大数据之Hadoop企业级生产调优手册(下)
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜
![]()
《大数据之Hadoop企业级生产调优手册(上)》
5 HDFS—存储优化
5.1 纠删码
5.2 异构存储(冷热数据分离)
6 HDFS—故障排除
6.1 集群安全模式
6.2 慢磁盘监控
6.3 小文件归档
7 MapReduce 生产经验
8 Hadoop 综合调优
8.1 Hadoop 小文件优化方法
8.2 测试 MapReduce计算性能
8.3 企业开发场景案例
5 HDFS—存储优化
注:演示纠删码和异构存储需要一共 5台虚拟机。尽量拿另外一套集群。提前准备 5台服务器的集群。
5.1 纠删码
5.1.1 纠删码原理
HDFS默认情况下,一个文件有 3个副本,这样提高了数据的可靠性,但也带来了 2倍的冗余开销。Hadoop3.x引入了纠删码, 采用计算的方式, 可以节省约 50%左右的存储空间。

纠删码操作相关的命令
[Tom@hadoop102 hadoop-3.1.3]$ hdfs ec
Usage: bin/hdfs ec [COMMAND]
[-listPolicies]
[-addPolicies -policyFile ]
[-getPolicy -path ]
[-removePolicy -policy ]
[-setPolicy -path [-policy ] [-replicate]]
[-unsetPolicy -path ]
[-listCodecs]
[-enablePolicy -policy ]
[-disablePolicy -policy ]
[-help ] 查看当前支持的纠删码策略
[Tom@hadoop102 hadoop-3.1.3]$ hdfs ec -listPolicies
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=DISABLED
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=ENABLED
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED纠删码策略解释
(1)RS-3-2-1024k:使用 RS编码,每 3个数据单元,生成 2个校验单元,共 5个单元,也就是说:这 5个单元中,只要有任意的 3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
(2)RS-10-4-1024k:使用 RS编码,每 10个数据单元( cell),生成 4个校验单元,共 14个单元,也就是说:这 14个单元中,只要有任意的 10个单元存在 (不管是数据单元还是校验单元,只要总数 =10),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
(3)RS-6-3-1024k:使用 RS编码,每 6个数据单元,生成 3个校验单元,共 9个单元,也就是说:这 9个单元中,只要有任意的 6个单元存在(不管是数据单元还是校验单元,只要总数 =6),就可以得到原始数据。每个单元的大小是 1024k=1024*1024=1048576。
(4)RS-LEGACY-6-3-1024k:策略和上面的 RS-6-3-1024k一样,只是编码的算法用的是 rs-legacy。
(5)XOR-2-1-1024k:使用 XOR编码(速度比 RS编码快),每 2个数据单元,生成 1个校验单元,共 3个单元,也就是说:这 3个单元中,只要有任意的 2个单元存在(不管是数据单元还是校验单元,只要总数 = 2),就可以得到原始数据。每个单元的大小是1024k=1024 * 1024=1048576。
5.1.2 纠删码案例实操

纠删码策略是给具体一个路径设置 。所有往此路径下存储的文件,都会执行此策略。默认只开启对RS-6-3-1024k策略的支持 ,如要使用别的策略需要提前启用 。
需求:将 /input目录设置为 RS-3-2-1024k策略
具体步骤
(1)开启对 RS-3-2-1024k策略的支持
[Tom@hadoop102 hadoop-3.1.3]$ hdfs ec -enablePolicy -policy RS-3-2-1024k
Erasure coding policy RS-3-2-1024k is enabled(2)在HDFS 创建目录,并设置RS-3-2-1024k 策略
[Tom@hadoop102 hadoop-3.1.3]$ hdfs dfs -mkdir /input
[Tom@hadoop102 hadoop-3.1.3]$ hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
Set RS-3-2-1024k erasure coding policy on /input(3)上传文件,并查看文件编码后的存储情况
[Tom@hadoop102 hadoop-3.1.3]$ hdfs dfs -put web.log /input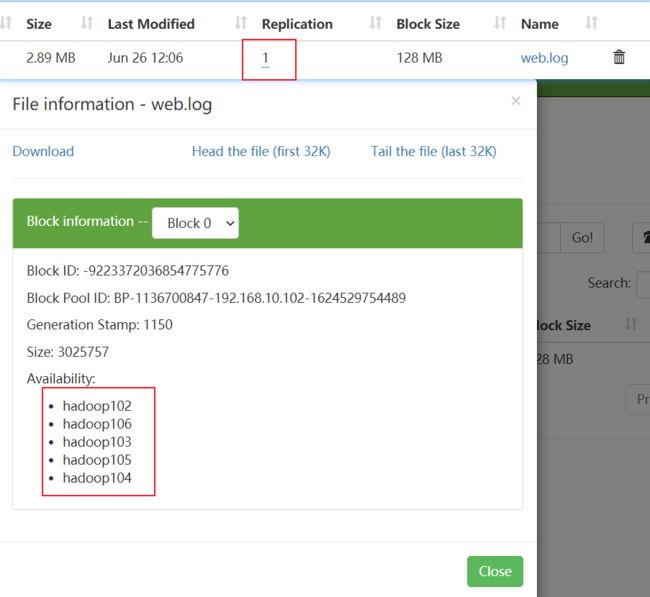
(4)查看存储路径的数据单元和校验单元,并作破坏实验
5.2 异构存储(冷热数据分离)
异构存储主要解决,不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
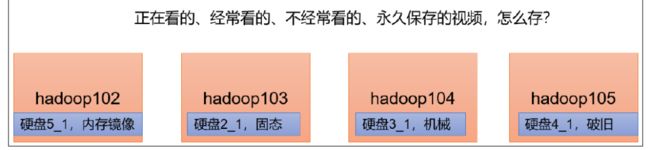
关于存储类型
RAM_DISK:(内存镜像文件系统)
SSD:(SSD固态硬盘)
