图像修复 : ICCV 2021 基于条件纹理和结构并行生成的图像修复【翻译】
声明:精简翻译,未完全校对
- 积压的存稿、好久没更文了、先发一篇
- 这个代码很不错、推荐有兴趣的同学学习
- 博主也写了对应的测评文章待发、点赞越多、发的越快
- 如有同学,学有余力、可以转载这个文章( 附原文地址即可 )、校对、共享,帮助大家学习进步
- 可以适当的给予鼓励,如果你同样认可这是一件快乐和有意义的事情
- 文末附中文翻译 PDF (机翻)分享
版权: 本文由【墨理学AI】原创首发、各位读者大大、敬请查阅、感谢三连
声明: 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️

- 精选专栏,图像修复-代码环境搭建-知识总结
- 源码测评, 图像修复 : 基于条件纹理和结构并行生成的图像修复——ICCV 2021 【附测评源码】
- 博主:墨理,2020年硕士毕业,目前从事图像算法,AI工程化 相关工作
- 该代码的测评,近期会更新博文,敬请关注
文章目录
-
- 基础信息
- 精简翻译
- 中文翻译 PDF (机翻)分享
- 预祝各位 前途似锦、可摘星辰
基础信息
- https://github.com/Xiefan-Guo/CTSDG
- https://arxiv.org/pdf/2108.09760.pdf
恭喜北航 和 论文作者( 作者只有三个人 )

