从SRN_Deblur梳理去模糊领域现状
Scale-recurrent Network for Deep Image Deblurring
这是CVPR2018年的一篇论文,尽管这篇论文有它所处时间的限制(局限于网络结构的研究)但是仍然算得上是承前启后,所以试着从这篇论文出发梳理去模糊领域现状,并向前展望。
先从标题开始看

GitHub:SRN-Deblur
1.Scale:指的 multi scale 的网,那其实大概率这篇论文也是沿用了coarse-to-fine的方案(把输入图片放缩到不同尺度),coarse-to-fine在传统方法和深度学习方法里都被广泛应用。
2.recurrent:18年以前原本的Deblur基于学习的方法习惯性的只使用CNN,这篇论文中用了RNN(好像是第一篇加入RNN的deblur网络)
那么从论文名称上,我们就应该能猜到论文大体上是什么结构。
作者有五位组成,用星号标注了一作和二作相同贡献,这篇论文是18年CVPR,Hongyun Gao在这篇论文的基础上在2019CVPR又发了篇论文,后续也会单独讲下那篇论文。通信作者就是大名鼎鼎的Jiaya Jia(贾佳亚),这篇论文是18年发出,那时Jiaya大佬已经去了优图实验室,所以挂名机构里也有优图实验室,(一作和二作后来也都跟着Jiaya大佬去了优图,最近Jiaya大佬创办了思谋科技,不知道会不会也跟着过去)。另外Jue wang (王珏)大佬在旷视,所以也有旷视科技的挂名。
Abstract
Abstract部分开篇提了两点
-
一点是coarse-to-fine,说明该论文依然采用的是coarse-to-fine的方案,和论文名的Scale对应。
-
第二点应该也就是论文里最重要的一点:Compared with the many recent learning-based approaches in[25],这里的【25】就是Seungjun Nah的那篇论文。
实际上这句话就是SRN这篇论文出发点:和Seungjun Nah的那篇论文做对比。
Seungjun Nah的那篇论文的贡献主要是开了基于学习方法中kernel free先河,跳过了估计模糊核的中间过程, 算是kernel free的开山之作。但是Seungjun Nah的方法为了解决deblur任务中两个重要的需求receptive field和long range dependencies(再说的通俗一点这两个需求似乎也是大多数视觉任务的需求),用residual connections加深了网络,虽然work, 但是带来了harder to converge的问题 ,拟合慢参数量大。这个问题也就是SRN这篇论文的最重要的出发点。
1.Introduction
Introduction里首先简单介绍了去模糊研究的因和果,然后介绍了一下传统去模糊方法中存在的问题
- 首先因为去模糊本身是个ill-posed problem(也就是并没有唯一解,做图像超分辨率,或者对图像去雨去雾去模糊等等任务时,这些都没有一个标准答案,解有无数种。更重要的是,这些解都是不稳定的)问题,以致于传统方法中做去模糊之前首先要做出一些假设,包括假设模糊是均匀的,模糊是仅由相机运动产生的,模糊是局部线性的等等,但是这些假设在很大程度上影响latent image(为简便后续以‘潜像’代称)的质量,因为真实的模糊是非均匀的,真实的模糊是非线性的,真实模糊也不一定仅由相机运动产生。这一问题在Seungjun Nah的那篇论文里也提到了,也就是Seungjun Nah那篇论文的出发点(哈哈哈哈,每篇论文的出发点很重要)。
回到SRN这篇论文,
作者接下来简单的介绍了一下基于学习方法,基于学习方法实际上是以Seungjun Nah那篇论文的出现为分水岭,大体分为了基于深度学习(为简便后续以‘基于学习’代称)的核估计方法(以learning to learn deblur和孙剑大佬的首次把CNN引入到Deblur中的那篇为代表),再一个就是以Seungjun Nah这篇为代表的基于学习的kernel free方法。
这篇文章里就直接省略传统方法了,主要还是因为传统方法太难了,各种数学( ̄ー ̄),实际上基于学习的核估计方法也少有人用了。
ok,然后作者就开始介绍相对于原始基于CNN的去模糊方法,SRN引入了两个创新。
第一个是Scale-recurrent Structure
第二个是Encoder-decoder ResBlock Network
接下来会细说这两点
2.Related Work
首先回顾一下图像去模糊方法
Image/Video Deblurring
- 首先传统去模糊的两篇开创性论文
Removing Camera Shake from a Single Photograph
High-quality Motion Deblurring from a Single Image
后续的论文在这两篇的基础上发展(主体思路都是假设先验来抑制伪影),包括
