DataHub安装及测试
一. 简介
官网:https://datahubproject.io/
Github: https://github.com/linkedin/datahub
DataHub的前身是Linkedin为了提高工作效率,开发并开源的WhereHows。同样,WhereHows自身有很大的局限性:
不够重视数据之间的关系:元数据通常传达重要的关系(血统,所有权,依赖性等),这些关系可以提供强大的功能,如影响分析,数据汇总,更好的搜索相关性等。将所有这些关系建模为头等公民和支持对其进行有效的分析查询。
元数据获取倾向于推动,忽略特定域的拉动方式:一般获取元数据是采取拉取的方式,但开发和维护集中的特定域爬网程序中,让各个元数据提供者通过API或消息将信息推送到中央存储库具有更大的可伸缩性,这种基于推送的方法还可以确保更及时地反映新的和更新的元数据。
DataHub是由Linkedin开源的,官方喊出的口号为:The Metadata Platform for the Modern Data Stack 。目的就是为了解决多种多样数据生态系统的元数据管理问题,它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。常见的元数据管理系统有:Atlas,DataHub,Amundsen等
竞品比较:

DataHub与Kafka有良好的融合性,Atlas对Hive有很好的支持性,Amundsen与数据调度平台Airflow有良好结合优势
支持数据源 :

支持的BI工具:
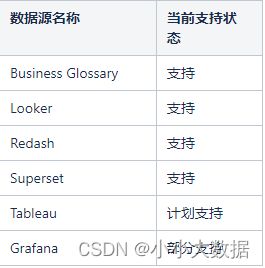
支持的ETL处理工具:
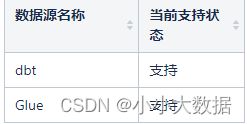
二.组件服务框架
DataHub的WebUI界面可以看做是一系列紧密结合功能的组件形成,以组件和服务为应用程序的核心,该框架使我们能够分解不同的方面并将应用程序中的其他功能组合在一起。
前端大致分为三种交互类型:
1.搜索
类似于典型的搜索引擎体验,用户可以通过提供关键字列表来搜索一种或多种类型的实体。他们可以通过筛选多个方面来进一步对结果进行切片和切块。高级用户还可以利用运算符(例如OR,NOT和regex)执行复杂的搜索
2.浏览
DataHub中的数据实体可以以树状方式组织和浏览,其中每个实体都可以出现在树中的多个位置。这使用户能够以不同方式浏览同一目录
3.查看/编辑元数据
每个数据实体都有一个“配置文件页面”,其中显示了所有关联的元数据。eg:生成数据集的作业,从该数据集计算出的度量或图表等。对于可编辑的元数据,用户也可以直接通过UI更新。
三. 基于DataHub的元数据分析
首先明确:元数据也是数据的一种,也有不同类型,不同的摄取方式,基本信息等
元数据的摄取:
在运行元数据摄入 job 之前,必须保证 DataHub 后台服务正在运行。DataHub提供两种形式的元数据摄取:API调用(离线)或Kafka流(实时)。
DataHub的API基于Rest.li,这是一种可扩展的,强类型的RESTful服务架构,已在LinkedIn上广泛使用。由于Rest.li使用Pegasus作为其接口定义,因此可以逐字使用上一节中定义的所有元数据模型。从API到存储需要多层转换的日子已经一去不复返,API和模型将始终保持同步
插件:
元数据摄入使用的是插件架构,摄入源有 32 种你仅需要安装所需的插件。比如:File,Mysql,Oracle,Kafka,Hive等
序号 插件名称 安装命令 提供功能
1 file included by default File source and sink
2 athena pip install 'acryl-datahub[athena]' AWS Athena source
3 bigquery pip install 'acryl-datahub[bigquery]' BigQuery source
4 bigquery-usage pip install 'acryl-datahub[bigquery-usage]' BigQuery usage statistics source
5 datahub-business-glossary no additional dependencies Business Glossary File source
6 dbt no additional dependencies dbt source
7 druid pip install 'acryl-datahub[druid]' Druid Source
8 feast pip install 'acryl-datahub[feast]' Feast source
9 glue pip install 'acryl-datahub[glue]' AWS Glue source
10 hive pip install 'acryl-datahub[hive]' Hive source
11 kafka pip install 'acryl-datahub[kafka]' Kafka source
12 kafka-connect pip install 'acryl-datahub[kafka-connect]' Kafka connect source
13 ldap pip install 'acryl-datahub[ldap]' (extra requirements) LDAP source
14 looker pip install 'acryl-datahub[looker]' Looker source
15 lookml pip install 'acryl-datahub[lookml]' LookML source, requires Python 3.7+
16 mongodb pip install 'acryl-datahub[mongodb]' MongoDB source
17 mssql pip install 'acryl-datahub[mssql]' SQL Server source
18 mysql pip install 'acryl-datahub[mysql]' MySQL source
19 mariadb pip install 'acryl-datahub[mariadb]' MariaDB source
