VoteNet 笔记
VoteNet
-
- 前言:
- 1.论文介绍&相关工作
- 2.Deep Hough Voting
- 3.VoteNet 结构
-
- 3.1 通过点云产生 投票(vote)
- 3.2 区域提议,从投票结果分类
- 4.损失函数
前言:
Deep Hough Voting for 3D Object Detection in Point Clouds
重新设计了一种利用raw point cloud data的方式来做,既不依赖于2D检测器的性能,也不会出现为了照顾计算量导致的细节数据丢失。那么为什么原来直接利用点云的方法没有得到如此高的精度呢?论文认为这是由于以往的方法没有根据点云的天生特点来进行设计,而是直接照搬2D的流程:提特征然后加RPN。但是点云不同于稠密的图像像素,在3D情况下目标中心附近一般没有点云,因为点云只存在于目标的表面。增大感受野可以 将距离目标中心的较近的点考虑进来,但是也会引入其他目标表面的点,因此结果往往都不尽如人意。
而论文提出的霍夫投票,将 位于目标表面的点云 用 投票生成的更加接近中心的vote点来代替,这样再进行提议生成 就能很好的解决之前的问题。
从本质上直接解决了点云检测的固有问题,抛弃了依赖2D检测器或者2D流程的所有思路。
3D检测严重依赖于2D的方法。主要有以下两种:
-
把3D点云转换为规则的网格(voxel grids 或者鸟瞰图)
-
在2D图像上做检测然后作为3D的提议
本文致力于提出一个泛化的pipeline( as generic as possible)完成点云目标检测的任务,即Votenet,克服了3D目标的中心远离其表面的点因而很难在一步内完成准确的回归的问题。
数据集:ScanNet , SUNRGBD
1.论文介绍&相关工作
介绍了之前的一些代表性工作,都是依赖于2D检测器的网络。体素化或者网格化导致信息细节丢失,而2D区域提议则将漏检所有2D检测器漏检的目标。
本文提出的网络则直接基于点云数据,不依赖于任何2D检测器(基于Point net++)
尽管Point net ++在3D分类和分割任务中取得了很大的成功,但是很少有人研究如何在3D检测中利用好它,一种Naive的思想是根据2D检测的流程,在Point net++的输出特征后面接一个RPN,得到目标框。然而点云的稀疏性导致结果不尽如人意,这里是有问题的:
-
在图像中目标中心都是有像素存在的
-
在3D情况下目标中心附近一般没有点云,因为点云只存在于目标的表面
因此,基于点云的网络很难在目标中心附近学习场景的上下文。
此外作者指出盲目增加感受野是没有效果的,只会把更多的目标中心点纳入到计算来
基于此,论文方法提出了vote机制,生成新的处于目标中心点的点云,来作为box proposals
综上,本文贡献:
-
在深度学习中引入Hough Vote机制 ,设计了一个可以端到端训练的模型,VoteNet
-
在两大数据集上的达到当时SOTA
-
深入分析了vote在点云三维目标检测中的重要性。
2.Deep Hough Voting
传统的Hough vote2D检测器:
包括离线和在线步骤。首先,在给定带注释对象边界框的图像集合的情况下,使用图像块(或其特征)与其到相应对象中心的偏移之间的存储映射来构造码本。在推断时,interest points是从图像中选择出来的,然后根据interest points 提取 patches。将这些patches与代码簿中的patches进行比较,以检索偏移量并计算投票。由于对象patches倾向于一致投票,cluster将在对象中心附近形成。最后,通过将cluster投票回溯到其生成的patches来检索目标边界。
-
基于投票的机制比区域建议网络(RPN)更适合稀疏数据。RPN必须在可能位于空白空间的对象中心附近生成建议,这会导致额外的计算。
