kaggle平台学习复习笔记 | pandas
目录
-
- 1.Creating, Reading and Writing
- 2.Indexing, Selecting & Assigning
- 3.Summary Functions and Maps
- 4.Grouping and Sorting
- 5.Data Types and Missing Values
- 6.Renaming and Combining
获得开展独立数据科学项目所需的技能。
1.Creating, Reading and Writing
DataFrame是一个表。它包含一个单独条目的数组,每个条目都有一个特定的值。每个条目对应一行(或记录)和一列。
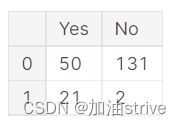
reviews = pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
DataFrame条目不限于整数。例如,这里有一个DataFrame,其值为字符串:
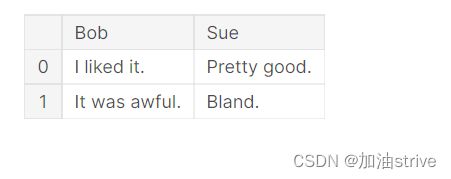
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
DataFrame中使用的行标签列表称为索引。我们可以在构造函数中使用索引参数为其赋值:
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])

Series
Series是一系列数据值。如果DataFrame是表,则Series是列表。事实上,您可以创建一个列表:
pd.Series([1, 2, 3, 4, 5])

pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')

Reading data files
我们可以使用shape属性检查生成的DataFrame的大小:
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv")
wine_reviews.shape

wine_reviews.head()
我们可以使用head()命令检查结果DataFrame的内容,该命令获取前五行

pd.read_csv()函数具有很好的特性,可以指定30多个可选参数。例如,您可以在这个数据集中看到CSV文件有一个内置索引,panda并没有自动获取该索引。为了使panda使用该列作为索引(而不是从头创建一个新列),我们可以指定一个index_col。
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()

2.Indexing, Selecting & Assigning
一个book对象可能有一个title属性,我们可以通过调用book.title来访问它。panda DataFrame中的列的工作方式大致相同。
选取列 注:reviews是1-2建立的dataframe
reviews.country
或
reviews['country']
选取该列的第一个元素
reviews['country'][0]
Index-based selection
基于index的选择
iloc选取 (前三行,前三列)
reviews.iloc[:3,:2]
reviews.iloc[[0, 1, 2], [0,1]]
iloc选取 (后5行)
print(df.iloc[-5:,:])
Label-based selection
基于标签的选择
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
reviews.loc[0, 'country']
Conditional selection
条件选择
reviews.country == 'Italy'

选择符合条件的行
reviews.loc[reviews.country == 'Italy']

可以使用多个条件 (‘并’用‘&’ 。。。 ‘或’用 ‘|’)不能用and和or
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]
isin函数的使用
选取‘Italy’和France两个城市
reviews.loc[reviews.country.isin(['Italy', 'France'])]
notnull函数的使用
reviews.loc[reviews.price.notnull()]
Assigning data
reviews['critic'] = 'everyone'
reviews['critic']

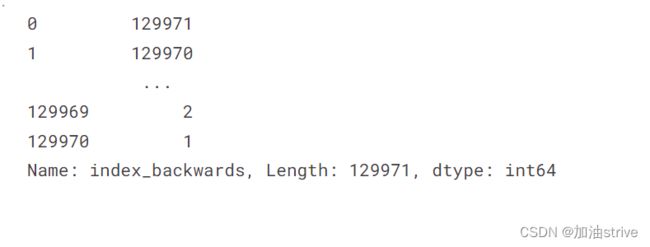
reviews['index_backwards'] = range(len(reviews), 0, -1)
reviews['index_backwards']
3.Summary Functions and Maps
对于数值型的数据,显示字段的平均值,最大值,最小值等
reviews.points.describe()

对于字符串,显示
reviews.taster_name.describe()

count 共多少个非空的值
unique 几个不同的值
top 出现最频繁的值
freq 出现最频繁的值的次数
reviews.points.mean()
reviews.taster_name.unique() # 效果同上
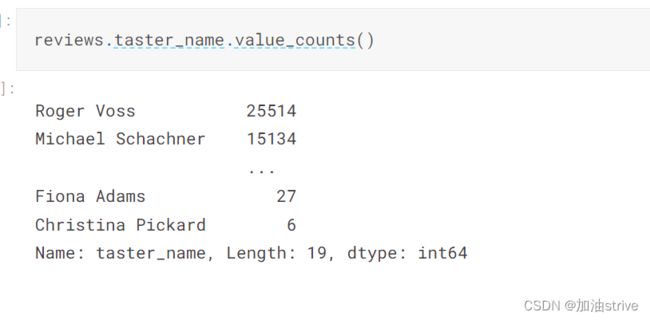
reviews.taster_name.value_counts() # 显示哪个值出现了多少次
Map() 和 apple()函数的应用
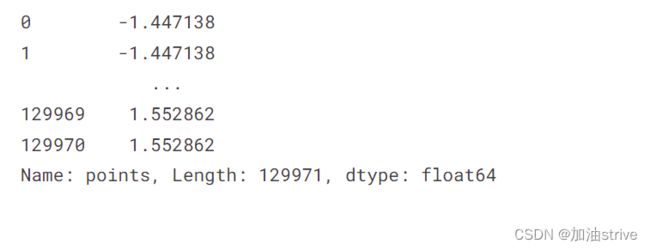
review_points_mean = reviews.points.mean()
reviews.points.map(lambda p: p - review_points_mean)
def remean_points(row):
row.points = row.points - review_points_mean
return row
reviews.apply(remean_points, axis='columns')
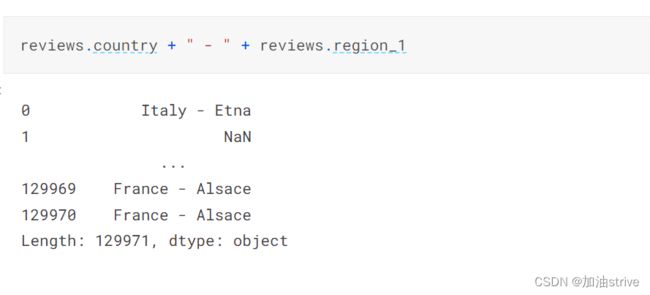
字符串拼接
4.Grouping and Sorting
reviews.groupby('points').points.count()

