吴恩达机器学习14-降维
吴恩达机器学习14-降维
1.数据压缩
数据压缩不仅压缩数据,因而使用较少的计算机内存或磁盘空间,而且加快了学习算法的收敛速度。
如果你有几百个或成千上万的特征,它是它这往往容易失去你需要的特征。有时可能有几个不同的工程团队,也许一个工程队给你二百个特征,第二工程队给你另外三百个的特征,第三工程队给你五百个特征,一千多个特征都在一起,它实际上会变得非常困难,去跟踪你知道的那些特征,你从那些工程队得到的。其实不想有高度冗余的特征一样。
故进行数据压缩,例如:
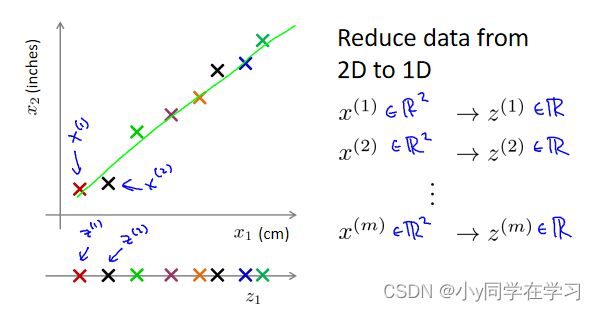
将二维降至一维。
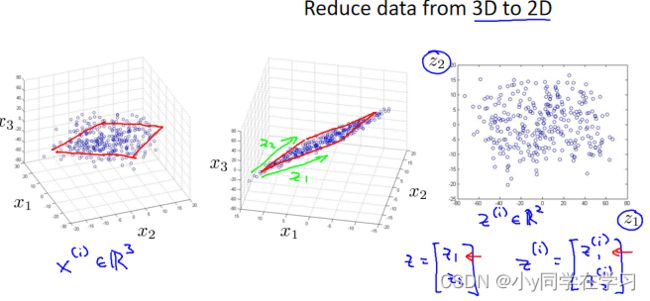
将数据从三维降至二维: 这个例子中我们要将一个三维的特征向量降至一个二维的特征向量。我们将三维向量投射到一个二维的平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量。
2.数据可视化
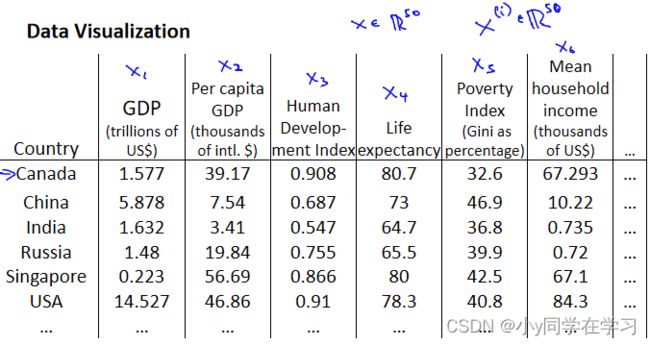
假使有关于许多不同国家的数据,每一个特征向量都有 50 个特征(如 GDP,人均 GDP,平均寿命等)。如果要将这个 50 维的数据可视化是不可能的。使用降维的方法将其降至 2 维,我们便可以将其可视化了。
原始数据:
降维结果:
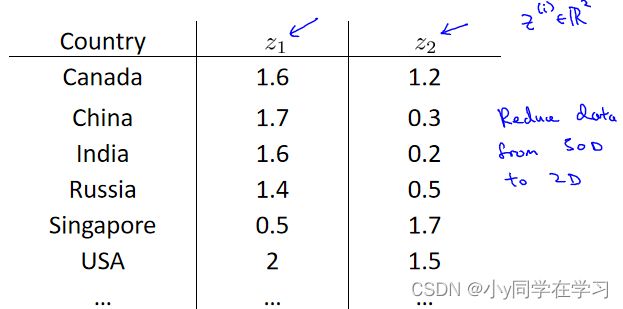
可视化:
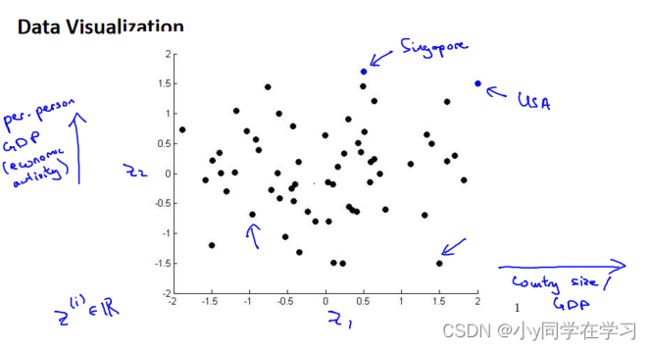
从中可以得出国家GDP和人均GDP,从而反应国民生活水平。
降维的算法只负责减少维数,新产生的特征的意义必须由我们自己去发现了。
3.主成分分析介绍
主成分分析(PCA)是最常见的降维算法。
在 PCA 中,我们要做的是找到一个方向向量,当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
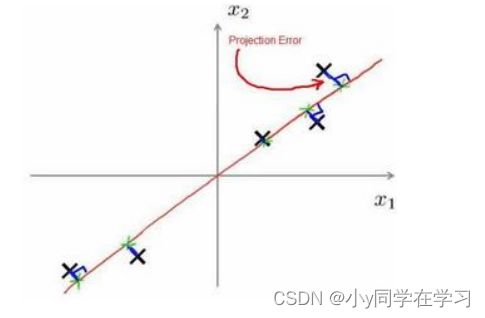
下面给出主成分分析问题的描述:
问题是要将 n 维数据降至 k 维, 目标是找到向量 u ( 1 ) , u ( 2 ) , … , u ( k ) 使得总的投射误差最小。 \text { 问题是要将 } n \text { 维数据降至 } k \text { 维, 目标是找到向量 } u^{(1)}, u^{(2)}, \ldots, u^{(k)} \text { 使得总的投射误差最小。 } 问题是要将 n 维数据降至 k 维, 目标是找到向量 u(1),u(2),…,u(k) 使得总的投射误差最小。
如下图中的品红色和红色直线,显然红色直线的投射误差最小,所以最终会选择红色直线作为方向向量
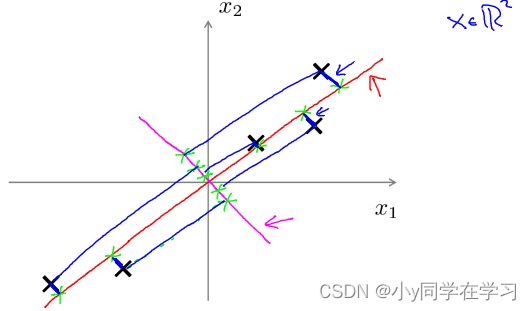
主成分分析与线性回顾的比较:
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差。而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。
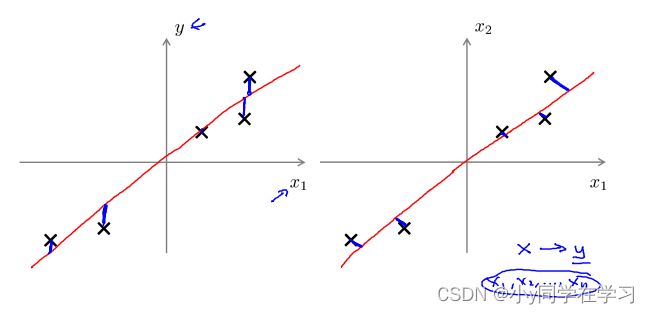
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。垂直方式存在区别