-
投票机制基于自下而上的原则,少量的空间信息累计形成一个confident detection
-
即使CNN有较大的感受野,引入投票机制仍然有可能提升性能
为了成功将vote机制引入到deep learning中,本文 对hough vote 的部件进行了如下调整:
-
Interest Points(即seed points)过CNN提取而不是手工提取
-
Vote 生成是通过网络学习到的而不是通过codebook,此外vote location可以通过特征向量进行扩充,从而实现更好的聚合
-
Vote aggregation 通过可训练的点云处理层实现,利用投票功能,网络可以筛选出低质量的vote,并生成改进后的提议。
-
Object proposals 的坐标、维度、朝向、语义类别都可以直接从聚合的特征中生成,少了回溯vote patches的过程。
3.VoteNet 结构
整体结构:
point cloud --> seed points --> votes --> vote cluster --> boundind boxes 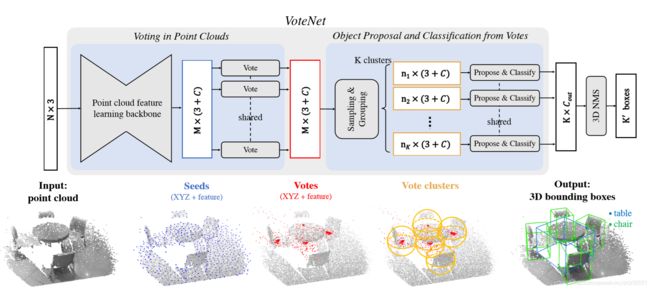
整个网络可以分成两个部分:
一个是处理现有的点云以产生vote;
另一个是在虚拟点(即vote)上运行的部分来产生提议和分类。
3.1 通过点云产生 投票(vote)
输入:
输入点云Nx3,输出M个votes,每个vote包含3D坐标和高维特征向量
点云特征学习:
使用point net++来做,输出一个带有特征向量的点云的子集(M个 seed points),每个维度是(3 + C).,一个seed point生成一个vote。
使用深度网络进行霍夫投票:
相比于使用预先计算好的码本的传统霍夫投票,这里直接使用深度网络。
输入为seed points = [ x , f ],输出为 ∆ = [ ∆x , ∆f ]
voting模块是一个全连接的多层感知网络,输出坐标偏移量∆x,以及特征偏移量 ∆f,最终得到 vote = [ x + ∆x , f + ∆f ],这样得到的vote相比于seed points 不在局限于目标的表面,更加互相接近
训练∆x的loss函数 :
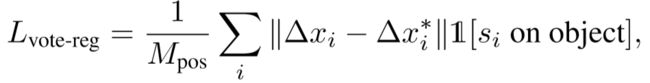
其中:Mpos是seed points 的总数, ∆x* 是ground truth
3.2 区域提议,从投票结果分类
vote点使得位于同一目标内的特征更加靠近,更易于聚类和学习上下文特征
通过采样和聚类进行投票聚类:
采用均匀抽样进行采样,通过空间接近程度进行聚类:
根据最远点采样从M个vote中采样出k个,然后通过寻找 k 个样本的邻接votes 形成k个聚类 ,论文评价这种方法简单但是有效
通过聚类中心进行提议和分类
vote本质上是一组高维空间的特征点,可以利用一个通用的点集学习网络(一个shared PointNet)来聚合vote,从而生成目标提议(一个聚类中心生成一个提议)
对于每个聚类:
-
聚类中的所有vote坐标点经过归一化后被输入到一个类pointnet的网络MLP1进行处理,相互之间独立
-
将得到的输出输入到MLP2中池化,融合各个vote的信息
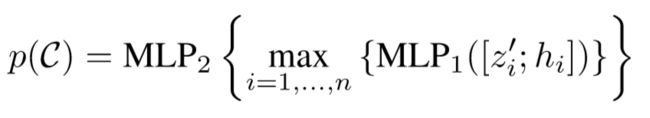
p©表示聚类C的提议向量,包含目标得分,目标框坐标,语义标签信息
4.损失函数
Vote Loss:
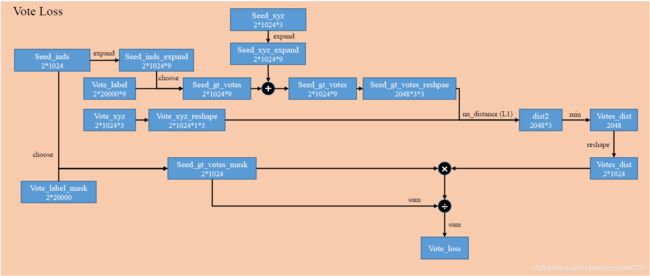
计算Vote与真值的差别,步骤如下:
-
根据Seed_inds从初始数据中的Vote_label中找到降采样后的Vote_label,然后加在Seed_xyz上得到Vote_xyz的真值,也就是Seed_gt_votes_reshape
