深度学习课程项目
文章目录
- 多元线性回归的随机梯度方法
-
- 代码
- 效果
- 原理
-
- 实值函数线性模型
- 实值函数线性基函数模型 linear basis function model
- 实值函数线性基函数模型求导的矩阵形式解 derivation
- 实值函数线性基函数模型参数求解的解析解 closed form solution
- 向量值函数广义线性模型
- Tips
- KNN识别CIFAR10
-
- 1NN
-
- 代码
- 效果
- KNN
-
- 代码
- 效果
多元线性回归的随机梯度方法
代码
import numpy as np
w=np.array([5,3,4]).transpose()
b=np.array([100])
def compute_error_for_given_points(b,w,points):
totalError = 0
for i in range(0, len(points)):
x = points[i].x
y = points[i].y
totalError += (y-(np.dot(w,x)+b)) ** 2
return totalError / float(len(points))
def step_gradient(b_current, w_current, points, learningRate):
b_gradient = 0
w_gradient = np.zeros((len(w_current)))
N = float(len(points))
for i in range(0, len(points)):
x = points[i].x
y = points[i].y
residual = np.dot(w_current,x)+b_current - y
b_gradient += (2) * residual
w_gradient += (2/N) * residual * x
new_b = b_current - (learningRate * b_gradient)
new_w = w_current - (learningRate * w_gradient)
return [new_b, new_w]
def gradient_descent_runner(starting_b, starting_w, points, learning_rate, num_iterations):
b = starting_b
w = starting_w
percent_old = 0
for i in range(num_iterations):
percent = i/num_iterations
if percent-percent_old > 0.01:
percent_old = percent
print("\r进度为{:.2f}%".format(percent*100), end="")
b, w = step_gradient(b, w, points, learning_rate)
print("\n")
return [b, w]
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
x = np.random.random((1000,3))*10+10
y = b + np.matmul(x,w) + np.random.normal(0, 1, 1000)
# points = tf.data.Dataset.from_tensor_slices((x,y))
points = np.ndarray((1000), dtype=Point)
for i in range(1000):
points[i] = Point(x[i], y[i])
loss = compute_error_for_line_given_points(0, np.array([0,0,0]), points)
print(f"loss before: {loss}")
b, w = gradient_descent_runner(0, np.array([0,0,0]), points, 0.0001, 5000)
loss = compute_error_for_line_given_points(b, w, points)
print(f"loss after: {loss}")
print(f"{b} + {w}*x")
效果

原理
实值函数线性模型
损失函数为 M S E 时, L ( w ) = 1 n Σ i = 1 n ( f ^ ( x ( i ) ) − y ( i ) ) 2 。当模型为 f ^ ( x ) = y ^ = b + Σ i = 1 d w i x i 时, ∂ L ( w ) ∂ b = 2 n Σ i = 1 n ( y ^ ( i ) − y ( i ) ) , ∂ L ( w ) ∂ w j = 2 n Σ i = 1 n ( y ^ ( i ) − y ( i ) ) x j ( i ) 。由对向量求导的定义得: ∂ L ( w ) ∂ w = 2 n Σ i = 1 n ( y ^ ( i ) − y ( i ) ) x ( i ) 。将 b 视为 w 0 的增广形式结果类似,只需 x 0 固定为 1. 损失函数为MSE时,L(\boldsymbol w)= \frac {1}{n}\Sigma_{i=1}^n (\hat f(\boldsymbol x^{(i)})- y^{(i)})^2 。当模型为\hat f(\boldsymbol x)=\hat y=b+\Sigma_{i=1}^d w_ix_i时,\frac{\partial L(\boldsymbol w)}{\partial b}=\frac {2}{n}\Sigma_{i=1}^n (\hat y^{(i)}- y^{(i)}),\frac{\partial L(\boldsymbol w)}{\partial w_j}=\frac {2}{n}\Sigma_{i=1}^n (\hat y^{(i)}- y^{(i)})x^{(i)}_j。由对向量求导的定义得:\frac{\partial L(\boldsymbol w)}{\partial \boldsymbol w}=\frac {2}{n}\Sigma_{i=1}^n (\hat y^{(i)}- y^{(i)})\boldsymbol x^{(i)}。将b视为w_0的增广形式结果类似,只需x_0固定为1. 损失函数为MSE时,L(w)=n1Σi=1n(f^(x(i))−y(i))2。当模型为f^(x)=y^=b+Σi=1dwixi时,∂b∂L(w)=n2Σi=1n(y^(i)−y(i)),∂wj∂L(w)=n2Σi=1n(y^(i)−y(i))xj(i)。由对向量求导的定义得:∂w∂L(w)=n2Σi=1n(y^(i)−y(i))x(i)。将b视为w0的增广形式结果类似,只需x0固定为1.