精简翻译
摘要翻译:
深度生成方法最近通过引入结构先验在图像修复方面取得了相当大的进展。然而,由于在结构重建过程中缺乏与图像纹理的适当交互,当前的解决方案无法处理具有大损坏的情况,并且通常会出现失真的结果。在本文中,我们提出了一种用于图像修复的新型双流网络,它以耦合的方式对结构约束纹理合成和纹理引导结构重建进行建模,以便它们更好地相互利用以获得更合理的生成。此外,为了增强全局一致性,设计了双向门控特征融合 (Bi-GFF) 模块来交换和组合结构和纹理信息,并开发了上下文特征聚合 (CFA) 模块来按区域细化生成的内容亲和力学习和多尺度特征聚合。在 CelebA、Paris StreetView 和 Places2 数据集上的定性和定量实验证明了所提出方法的优越性
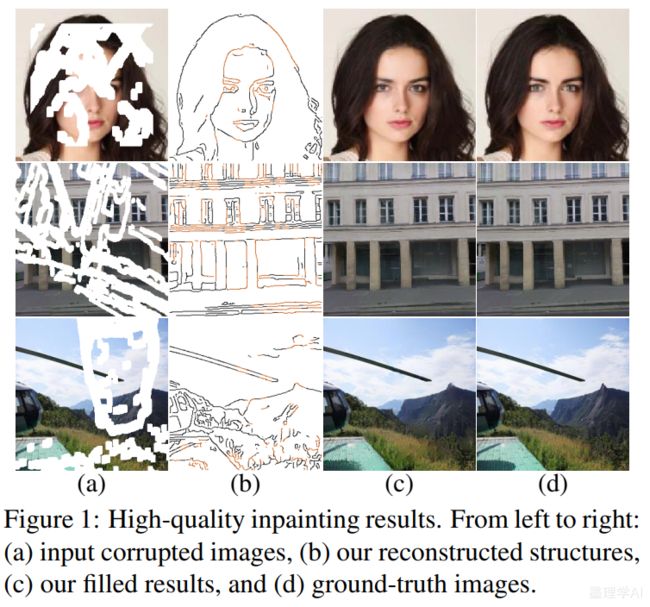
输入 - 过程(重建的结构) - 输出(修复图像) - 真实图像
简单说一说论文目录结构
优秀顶会论文的特点:文章内容高度凝聚、没有多余的标题
- Introduction
图像修复[3]指的是在重建图像受损区域的同时保持其整体一致性的过程,这是一项典型的低水平视觉任
务,具有许多实际应用,如照片编辑、分散注意力的物体移除和修复受损部分。
与大多数计算机视觉问题一样,在过去十年中,深度学习的广泛应用在很大程度上促进了图像修复。与
传统方法[2, 5]不同,传统方法通过从已知区域搜索最相似的补丁来逐步填补缺失区域,而深层生成方法[19, 7, 31, 33]捕捉到了更高层次的语义,并更好地处理了具有非重复模式的图像修复任务;
还有一种趋势是,将深度生成和基于补丁的传统图像修复方法的优点结合起来[35, 30, 24, 15],提供具有真实纹理和合理语义的修复内容。此外,还研究了香草卷积的更新版本[13, 27, 36],其中操作被屏
蔽并标准化为仅以有效像素为条件,从而在不规则损坏方面实现了良好的性能。然而,上述方法在恢复图像的全局结构时暴露了一个共同的缺点,因为生成网络的功能不如预期的强大。
为了解决这个问题,人们提出了许多多阶段方法来明确地结合结构建模,在第一阶段中幻觉缺失区域的结构,并在第二阶段使用它们来指导像素生成。例如,EdgeConnect [18]通过边缘对此类结构进行编码,而[20]和[28]采用中间边缘保留的平滑图像和前景轮廓。这些替代方案显示了结构和纹理得到改善的结果。不幸的是,从损坏的图像中获取合理的边缘本身就是一项非常艰巨的任务。在这些串联耦合的框架中,重复任务和采用不稳定的结构先验往往会导致很大的错误。
最近,一些尝试混合了结构和纹理的建模过程。PRV(视觉结构的渐进重建)[10]和MED(相互编码解码器)[14]是代表,它们通常利用纹理和结构的共享生成器。尽管报告了一些性能提升,但在这种单一
缠绕结构中,结构和纹理之间的关系并未得到充分考虑。特别是,由于图像结构和纹理在整个网络中相互关联,它们很难传递整体的补充信息来帮助另一方。这一事实表明,仍有很大的改进空间。
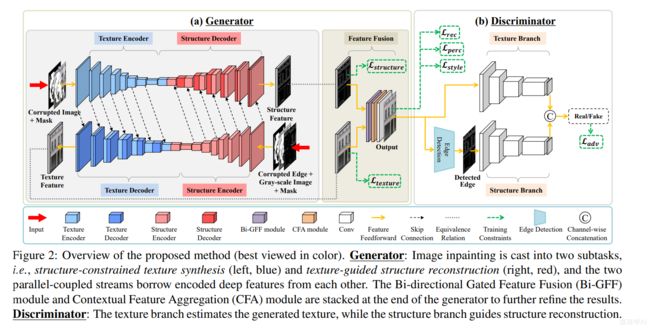
在本文中,我们提出了一种新的双流网络,该网络将图像修复分为两个子任务,即结构约束纹理合成和
纹理引导结构重建。通过这种方式,两个并行耦合流被单独建模并组合以相互补充。相应地,我们开发了一个双分支鉴别器来评估这一代的性能,它监督模型同时合成真实像素和锐利边缘,以进行全局优化。此外,我们还引入了一个新的双向选通特征融合(bi GFF)模块来集成重建的结构和纹理特征映射,以增强它们的一致性,以及一个上下文特征聚合(CFA)模块来突出来自遥远空间位置的线索,以呈现更精细的细节。由于双代网络以及专门设计的模块,我们的方法能够实现更具视觉说服力的结构和纹理(见图1, 放大以获得更好的视图)。
在 CelebA [16]、Paris StreetView [4] 和 Places2 [39] 数据集上进行了大量实验以进行评估。定性和定量结果表明,我们的模型显著优于最先进的模型。
- CelebA[16], Paris StreetView [4] and Places2 [39] datasets for evaluation.
- Qualitative and quantitative results demonstrate [ 定性 定量评估 ]
- our model significantly outperforms the state-of-the-art.
- The main novelties and contributions are as follows:

