ICCV 2021 |首届 SoMoF 人体序列预测比赛冠军方案分享

近日阿里巴巴淘系技术多媒体算法团队的同学,以大幅领先第二名的成绩获得了在 ICCV2021 上举办的第一届室外场景下的人体轨迹预测比赛( SoMoF Challenge )的冠军,同时比赛论文被该 Workshop 接收。
作为计算机视觉领域的三大顶级会议之一, ICCV 是每年学界的重要事件。ICCV 全称为 International Conference on Computer Vision ,中文为国际计算机视觉大会。这个会议是由 IEEE 主办的全球最高级别学术会议,每两年在世界范围内召开一次,在业内具有极高的评价。而由斯坦福大学主办的第一届 SoMoF Challenge 以人体轨迹预测这一既有广阔应用前景又极具挑战的任务为主题,吸引了来自众多高校和工业界的参赛者。
本次Challenge中我们通过改进图卷积网络,应用轨迹信息作为输入,通过设计新颖的训练和数据处理策略,获得了2D数据集PoseTrack和3D数据集3DPW两个子任务上的冠军,并且在两个数据集上分别领先第二名5%和13%。
比赛地址:https://somof.stanford.edu/workshops/iccv21
论文地址:https://openaccess.thecvf.com/content/ICCV2021W/SoMoF/papers/Wang_Simple_Baseline_for_Single_Human_Motion_Forecasting_ICCVW_2021_paper.pdf
背景
随着计算机视觉研究的不断深入,许多识别类任务,如动作认别,姿态识别取得了重大的进展。为了进一步拓宽计算机视觉的应用场景,越来越多的研究者将注意力从“识别”类任务转移到“预测”类任务上。人体动作序列预测就是其中一个颇受关注的方向。
概括来说,动作序列预测要做的是,根据给定图像序列中的人体关节点的2D或3D坐标,预测接下来若干帧图像序列中的关节点的位置。值得一提的是,接下来若干帧的图像信息是不可见的。
动作序列预测是一个很有应用前景,也极具挑战的研究方向。它的应用场景广泛,包括自动驾驶,人机交互,安防,AI健身教练等。举个例子,如果一辆行进中的自动驾驶汽车,通过观察斑马线上路人过马路时的画面,能够预测接下来他们的行动轨迹,那就能及时停车或者前进,减小交通事故发生的概率。

同时这还是一个很有挑战的方向。由于室外场景的复杂性,人们自身行动的随意性,周围人和物的多变性,以及预测类任务本身自带的不确定性,都会增加未来时刻动作序列预测的难度。
本次比赛中,我们通过采用在解决手淘场景下的人体/人手姿态估计时提炼出的技术积累,结合动作序列任务本身的特性,设计了新的网络结构,采用了新颖的训练和数据处理策略,在此次比赛中获得了第一名的结果,具体方法将在下文介绍。
网络结构
我们的网络输入只有关节点的坐标序列。对于实验所用到的两个数据集来说,在PoseTrack上,使用的是14个关节点的2D图像坐标,在3DPW数据集上,使用的是24个关节点的3D世界坐标。
实验中我们尝试增加了图像信息,效果都有所下降,原因可能是关节点本身已经是图像信息对关节点预测最有效最精简的信息,额外的图像信息分散了网络的关注点,反倒不利于网络的学习。
网络结构我们采用的是GCN结构。在输入的关节点序列进网络前,先经过一个DCT变换,将时域信息转换到频域。在GCN的最后,经过iDCT变换,将频域信息转换回到时域中,即为预测的结果。
GCN相比RNN/LSTM的优势是,所有帧的预测结果可以一次预测出来,不需要一帧一帧的连续多帧预测。
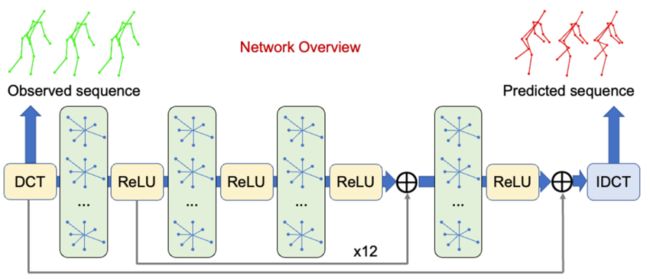
▐ 网络结构上的创新点
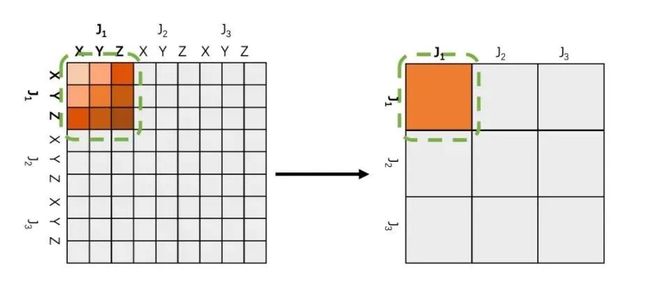
相比经典的GCN网络结构,本文中的方法将每个关节点的不同坐标(即x,y或者x,y,z)当做一个统一的图网络中的节点,而不是分开考虑。这样做有两个好处,首先是图网络看到的信息更集中更全面,有助于网络学习,另一个好处是减少了图网络的边,大大减小了网络学习的难度,因为图网络学习的权重就是不同边之间的关系。
另一个创新点是除了考虑骨架点坐标,我们还考虑了相邻两帧的骨架点的坐标差,也就是骨架点移动的速度。实际测试发现,在3D数据集上,使用速度作为输入预测效果更好。
网络训练策略
▐ 课程学习
在本次比赛中,由于我们需要预测14帧的图像,差不多跟已知的16帧时间相等,因此这个任务是个长时间的预测任务。
一般来说,长期预测任务相比短期预测任务会更难,因为距离当前时刻越远,变化越大,预测难度也越大。为了解决长时间预测不准的问题,我们采用课程学习的方法来学习loss,刚开始的epoch,只学习前面的16帧的loss,然后每增加一个epoch,往后算一帧的loss。通过这种方式,我们能确保前期的模型在短期预测方面能够学好,然后不断增加学习的难度,进行长期任务的预测。