-
通过nn_distance计算预测值与真值的差距。nn_distance的作用是计算两个储存位置信息的tensor之间的距离差,tensorA的维度为(batch,参与计算距离的点的数目,3)。所以该nn_distance是计算Vote_xyz_reshape中的一个点与Seed_gt_votes_reshape中的3个点计算距离,输出距离最小值,这样操作重复2048个点。L1表示是使用L1距离。所以dist2则是Seed_gt_votes_reshape中的3个点距离Vote_xyz_reshape中对应点的距离,然后去最小值得到Votes_dist。
-
通过Seed_inds选取mask,当seed点在物体内时,Vote_label_mask为1,其余为0,然后相乘则是使用mask使得不是物体内的点不参与loss的计算,相除是为了归一化。
Objectness Loss:
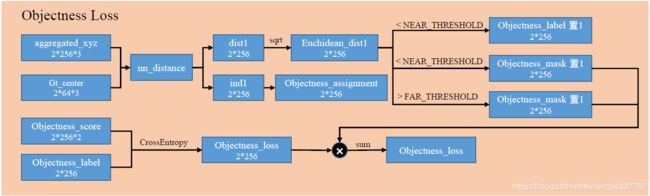
loss主要是与判断一个aggregated_vote是否是物体有关,并产生了计算box loss的mask。步骤如下:
-
计算aggregated_xyz与物体中心gt_center的距离,当距离小于NEAR_THRESHOLD时,objectness_label置1,然后当距离小于NEAR_THRESHOLD大于FAR_THRESHOLD,mask置1,mask为0的部分(既不远也不近)的部分不参与Objectness_loss计算
-
选取aggregated_xyz距离最近的gt_center,构建objectness_assignment
Box Loss:
Center Loss:
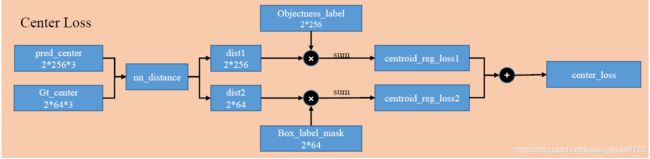
计算预测的box的center的位置偏差有关的loss。这个loss由两部分组成,下面一支代表,每个box的center都需要有一个center去预测。
Heading Loss:
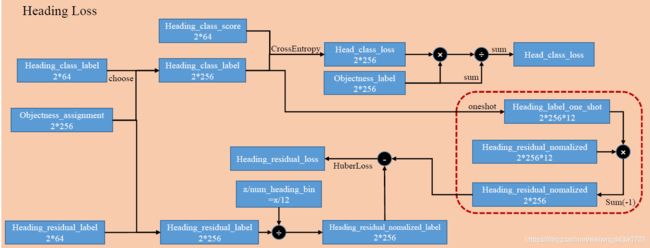
计算与box heading有关的loss,包括Classification和regression的部分,步骤如下:
-
根据Objectness_assignment从heading_class_label中选取对应的,构建label,然后与预测的heading_class_score求loss,使用objectness_label做mask,只有是objectness的部分参与计算heading_class_loss
-
根据Objectness_assignment从heading_residual_label中选取对应的,构建label,然后用角度归一化。接下来着重解释一下,由heading_class_label变成one_hot,只有正确的那个heading_class为1,其余为0,与heading_residual_nomalized相乘,使得正确的heading_class对应的那个residual不为0,其余residual为0,再相加,只不过相当于减少这个维度。
-
然后与构建Heading_residual_normalized_label去HuberLoss
Size Loss:

Semantice Classification Loss:

计算sem_cls_loss的过程,同样首先是根据objectness_assignment和sem_cls_label构建新的label,然后送入CrossEntropy计算loss
总结三部分:objectness, bounding box estimation, semantic classification losses.
