黑马Hive+Spark离线数仓工业项目-任务流调度工具AirFlow(2)
Oracle与MySQL调度方法
目标:了解Oracle与MySQL的调度方法
实施
Oracle调度:参考《oracle任务调度详细操作文档.md》
- step1:本地安装Oracle客户端
- step2:安装AirFlow集成Oracle库
- step3:创建Oracle连接
- step4:开发测试
query_oracle_task = OracleOperator(
task_id = 'oracle_operator_task',
sql = 'select * from ciss4.ciss_base_areas',
oracle_conn_id = 'oracle-airflow-connection',
autocommit = True,
dag=dag
)MySQL调度:《MySQL任务调度详细操作文档.md》
- step1:本地安装MySQL客户端
- step2:安装AirFlow集成MySQL库
- step3:创建MySQL连接
- step4:开发测试
- 方式一:指定SQL语句
query_table_mysql_task = MySqlOperator(
task_id='query_table_mysql',
mysql_conn_id='mysql_airflow_connection',
sql=r"""select * from test.test_airflow_mysql_task;""",
dag=dag
)- 方式二:指定SQL文件
query_table_mysql_task = MySqlOperator(
task_id='query_table_mysql_second',
mysql_conn_id='mysql-airflow-connection',
sql='test_airflow_mysql_task.sql',
dag=dag
)- 方式三:指定变量
insert_sql = r"""
INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task3');
INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task4');
INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task5');
"""
insert_table_mysql_task = MySqlOperator(
task_id='mysql_operator_insert_task',
mysql_conn_id='mysql-airflow-connection',
sql=insert_sql,
dag=dag
)大数据组件调度方法
目标:了解大数据组件调度方法
实施
AirFlow支持的类型
- HiveOperator
- PrestoOperator
- SparkSqlOperator
需求:Sqoop、MR、Hive、Spark、Flink
解决:统一使用BashOperator或者PythonOperator,将对应程序封装在脚本中
- Sqoop
run_sqoop_task = BashOperator(
task_id='sqoop_task',
bash_command='sqoop --options-file xxxx.sqoop',
dag=dag,
)- Hive
run_hive_task = BashOperator(
task_id='hive_task',
bash_command='hive -f xxxx.sql',
dag=dag,
)- Spark
run_spark_task = BashOperator(
task_id='spark_task',
bash_command='spark-sql -f xxxx.sql',
dag=dag,
)- Flink
run_flink_task = BashOperator(
task_id='flink_task',
bash_command='flink run /opt/flink-1.12.2/examples/batch/WordCount.jar',
dag=dag,
)定时调度使用
目标:掌握定时调度的使用方式
实施
- http://airflow.apache.org/docs/apache-airflow/stable/dag-run.html

方式一:内置
with DAG(
dag_id='example_branch_operator',
default_args=args,
start_date=days_ago(2),
schedule_interval="@daily",
tags=['example', 'example2'],
) as dag:- **方式二:datetime.timedelta对象**
timedelta(minutes=1)
timedelta(hours=3)
timedelta(days=1) with DAG(
dag_id='latest_only',
schedule_interval=dt.timedelta(hours=4),