这里有一种方法可以选择数据集中每个酒庄的第一款葡萄酒的名称
reviews.groupby('winery').apply(lambda df: df.title.iloc[0])
以下是我们如何按国家和省份挑选最好的葡萄酒
reviews.groupby(['country', 'province']).apply(lambda df: df.loc[df.points.idxmax()])
另一个值得一提的groupby()方法是agg(),它允许您同时在DataFrame上运行一系列不同的函数。例如,我们可以生成数据集的简单统计摘要,如下所示:
reviews.groupby(['country']).price.agg([len, min, max])

多重索引
reviews.groupby(['country', 'province']).apply(lambda df: df.loc[df.points.idxmax()])

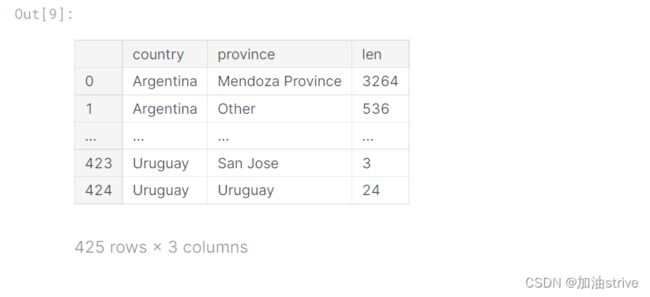
countries_reviewed = reviews.groupby(['country', 'province']).description.agg([len])
countries_reviewed

然而,通常情况下,您最常用的多索引方法是用于转换回常规索引的方法,即reset_index()方法:
countries_reviewed.reset_index()
对比上图比较区别
Sorting
按值排序
默认升序
countries_reviewed = countries_reviewed.reset_index()
countries_reviewed.sort_values(by='len')

降序排序
countries_reviewed.sort_values(by='len', ascending=False)
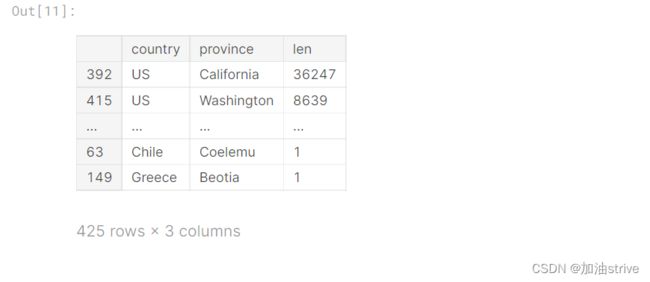
按索引排序
countries_reviewed.sort_index()
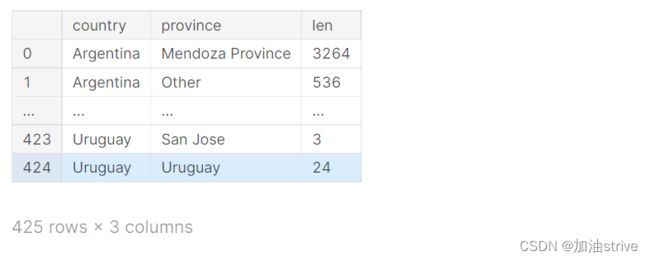
最后,要知道您可以一次按多个列排序:
注:先按照country排序,再按照len排序
countries_reviewed.sort_values(by=['country', 'len'])

5.Data Types and Missing Values
reviews.dtypes

reviews.points.astype('float64')

Pandas提供了一些特定于缺失数据的方法。要选择NaN条目,可以使用pd.isnull()(或其伴随的pd.notnull())
reviews[pd.isnull(reviews.country)]
fillna函数
将NAN替换为Unknow
reviews.region_2.fillna("Unknown")
将non-NAN的字符串替换为想要的字符串
reviews.taster_twitter_handle.replace("@kerinokeefe", "@kerino")
6.Renaming and Combining
将points字段名改为score
reviews.rename(columns={'points': 'score'})
将第1行和第2行的索引值改为指定索引
reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'})
行索引和列索引都可以有自己的name属性。可以使用补充的rename_axis()方法来更改这些名称。例如:
merge、concat、join
# 可以指定按照两组数据的共同键值对合并或者左右各自
# left: DataFrame
# right: 另一个DataFrame
# on: 指定的共同键
# how:按照什么方式连接
pd.merge(left, right, how='inner', on=None)
# 按照行或列进行合并,axis=0为列索引,axis=1为行索引
pd.concat([data1, data2], axis=1)
就复杂性而言,最中间的组合器是join()。join()允许您组合具有共同索引的不同DataFrame对象。例如,要删除恰好在加拿大和英国同一天流行的视频,我们可以执行以下操作:
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date'])
left.join(right, lsuffix='_CAN', rsuffix='_UK')