GoogleNet论文精读与代码复现
GoogleNet论文精读笔记
1 核心观点
本文的工作点在于:
- 提出了一种代号为Inception的深度卷积神经网络架构,提高了网络内部计算资源的利用率
- 目标检测的最大收益并不来自于单独使用深度网络或更大的模型,而是来自于深度架构和经典计算机视觉的协同作用
- Inception架构的主要思想是基于找出卷积视觉网络中最优的局部稀疏结构如何被现成的密集组件逼近和覆盖。
卷积网络的前代发展:
现存的问题:
- 更深的网络倾向于过拟合
- 高质量的训练集是棘手且代价高的,这是一个瓶颈
- 统一增加网络大小的另一个缺点是计算资源的使用急剧增加
在深度视觉网络中,如果两个卷积层是链式的,它们的滤波器数量的任何均匀增加都会导致计算量的二次增长
解决问题的思路:
- 全连接架构转移至稀疏链接
- 稀疏矩阵的计算效率很低,将稀疏矩阵聚类为相对密集的子矩阵往往会为稀疏矩阵乘法提供最先进的实用性能
2 网络结构
选择卷积核大小的依据:
1、为了避免补丁问题,当前的Inception体系结构被限制为过滤器大小1×1、3×3和5×5,但是这个决定更多地是基于方便而非必要性
patch alignment issues:图像块的对齐,也就是cat时需要大小相同的特征图才能进行cat操作
2、由于这些“Inception模块”是相互叠加的,它们的输出相关统计数据必然会变化:由于更高的抽象特征被更高的层捕获,它们的空间集中度预计会下降,这表明3×3和5×5卷积的比率应该随着我们移动到更高的层而增加。
Inception小块:

一般来说,Inception网络是一个由上述类型的模块组成的网络,这些模块彼此堆叠在一起,偶尔有一个stride为2的最大池层,以将网格的分辨率减半。出于技术原因(训练期间的内存效率),只在较高层使用Inception模块,而以传统的卷积方式保持较低层似乎是有益的。
底层用传统卷积的这种策略不是必须的,因为现实的硬件资源不支持,效率低下
结构的优势优势:
1、它允许在每个阶段显著增加单元数量,而不会导致计算复杂度失控(降维)
降维的普遍使用允许将上一阶段的大量输入滤波器屏蔽到下一层,首先降低它们的维数,然后用大的patch size对它们进行卷积
2、它与直觉保持一致,即视觉信息应该在不同的尺度上处理,然后聚合,以便下一个阶段可以同时从不同的尺度上抽象特征
总体网络结构组成:

从完全连接层转移到平均池化可以提高0.6%的top-1准确率,然而,即使在移除完全连接层后,dropout仍然是必不可少的。
网络高效性:它总共有22层,但是总的参数比AlexNet还要小12倍
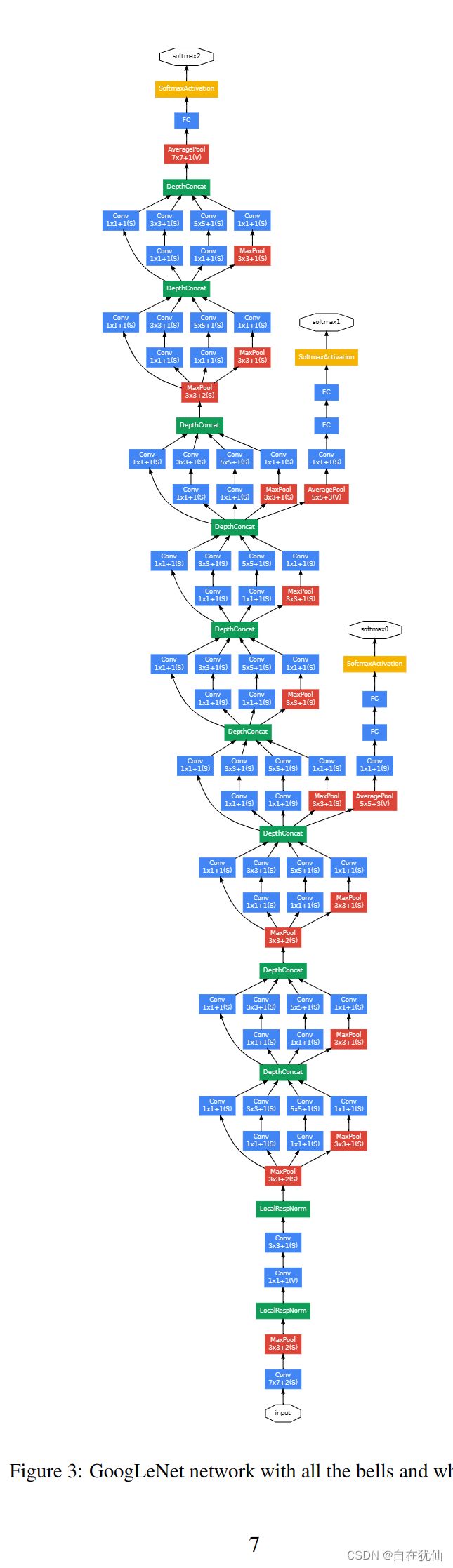
3 训练策略
- 并行训练:使用DistBelief分布式机器学习系统进行训练,使用适量的模型和数据并行性
- 学习率调整:固定学习率计划(每8个epoch学习率降低4%
- 使用Polyak平均来创建推理时使用的最终模型
- 采样策略:对图像的各种大小的小块进行采样,这些小块的大小均匀分布在图像面积的8%到100%之间,其长宽比随机选择在3/4到4/3之间
- 抗过拟合:Andrew Howard的光度畸变在一定程度上有助于对抗过拟合(图像增广)
photometric distortion中: 调整图像的亮度,对比度,色调,饱和度以及噪声
geometric distortion: 随机增加尺度变化,裁剪,翻转以及旋转
4 代码复现
GoogLeNet是与众不同的一个深度学习的网络,它有很多优秀的特点。
-
GoogLeNet是个很大的网络,但是由于都是利用inception组合,其参数比之前的网络要少很多。
-
inception结构也充分利用了现有的计算基础设施,提高了运行的效率。
-
inception的模块化结构使得整个网络便于增加和修改。
-
GoogLeNet最后使用池化层代替全连接层,其思想来源于Network-in-Network,但为了灵活输出还是加了全连接层。
-
网络中保留了Dropout
-
为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉
-
GoogleNet证明迁移到更稀疏的架构是可行的和有用的。这表明未来有希望创建更稀疏和更精细的结构。
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch.utils.data import TensorDataset,DataLoader
from torchvision.transforms import transforms
import d2I.torch1 as d2I
"""
GoogleNet:利用Inception整合不同卷积核大小的空间信息和通道信息
"""
"""
tricks :
1.nn.MaxPool2d(kernel_size=3, stride=2, padding=1) 常常用来将输入大小减半
2.nn.Conv2d(kernel_size=3,stride=1,padding = 1) 常常用来保持输入输出大小
3.nn.Conv2d(kernel_size=1) 常常用来整合通道信息,不改变输出尺度大小,当作全连接层使用
"""
# 定义Inception_block模块
class Inception(nn.Module):