start_date=days_ago(2),
tags=['example2', 'example3'],
) as dag:方式三:Crontab表达式
- 与Linux Crontab用法一致
with DAG(
dag_id='example_branch_dop_operator_v3',
schedule_interval='*/1 * * * *',
start_date=days_ago(2),
default_args=args,
tags=['example'],
) as dag:分钟 小时 日 月 周
00 00 * * *
05 12 1 * *
30 8 * * 4Airflow常用命令
目标:了解AirFlow的常用命令
实施
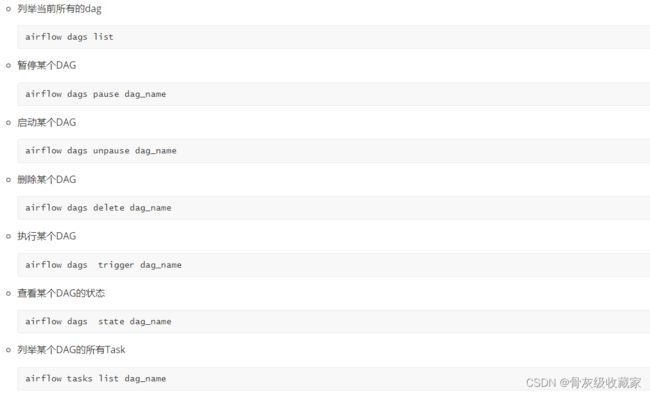
邮件告警使用
目标:了解AirFlow中如何实现邮件告警
路径
- step1:AirFlow配置
- step2:DAG配置
实施
- 原理:自动发送邮件的原理:邮件第三方服务
- 发送方账号:配置文件中配置
```properties
smtp_user = [email protected]
# 秘钥id:需要自己在第三方后台生成
smtp_password = 自己生成的秘钥
# 端口
smtp_port = 25
# 发送邮件的邮箱
smtp_mail_from = [email protected]
```
- 接收方账号:程序中配置
default_args = {
'owner': 'airflow',
'email': ['[email protected]'],
'email_on_failure': True,
'email_on_retry': True,
'retries': 1,
'retry_delay': timedelta(minutes=1),
}
- AirFlow配置:airflow.cfg
# 发送邮件的代理服务器地址及认证:每个公司都不一样
smtp_host = smtp.163.com
smtp_starttls = True
smtp_ssl = False
# 发送邮件的账号
smtp_user = [email protected]
# 秘钥id:需要自己在第三方后台生成
smtp_password = 自己生成的秘钥
# 端口
smtp_port = 25
# 发送邮件的邮箱
smtp_mail_from = [email protected]
# 超时时间
smtp_timeout = 30
# 重试次数
smtp_retry_limit = 5- 关闭Airflow
# 统一杀掉airflow的相关服务进程命令
ps -ef|egrep 'scheduler|flower|worker|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -9
# 下一次启动之前
rm -f /root/airflow/airflow-*- 程序配置
default_args = {
'email': ['[email protected]'],
'email_on_failure': True,
'email_on_retry': True
}- 启动Airflow
airflow webserver -D
airflow scheduler -D
airflow celery flower -D
airflow celery worker -D- 模拟错误
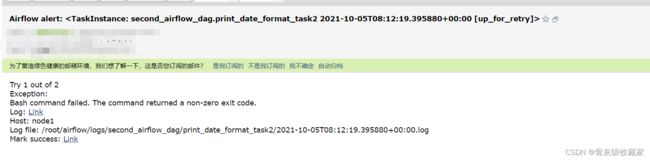
一站制造中的调度
目标:了解一站制造中调度的实现
实施
- ODS层 / DWD层:定时调度:每天00:05开始运行
- dws(11)
- dws耗时1小时
- 从凌晨1点30分开始执行
- dwb(16)
- dwb耗时1.5小时
- 从凌晨3点开始执行
- st(10)
- st耗时1小时
- 从凌晨4点30分开始执行
- dm(1)
- dm耗时0.5小时
- 从凌晨5点30分开始执行
Spark核心概念

- 什么是分布式计算?
- 分布式程序:MapReduce、Spark、Flink程序
- 多进程:一个程序由多个进程来共同实现,不同进程可以运行在不同机器上
- 每个进程所负责计算的数据是不一样,都是整体数据的某一个部分
- 自己基于MapReduce或者Spark的API开发的程序:数据处理的逻辑
- 分逻辑
- MR
- ·MapTask进程:分片规则:基于处理的数据做计算
- 判断:文件大小 / 128M > 1.1
- 大于:按照每128M分
- 小于:整体作为1个分片
- 大文件:每128M作为一个分片
- 一个分片就对应一个MapTask
- ReduceTask进程:指定
- Spark
- Executor:指定
- 分布式资源:YARN、Standalone资源容器
- 将多台机器的物理资源:CPU、内存、磁盘从逻辑上合并为一个整体
- YARN:ResourceManager、NodeManager【8core8GB】
- 每个NM管理每台机器的资源
- RM管理所有的NM
- Standalone:Master、Worker
- 实现统一的硬件资源管理:MR、Flink、Spark on YARN
- Spark程序的组成结构?
