高速缓冲存储器--Cache
本篇参考 arm 官网公开材料,和微信公众号 老秦谈芯 学习笔记
宋宝华:深入理解cache对写好代码至关重要(上)
深入学习Cache系列 1: 带着几个疑问,从Cache的应用场景学起
深入学习Cache系列 2: Cache是如何工作的?概念以及工作过程
深入学起Cache系列 3 : 多核多Cluster多系统之间的缓存一致性

1.什么是cache
Cache存储器也被称为高速缓冲存储器,位于CPU和主存储器之间。之所以在CPU和主存之间要加cache是因为现代的CPU频率大大提高,内存的发展已经跟不上CPU访存的速度。在2001 – 2005年间,处理器时钟频率以每年55%的速度增长,而主存的增长速度只是7%。在现在的系统中,处理器需要上百个时钟周期才能从主存中取到数据。如果没有cache,处理器在等待数据的大部分时间内将会停滞不动。
2.Cache的基本原理
Cache的容量跟主存比起来要小得多,尤其是离CPU最近的L1,通常是几十KB大小。一般L3也就是几十MB大小,跟现在以GB为单位的内存比起来差了好几个数量级。那为什么加入cache还能提高性能呢?
设想一下,如果提前把CPU接下来最有可能用到的数据存放在cache中,那么CPU就可以在很短的时间内得到数据了,一般如果L1命中的话,CPU在2-3个时钟周期内就会得到想要的数据。那么CPU是如何预测到接下来将要用到的数据的呢?其实这种预测是基于程序代码和数据在时间和空间上的局部性原理(locality)。
时间局部性(temporal locality):如果一个数据现在被访问了,那么以后很有可能也会被访问
空间局部性(spatial locally):如果一个数据现在被访问了,那么它周围的数据在以后可能也会被访问
这里要提到一些概念。当CPU在cache中找到需要的数据,我们称之为命中(hit)。反之没有找到数据,我们称之为缺失(miss),这时候就要去外层存储中寻找所需数据。如果是多级cache设计,那么对于L1来讲L2就是它的外层存储。
缓存缺失的类型有很多,常见的有以下三种,可以用3C表示
强制缺失(Compulsory miss),第一次将数据块读入cache所产生的缺失,也成为冷缺失(cold miss)。
冲突缺失(Conflict miss),由于cache相联度有限导致的缺失。
容量缺失(Capacity miss),由于cache大小有限导致的缺失。
高速缓存的管理需要考虑多个方面。首先是数据放置策略;其次是数据替换策略;最后是数据写策略,后面会逐一介绍。
3.为什么cache要分级
我们经常会看到cache分为L1,L2,L3甚至L4等多级。为什么不能把L1的容量做大,不要其它的cache了?原因在于性能/功耗/面积(PPA)权衡考虑。L1 cache一般工作在CPU的时钟频率,要求的就是够快,可以在2-4时钟周期内取到数据。L2 cache相对来说是为提供更大的容量而优化的。虽然L1和L2往往都是SRAM,但构成存储单元的晶体管并不一样。L1是为了更快的速度访问而优化过的,它用了更多/更复杂/更大的晶体管,从而更加昂贵和更加耗电;L2相对来说是为提供更大的容量优化的,用了更少/更简单的晶体管,从而相对便宜和省电。在有一些CPU设计中,会用DRAM实现大容量的L3 cache(一个DRAM的存储单元要比SRAM小)。现在也有一些设计会带L4 cache,有时放在片外或者和CPU封装在一起。
因此出于PPA的权衡,我们先看到的cache系统一般是这样的:32-64KB的指令cache和数据cache(一般L1的指令和数据cache是分开的),2-4个时钟周期访问时间;256KB-2MB的L2 cache(一般从L2开始指令和数据就不分开了),10-20个时钟周期的访问时间;8-80MB的L3 cache,20-50个时钟周期的访问时间。注意,这里所说的时钟周期都是指的CPU的时钟周期。一般L2和L3的工作时钟频率要比CPU的低,这个时钟周期是折算后的数值。

