[filename](url)
else :
mark_str = '['+os.path.join(filename)+']'+'('+ ')'+ '\n' #markdowm 格式[filename](url)
print(mark_str)
with open('doi.txt', 'a') as new_file:
new_file.write(mark_str)参考资料
https://pypi.org/project/pdf2doi/