DISK:(普通磁盘,在HDFS中,如果没有主动声明数据目录存储类型默认都是DISK)
ARCHIVE:(没有特指哪种存储介质,主要的指的是计算能力比较弱而存储密度比较高的存储介质,用来解决数据量的容量扩增的问题,一般用于归档)

5.2.1 异构存储Shell 操作
(1)查看当前有哪些存储策略可以用
[Tom@hadoop102 ~]$ hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}(2)为指定路径 (数据存储目录) 设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx(3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx(4)取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是 HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx(5)查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations(6)查看集群节点
hadoop dfsadmin -report5.2.2 测试环境准备
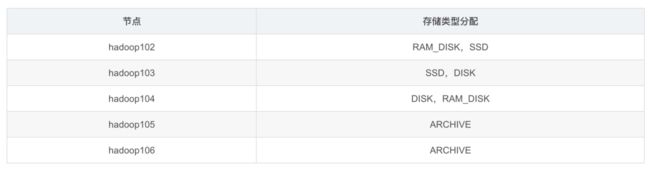
测试环境描述
服务器规模:5台
集群配置:副本数为2,创建好带有存储类型的目录(提前创建)
集群规划:
配置文件信息
(1)为 hadoop102节点的 hdfs-site.xml添加如下信息
dfs.replication
2
dfs.storage.policy.enabled
true
dfs.datanode.data.dir
[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[RAM_DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/ram_disk
(2)为 hadoop103节点的 hdfs-site.xml添加如下信息
dfs.replication
2
dfs.storage.policy.enabled
true
dfs.datanode.data.dir
[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk
(3)为 hadoop104节点的 hdfs-site.xml添加如下信息
dfs.replication
2
dfs.storage.policy.enabled
true
dfs.datanode.data.dir
[RAM_DISK]file:///opt/module/hdfsdata/ram_disk,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk
(4)为 hadoop105节点的 hdfs-site.xml添加如下信息
dfs.replication
2
dfs.storage.policy.enabled
true
dfs.datanode.data.dir
[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive
(5)为 hadoop106节点的 hdfs-site.xml添加如下信息
dfs.replication
2
dfs.storage.policy.enabled
true
dfs.datanode.data.dir
[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive
数据准备
(1)启动集群
[Tom@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
[Tom@hadoop102 hadoop-3.1.3]$ myhadoop.sh start(2)在 HDFS上创建文件目录
[Tom@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /hdfsdata(3)将文件资料上传
[Tom@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/NOTICE.txt /hdfsdata5.2.3 HOT存储策略案例
(1)最开始我们未设置存储策略的情况下,我们获取该目录的存储策略
[Tom@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -getStoragePolicy -path /hdfsdata(2)我们查看上传的文件块分布
[Tom@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata-files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]未设置存储策略,所有文件块都存储在 DISK下。所以, 默认存储策略为 HOT。
5.2.4 WARM存储策略测试
(1)接下来我们为数据降温
[Tom@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy WARM(2)再次查看文件块分布,我们可以看到文件块依然放在原处。
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata-files -blocks -locations(3)我们需要让他 HDFS按照存储策略自行移动文件块