T. F. Chan and C.-K. Wong. Total variation blind deconvolution. IEEE Trans. on Image Processing, 7(3):370–375, 1998.(主体思路: total variation )
A. Levin, Y. Weiss, F. Durand, and W. T. Freeman. Understanding and evaluating blind deconvolution algorithms. In CVPR, pages 1964–1971. IEEE, 2009.(主体思路:sparse image priors )
Q. Shan, J. Jia, and A. Agarwala. High-quality motion deblurring from a single image. volume 27, page 73. ACM, 2008.(主体思路: heavy-tailed gradient prior )
D. Krishnan and R. Fergus. Fast image deconvolution using hyper-laplacian priors. In NIPS, pages 1033–1041, 2009.(主体思路:hyper-Laplacian prior )
L. Xu, S. Zheng, and J. Jia. Unnatural l0 sparse representation for natural image deblurring. In CVPR, pages 1107– 1114. IEEE, 2013.(主体思路:l0-norm gradient prior )
有一点要注意的是这些传统方法全都遵循从粗到精的框架
- 然后就是引入了CNN之后的基于学习的方法
J. Sun, W. Cao, Z. Xu, and J. Ponce. Learning a convolutional neural network for non-uniform motion blur removal. In CVPR, pages 769–777. IEEE, 2015.
孙剑大佬的这篇论文将CNN首次引入了去模糊领域,
C. J. Schuler, M. Hirsch, S. Harmeling, and B. Scholkopf. ¨ Learning to deblur. TPAMI, 38(7):1439–1451, 2016.
然后是Schuler的这篇把传统方法中的从粗到精的模式引入了以CNN为基础的去模糊领域
还有Chakrabarti的(这篇没细看)
A. Chakrabarti. A neural approach to blind motion deblurring. In ECCV, pages 221–235. Springer, 2016.
下一篇是刚刚说过的以编码器-解码器网络来学习视频去模糊的,
S. Su, M. Delbracio, J. Wang, G. Sapiro, W. Heidrich, and O. Wang. Deep video deblurring. In CVPR, 2017.
最后就是 Seungjun Nah的这一篇,通过多尺度的深度网络来逐步还原清晰的图像。
CNNs for Image Processing
在这一部分介绍了图像处理中CNN的结构(为作者简化)
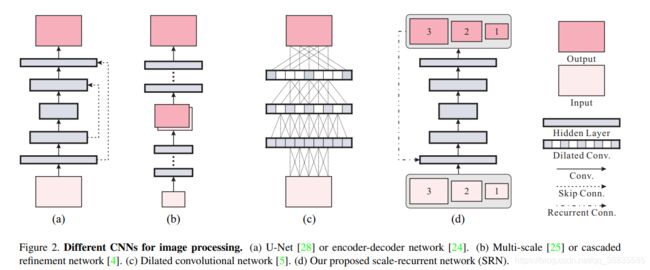
这张图是作者根据自己的理解画的其他网络的结构
- (a)图为Encoder-Decoder Networks结构
以15年U-net(引用已经快两万了)和16年NIPS上提出的REDNet为代表。这种Encoder-Decoder结构被广泛的应用于光流,去模糊,frame synthesis等领域
- (b)图为多尺度CNN 和级联优化网络(CRN)
多尺度CNN的代表性论文还是Seungjun Nah的那篇去模糊。
级联优化网络(CRN)的代表性论文为ICCV 2017的这篇Photographic Image Synthesis with Cascaded Refinement Networks,这篇论文贡献在于给出了一个不使用GAN,VAE等无监督模型也能生成真实图像的新的研究方向。提出了级联优化网络(CRN)(这篇论文我还没有细读,但是觉得思路好像很棒。作者认为想要生成真实的图像首先需要满足三点,Global coordination(感受野?)、High resolution、Memory)。
- (c)图为空洞卷积 dilated convolution (膨胀卷积或者扩张卷积)
最早提出空洞卷积的论文为
Yu, Fisher, and Vladlen Koltun. “Multi-scale context aggregation by dilated convolutions.” In ICRL. 2016.