20 openapi pip install 'acryl-datahub[openapi]' OpenApi Source
21 oracle pip install 'acryl-datahub[oracle]' Oracle source
22 postgres pip install 'acryl-datahub[postgres]' Postgres source
23 redash pip install 'acryl-datahub[redash]' Redash source
24 redshift pip install 'acryl-datahub[redshift]' Redshift source
25 sagemaker pip install 'acryl-datahub[sagemaker]' AWS SageMaker source
26 snowflake pip install 'acryl-datahub[snowflake]' Snowflake source
27 snowflake-usage pip install 'acryl-datahub[snowflake-usage]' Snowflake usage statistics source
28 sql-profiles pip install 'acryl-datahub[sql-profiles]' Data profiles for SQL-based systems
29 sqlalchemy pip install 'acryl-datahub[sqlalchemy]' Generic SQLAlchemy source
30 superset pip install 'acryl-datahub[superset]' Superset source
31 trino pip install 'acryl-datahub[trino] Trino source
32 starburst-trino-usage pip install 'acryl-datahub[starburst-trino-usage]' Starburst Trino usage statistics source
摄入汇(Sinks)有 4 种:
序号 插件名称 安装命令 提供功能
1 file included by default File source and sink
2 console included by default Console sink
3 datahub-rest pip install 'acryl-datahub[datahub-rest]' DataHub sink over REST API
4 datahub-kafka pip install 'acryl-datahub[datahub-kafka]' DataHub sink over Kafka
**File:**将元数据输出到文件。使用 File 汇可以将源数据源的处理和推送从 DataHub 解耦。也适合于调试目的
**DataHub Rest:**使用 GMS Rest 接口将元数据推送到 DataHub。
**DataHub Kafka:**通过发布消息到 Kafka 将元数据推送至 DataHub,异步的可以处理更高的流量。
**Console:**将元数据事件输出到标准输出。用于试验和调试。
测试:
从 MySQL 获取元数据使用 Rest 接口将数据存储 DataHub
(datahub) [root@home datahub]# cat mysql_to_datahub_rest.yml
# A sample recipe that pulls metadata from MySQL and puts it into DataHub
# using the Rest API.
source:
type: mysql
config:
username: root
password: 123456
database: cnarea20200630
transformers:
- type: "fully-qualified-class-name-of-transformer"
config:
some_property: "some.value"
sink:
type: "datahub-rest"
config:
server: "http://home:8080"
# datahub ingest -c mysql_to_datahub_rest.yml
元数据服务:
一旦摄取并存储了元数据,如何有效地处理原始和派生的元数据就很重要。DataHub旨在支持对大量元数据的四种常见查询类型:
面向文档的查询
面向图的查询
涉及联接的复杂查询
全文搜索
综上,对市面上常见的元数据治理工具:Atlas(对hive有非常好的支持,但是部署起来非常的吃力),Amundsen(是一个新兴的框架,还没有release版本,未来可能会发展起来还需要慢慢观察),DataHub是目前我们实时数据治理的最佳选择,虽然目前DataHub的相关的资料还较少,但整体上我个人还是看好DataHub的发展的,毕竟Linkedin的Kafka就是一款 很好的产品哦~~~
四. 部署安装
基础:
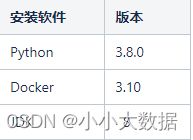
安装:
#启动Docker
systemctl start docker
#安装DataHub
cd /usr/local
yum -y install git
git --version
git clone git://github.com/linkedin/datahub.git
cd /usr/local/docker
source ./quickstart.sh
#扩展
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip uninstall datahub acryl-datahub || true
python3 -m pip install --upgrade acryl-datahub
datahub version
datahub docker quickstart
参考文档:
DataHub官方文档
数据治理方案技术调研
元数据管理-DataHub
实时数据治理平台-DataHub