[Tom@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(4)再次查看文件块分布
[Tom@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]文件块一半在DISK,一半在 ARCHIVE,符合我们设置的 WARM策略
5.2.5 COLD策略测试
(1)我们继续将数据降温为 cold
[Tom@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy COLD注意 :当我们将目录设置为 COLD并且我们未配置 ARCHIVE存储目录的情况下,不可以向该目录直接上传文件,会报出异常。
(2)手动转移
[Tom@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)检查文件块的分布
[Tom@hadoop102 hadoop-3.1.3]$ bin/hdfs fsck /hdfsdata -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.106:9866,DS-827b3f8b-84d7-47c6-8a14-0166096f919d,ARCHIVE]]所有文件块都在ARCHIVE,符合 COLD存储策略。
5.2.6 ONE_SSD策略测试
(1)接下来我们将存储策略从默认的 HOT更改为 One_SSD
[Tom@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy One_SSD(2)手动转移文件块
[Tom@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)转移完成后,检查文件块的分布
[Tom@hadoop102 hadoop-3.1.3]$ bin/hdfs fsck /hdfsdata -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]文件块分布为一半在SSD,一半在 DISK,符合 One_SSD存储策略。
5.2.7 ALL_SSD策略测试
(1)接下来我们将存储策略从默认的 HOT更改为 All_SSD
[Tom@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy All_SSD(2)手动转移文件块
[Tom@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)转移完成后,检查文件块的分布
[Tom@hadoop102 hadoop-3.1.3]$ bin/hdfs fsck /hdfsdata -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.102:9866,DS-c997cfb4-16dc-4e69-a0c4-9411a1b0c1eb,SSD], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]所有的文件块都存储在SSD,符合 All_SSD存储策略。
5.2.8 LAZY_PERSIST策略测试
(1)继续改变策略,将存储策略改为 lazy_persist
[Tom@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy policy lazy_persist(2)手动转移文件块
[Tom@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata(3)转移完成后,检查文件块的分布
[Tom@hadoop102 hadoop-3.1.3]$ bin/hdfs fsck /hdfsdata -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]这里我们发现所有的文件块都是存储在DISK,按照理论一个副本存储在 RAM_DISK,其他副本存储在 DISK中,这是因为,我们还需要配置"dfs.datanode.max.locked.memory","dfs.block.size"参数。
那么出现存储策略为LAZY_PERSIST 时,文件块副本都存储在 DISK 上的原因有如下两点:
(1)当客户端所在的 DataNode节点没有 RAM_DISK时,则会写入客户端所在的DataNode节点的 DISK磁盘,其余副本会写入其他节点的 DISK磁盘。
(2)当客户端所在的 DataNode有 RAM_DISK,但dfs.datanode.max.locked.memory参数值未设置或者设置过小(小于“ dfs.block.size”参数值)时,则会写入客户端所在的DataNode节点的 DISK磁盘,其余副本会写入其他节点的 DISK磁盘。
但是由于虚拟机的“max locked memory”为 64KB,所以,如果参数配置过大,还会报出错误:
ERROR org.apache .hadoop.hdfs.server.datanode.DataNode: Exception in secureMainjava.lang.RuntimeException: Cannot start datanode because the configured max locked memory size(dfs.datanode.max.locked.memory) of 209715200 bytes is more than the datanode's available RLIMIT_ MEMLOCK ulimit of 65536 bytes.我们可以通过该命令查询此参数的内存