空洞卷积的应用范围很广,后续在多个领域都相继应用到了空洞卷积。
简单来说空洞卷积的idea就是在不增加额外参数的情况下解决了pooling过程中损失信息的问题从而加大了感受野
dilated convolution的出现实际上是为了弥补pooling带来的一些问题,但是dilated convolution随后也带来了一系列的缺点,包括损失pooling的不变形以及网格效应等等,这实际上就已经是网络结构领域要研究的问题了,走的有点远了,回到我们的正题。
值得说的一点是作者这篇里引用的论文是另一篇
Q. Chen, J. Xu, and V. Koltun. Fast image processing with fully-convolutional networks. In ICCV. IEEE, 2017.
Fast image的三作就是Multi-Scale Context Aggregation by Dilated Convolutions的一作,Fast image里的结构似乎也是完全从Multi-Scale里照搬的,只不过Multi-Scale这篇是用于high-level任务中的图像分割,而Fast image把网络应用到low-level的图像处理任务中,效果非常很好,增加感受野这种思路说白了用到哪效果都是不错的~~(这样就发个ICCV,到现在已经有149个引用了,太舒服了吧)
这里有两篇关于空洞卷积的文章很棒,想要了解可以看一下。
1.如何理解空洞卷积(dilated convolution)?
2.计算机视觉论文笔记六:Multi-Scale Context Aggregation by Dilated Convolutions
3.Network Architecture
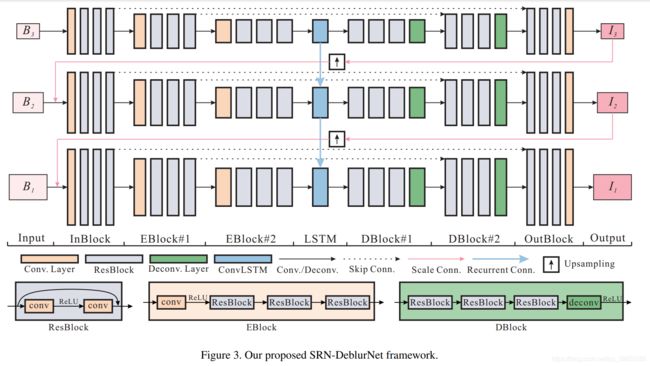
上图为原始论文里给出的结构图。
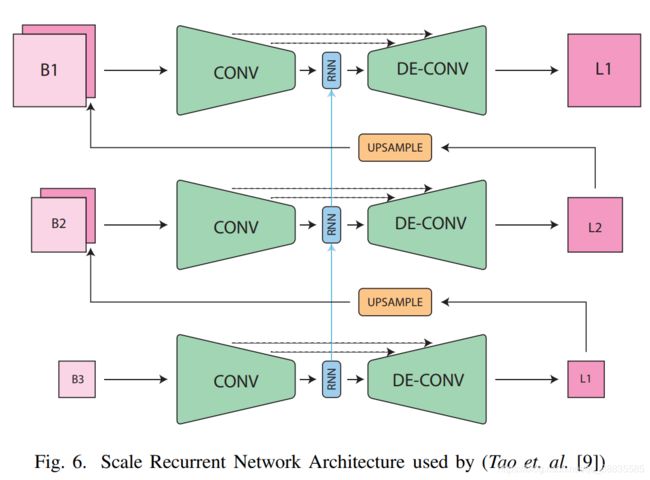
下面我们来与Seungjun Nah的那篇做一个对比,这里我使用的图片来自于这篇去模糊的综述
Siddhant Sahu, Manoj Kumar Lenka, Pankaj Kumar Sa,“Blind Deblurring using Deep Learning: A Survey” 2019
L i , h i = Net S R ( B i , L i + 1 ↑ , h i + 1 ↑ ; θ S R ) \mathbf{L}^{i}, \mathbf{h}^{i}=\operatorname{Net}_{S R}\left(\mathbf{B}^{i}, \mathbf{L}^{i+1 \uparrow}, \mathbf{h}^{i+1 \uparrow} ; \theta_{S R}\right) Li,hi=NetSR(Bi,Li+1↑,hi+1↑;θSR)

L i = G ( B i , L i + 1 ↑ ; θ S R ) \mathbf{L}^{i}=\operatorname{G}_{}\left(\mathbf{B}^{i}, \mathbf{L}^{i+1 \uparrow}; \theta_{S R}\right) Li=G(Bi,Li+1↑;θSR)
两个结构的相同点
- 都是从粗到精三个尺度
- 都用到了Resblocks来增大感受野
不同点
-
multi-scale methods
UpConV和upsampling的目的是将经过处理的L3尺度的输出图片作为B2尺度的输入图像,L2尺度的输出图片处理后传给B1尺度作为输入图像。
Seungjun Nah的论文里把这个叫做multi-scale methods, Nah里提到了也可以使用reshaping 或者 upsampling代替,但是Nah的实验过程中发现UpConV效果更好,他认为清晰和模糊的patches共享着low-frequency information,上卷积可以学到适合的特征有助于消除冗余。
SRN这篇里使用的双线性插值。
-
RNN循环网络
SRN里增加了循环网络,作者在论文中说循环网络可从RNN,LSTM,GRU,ConvLSTM中选择,作者选择了ConvLSTM,因为效果最好。
-
共享参数
这一点从图里是没办法看出来的,Seungjun Nah方法里三个尺度的参数都是分别独立的,而这一篇因为有RNN循环网络的存在,可以将三个尺度的参数共享,也就是三个尺度共用一套参数。