TIPS:
-
PCA要保证降维后,还要保证数据的特性损失最小
-
PCA 对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
-
PCA 技术的一个很大的优点是,它是完全无参数限制的。在 PCA 的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高
4.主成分分析算法
PCA算法从n 维减少到k维:
第一步是均值归一化。我们需要计算出所有特征的均值, 然后令 x j = x j − μ j x_{j}=x_{j}-\mu_{j} xj=xj−μj 。如果特征是在不同的数量级上, 我们还需要进行特征缩放,将其除以 m a x − m i n max-min max−min或者标准差 σ 2 \sigma^{2} σ2 。
第二步是计算协方差矩阵 $ \Sigma: \Sigma=\frac{1}{m} \sum_{i=1}{m}\left(x{(i)}\right)\left(x{(i)}\right){T}$ 其中 x ( i ) x^{(i)} x(i)是n*1,表示n个特征,m为样本个数
第三步是计算协方差矩阵 Σ \Sigma Σ 的特征向量:利用Matlab:
[U, S, V]= svd(sigma)
其中U:
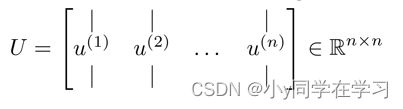
对于一个 n × n n \times n n×n 维度的矩阵, 上式中的 U 是一个具有与数据之间最小投射误差的方向向量构成的矩阵。如果我们希望将数据从n维降至k维, 我们只需要从U中选取前k个向量, 获得一个 × 维度的矩阵,我们用 U reduce U_{\text {reduce }} Ureduce 表示,然后通过如下计算获得要求的新特征向量 :
z ( i ) = U reduce T ∗ x ( i ) z^{(i)}=U_{\text {reduce }}^{T} * x^{(i)} z(i)=Ureduce T∗x(i)
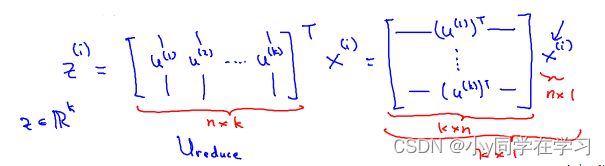
其中是 × 1维的,因此结果为 × 1维度
5.压缩重现
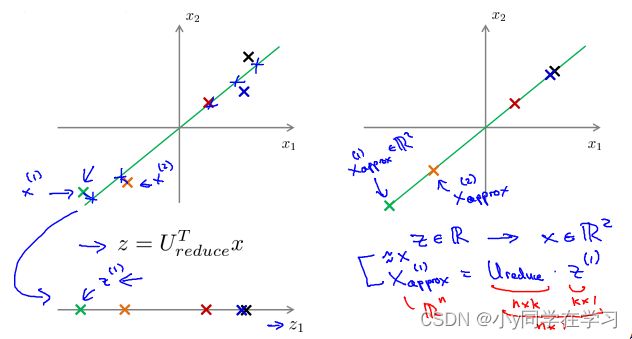
PCA 算法中样本 x ( 1 ) , x ( 2 ) x^{(1)}, x^{(2)} x(1),x(2) 。把这些样本由二维平面投射到一维平面。怎么能回去这个原始的二维空间呢?给定一个点 z ( 1 ) z^{(1)} z(1) , 我们x为2维,z为 1 维, z = U recuce T x z=U_{\text {recuce }}^{T} x z=Urecuce Tx , 相反的方程为:
x appox = U reduce ⋅ z , x appox ≈ x ∘ x_{\text {appox }}=U_{\text {reduce }} \cdot z, x_{\text {appox }} \approx x_{\circ} xappox =Ureduce ⋅z,xappox ≈x∘
6 选择主成分的数量
有两种方法可供选择,核心点是希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的值。期望的比例小于 1%,就意味着原本数据的偏差有 99%都保留下来了。