[Tom@hadoop102 hadoop-3.1.3]$ ulimit -a max locked memory (kbytes, -l) 646 HDFS—故障排除
6.1 集群安全模式
安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求
进入安全模式场景
NameNode在加载镜像文件和编辑日志期间处于安全模式
NameNode再接收 DataNode注册时,处于安全模式

退出安全模式条件
dfs.namenode.safemode.min.datanodes:最小可用 datanode数量 ,默认 0
dfs.namenode.safemode.threshold-pct:副本数达到最小要求的 block占系统总 block数的百分比 ,默认 0.999f。(只允许丢一个块)
dfs.namenode.safemode.extension:稳定时间 ,默认值 30000毫秒,即 30秒
基本语法
集群处于安全模式,不能执行重要操作(写操作) 。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get(功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave(功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait(功能描述:等待安全模式状态)案例:集群启动后,立即来到集群上删除数据,提示集群处于安全模式

6.2 慢磁盘监控
"慢磁盘"指的时写入数据非常慢的一类磁盘。其实慢性磁盘并不少见,当机器运行时间长了,上面跑的任务多了,磁盘的读写性能自然会退化,严重时就会出现写入数据延时的问题。如何发现慢磁盘?
正常在HDFS上创建一个目录,只需要不到 1s的时间。如果你发现创建目录超过 1分钟及以上,而且这个现象并不是每次都有。只是偶尔慢了一下,就很有可能存在慢磁盘。可以采用如下方法找出是哪块磁盘慢:
通过心跳未联系时间
一般出现慢磁盘现象,会影响到DataNode与 NameNode之间的心跳。正常情况心跳时间间隔是 3s。超过 3s说明有异常。

fio命令 ,测试磁盘的读写性能
(1)顺序读测试
[Tom@hadoop102 ~]#sudo yum install -y fio
[Tom@hadoop102 ~]# sudo fio -filename=/home/Tom/test.log -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync-bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r
Run status group 0 (all jobs):
READ: bw=360MiB/s (378MB/s), 360MiB/s-360MiB/s (378MB/s-378MB/s), io=20.0GiB (21.5GB), run=56885-56885msec结果显示,磁盘的总体顺序读速度为360MiB/s
(2)顺序写测试
[Tom@hadoop102 ~]# sudofio -filename=/home/Tom/test.log -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_w
Run status group 0 (all jobs):
WRITE: bw=341MiB/s (357MB/s), 341MiB/s-341MiB/s (357MB/s-357MB/s), io=19.0GiB (21.4GB), run=60001-60001msec结果显示,磁盘的总体顺序写速度为341MiB/s
(3)随机写测试
[Tom@hadoop102 ~]#sudofio -filename=/home/Tom/test.log -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync-bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_randw
Run status group 0 (all jobs):
WRITE: bw=309MiB/s (324MB/s), 309MiB/s-309MiB/s (324MB/s-324MB/s), io=18.1GiB (19.4GB), run=60001-60001msec结果显示,磁盘的总体随机写速度为309MiB/s。
(4)顺序读测试
[Tom@hadoop102 ~]# sudo fio -filename=/home/Tom/test.log -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r_w -ioscheduler=noop
Run status group 0 (all jobs):
READ: bw=220MiB/s(231MB/s), 220MiB/s-220MiB/s (231MB/s-231MB/s), io=12.9GiB (13.9GB), run=60001-60001msec
WRITE: bw=94.6MiB/s (99.2MB/s), 94.6MiB/s-94.6MiB/s (99.2MB/s-99.2MB/s), io=5674MiB (5950MB), run=60001-60001msec结果显示,磁盘的总体混合随机读写 ,读速度为 220MiB/s,写速度 94.6MiB/s。
6.3 小文件归档
HDFS存储小文件弊端

