机器学习中的性能指标:精度、召回率,PR曲线,ROC曲线和AUC,及示例代码
机器学习中的性能指标:精度、召回率、PR曲线,ROC曲线和AUC
-
- 精度、召回率
-
- 基本概念
- F-Score
- 度量曲线
-
- PR曲线
- ROC曲线
- PR曲线和ROC曲线的比较
- AUC
精度、召回率
基本概念
可以通过下图来帮助理解
| 预测为正/阳性 | 预测为负/阴性 | 指标 | |
|---|---|---|---|
| 真值为正/阳性 | True Positive(TP) | False Negative(FN) | R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP |
| 真值为负/阴性 | False Positive(FP) | True Negative(TN) | S p e c i f i c i t y = T N T N + F P Specificity=\frac{TN}{TN+FP} Specificity=TN+FPTN |
| A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy= \frac {TP +TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN | P r e c i s i o n = T P ( T P + F P ) Precision=\frac{TP}{(TP+FP)} Precision=(TP+FP)TP | F 1 S c o r e = 2 ∗ R e c a l l ∗ P r e c i s i o n R e c a l l + P r e c i s i o n F1 Score=\frac{2*Recall *Precision}{Recall+Precision} F1Score=Recall+Precision2∗Recall∗Precision |
-
精度 ( P r e c i s i o n ) (Precision) (Precision):预测为阳性样本的准确程度。在信息检索领域也叫查准率。换句话理解:判定为阳性的正确个数除以所有判定为阳性的总素。
-
召回率 ( R e c a l l ) (Recall) (Recall):也称作敏感度(sensitivity),全部阳性样本中被预测为阳性的比例。在信息检索领域也称作查全率。
其中精度和召回率同时越高,说明模型性能越好。但精度和召回率在某些情况下是相互矛盾。例如:
阳性/阴性=50/50,模型只识别出一个为阳性,其余被识别为阴性。此时precision=1/(1+0)=100%, recall=1/(1+49)=2%.
F-Score
通过加权平均综合precision和recall,可以得到F-Score:
F S c o r e = ( 1 + a 2 ) ∗ R e c a l l ∗ P r e c i s i o n a 2 ∗ P r e c i s i o n + R e c a l l F Score=\frac{(1+a^2)*Recall *Precision}{a^2*Precision+Recall} FScore=a2∗Precision+Recall(1+a2)∗Recall∗Precision
设置 a = 1 a=1 a=1,可以得到F1-Score:
F 1 − s c o r e = 2 ∗ R e c a l l ∗ P r e c i s i o n R e c a l l + P r e c i s i o n F1-score=\frac{2*Recall *Precision}{Recall+Precision} F1−score=Recall+Precision2∗Recall∗Precision
度量曲线
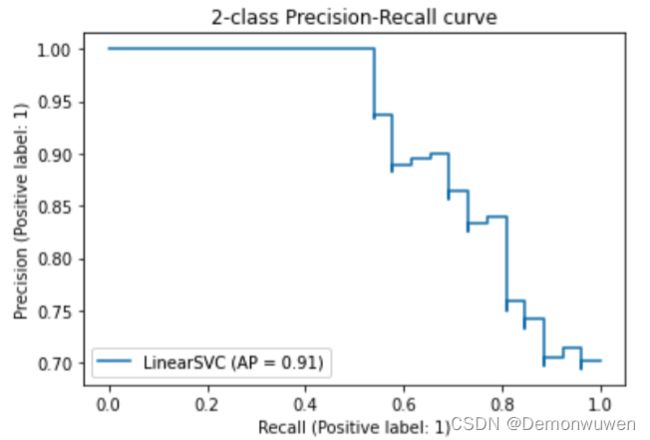
PR曲线
PR曲线(Precision-Recall Curve):
- 横轴:召回率;
- 纵轴:精度。
理想性能是右上角(1,1)处。PR曲线越往右上凸,说明模型性能越好。
PR曲线绘制方法:
- 根据模型的预测数值,对样本进行从高到低排序,排在前面的样本是正例的可能性更高。
- 按此顺序逐个样本作为正例进行预测(或设置阈值截断正例和负例),则每次可以计算一个召回率和精度。
- 将这些值连成(拟合)一条曲线。
使用scikit-learn官方代码示例:
使用鸢尾花数据集来绘制PR曲线。
from sklearn.metrics import PrecisionRecallDisplay
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)
# Add noisy features
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.concatenate([X, random_state.randn(n_samples, 200 * n_features)], axis=1)