实值函数线性基函数模型 linear basis function model
当模型为 f ^ ( x ) = y ^ = Σ i = 0 m w i ϕ i ( x ) 时 , 当模型为\hat f(\boldsymbol x)=\hat y=\Sigma_{i=0}^m w_i \phi_i (\boldsymbol x)时, 当模型为f^(x)=y^=Σi=0mwiϕi(x)时,
其中 ϕ i ( x ) 为 d 元实值函数,可退化为 P o l y n o m i a l : x i i , G u s s i a n : e ( x i − μ i ) 2 2 σ i 2 , S i g m o i d a l : 1 1 + e x i − μ i σ i . 并保持 ϕ 0 ( x ) ≡ 1 其中\phi_i(\boldsymbol x)为d元实值函数,可退化为Polynomial:x_i^i, Gussian:e^{\frac{(x_i-\mu_i)^2}{2\sigma_i^2}}, Sigmoidal:\frac{1}{1+e^{\frac{x_i-\mu_i}{\sigma_i}}}.并保持\phi_0(\boldsymbol x)\equiv1 其中ϕi(x)为d元实值函数,可退化为Polynomial:xii,Gussian:e2σi2(xi−μi)2,Sigmoidal:1+eσixi−μi1.并保持ϕ0(x)≡1
上述求导结果变为 ∂ L ( w ) ∂ w = 2 n Σ i = 1 n ( y ^ ( i ) − y ( i ) ) ϕ ( x ( i ) ) 上述求导结果变为\frac{\partial L(\boldsymbol w)}{\partial \boldsymbol w}=\frac {2}{n}\Sigma_{i=1}^n (\hat y^{(i)}- y^{(i)})\boldsymbol \phi(\boldsymbol x^{(i)}) 上述求导结果变为∂w∂L(w)=n2Σi=1n(y^(i)−y(i))ϕ(x(i))
实值函数线性基函数模型求导的矩阵形式解 derivation
在求解 ∂ L ( w ) ∂ w = 0 时需要将上式中的 w 分离 . 即对 n 个向量求和为 0 向量问题需转化为矩阵问题 在求解\frac{\partial L(\boldsymbol w)}{\partial \boldsymbol w}=\boldsymbol 0时需要将上式中的\boldsymbol w分离.即对n个向量求和为0向量问题需转化为矩阵问题 在求解∂w∂L(w)=0时需要将上式中的w分离.即对n个向量求和为0向量问题需转化为矩阵问题
Σ i = 1 n ( y ^ ( i ) − y ( i ) ) ϕ ( x ( i ) ) \Sigma_{i=1}^n (\hat y^{(i)}- y^{(i)})\boldsymbol \phi(\boldsymbol x^{(i)}) Σi=1n(y^(i)−y(i))ϕ(x(i))
= Σ i = 1 n ϕ ( x ( i ) ) ( y ^ ( i ) − y ( i ) ) =\Sigma_{i=1}^n \boldsymbol \phi(\boldsymbol x^{(i)})(\hat y^{(i)}- y^{(i)}) =Σi=1nϕ(x(i))(y^(i)−y(i))
= ( ϕ ( x ( 1 ) ) , ϕ ( x ( 2 ) , ) ⋯ , ϕ ( x ( n ) ) ⋅ ( y ^ ( 1 ) − y ( 1 ) , y ^ ( 2 ) − y ( 2 ) , ⋯ , y ^ ( n ) − y ( n ) ) ′ =(\boldsymbol \phi(\boldsymbol x^{(1)}),\boldsymbol \phi(\boldsymbol x^{(2)},)\cdots,\boldsymbol \phi(\boldsymbol x^{(n)})\cdot (\hat y^{(1)}- y^{(1)},\hat y^{(2)}- y^{(2)},\cdots,\hat y^{(n)}- y^{(n)})' =(ϕ(x(1)),ϕ(x(2),)⋯,ϕ(x(n))⋅(y^(1)−y(1),y^(2)−y(2),⋯,y^(n)−y(n))′
= ( ϕ ( x ( 1 ) ) , ϕ ( x ( 2 ) ) , ⋯ , ϕ ( x ( n ) ) ⋅ ( w ′ ϕ ( x ( 1 ) ) − y ( 1 ) , w ′ ϕ ( x ( 2 ) ) − y ( 2 ) , ⋯ , w ′ ϕ ( x ( n ) ) − y ( n ) ) =(\boldsymbol \phi(\boldsymbol x^{(1)}),\boldsymbol \phi(\boldsymbol x^{(2)}),\cdots,\boldsymbol \phi(\boldsymbol x^{(n)})\cdot \left( %左括号 \begin{array}{c} %该矩阵一共3列,每一列都居中放置 \boldsymbol w' \boldsymbol \phi(\boldsymbol x^{(1)})- y^{(1)},\\ \boldsymbol w' \boldsymbol \phi(\boldsymbol x^{(2)})- y^{(2)},\\ \cdots,\\ \boldsymbol w' \boldsymbol \phi(\boldsymbol x^{(n)})- y^{(n)} \end{array} \right) =(ϕ(x(1)),ϕ(x(2)),⋯,ϕ(x(n))⋅ w′ϕ(x(1))−y(1),w′ϕ(x(2))−y(2),⋯,w′ϕ(x(n))−y(n)