每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此 HDFS存储小文件会非常低效。因为大量的小文件会耗尽 NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个 1MB的文件设置为 128MB的块存储,实际使用的是 1MB的磁盘空间,而不是 128MB。
解决存储小文件办法之一
HDFS存档文件或 HAR文件,是一个更高效的文件存档工具, 它将文件存入 HDFS块,在减少 NameNode内存使用的同时,允许对文件进行透明的访问。具体说来, HDFS存档文件对内还是一个一个独立文件,对 NameNode而言却是一个整体,减少了 NameNode的内存。

案例实操
(1)需要启动 YARN进程
[Tom@hadoop102 hadoop 3 1 3 ]$ start-yarn.sh(2)归档文件
把 /input目录里面的所有文件归档成一个叫 input.har的归档文件,并把归档 后文件存储到 /output路径下。
[Tom@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName input.har -p /input /output(3)查看文档
[Tom@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /output/input.har
Found 4 items
-rw-r--r-- 3 Tom supergroup 0 2021-06-26 17:26 /output/input.har/_SUCCESS
-rw-r--r-- 3 Tom supergroup 268 2021-06-26 17:26 /output/input.har/_index
-rw-r--r-- 3 Tom supergroup 23 2021-06-26 17:26 /output/input.har/_masterindex
-rw-r--r-- 3 Tom supergroup 74 2021-06-26 17:26 /output/input.har/part-0
[Tom@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///output/input.har
2021-06-26 17:33:50,362 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Found 3 items
-rw-r--r-- 3 Tom supergroup 38 2021-06-26 17:24 har:///output/input.har/shu.txt
-rw-r--r-- 3 Tom supergroup 19 2021-06-26 17:24 har:///output/input.har/wei.txt
-rw-r--r-- 3 Tom supergroup 17 2021-06-26 17:24 har:///output/input.har/wu.txt(4)解归档文件
[Tom@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:///output/input.har/* /7 MapReduce 生产经验
MapReduce 跑的慢的原因
(1)计算机性能:CPU、内存、磁盘、网络
(2)I/O 操作优化:数据倾斜;Map 运行时间太长,导致Reduce 等待过久;小文件过多
MapReduce 常用调优参数
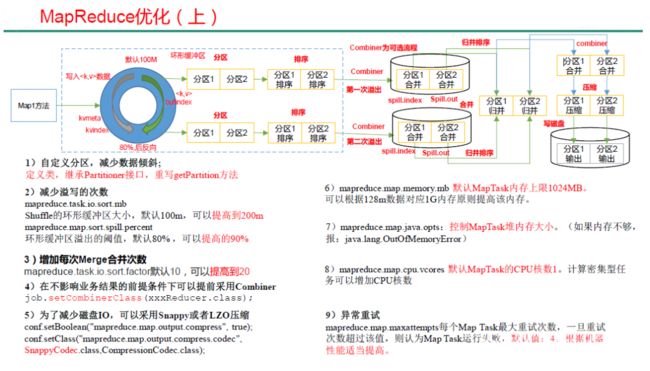

MapReduce 数据倾斜问题
数据频率倾斜——某一个区域的数据量要远远大于其他区域。数据大小倾斜——部分记录的大小远远大于平均值。
减少数据倾斜的方法
(1)首先检查是否空值过多造成的数据倾斜。生产环境,可以直接过滤掉空值;如果想保留空值,就自定义分区,将空值加随机数打散。最后再二次聚合 。
(2)能在 map阶段提前处理,最好先在 Map阶段处理。如:Combiner、 MapJoin。
(3)设置多个 reduce个数。
8 Hadoop 综合调优
8.1 Hadoop 小文件优化方法
8.1.1 Hadoop小文件弊端
HDFS上每个文件都要在 NameNode上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件 一方面会大量占用NameNode的内存空间 另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行MR计算时,会生成过多切片,需要启动过多的 MapTask。每个MapTask处理的数据量小, 导致 MapTask的处理时间比启动时间还小,白白消耗资源。
8.1.2 Hadoop小文件解决方案
1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS(数据源头)
2)Hadoop Archive(存储方向)
是一个高效的将小文件放入HDFS块中的文件存档工具,能够将多个小文件打包成一个 HAR文件,从而达到减少 NameNode的内存使用。
3)CombineTextInputFormat(计算方向)
CombineTextInputFormat用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片。
4)开启 uber模式,实现 JVM重用 (计算方向)