-
objectness:交叉熵
-
bounding box estimation:包括中心点回归,朝向和尺寸估计。只对正样本计算,
-
semantic classification losses:交叉熵
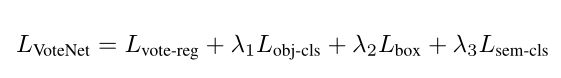
其中包含了L1距离的vote回归的loss,分类是不是目标的loss,回归bounding box的loss和分类语义的loss。其中回归bounding box的loss又由以下几部分组成:
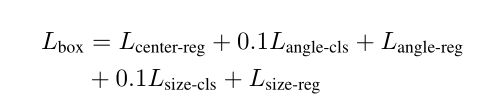
分别为回归bounding box的中心,角度以及尺度的分类和回归。其中回归中心的Loss用的是chamfer distance loss。
在计算loss时,作者对所有投票与真实目标中心近于0.3 米以内或远离任何中心(0.6 米以上)的 proposal 分别视为positive proposal 和negative proposal。对于其他 proposal 的对象性预测不进行惩罚。对于正立才计算以上的所有loss,反例只计算分类是不是目标的loss。
def compute_loss():
# 简化版的loss,可以看出loss主要包括vote_loss,objectness_loss,box_loss,sem_cls_loss
# box_loss则跟center,heading,size有关
box_loss = center_loss + 0.1*heading_cls_loss + heading_reg_loss + 0.1*size_cls_loss + size_reg_loss
loss = vote_loss + 0.5*objectness_loss + box_loss + 0.1*sem_cls_loss
def compute_vote_loss(end_points):
""" Compute vote loss: Match predicted votes to GT votes.
Args:
end_points: dict (read-only)
Returns:
vote_loss: scalar Tensor
Overall idea:
If the seed point belongs to an object (votes_label_mask == 1),
then we require it to vote for the object center.
Each seed point may vote for multiple translations v1,v2,v3
A seed point may also be in the boxes of multiple objects:
o1,o2,o3 with corresponding GT votes c1,c2,c3
Then the loss for this seed point is:
min(d(v_i,c_j)) for i=1,2,3 and j=1,2,3
"""
# Load ground truth votes and assign them to seed points
batch_size = end_points['seed_xyz'].shape[0]
num_seed = end_points['seed_xyz'].shape[1] # B,num_seed,3
vote_xyz = end_points['vote_xyz'] # B,num_seed*vote_factor,3
seed_inds = end_points['seed_inds'].long() # B,num_seed in [0,num_points-1]
# Get groundtruth votes for the seed points
# vote_label_mask: Use gather to select B,num_seed from B,num_point
# non-object point has no GT vote mask = 0, object point has mask = 1
# vote_label: Use gather to select B,num_seed,9 from B,num_point,9
# with inds in shape B,num_seed,9 and 9 = GT_VOTE_FACTOR * 3
seed_gt_votes_mask = torch.gather(end_points['vote_label_mask'], 1, seed_inds)
seed_inds_expand = seed_inds.view(batch_size,num_seed,1).repeat(1,1,3*GT_VOTE_FACTOR)
seed_gt_votes = torch.gather(end_points['vote_label'], 1, seed_inds_expand)
seed_gt_votes += end_points['seed_xyz'].repeat(1,1,3)
# Compute the min of min of distance
vote_xyz_reshape = vote_xyz.view(batch_size*num_seed, -1, 3) # from B,num_seed*vote_factor,3 to B*num_seed,vote_factor,3
seed_gt_votes_reshape = seed_gt_votes.view(batch_size*num_seed, GT_VOTE_FACTOR, 3) # from B,num_seed,3*GT_VOTE_FACTOR to B*num_seed,GT_VOTE_FACTOR,3