▐ OHKM Loss
为了进一步提高网络学习能力,实验中我们采用了包含在线难关节点挖掘( OHKM, Online Hard Keypoints Mining)的损失函数。具体来说,训练过程中,对所有关节点的loss进行从大到小的排序,将loss最小的N个关节点的loss置零,也就是只考虑最难的一些关节点。这种方法让网络能更集中地学习较难的关节点。

数据处理
有一句话叫做“魔鬼藏在细节中”,实验中我们发现,通过考虑数据中的细节,能很大程度上提升结果。
▐ 坐标系变换
比赛所给的数据集中的骨架点坐标都是绝对坐标,通过将坐标点减去中心点坐标的位置后,我们就得到了相对坐标。
可以认为,绝对坐标的变化是人体中心骨架点的变化叠加上人体各个关节的变化后的结果,两组变化量的叠加大大增大了网络学习的难度。而相对坐标剔除了中心点坐标的运动量,简化了网络的学习。同时变化范围也减小了,更小的数值让网络更容易收敛。
▐ 关节点可见性设置
在 PoseTrack 数据集的评价指标中,需要使用关节点的的可见性。实际实验中,我们采用这样一种策略,即所有预测帧的关节点可见性采用最后一帧已知帧中的结果。实验结果证明采用这种简单的策略,也能达到较好的效果。
▐ 不可见关节点的插值
通过观察数据发现,在PoseTrack数据集中,不可见关节点的坐标被置成了0。如果将这些0值加入到序列的预测中,会增加数据的抖动性,对结果影响比较大。为了解决这个问题,我们采用线性插值的方式,利用这个关节点的可见前后帧数据来插值填充当前帧的数据。

实验结果
通过以上的优化思路,结合模型融合等比赛中常见的技巧,最终我们的方法大幅度超过了所有现有算法,在SoMoF比赛结果公布后,我们的方法在PoseTrack和3DPW两个数据集上都获得第一名,分别领先第二名5%和13%。

下面是我们的方法在3DPW和PoseTrack上的可视化结果。


业务相关落地
虽然动作序列预测本身在淘系业务中暂时没有合适的落地场景,不过通过本次比赛总结出的网络结构设计、训练策略和数据处理方面的部分经验,已经落地到手淘的逛逛、淘宝人生等业务中,通过2D/3D人体关键点估计的基础能力,自研的虚拟形象驱动算法,能够为C端用户提供好玩的2D/3D特效和玩法。
例如已经在手淘上线逛逛的2D虚拟形象驱动玩法“跳舞逛仔”,根据用户做的动作来驱动虚拟2D形象,结合精美设计的界面,好玩的音乐,给用户带来不一样的短视频拍摄体验。欢迎在逛逛拍视频的自拍游戏按钮下,搜索“跳舞逛仔”进行试玩。
另外基于3D虚拟形象驱动的项目,淘宝人生真人拍照也用到了相关算法,上传一张照片就可以驱动你的淘宝人生3D虚拟形象做出照片中的动作,大大增加了拍照的多样性和好玩度。

淘宝人生真人拍照玩法预计近期上线手淘,敬请期待。
总结与展望
在此次比赛中,我们通过优化图卷积网络结构,不断地细化数据和训练策略,提高了关节点不同坐标间的关联性,避免了数据标注方面的噪声对网络学习的影响,在仅利用轨迹信息作为输入的情况下,超过了使用额外图像信息的方法,获得了2D和3D测试集上的第一名。
未来,我们认为结合时间和空间上的上下文信息,如人与人、人与物的交互信息,可以更好地预测动作轨迹。另外如何做好时空上下文信息与轨迹主信息的均衡,也是一个待解决的问题。
进一步的探讨交流,欢迎发邮件至[email protected]。
团队介绍
淘系技术部-内容互动算法团队,成员来自海内外知名高校,先后获得国家科技进步二等奖,多项 CVPR 视觉比赛冠军,累积在计算机视觉顶会期刊(如 CVPR、NIPS、TIP 等)上发表论文10余篇,业务上依托淘宝直播、逛逛和点淘,致力于打造行业领先的内容理解平台和AR/VR互动视觉玩法。
真诚邀请海内外相关方向的人才加入我们,在这里成长并贡献才智。如果您有兴趣,可访问我们的招聘链接:https://talent.alibaba.com/off-campus-position/797825
参考文献
Learning trajectory dependencies for human motion prediction
Socially and contextually aware human motion and pose forecasting
Tripod:Human trajectory and pose dynamics forecasting in the wild
Amass:Archive of motion capture as surface shapes
Semi-supervised classification with graph convolutional networks
History repeats itself:Human motion prediction via motion attention
On human motion prediction using recurrent neural networks
Curriculum learning
Social lstm:Human trajectory prediction in crowded spaces
Social gan:Socially acceptable trajectories with generative adversarial networks
Stgat:Modeling spatial-temporal interactions for human trajectory prediction
✿ 拓展阅读


作者|黎水,蔚山,亭枫,塞远
编辑|橙子君
出品|阿里巴巴新零售淘系技术