-
Encoder-decoder
在Seungjun Nah的基础上对网络做出一些修改,增加了“Encoder-decoder”,为什么要加引号呢,因为这里的Encoder-decoder实际上也可以说是CNN的一种
下面我将在具体讲解作者的这两点创新时,分别解释这四个不同点为什么会work.
首先Scale-recurrent Structure

原文是这样写的
原文翻译:在公认的多尺度方法中,每个尺度的solver 和相应参数通常是相同的。 从直觉上来说,这是一种自然的选择,因为在每个尺度下,我们都致力于解决相同的问题。 另外还发现,在每个尺度上变化的参数都可能导致不稳定,并导致解决方案空间不受限制的额外问题。 另一个问题是输入图像可能具有不同的分辨率和运动比例。 如果允许在每个比例中进行参数调整,则解决方案可能会过分适合特定的图像分辨率或运动比例
我们认为,出于相同的原因,该方案也应应用于基于CNN的方法。但是,最近的级联网络(这里指的是Seungjun Nah这篇),仍对其尺度使用各自独立的参数。在这项工作中,我们建议跨尺度共享网络权重,以显着降低训练难度并引入明显的稳定性好处。
优点是双重的,首先,它大大减少了可训练参数的数量。即使使用相同的训练数据,对共享权重的循环利用也以类似于多次使用数据来学习参数的方式工作,这实际上等于关于尺度的数据增强。其次,我们建议的结构可以包含循环模块,其中隐藏状态捕获有用的信息并有益于跨规模恢复
我的理解:
作者认为原本的级联网络(类似于Seungjun Nah)有一个问题是每一个尺度的参数是不共享的,那么不共享就导致了几个问题
- 其一是参数量巨大(因为每一个尺度都需要有单独的参数)
- 其二也就是我不太理解的地方,作者认为尽管在多尺度情况下,每个尺度的参数也要尽量相同的,原论文里说的是
In well-established multiscale methods, the solver and corresponding parameters at each scale are usually the same
可能在传统的Deblur方法中,多尺度间的kernel(应该也就是论文里说的solver )是相同的,后续会再了解一下。(但是不理解也没关系,后续作者给出了实验,证明了每个尺度间参数共享不仅能降低参数数量,还能明显提高性能)
- 其三是每个尺度的不同参数都意味着不同的solution space(应该就是真实图像的分布空间),那么每个尺度的不同参数也就无形中增加了solution space的大小,导致预测真实图像的难度加大
- 其四是输入图像可能具有不同的分辨率和运动比例。 如果放任每个尺度进行参数调整,则solution space可能会过分适合特定的图像分辨率或运动比例(有点过拟合的感觉)
作者在如上问题的基础上提出了Scale-recurrent Structure,主要的两点idea为使用共享权重和RNN循环模块,也就是我们上面所说的四个不同点中的两点。
然后Encoder-decoder with ResBlocks
这里的Encoder-decoder指的是像U-net那样的对称的CNN结构,但是并不是自然语言处理方向中的Encoder-decoder。该结构首先将输入数据逐步转换为具有较小空间大小和更多通道的特征图(在编码器中),然后将它们转换回输入的形状(在解码器中)。相应特征图之间的跳层连接被广泛用于组合不同级别的信息,有益于梯度传播并加速收敛,所以也可以看做另一类CNN结构。
通常,编码器包含具有strides的卷积层的多个阶段,而解码器模块使用一系列 deconvolution层或resizing来实现。
作者说这一个idea是受到其他计算机视觉任务中的Encoder-decoder的启发
给作者启发的论文包括:
Video Frame Synthesis using Deep Voxel Flow
Deep Video Deblurring
Detail-revealing Deep Video Super-resolution(这一篇也出自作者之手)
Deep Image Matting
但如上第一,二,三篇并不是去模糊方向的论文,