- Related Work
- 2.1. Traditional Methods
传统的方法主要可以归纳为两类,即基于扩散的方法和基于斑块的方法。基于扩散的方法[3, 1]根据相邻
区域的外观信息渲染缺失区域。由于这种初步的搜索机制,他们的结果不太好。在基于面片的方法[2, 29]中,像素完成是通过从源图像的未受损区域搜索和粘贴最相似的面片来实现的,这利用了远距离信息。这些方法实现了更好的性能,但在计算缺失区域和可用区域之间的补丁相似性时,它们的计算成本很高,并且难以重建具有丰富语义的模式。
- 2.2. Deep Generative Methods
深度生成方法[35, 36, 8, 34, 38, 40, 37, 26, 12]目前占主导地位,由于其强大的特征学习能力,可以有效地从受损图像中提取有意义的语义,并以较高的视觉保真度恢复合理的内容。
最近,Wang等人[25]通过涉及结构信息,显著提高了边缘更清晰的图像合成质量。随后,提出了一系列
多阶段方法,这些方法连续地结合了额外的结构先验,产生了更令人印象深刻的结果。EdgeConnect [18]通过边缘提取图像结构,并根据边缘填充孔洞。Xiong等人[28]展示了一个类似的模型,该模型使用前景对象轮廓作为结构先验,而不是边缘。Ren等人[20]指出,由于捕捉到了更多的语义,所以边缘保留的平滑图像传达了更好的全局结构。但这些方法对结构(如边缘和轮廓)的准确性很敏感,这不容易保证。为了克服这个缺点,有几种方法试图利用纹理和结构的相关性。Li等人[10]设计了一个视觉结构重建层,以逐步缠绕图像内容和结构的生成。Yang等人[32]引入了一个多任务框架,通过添加结构约束来生成锐利的边缘。Liu等人[14]提出了一个相互编码-解码网络,以同时学习CNN特征,这些特征对应于不同层的结构和纹理。然而,很难对纹理和结构进行建模,并使它们在单个共享架构中充分互补。
我们的研究还利用了图像结构信息,提出了一种不同但更有效的双流网络,其中结合了结构约束纹理合成和纹理引导结构重建。这两个子任务可以更好地相互促进,在 dual generation 中产生更令人信服的纹理和结构。
- Approach ( 网络的可改进点,主要就是围绕这些,至于你是创新、还是拼凑、先实验效果好、然后理论升华一样 很 OK )
- 3.1. Generator
这里作者所提出的这俩创新模块、盲猜大概率有很多 Tricks 创意 是受 NLP、语音 领域的一些前沿网络启发
这里的网络结构图,是如何生成、或者用什么 工具画出来的,希望有经验的 硕博 前辈 指点一二
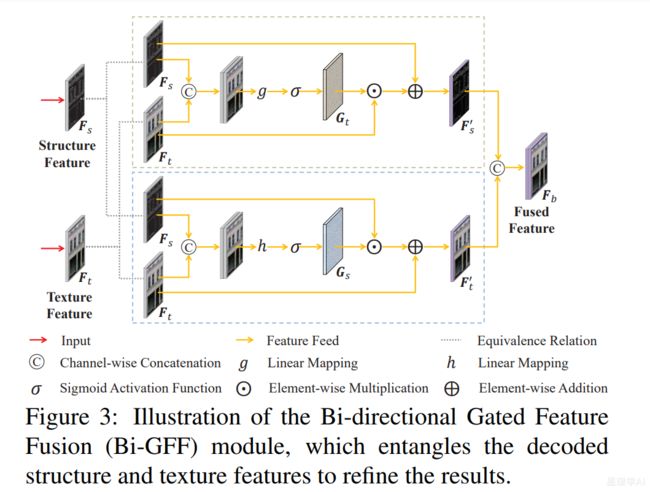
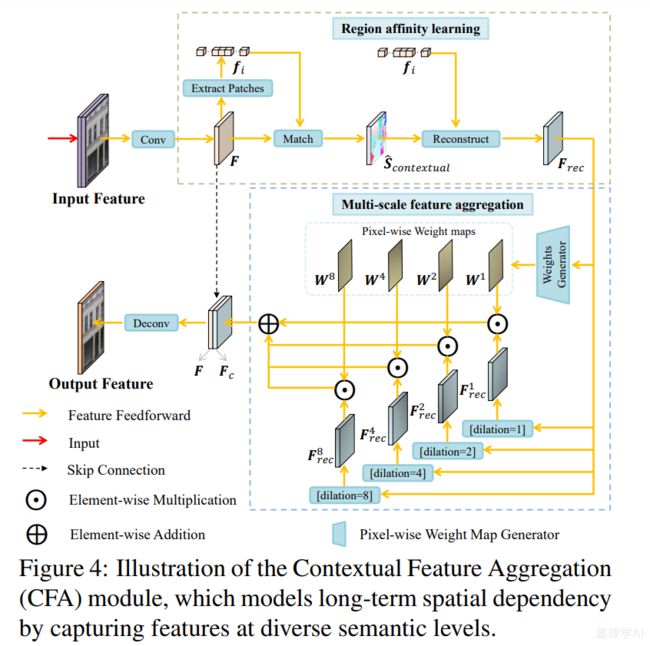
- 3.2. Discriminator
Motivated by global and local GANs [7], Gated Convolution [36] and Markovian GANs [9], we develop a twostream discriminator to distinguish genuine images from the generated ones by estimating the feature statistics of both texture and structure.
- 3.3. Loss Functions
损失也还是那几个常见的 Loss , 名字大家都知道
这个地方就是,有的时候,其他顶会中如果出来某个新的 Loss、确实效果好的话、都可以及时拿来 套用、看是否适合当前领域研究
The model is trained with a joint loss, containing the reconstruction loss, perceptual loss, style loss and adversarial loss, to render visually realistic and semantically reasonable results.