- Application:程序
- 进程:一个Driver、多个Executor
- 运行:多个Job、多个Stage、多个Task
- 什么是Standalone?
- Spark自带的集群资源管理平台
- 为什么要用Spark on YARN?
- 为了实现资源统一化的管理,将所有程序都提交到YARN运行
- Master和Worker是什么?
- 分布式主从架构:Hadoop、Hbase、Kafka、Spark……
- 主:管理节点:Master
- 接客
- 管理从节点
- 管理所有资源
- 从:计算节点:Worker
- 负责执行主节点分配的任务
- Driver和Executer是什么?
- step1:启动了分布式资源平台
- step2:开发一个分布式计算程序
sc = SparkContext(conf)
# step1:读取数据
inputRdd = sc.textFile(hdfs_path)
#step2:转换数据
wcRdd = inputRdd.filter.map.flatMap.reduceByKey
#step3:保存结果
wcRdd.foreach
sc.stop- step3:提交分布式程序到分布式资源集群运行
spark-submit xxx.py
executor个数和资源
driver资源配置- 先启动Driver进程
- 申请资源:启动Executor计算进程
- Driver开始解析代码,判断每一句代码是否产生job
- 再启动Executor进程:根据资源配置运行在Worker节点上
- 所有Executor向Driver反向注册,等待Driver分配Task
- Job是怎么产生的?
- 当用到RDD中的数据时候就会触发Job的产生:所有会用到RDD数据的函数称为**触发算子**
- DAGScheduler组件根据代码为当前的job构建DAG图
- DAG是怎么生成的?
- 算法:回溯算法:倒推
- DAG构建过程中,将每个算子放入Stage中,如果遇到宽依赖的算子,就构建一个新的Stage
- Stage划分:宽依赖
- 运行Stage:按照Stage编号小的开始运行
- 将每个Stage转换为一个TaskSet:Task集合
- Task的个数怎么决定?
- 一核CPU = 一个Task = 一个分区
- 一个Stage转换成的TaskSet中有几个Task:由Stage中RDD的最大分区数来决定
- Spark的算子分为几类?
- 转换:Transformation
- 返回值:RDD
- 为lazy模式,不会触发job的产生
- map、flatMap
- 触发:Action
- 返回值:非RDD
- 触发job的产生
- count、first
## 附录一:AirFlow安装
**直接在node1上安装**
### 1、安装Python
- 安装依赖
yum -y install zlib zlib-devel bzip2 bzip2-devel ncurses ncurses-devel readline readline-devel openssl openssl-devel openssl-static xz lzma xz-devel sqlite sqlite-devel gdbm gdbm-devel tk tk-devel gcc
yum install mysql-devel -y
yum install libevent-devel -y- 添加Linux用户及组
# 添加py用户
useradd py
# 设置密码 '123456'
passwd py
# 创建anaconda安装路径
mkdir /anaconda
# 赋予权限
chown -R py:py /anaconda- 上传并执行Anaconda安装脚本
cd /anaconda
rz
chmod u+x Anaconda3-5.3.1-Linux-x86_64.sh
sh Anaconda3-5.3.1-Linux-x86_64.sh- 自定义安装路径
Anaconda3 will now be installed into this location:
/root/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/anaconda3] >>> /anaconda/anaconda3 - 添加到系统环境变量
# 修改环境变量
vi /root/.bash_profile
# 添加下面这行
export PATH=/anaconda/anaconda3/bin:$PATH
# 刷新
source /root/.bash_profile
# 验证
python -V- 配置pip
mkdir ~/.pip
touch ~/.pip/pip.conf
echo '[global]' >> ~/.pip/pip.conf
echo 'trusted-host=mirrors.aliyun.com' >> ~/.pip/pip.conf
echo 'index-url=http://mirrors.aliyun.com/pypi/simple/' >> ~/.pip/pip.conf
# pip默认是10.x版本,更新pip版本
pip install PyHamcrest==1.9.0
pip install --upgrade pip
# 查看pip版本
pip -V2、安装AirFlow
- 安装
pip install --ignore-installed PyYAML
pip install apache-airflow[celery]
pip install apache-airflow[redis]
pip install apache-airflow[mysql]
pip install flower
pip install celery- 验证
airflow -h
ll /root/airflow3、安装Redis
- 下载安装
wget https://download.redis.io/releases/redis-4.0.9.tar.gz
tar zxvf redis-4.0.9.tar.gz -C /opt
cd /opt/redis-4.0.9
make- 启动
`powershell
cp redis.conf src/
cd src
nohup /opt/redis-4.0.9/src/redis-server redis.conf > output.log 2>&1 &- 验证
ps -ef | grep redis4、配置启动AirFlow
- 修改配置文件:airflow.cfg
[core]
#18行:时区
default_timezone = Asia/Shanghai
#24行:运行模式
# SequentialExecutor是单进程顺序执行任务,默认执行器,通常只用于测试
# LocalExecutor是多进程本地执行任务使用的
# CeleryExecutor是分布式调度使用(可以单机),生产环境常用
# DaskExecutor则用于动态任务调度,常用于数据分析
executor = CeleryExecutor
#30行:修改元数据使用mysql数据库,默认使用sqlite
sql_alchemy_conn = mysql://airflow:airflow@localhost/airflow
[webserver]
#468行:web ui地址和端口
base_url = http://localhost:8085
#474行
default_ui_timezone = Asia/Shanghai
#480行
web_server_port = 8085
[celery]
#735行
broker_url = redis://localhost:6379/0
#736
celery_result_backend = redis://localhost:6379/0
#743
result_backend = db+mysql://airflow:airflow@localhost:3306/airflow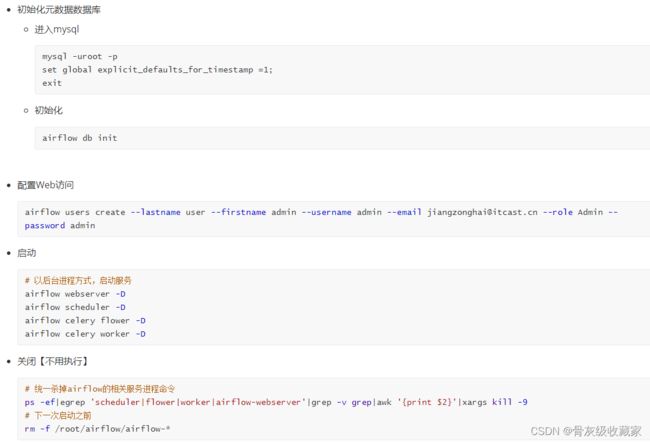
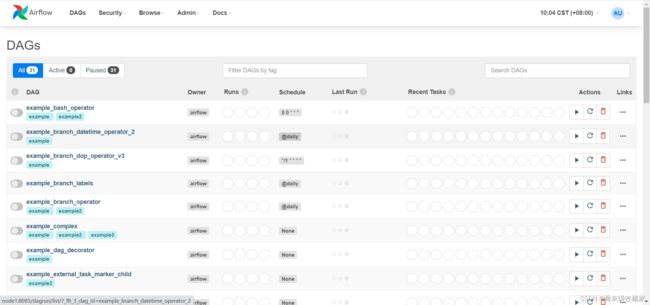
5、验证AirFlow
- Airflow Web UI:`node1:8085`
- Airflow Celery Web:`node1:5555`