投射的平均均方误差: 1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 \frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}-x_{a p p r o x}^{(i)}\right\|^{2} m1∑i=1m∥ ∥x(i)−xapprox(i)∥ ∥2
训练集的方差为: 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 \frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}\right\|^{2} m1∑i=1m∥ ∥x(i)∥ ∥2
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 = 1 − ∑ i = 1 k s i i ∑ i = 1 n s i i ≤ 1 % \frac{\frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}-x_{a p p r o x}^{(i)}\right\|^{2}}{\frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}\right\|^{2}}=1-\frac{\sum_{i=1}^{k} s_{i i}}{\sum_{i=1}^{n} s_{i i}} \leq 1 \% m1∑i=1m∥x(i)∥2m1∑i=1m∥x(i)−xapprox(i)∥2=1−∑i=1nsii∑i=1ksii≤1%
-
第一种方法:迭代
可以先令 = 1,然后进行主要成分分析,获得和,再计算 x appox 和 x ∘ x_{\text {appox }} 和x_{\circ} xappox 和x∘,然后计算投射的平均均方误差和训练集的方差比例是否小于1%。如果不是的话再令 = 2,如此类推,直到找到可以使得比例小于 1%的最小 值
-
第二章方法:利用S矩阵
之前提到svd方法:
[U, S, V] = svd(sigma)其中的是一个 × 的矩阵,只有对角线上有值,而其它单元都是 0,我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例:
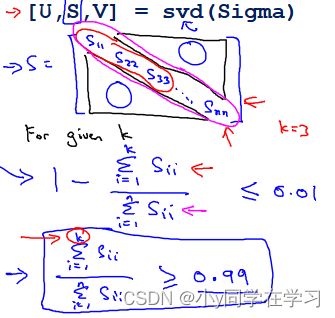
通过上述两种使k值尽可能小。
7.主成分分析法的应用建议
举例:
假使我们正在针对一张 100×100 像素的图片进行某个计算机视觉的机器学习,即总共有 10000 个特征。
-
第一步是运用主要成分分析将数据压缩至 1000 个特征
-
然后对训练集运行学习算法,如逻辑回归、神经网络等。
-
在预测时,采用之前学习而来的将输入的特征转换成特征向量,然后再进行预测
TIPS:如果我们有交叉验证集和测试集,在运行学习算法之前也采用对训练集学习而来的。
常见错误:
-
利用主成分分析解决过拟合问题:
用于减少过拟合时也减少了特征的数量,这样做非常不好,不如尝试正则化处理。原因在于主要成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。
-
认为主成分分析是必要步骤:
虽然很多时候有效果,最好还是从所有原始特征开始(更能突出本质信息),只在有必要的时候(算法运行太慢或者占用太多内存才考虑采用主要成分分析。