作者认为现有的编解码器结构无法产生最佳结果,所以在现有编解码器结构的基础上引入了residual,这样可以增加感受野,residual成了所有深度学习论文都跳不过的一个话题…
该模型以Seungjun Nah模型的四分之一训练时间和三分之一的训练参数获得了更高质量的效果。
四个不同点中我们已经讲了三个,最后一个是multi-scale methods,作者没有给出具体解释,只是说双线性插值更简单方便实验。
Losses
接下来简单说一下损失函数
论文中所用loss为
Loss = Σ k i N i ∥ I i − I ∗ i ∥ 2 2 \text {Loss}=\Sigma \frac{k_{i}}{N_{i}}\left\|I^{i}-I_{*}^{i}\right\|_{2}^{2} Loss=ΣNiki∥∥Ii−I∗i∥∥22
其中ki是每个scale的权重,默认ki为1,Ni是图像中像素的数量,起到归一化的作用。
损失函数这里作者没有给出解释,但是损失函数就那么几种,L1,L2,ssim,对抗loss…
这里用的是L2 loss的开平方,如同Adam是 较为理想的优化器一样,L2 loss也是较为理想的loss函数,因为可以更容易跑出高一点的PSNR值(至于为什么,后续有机会可以详细写一写),但是L2 loss也存在它的缺点,容易受到异常值(outliers)的影响,所以在使用的时候也要思考这个问题。
4.Experiments
数据集
(首先要说的是low level version 领域里数据集的地位其实要远高于high level version,虽然high level version里数据集也很重要)
早期基于学习的方法中通过将清晰的图像与实际或生成的均匀/不均匀模糊内核进行卷积来合成模糊图像。
比如这三篇:
A. Chakrabarti. A neural approach to blind motion deblurring. In ECCV, pages 221–235. Springer, 2016.
C. J. Schuler, M. Hirsch, S. Harmeling, and B. Scholkopf. ¨ Learning to deblur. TPAMI, 38(7):1439–1451, 2016.
J. Sun, W. Cao, Z. Xu, and J. Ponce. Learning a convolutional neural network for non-uniform motion blur removal. In CVPR, pages 769–777. IEEE, 2015.
但是这些方法有明显的缺点,由于简化了图像形成模型,所以合成数据仍然与相机捕获的数据有所不同。
在这个基础上Nah和S. Su通过对高速相机拍摄的视频中连续的短曝光帧求平均来生成模糊图像的方法提出了两个数据集
S. Nah, T. H. Kim, and K. M. Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. pages 3883–3891, 2017.(GoPro Dataset)
S. Su, M. Delbracio, J. Wang, G. Sapiro, W. Heidrich, and O. Wang. Deep video deblurring. CVPR 2017.(DeepVideoDeblurring_Dataset)
近似长时间曝光的模糊画面使得生成的帧更加逼真,更好的模拟真实照片中复杂的相机抖动和物体运动现象。
该实验中使用的数据集为GOPRO数据集,其中包含3,214个模糊/清晰图像对。遵循Nah相同的策略,使用2,103对进行训练,其余1,111对进行评估。
Model Training
参数没什么好说的,直接贴出来吧

这里指的一说的是,对于ConvLSTM的处理,由于ConvLSTM容易产生梯度爆炸问题,所以使用了gradient clip去clip ConvLSTM模块的权重(clipped by global norm 3)来稳定训练。
(我始终认为是ConvLSTM的存在才使得这个模型work,对于ConvLSTM这种捕获时空依赖的方法始终有一种迷之信赖,但是作者的论文里对ConvLSTM一笔带过了)
对于一个720 × 1280的testing image 运行时间约为1.87秒。
4.1 Multi-scale Strategy