# Limit to the two first classes, and split into training and test
X_train, X_test, y_train, y_test = train_test_split(
X[y < 2], y[y < 2], test_size=0.5, random_state=random_state
)
classifier = make_pipeline(StandardScaler(), LinearSVC(random_state=random_state))
classifier.fit(X_train, y_train)
display = PrecisionRecallDisplay.from_estimator(
classifier, X_test, y_test, name="LinearSVC"
)
_ = display.ax_.set_title("2-class Precision-Recall curve")
ROC曲线
ROC曲线(Receiver-operating-characteristic curve):
- 横轴:False Positive rate(FPR),度量所有阴性样本中被错误识别为阳性的比率。 F P R = 1 − S p e c i f i c i t y FPR=1-Specificity FPR=1−Specificity。
F P R = F P F P + T N FPR =\frac{FP}{FP+TN} FPR=FP+TNFP - 纵轴:True positive rate(TPR),即recall。度量所有阳性样本被识别为阳性的比例。
理想性能在左上角(0,1)处。ROC曲线越往左上凸,说明模型性能越好。对角线为随机识别的ROC曲线。绘制方法与PR曲线相似。
PR曲线和ROC曲线的比较
- ROC曲线:对于各类别之间样本分布比例不敏感,因为FPR和TPR各自只跟真值为负或真值为正的样本相关。
- PR曲线:对于各类别样本分布比例敏感,因为precision同时和真值正负的样本都相关。
AUC
曲线下方面积(Area under the Curve, AUC):将曲线度量所表达的信息浓缩到一个标量表达。
- A U C = 1 AUC=1 AUC=1,是完美分类起
- 0.5 < A U C < 1 0.5
- A U C = 0.5 AUC=0.5 AUC=0.5:跟随机猜测一样,模型没有预测价值
- A U C < 0.5 AUC<0.5 AUC<0.5:比随机猜想还差。
使用scikit-learn官方示例代码
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import roc_auc_score
# Import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Binarize the output
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
# Add noisy features to make the problem harder
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# shuffle and split training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
# Learn to predict each class against the other
classifier = OneVsRestClassifier(
svm.SVC(kernel="linear", probability=True, random_state=random_state)
)
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
plt.figure(dpi=100)
lw = 2
plt.plot(
fpr[2],
tpr[2],
color="darkorange",
lw=lw,
label="ROC curve (area = %0.2f)" % roc_auc[2],
)
plt.plot([0, 1], [0, 1], color="navy", lw=lw, linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Receiver operating characteristic example")
plt.legend(loc="lower right")
plt.show()
如图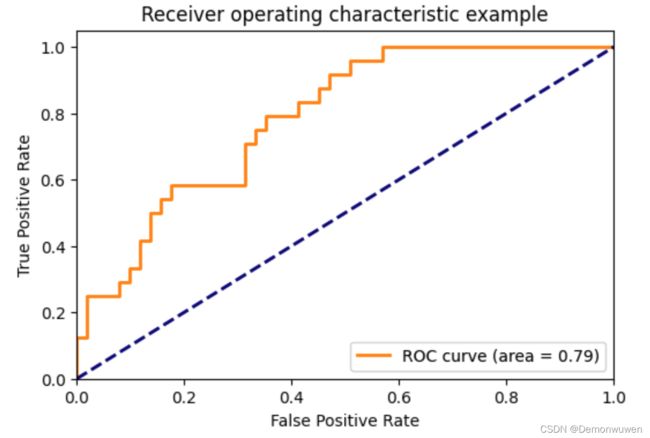
参考文献
[1]: 中国大学慕课-模式识别与机器学习
[2]: scikit-learn