默认情况下,每个Task任务都需要启动一个 JVM来运行,如果 Task任务计算的数据量很小,我们可以让同一个 Job的多个 Task运行在一个 JVM中,不必为每个 Task都开启一个 JVM。
(1)未开启 uber模式,在 /input路径上上传多个小文件 并执行 wordcount程序
[Tom@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2(2)观察控制台
2021-06-26 16:18:07,607 INFO mapreduce.Job: Job job_1613281510851_0002 running in uber mode : false(3)观察 http://hadoop103:8088/cluster

(4)开启 uber模式,在 mapred-site.xml中添加如下配置
mapreduce.job.ubertask.enable
true
mapreduce.job.ubertask.maxmaps
9
mapreduce.job.ubertask.maxreduces
1
mapreduce.job.ubertask.maxbytes
(5)分发配置
[Tom@hadoop102 hadoop]$ xsync mapred-site.xml(6)再次执行 wordcount程序
[Tom@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2(7)观察控制台
2021-06-27 16:28:36,198 INFO mapreduce.Job: Job job_1613281510851_0003 running in uber mode : true(8)观察 http://hadoop103:8088/cluster
![]()
8.2 测试 MapReduce计算性能
使用Sort程序评测 MapReduce
注:一个虚拟机不超过150G磁盘尽量不要执行这段代码
(1)使用 RandomWriter来产生随机数,每个节点运行 10个 Map任务,每个 Map产生大约 1G大小的二进制随机数
[Tom@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data(2)执行 Sort程序
[Tom@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sortrandom-data sorted-data(3)验证数据是否真正排好序了
[Tom@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data8.3 企业开发场景案例
8.3.1 需求
(1)需求:从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程。
(2)需求分析:
1G / 128m = 8个MapTask;1个ReduceTask;1个mrAppMaster,平均每个节点运行10个/ 3台≈3个任务(4 3 3)
8.3.2 HDFS参数调优
(1)修改 hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS-Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS-Xmx1024m"(2)修改 hdfs-site.xml
dfs.namenode.handler.count
21
(3)修改 core-site.xml
fs.trash.interval
60
(4)分发配置
[Tom@hadoop102 hadoop]$ xsync hadoop-env.sh hdfs-site.xml core-site.xml8.3.3 MapReduce参数调优
(1)修改 mapred-site.xml
mapreduce.task.io.sort.mb
100
mapreduce.map.sort.spill.percent
0.80
mapreduce.task.io.sort.factor
10
mapreduce.map.memory.mb
-1
The amount of memory to request from the scheduler for each map task. If this is not specified or is non-positive, it is inferred frommapreduce.map.java.opts and mapreduce.job.heap.memory-mb.ratio. If java-opts are also not specified, we set it to 1024.
mapreduce.map.cpu.vcores
1
mapreduce.map.maxattempts
4
mapreduce.reduce.shuffle.parallelcopies
5
mapreduce.reduce.shuffle.input.buffer.percent
0.70
mapreduce.reduce.shuffle.merge.percent
0.66
mapreduce.reduce.memory.mb
-1
The amount of memory to request from the scheduler for each reduce task. If this is not specified or is non-positive, it is inferred
from mapreduce.reduce.java.opts and mapreduce.job.heap.memory-mb.ratio.