# A predicted vote to no where is not penalized as long as there is a good vote near the GT vote.
dist1, _, dist2, _ = nn_distance(vote_xyz_reshape, seed_gt_votes_reshape, l1=True)
votes_dist, _ = torch.min(dist2, dim=1) # (B*num_seed,vote_factor) to (B*num_seed,)
votes_dist = votes_dist.view(batch_size, num_seed)
vote_loss = torch.sum(votes_dist*seed_gt_votes_mask.float())/(torch.sum(seed_gt_votes_mask.float())+1e-6)
return vote_loss
def compute_objectness_loss(end_points):
""" Compute objectness loss for the proposals.
Args:
end_points: dict (read-only)
Returns:
objectness_loss: scalar Tensor
objectness_label: (batch_size, num_seed) Tensor with value 0 or 1
objectness_mask: (batch_size, num_seed) Tensor with value 0 or 1
object_assignment: (batch_size, num_seed) Tensor with long int
within [0,num_gt_object-1]
"""
# Associate proposal and GT objects by point-to-point distances
aggregated_vote_xyz = end_points['aggregated_vote_xyz']
gt_center = end_points['center_label'][:,:,0:3]
B = gt_center.shape[0]
K = aggregated_vote_xyz.shape[1]
K2 = gt_center.shape[1]
dist1, ind1, dist2, _ = nn_distance(aggregated_vote_xyz, gt_center) # dist1: BxK, dist2: BxK2
# Generate objectness label and mask
# objectness_label: 1 if pred object center is within NEAR_THRESHOLD of any GT object
# objectness_mask: 0 if pred object center is in gray zone (DONOTCARE), 1 otherwise
euclidean_dist1 = torch.sqrt(dist1+1e-6)
objectness_label = torch.zeros((B,K), dtype=torch.long).cuda()
objectness_mask = torch.zeros((B,K)).cuda()
objectness_label[euclidean_dist1<NEAR_THRESHOLD] = 1
objectness_mask[euclidean_dist1<NEAR_THRESHOLD] = 1
objectness_mask[euclidean_dist1>FAR_THRESHOLD] = 1
# Compute objectness loss
objectness_scores = end_points['objectness_scores']
criterion = nn.CrossEntropyLoss(torch.Tensor(OBJECTNESS_CLS_WEIGHTS).cuda(), reduction='none')
objectness_loss = criterion(objectness_scores.transpose(2,1), objectness_label)
objectness_loss = torch.sum(objectness_loss * objectness_mask)/(torch.sum(objectness_mask)+1e-6)
# Set assignment
object_assignment = ind1 # (B,K) with values in 0,1,...,K2-1
return objectness_loss, objectness_label, objectness_mask, object_assignment
def compute_box_and_sem_cls_loss(end_points, config):
""" Compute 3D bounding box and semantic classification loss.