def __init__(self,in_channels,c0,c1,c2,c3,**kwargs):
super(Inception, self).__init__()
self.c0 = nn.Conv2d(in_channels,c0,kernel_size=1)
self.c1_0 = nn.Conv2d(in_channels,c1[0],kernel_size=1)
self.c1_1 = nn.Conv2d(c1[0],c1[1],kernel_size=3,padding=1)
self.c2_0 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.c2_1 = nn.Conv2d(c2[0], c2[1], kernel_size=5, padding=2)
self.c3_0 = nn.MaxPool2d(3,stride=1,padding=1)
self.c3_1 = nn.Conv2d(in_channels,c3,kernel_size=1)
def forward(self,x):
c0 = F.relu(self.c0(x))
c1 = F.relu(self.c1_1(self.c1_0(x)))
c2 = F.relu(self.c2_1(self.c2_0(x)))
c3 = F.relu(self.c3_1(self.c3_0(x)))
out = torch.cat((c0,c1,c2,c3),dim=1)
return out
class GoogelNet(nn.Module):
def __init__(self,input_channels):
super(GoogelNet, self).__init__()
self.g1 = nn.Sequential(
nn.Conv2d(input_channels,out_channels=64,kernel_size=7,stride=2,padding=3), #(224,224) --> (112,112)
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1) #(112,112) --> (56,56)
)
self.g2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1), #(56,56) --> (56,56)
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1), #(56,56) --> (56,56)
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) #(56,56) --> (28,28)
)
self.g3 = nn.Sequential(
Inception(192, 64, (96,128), (16,32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.g4 = nn.Sequential(
Inception(480, 192, (96,208), (16,48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 96), 64),
Inception(560, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.g5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d(1),
nn.Flatten()
)
self.Linear = nn.Linear(1024,10)
def forward(self,x):
out = self.g1(x)
out = self.g2(out)
out = self.g3(out)
out = self.g4(out)
out = self.g5(out)
out = self.Linear(out)
return out
def get_All_Seq(self):
return nn.Sequential(
self.g1,
self.g2,
self.g3,
self.g4,
self.g5,
self.Linear
)
x = torch.randn((1,1,224,224),dtype=torch.float32)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
GoogelNet_v1 = GoogelNet(input_channels=1)
for net in GoogelNet_v1.get_All_Seq():
x = net(x)
print(net.__class__.__name__," outputshape: ",x.shape)
# 载入数据
train_data,test_data = d2I.load_data_fashion_mnist(128,224)
d2I.train_ch6(GoogelNet_v1,train_data,test_data,10,0.01,device)