= ( ϕ ( x ( 1 ) ) , ϕ ( x ( 2 ) ) , ⋯ , ϕ ( x ( n ) ) ⋅ ( ϕ ( x ( 1 ) ) ′ w − y ( 1 ) , ϕ ( x ( 2 ) ) ′ w − y ( 2 ) , ⋯ , ϕ ( x ( n ) ) ′ w − y ( n ) ) =(\boldsymbol \phi(\boldsymbol x^{(1)}),\boldsymbol \phi(\boldsymbol x^{(2)}),\cdots,\boldsymbol \phi(\boldsymbol x^{(n)})\cdot \left( %左括号 \begin{array}{c} %该矩阵一共3列,每一列都居中放置 \boldsymbol \phi(\boldsymbol x^{(1)})'\boldsymbol w- y^{(1)},\\ \boldsymbol \phi(\boldsymbol x^{(2)})'\boldsymbol w- y^{(2)},\\ \cdots,\\ \boldsymbol \phi(\boldsymbol x^{(n)})'\boldsymbol w- y^{(n)} \end{array} \right) =(ϕ(x(1)),ϕ(x(2)),⋯,ϕ(x(n))⋅ ϕ(x(1))′w−y(1),ϕ(x(2))′w−y(2),⋯,ϕ(x(n))′w−y(n)
= ( ϕ ( x ( 1 ) ) , ϕ ( x ( 2 ) ) , ⋯ , ϕ ( x ( n ) ) ⋅ ( ( ϕ ( x ( 1 ) ) ′ , ϕ ( x ( 2 ) ) ′ , ⋯ , ϕ ( x ( n ) ) ′ ) w − y ) =(\boldsymbol \phi(\boldsymbol x^{(1)}),\boldsymbol \phi(\boldsymbol x^{(2)}),\cdots,\boldsymbol \phi(\boldsymbol x^{(n)})\cdot (\left( %左括号 \begin{array}{c} %该矩阵一共3列,每一列都居中放置 \boldsymbol \phi(\boldsymbol x^{(1)})',\\ \boldsymbol \phi(\boldsymbol x^{(2)})',\\ \cdots,\\ \boldsymbol \phi(\boldsymbol x^{(n)})' \end{array} \right)\boldsymbol w-\boldsymbol y ) =(ϕ(x(1)),ϕ(x(2)),⋯,ϕ(x(n))⋅( ϕ(x(1))′,ϕ(x(2))′,⋯,ϕ(x(n))′ w−y)
令 Φ = ( ϕ ( x ( 1 ) ) , ϕ ( x ( 2 ) ) , ⋯ , ϕ ( x ( n ) ) = ( ϕ 0 ( x ( 1 ) ) , ϕ 0 ( x ( 2 ) ) , ⋯ , ϕ 0 ( x ( n ) ) ϕ 1 ( x ( 1 ) ) , ϕ 1 ( x ( 2 ) ) , ⋯ , ϕ 1 ( x ( n ) ) ⋯ ϕ m ( x ( 1 ) ) , ϕ m ( x ( 2 ) ) , ⋯ , ϕ m ( x ( n ) ) ) 令\boldsymbol \Phi=(\boldsymbol \phi(\boldsymbol x^{(1)}),\boldsymbol \phi(\boldsymbol x^{(2)}),\cdots,\boldsymbol \phi(\boldsymbol x^{(n)})= \left( \begin{array}{cccc} \phi_0(\boldsymbol x^{(1)}),\phi_0(\boldsymbol x^{(2)}),\cdots,\phi_0(\boldsymbol x^{(n)}) \\ \phi_1(\boldsymbol x^{(1)}),\phi_1(\boldsymbol x^{(2)}),\cdots,\phi_1(\boldsymbol x^{(n)}) \\ \cdots \\ \phi_m(\boldsymbol x^{(1)}),\phi_m(\boldsymbol x^{(2)}),\cdots,\phi_m(\boldsymbol x^{(n)}) \\ \end{array} \right) 令Φ=(ϕ(x(1)),ϕ(x(2)),⋯,ϕ(x(n))= ϕ0(x(1)),ϕ0(x(2)),⋯,ϕ0(x(n))ϕ1(x(1)),ϕ1(x(2)),⋯,ϕ1(x(n))⋯ϕm(x(1)),ϕm(x(2)),⋯,ϕm(x(n))
∂ L ( w ) ∂ w = Φ ⋅ ( Φ ′ w − y ) \frac{\partial L(\boldsymbol w)}{\partial \boldsymbol w}=\boldsymbol \Phi \cdot (\boldsymbol \Phi' \boldsymbol w - \boldsymbol y) ∂w∂L(w)=Φ⋅(Φ′w−y)