然后作者做了一个消融实验来验证各个循环模块和多尺度策略的有效性。
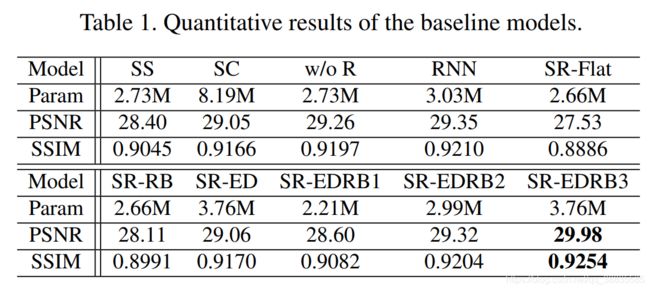
前提:所有卷积层的kernel大小3
SS模型为单尺度模型,另外循环模块被一个卷积层替代。
SC模型是Nah所提出的级联模型,由三个SS模型组成,也就是三个尺度组成,所以参数的数量要大三倍。
w/o R模型在SC模型的基础上加入了共享权重,可以看到因为共享权重的关系w/o R模型的参数量降到了和SS模型相同。
RNN模型使用 vanilla RNN 结构代替 ConvLSTM
SR-RB,SR-ED, SR-EDRB1,SR-EDRB2这三个模型是关于Encoder-decoder有效性的实验,等一下会说。
SR-EDRB3模型是最终模型( 1 InBlock -> 2 EBlocks -> 1 Convolutional LSTM block -> 2 DBlocks -> 1 OutBlock)X3(不同尺度)
(这里只对比1 Convolutional LSTM block那部分和X3那部分就可以了)
从实验中可观察到的几点结果
- 1.多尺度策略非常有效(不做实验也知道)
因为SS模型的PSNR(28.40dB)低于所有多尺度模型,我们来看一下作者论文中给出的效果图。

从视觉上看单尺度的确实效果不如多尺度,但是三尺度相对于二尺度来说效果没有太明显。
-
2.三个尺度的参数不需要分别独立。分别独立意味着三倍的参数,参数量大的情况下PSNR反而降低了,当下的很多low level version 任务里模型规模参数的大小这一点很重要。
SC模型PSNR为29.05dB,w/o R模型为29.26dB,那就没必要独立参数了。 -
另外还可以看出,vanilla RNN优于不使用 RNN,ConvLSTM可获得获得最佳结果(还是ConvLSTM)。
4.2 Encoder-decoder ResBlock Network
另外的一个消融实验就是针对Encoder-decoder ResBlock Network的有效性了
在这一部分所有基础模型都是SR模型,也就是带RNN循环模块的多尺度模型,但是作者没有提具体循环模块是什么。(ConvLSTM还是vanilla RNN?)
SR-Flat模型用 flat 的卷积层代替了编码器-解码器体系结构。
SR-RB模型用ResBlock替换了所有EBlock和DBlock,不加入stride 和 pooling来使得feature maps相似。
SR-ED模型使用原始的编码器-解码器结构,所有ResBlocks都替换为2个卷积层。
SR-EDRB1,SR-EDRB2和SR-EDRB3模型分别是指使用1、2和3 个ResBlock的模型,来比较EBlock / DBlock中不同数量的ResBlock的有效性。
从实验中可观察到的几点结果
- 1.
SR-Flat模型在PSNR和SSIM方面表现最差,甚至低于SS模型。 - 2.
SR-RB模型比SR-Flat模型要好一些,因为ResBlock结构是为更好的训练而设计的。 - 3.
SR-ED模型这里有一些问题,SR-ED模型性能出奇的好(29.06dB),但是在增加一个ResBlock模块是也就是SR-EDRB1性能反而降低了(但是说它性能降低是以PSNR为标准,事实上该论文在SRGAN之前发出,SRGAN发出之后大家对于PSNR的准确性是持怀疑态度的) - 4.随着ResBlock数量的增加,参数的数量也增加了,但是结果(
SR-EDRB1除外)也变得更好。SR-EDRB2的性能超过了SR-ED模型,3个ResBlock的效果最好。
4.3 Comparisons
然后就是与其他动态去模糊论文做的比较了。


由于图片太大,全部截图的话没办法看清楚,所以这里只截取了一部分对比图,原图可以去论文中看。
5. Conclusion
这篇文论实际上还是在模型结构上下功夫
在传统图像去模糊中“粗到细”方案的基础下,增加了规模递归网络(ConvLSTM),以及在每个尺度中的将增加了编码器-解码器ResBlocks结构。
这种新的网络结构的优点是比以前的多尺度去模糊模型具有更少的参数,并且更易于训练。
6.展望
刚开始学习deblur不久,暂时还谈不上什么展望,所以只是总结了一些大佬的观点。
现在low-level vision的热点方向是什么?