Args:
end_points: dict (read-only)
Returns:
center_loss
heading_cls_loss
heading_reg_loss
size_cls_loss
size_reg_loss
sem_cls_loss
"""
num_heading_bin = config.num_heading_bin
num_size_cluster = config.num_size_cluster
num_class = config.num_class
mean_size_arr = config.mean_size_arr
object_assignment = end_points['object_assignment']
batch_size = object_assignment.shape[0]
# Compute center loss
pred_center = end_points['center']
gt_center = end_points['center_label'][:,:,0:3]
dist1, ind1, dist2, _ = nn_distance(pred_center, gt_center) # dist1: BxK, dist2: BxK2
box_label_mask = end_points['box_label_mask']
objectness_label = end_points['objectness_label'].float()
centroid_reg_loss1 = \
torch.sum(dist1*objectness_label)/(torch.sum(objectness_label)+1e-6)
centroid_reg_loss2 = \
torch.sum(dist2*box_label_mask)/(torch.sum(box_label_mask)+1e-6)
center_loss = centroid_reg_loss1 + centroid_reg_loss2
# Compute heading loss
heading_class_label = torch.gather(end_points['heading_class_label'], 1, object_assignment) # select (B,K) from (B,K2)
criterion_heading_class = nn.CrossEntropyLoss(reduction='none')
heading_class_loss = criterion_heading_class(end_points['heading_scores'].transpose(2,1), heading_class_label) # (B,K)
heading_class_loss = torch.sum(heading_class_loss * objectness_label)/(torch.sum(objectness_label)+1e-6)
heading_residual_label = torch.gather(end_points['heading_residual_label'], 1, object_assignment) # select (B,K) from (B,K2)
heading_residual_normalized_label = heading_residual_label / (np.pi/num_heading_bin)
# Ref: https://discuss.pytorch.org/t/convert-int-into-one-hot-format/507/3
heading_label_one_hot = torch.cuda.FloatTensor(batch_size, heading_class_label.shape[1], num_heading_bin).zero_()
heading_label_one_hot.scatter_(2, heading_class_label.unsqueeze(-1), 1) # src==1 so it's *one-hot* (B,K,num_heading_bin)
heading_residual_normalized_loss = huber_loss(torch.sum(end_points['heading_residuals_normalized']*heading_label_one_hot, -1) - heading_residual_normalized_label, delta=1.0) # (B,K)
heading_residual_normalized_loss = torch.sum(heading_residual_normalized_loss*objectness_label)/(torch.sum(objectness_label)+1e-6)
# Compute size loss
size_class_label = torch.gather(end_points['size_class_label'], 1, object_assignment) # select (B,K) from (B,K2)
criterion_size_class = nn.CrossEntropyLoss(reduction='none')
size_class_loss = criterion_size_class(end_points['size_scores'].transpose(2,1), size_class_label) # (B,K)
size_class_loss = torch.sum(size_class_loss * objectness_label)/(torch.sum(objectness_label)+1e-6)
size_residual_label = torch.gather(end_points['size_residual_label'], 1, object_assignment.unsqueeze(-1).repeat(1,1,3)) # select (B,K,3) from (B,K2,3)
size_label_one_hot = torch.cuda.FloatTensor(batch_size, size_class_label.shape[1], num_size_cluster).zero_()
size_label_one_hot.scatter_(2, size_class_label.unsqueeze(-1), 1) # src==1 so it's *one-hot* (B,K,num_size_cluster)
size_label_one_hot_tiled = size_label_one_hot.unsqueeze(-1).repeat(1,1,1,3) # (B,K,num_size_cluster,3)
predicted_size_residual_normalized = torch.sum(end_points['size_residuals_normalized']*size_label_one_hot_tiled, 2) # (B,K,3)
mean_size_arr_expanded = torch.from_numpy(mean_size_arr.astype(np.float32)).cuda().unsqueeze(0).unsqueeze(0) # (1,1,num_size_cluster,3)
mean_size_label = torch.sum(size_label_one_hot_tiled * mean_size_arr_expanded, 2) # (B,K,3)
size_residual_label_normalized = size_residual_label / mean_size_label # (B,K,3)
size_residual_normalized_loss = torch.mean(huber_loss(predicted_size_residual_normalized - size_residual_label_normalized, delta=1.0), -1) # (B,K,3) -> (B,K)
size_residual_normalized_loss = torch.sum(size_residual_normalized_loss*objectness_label)/(torch.sum(objectness_label)+1e-6)
# 3.4 Semantic cls loss
sem_cls_label = torch.gather(end_points['sem_cls_label'], 1, object_assignment) # select (B,K) from (B,K2)
criterion_sem_cls = nn.CrossEntropyLoss(reduction='none')
sem_cls_loss = criterion_sem_cls(end_points['sem_cls_scores'].transpose(2,1), sem_cls_label) # (B,K)
sem_cls_loss = torch.sum(sem_cls_loss * objectness_label)/(torch.sum(objectness_label)+1e-6)
return center_loss, heading_class_loss, heading_residual_normalized_loss, size_class_loss, size_residual_normalized_loss, sem_cls_loss