此外,矩阵形式的梯度计算可能可以得到更好的 G P U 加速 此外,矩阵形式的梯度计算可能可以得到更好的GPU加速 此外,矩阵形式的梯度计算可能可以得到更好的GPU加速
实值函数线性基函数模型参数求解的解析解 closed form solution
∂ L ( w ) ∂ w = Φ ⋅ ( Φ ′ w − y ) = 0 \frac{\partial L(\boldsymbol w)}{\partial \boldsymbol w}=\boldsymbol \Phi \cdot (\boldsymbol \Phi' \boldsymbol w - \boldsymbol y)=\boldsymbol 0 ∂w∂L(w)=Φ⋅(Φ′w−y)=0
Φ Φ ′ w − Φ y = 0 \boldsymbol \Phi \boldsymbol \Phi' \boldsymbol w - \boldsymbol \Phi \boldsymbol y=\boldsymbol 0 ΦΦ′w−Φy=0
Φ Φ ′ w = Φ y \boldsymbol \Phi \boldsymbol \Phi' \boldsymbol w =\boldsymbol \Phi \boldsymbol y ΦΦ′w=Φy
w = ( Φ Φ ′ ) − 1 Φ y \boldsymbol w =(\boldsymbol \Phi \boldsymbol \Phi')^{-1}\boldsymbol \Phi \boldsymbol y w=(ΦΦ′)−1Φy
向量值函数广义线性模型
输出值为c个类别的评分,即c元向量,每个维度均由各自的线性函数产生
∂ L ( w i ) ∂ w i = 2 n Σ p = 1 n ( y ^ ( p ) − y ( p ) ) x ( p ) = 2 n Σ p = 1 n ( w i x ( p ) − y ( p ) ) x ( p ) \frac{\partial L(\boldsymbol w_i)}{\partial \boldsymbol w_i}=\frac {2}{n}\Sigma_{p=1}^n (\hat y^{(p)}- y^{(p)})\boldsymbol x^{(p)}=\frac {2}{n}\Sigma_{p=1}^n (\boldsymbol w_i \boldsymbol x^{(p)}- y^{(p)})\boldsymbol x^{(p)} ∂wi∂L(wi)=n2Σp=1n(y^(p)−y(p))x(p)=n2Σp=1n(wix(p)−y(p))x(p)
每个维度的权重向量 w i \boldsymbol w_i wi均可由上述方法求出。
Tips
1.若生成的x为特殊序列则随机梯度下降可能永远无法得到正确解,例如 ( 1 , 1 , 1 ) , ( 2 , 2 , 2 ) , ⋯ , ( n , n , n ) (1,1,1),(2,2,2),\cdots,(n,n,n) (1,1,1),(2,2,2),⋯,(n,n,n),此时各维权重总是增加相同值。
2.原模型偏置bias相对样本的teaching signal较小时,总是无法得到较好解。
KNN识别CIFAR10
1NN
代码
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
import time
"""
KNN
SVM, Softmax
Two-layer neural network
Image features
"""
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_valid, y_valid) = cifar10.load_data()
x_train = x_train.reshape((50000,32*32*3))
x_valid = x_valid.reshape((10000,32*32*3))
x_valid = x_valid[0:1000]
y_valid = y_valid[0:1000]
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
""" X is N x D, y is 1-dimension of size N"""
self.Xtr = X
self.ytr = y
def predict(self, X):
"""predict an array of patterns at one time"""
start = time.time()
num_test = X.shape[0]
yPred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in range(num_test):
print("\r{:.2f}%".format(i*100/num_test), end="")
distances = np.sum(np.abs(self.Xtr-X[i,:]), axis = 1)#N1
# N2
# distances = np.linalg.norm(self.Xtr-X[i,:], ord=2, axis=1)
# 余弦
# distances = np.zeros(self.Xtr.shape[0])
# for j in range(len(distances)):
# numerator = np.dot(X[i], self.Xtr[j])
# denominator = math.sqrt(np.sum(np.square(X[i])))
# denominator *= math.sqrt(np.sum(np.square(self.Xtr[j])))
# distances[j] = numerator/denominator
min_index = np.argmin(distances)