4 Experiments
- 4.1. Experimental Settings

- 4.2 Qualitative Comparison
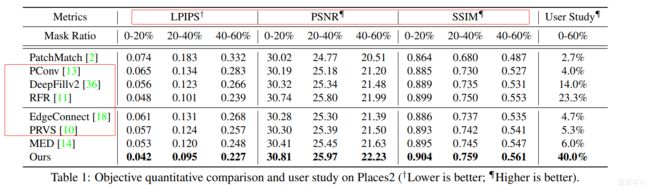
- 4.3 Quantitative Comparison
定性、定量对比

- 4.4 Analysis on Network Architecture

- 4.5. Ablation Study
补充工作量、提升想象空间,这些东西说来容易、折腾其中的时候、如果不是对科研充满热爱、都是磨人的过程,痛并快乐着 ?
- Conclusion
在本文中,我们提出了一种新的双流图像修复方法,该方法通过同时建模结构约束纹理合成和纹理引导结构重建来恢复损坏的图像。 通过这种方式,两个子任务交换有用的信息,从而相互促进。 此外,引入了一个双向门控特征融合模块,然后是一个上下文特征聚合模块来细化结果,具有语义上合理的结构和细节丰富的纹理。实验表明,该模型能够胜任这一任务,并且优于最先进的模型。
中文翻译 PDF (机翻)分享
机翻中文论文效果大致如下:


文末卡片、关注 墨理学AI 、后台回复,关键词,20220110
20220110
预祝各位 前途似锦、可摘星辰
- 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️
- ❤️ 如果文章对你有帮助、点赞、评论鼓励博主的每一分认真创作
- 深度学习模型训练推理——基础环境搭建推荐博文查阅顺序【基础安装—认真帮大家整理了】——【1024专刊】
计算机视觉领域 八大专栏、不少干货、有兴趣可了解一下
- ❤️ 图像风格转换 —— 代码环境搭建 实战教程【关注即可阅】!
- 图像修复-代码环境搭建-知识总结 实战教程 【据说还行】
- 超分重建-代码环境搭建-知识总结 解秘如何让白月光更清晰【脱单神器】
- YOLO专栏,只有实战,不讲道理 图像分类【建议收藏】!
-
深度学习:环境搭建,一文读懂
-
深度学习:趣学深度学习
-
落地部署应用:模型部署之转换-加速-封装
-
CV 和 语音数据集:数据集整理
-
最近更新:2022年4月11日
-
点赞 收藏 ⭐留言 都是博主坚持写作、更新高质量博文的最大动力!