当前超分辨率有何可进行优化或创新的方向?
如何评价近几年顶会的超分,去噪,去模糊等图像复原文章?
如何评价近几年顶会的超分,去噪,去模糊等图像复原文章?
1.首先,low level version任务不同于hig level version任务,各个子领域如Deblur、Denoising、Derain、Dehaze、SR、Inpainting、Deblocking虽然不尽相同,但是却有一定的相关性。另外,hig level version的网络结构似乎有时候也可以直接照搬拿到low level version任务中,依然能取得好的效果。
2.网络设计方面
- 注意力?
- residual, 级联, 权重共享,空洞卷积(已经被用烂了)
A Deep Journey into Super-resolution: A Survey
以超分领域最近的这篇综述论文来看,从网络结构上找出发点基本上是无用功了,大家都是在搭积木。
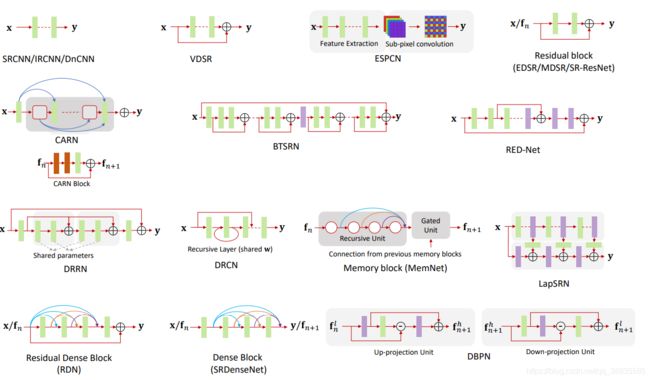
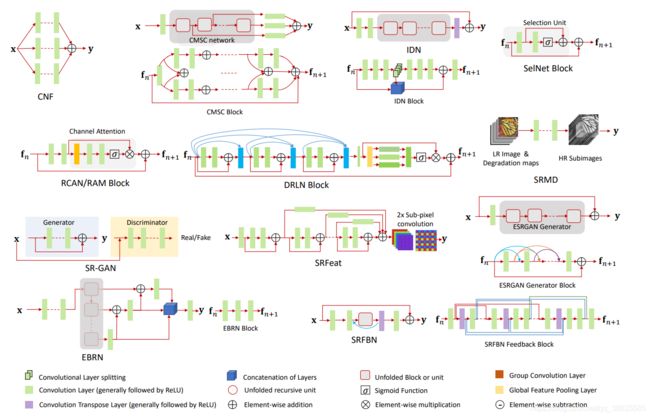
-
参数量
这一点似乎还是可以挖掘的,参数量始终还是限制学界和工业界交流的一个障碍,是否可以通过剪枝,知识蒸馏等方法让这些low level version任务更好的落地。
-
采样的方法
这一点以超分领域Pixel Shuffle为代表,去模糊领域是否有更好的采样方法。
-
时空依赖
SRN这篇使用了ConvLSTM但是似乎是没有更好的利用ConvLSTM,有没有什么方法能改善这一点
-
损失函数
组合损失函数,对抗损失函数,L2,L1还是有改进的空间的?
接下来是最有希望或者说最有意义的两点
3.数据集
能不能手机更接近与真实场景的训练数据,去模糊领域里,实际上并没有真的需要被去模糊的图片,但是如果用真实的图片作为训练的话那就没有可供参考的GT,也就无从计算loss了,当下去模糊领域两个常用的数据集GOPRO数据集和REDS数据集都是Nah提出的。
是否可以使用长、短焦距的镜头来拍摄图像对,或者普通相机和高速相机的图像对来做blur image和GT呢,那就涉及图片对齐的问题了。
4.评价指标
实际上不只是low level version领域没有好的评价指标,绝大多数AI方向的评价指标都或多或少有些问题。Detection和Segmentation等领域能够快速的发展是不是也得益于有一个相对较好的评价指标呢。
cvpr2017发表的SRGAN出来后大家发现PSNR并不一定是一个好的指标。
第三幅图是要比第二幅图清晰的,但是却没有得到一个好的PSNR结果,找到一个好的评价指标显然是一个更有意义的研究。
欢迎讨论