yPred[i] = self.ytr[min_index]
end = time.time()
print(f"\n耗时{end-start}s")
return yPred
nn = NearestNeighbor()
nn.train(x_train, y_train)
yPred = nn.predict(x_valid)
num_wrong = 0
for i in range(yPred.shape[0]):
if yPred[i] != y_valid[i]:
num_wrong += 1
print(num_wrong)
print("accuracy is {:.2f}%".format((1-num_wrong/x_valid.shape[0])*100))
效果
| 方法 | L1范式 | L2范式 | 余弦距离 |
|---|---|---|---|
| 准确率/% | 25.30 | 20.90 | 9.30 |
KNN
代码
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import math
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
import time
"""
KNN
SVM, Softmax
Two-layer neural network
Image features
"""
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_valid, y_valid) = cifar10.load_data()
x_train = x_train.reshape((50000,32*32*3))
x_valid = x_valid.reshape((10000,32*32*3))
x_valid = x_valid[0:1000]
y_valid = y_valid[0:1000]
class KNearestNeighbor:
def __init__(self):
pass
def train(self, X, y, k):
""" X is N x D, y is 1-dimension of size N"""
self.Xtr = X
self.ytr = y
self.k = k
def getIndex(self, distances):
n = len(distances)
cnts = np.zeros(10)
pivot = np.partition(distances, self.k)[self.k]
for i in range(n):
if distances[i] <= pivot:
cnts[self.ytr[i]] += 1
return np.argmax(cnts)
def predict(self, X):
"""predict an array of patterns at one time"""
start = time.time()
num_test = X.shape[0]
yPred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in range(num_test):
print("\r{:.2f}%".format(100*i/num_test), end="")
distances = np.sum(np.abs(self.Xtr-X[i,:]), axis = 1)
yPred[i] = self.getIndex(distances)
end = time.time()
print(f"耗时{end-start}s")
return yPred
nn = KNearestNeighbor()
for i in range(2, 10): # define range by your own
nn.train(x_train, y_train, i)
yPred = nn.predict(x_valid)
num_wrong = 0
for j in range(yPred.shape[0]):
if yPred[j] != y_valid[j]:
num_wrong += 1
print(num_wrong)
print("accuracy is {:.2f}%".format((1-num_wrong/x_valid.shape[0])*100))
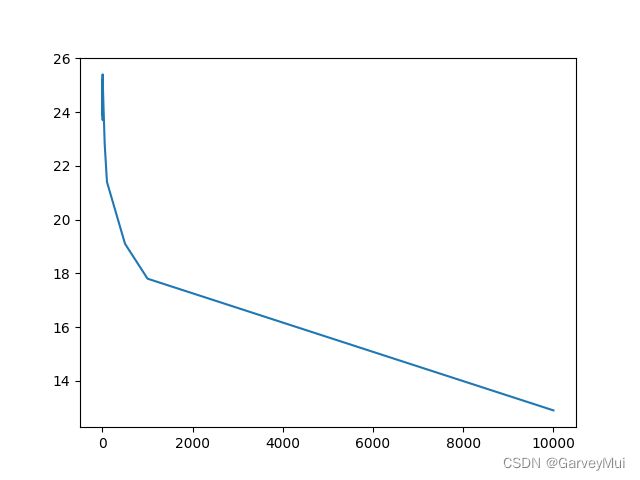
效果
使用L1范式作为测度
| K | 准确率/% |
|---|---|
| 2 | 23.90 |
| 3 | 24.40 |
| 4 | 25.40 |
| 5 | 23.70 |
| 6 | 24.60 |
| 7 | 25.00 |
| 8 | 25.20 |
| 9 | 25.00 |
| 25 | 24.10 |
| 50 | 22.80 |
| 100 | 21.40 |
| 500 | 19.10 |
| 1000 | 17.80 |
| 10000 | 12.90 |