If java-opts are also not specified, we set it to 1024.
mapreduce.reduce.cpu.vcores
2
mapreduce.reduce.maxattempts
4
mapreduce.job.reduce.slowstart.completedmaps
0.05
mapreduce.task.timeout
600000
(2)分发配置
[Tom@hadoop102 hadoop]$ xsync mapred-site.xml8.3.4 Yarn参数调优
(1)修改 yarn-site.xml配置参数如下:
The class to use as the resource scheduler.
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
Number of threads to handle scheduler interface.
yarn.resourcemanager.scheduler.client.thread-count
8
Enable auto-detection of node capabilities such as memory and CPU.
yarn.nodemanager.resource.detect-hardware-capabilities
false
Flag to determine if logical processors(such as hyperthreads) should be counted as cores. Only applicable on Linux when yarn.nodemanager.resource.cpu-vcores is set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true.
yarn.nodemanager.resource.count-logical-processors-as-cores
false
Multiplier to determine how to convert phyiscal cores to vcores. This value is used if yarn.nodemanager.resource.cpu-vcores is set to -1(which implies auto-calculate vcores) and yarn.nodemanager.resource.detect-hardware-capabilities is set to true. Thenumber of vcores will be calculated asnumber of CPUs * multiplier.
yarn.nodemanager.resource.pcores-vcores-multiplier
1.0
Amount of physical memory, in MB, that can be allocated for containers. If set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically calculated(in case of Windows and Linux).In other cases, the default is 8192MB.
yarn.nodemanager.resource.memory-mb
4096
Number of vcores that can be allocated
for containers. This is used by the RM scheduler when allocating resources for containers. This is not used to limit the number of CPUs used by YARN containers. If it is set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically determined from the hardware in case of Windows and Linux.In other cases, number of vcores is 8 by default.
yarn.nodemanager.resource.cpu-vcores
4
The minimum allocation for every container request at the RMin MBs. Memory requests lower than this will be set to the value of thisproperty. Additionally, a node manager that is configured to have less memorythan this value will be shut down by the resource manager.
yarn.scheduler.minimum-allocation-mb
1024
The maximum allocation for every container request at the RMin MBs. Memory requests higher than this will throw anInvalidResourceRequestException.
yarn.scheduler.maximum-allocation-mb
2048
The minimum allocation for every container request at the RMin terms of virtual CPU cores. Requests lower than this will be set to thevalue of this property. Additionally, a node manager that is configured tohave fewer virtual cores than this value will be shut down by the resourcemanager.
yarn.scheduler.minimum-allocation-vcores
1
The maximum allocation for every container request at the RMin terms of virtual CPU cores. Requests higher than this will throw an InvalidResourceRequestException.
yarn.scheduler.maximum-allocation-vcores
2
Whether virtual memory limits will be enforced for containers.
yarn.nodemanager.vmem-check-enabled
false
Ratio between virtual memory to physical memory whensetting memory limits for containers. Container allocations areexpressed in terms of physical memory, and virtual memory usageis allowed to exceed this allocation by this ratio.
yarn.nodemanager.vmem-pmem-ratio
2.1
(2)分发配置
[Tom@hadoop102 hadoop]$ xsync yarn-site.xml8.3.5 执行程序
(1)重启集群
[Tom@hadoop102 hadoop-3.1.3]$ sbin/stop-yarn.sh
[Tom@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh(2)执行 WordCount程序
[Tom@hadoop102 hadoop 3.1.3]$ hadoop jar
share/hadoop/ mapreduce/hadoop mapreduce examples 3.1.3.jar
wordcount /input /output(3)观察 Yarn任务执行页面 http://hadoop103:8088/cluster/apps

八千里路云和月 | 从零到大数据专家学习路径指南
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。