4.Cache的数据放置策略
在讲cache的构成前,先要讲几个概念。首先,缓存的大小称之为cache size,其中每一个缓存行称之为cache line。Cache主要由两部分组成,Tag部分和Data部分。因为cache是利用了程序中的相关性,一个被访问的数据,它本身和它周围的数据在最近都有可能被访问,因此Data部分就是用来保存一片连续地址的数据,而Tag部分则是存储着这片连续地址的公共地址,一个Tag和它对应的所有数据Data组成一行称为cache line,而cache line中的数据部分成为数据块(cache data block,也称做cache block或data block)。如果一个数据可以存储在cache的多个地方,这些被同一个地址找到的多个cache line称为cache set。当CPU在读取缓存数据时,一个cache line的多字节会被同时读出。
假设我们现在的cache size是32KB,一个cache line是64Bytes,4路组相连。通过简单的除法我们就知道在cache中有512条cache line。
假设我们的系统中地址宽度是44bit,当一个地址发下来,会用最低的6bits作为块内的偏移地址(offset),用较高的9bits作为cache索引地址(set==index),将其余的29bits地址作为标志位(tag)作为比对。

使用Index来从cache中找到一个对应的cache line,但是所有Index相同的地址都会寻址到这个cache line,因此在cache line中还有Tag部分,用来和地址中的Tag进行比较,只有它们相等才表明这个cache line就是想要的那个。在一个cache line中有很多数据,通过存储器地址中的Offset部分可以找到真正想要的数据,它可以定位到每个字节。在cache line中还有一个有效位(Valid),用来标记这个Cache line是否保存着有效的数据,只有在之前被访问过的存储器地址,它的数据才会存在于对应的cache line中,相应的有效位也会被置为1。每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit。
组相联的方式是为了解决直接映射结构Cache的不足而提出的,存储器中的一个数据不单单只能放在一个cache line中,而是可以放在多个cache line中,对于一个组相联结构的cache来说,如果一个数据可以放在n个位置,则称这个cache是n路组相联的cache(n way set-associative Cache)。下图为一个两路组相联Cache的原理图。
这种结构仍旧使用存储器地址的Index部分对cache进行寻址,此时可以得到两个cache line,这两个cache line称为一个cache set,究竟哪个cache line才是最终需要的,是根据Tag比较的结果来确定的,如果两个cache line的Tag比较结果都不相等,那么就说明这个存储器地址对应的数据不在cache中,也就是发生了cache缺失。上图所示为并行访问,如果先访问Tag SRAM部分,根据Tag比较的结果再去访问Data SRAM部分,就称为串行访问。
两路组相联缓存的硬件成本相对于直接映射缓存更高。因为其每次比较tag的时候需要比较多个cache line对应的tag(某些硬件可能还会做并行比较,增加比较速度,这就增加了硬件设计复杂度)。为什么我们还需要两路组相联缓存呢?因为其可以有助于降低cache颠簸可能性。
既然组相联缓存那么好,如果所有的cache line都在一个组内。岂不是性能更好?由于所有的cache line都在一个组内,因此地址中不需要set index部分。因为,只有一个组让你选择,间接来说就是你没得选。我们根据地址中的tag部分和所有的cache line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。哪个tag比较相等,就意味着命中某个cache line。因此,在全相连缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率。但是硬件成本上也是更高。
5.再谈直接相连与组相联
– 图片源自知乎:https://zhuanlan.zhihu.com/p/102293437
5.1 直接相连:
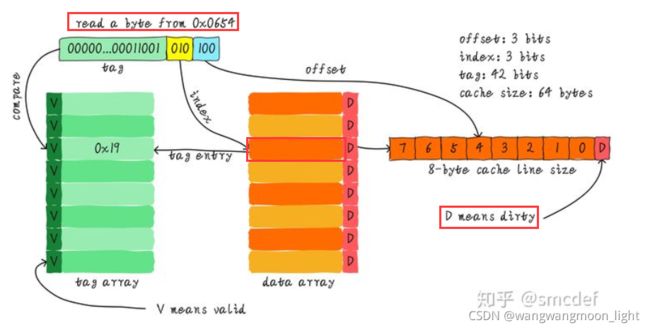
我们一共有8行cache line,cache line大小是8 Bytes。所以我们可以利用地址低3 bits(如上图地址蓝色部分)用来寻址8 bytes中某一字节,我们称这部分bit组合为offset。同理,8行cache line,为了覆盖所有行。我们需要3 bits(如上图地址黄色部分)查找某一行,这部分地址部分称之为index。现在我们知道,如果两个不同的地址,其地址的bit3-bit5如果完全一样的话,那么这两个地址经过硬件散列之后都会找到同一个cache line。所以,当我们找到cache line之后,只代表我们访问的地址对应的数据可能存在这个cache line中,但是也有可能是其他地址对应的数据。所以,我们又引入tag array区域,tag array和data array一一对应(直接相连)。每一个cache line都对应唯一一个tag,tag中保存的是整个地址位宽去除index和offset使用的bit剩余部分(如上图地址绿色部分)。tag、index和offset三者组合就可以唯一确定一个地址了。
因此,当我们根据地址中index位找到cache line后,取出当前cache line对应的tag,然后和地址中的tag进行比较,如果相等,这说明cache命中。如果不相等,说明当前cache line存储的是其他地址的数据,这就是cache缺失。在上述图中,我们看到tag的值是0x19,和地址中的tag部分相等,因此在本次访问会命中。由于tag的引入,因此解答了我们之前的一个疑问“为什么硬件cache line不做成一个字节?”。这样会导致硬件成本的上升,因为原本8个字节对应一个tag,现在需要8个tag,占用了很多内存。
我们可以从图中看到tag旁边还有一个valid bit,这个bit用来表示cache line中数据是否有效(例如:1代表有效;0代表无效)。当系统刚启动时,cache中的数据都应该是无效的,因为还没有缓存任何数据。cache控制器可以根据valid bit确认当前cache line数据是否有效。所以,上述比较tag确认cache line是否命中之前还会检查valid bit是否有效。只有在有效的情况下,比较tag才有意义。如果无效,直接判定cache缺失。
5.2 组相连:

两路组相连缓存就是将cache平均分成2份,每份32 Bytes。
cache被分成2路,每路包含4行cache line。我们将所有索引一样的cache line组合在一起称之为组。例如,上图中一个组有两个cache line,总共4个组。我们依然假设从地址0x0654地址读取一个字节数据。由于cache line size是8 Bytes,因此offset需要3 bits,这和之前直接映射缓存一样。不一样的地方是index,在两路组相连缓存中,index只需要2 bits,因为一路只有4行cache line。上面的例子根据index找到第2行cache line(从0开始计算),第2行对应2个cache line,分别对应way 0和way 1。因此index也可以称作set index(组索引)。先根据index找到set,然后将组内的所有cache line对应的tag取出来和地址中的tag部分对比,如果其中一个相等就意味着命中。
两路组相连缓存优缺点
两路组相连缓存的硬件成本相对于直接映射缓存更高。因为其每次比较tag的时候需要比较多个cache line对应的tag(某些硬件可能还会做并行比较,增加比较速度,这就增加了硬件设计复杂度)。为什么我们还需要两路组相连缓存呢?因为其可以有助于降低cache颠簸可能性。那么是如何降低的呢?根据两路组相连缓存的工作方式,我们可以画出主存地址0x00-0x4f地址对应的cache分布图。
我们依然考虑直接映射缓存一节的问题“如果一个程序试图依次访问地址0x00、0x40、0x80,cache中的数据会发生什么呢?”。现在0x00地址的数据可以被加载到way 1,0x40可以被加载到way 0。这样是不是就在一定程度上避免了直接映射缓存的尴尬境地呢?在两路组相连缓存的情况下,0x00和0x40地址的数据都缓存在cache中。试想一下,如果我们是4路组相连缓存,后面继续访问0x80,也可能被被缓存。
因此,当cache size一定的情况下,组相连缓存对性能的提升最差情况下也和直接映射缓存一样,在大部分情况下组相连缓存效果比直接映射缓存好。同时,其降低了cache颠簸的频率。从某种程度上来说,直接映射缓存是组相连缓存的一种特殊情况,每个组只有一个cache line而已。因此,直接映射缓存也可以称作单路组相连缓存
5.3 全相连:

由于所有的cache line都在一个组内,因此地址中不需要set index部分。因为,只有一个组让你选择,间接来说就是你没得选。我们根据地址中的tag部分和所有的cache line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。哪个tag比较相等,就意味着命中某个cache line。因此,在全相连缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率。但是硬件成本上也是更高。
一个四路组相连缓存实例问题–计算tag的bit位
考虑这么一个问题,32 KB大小4路组相连cache,cache line大小是32 Bytes。请思考以下2个问题:
1)多少个组?
2)假设地址宽度是48 bits,index、offset以及tag分别占用几个bit?
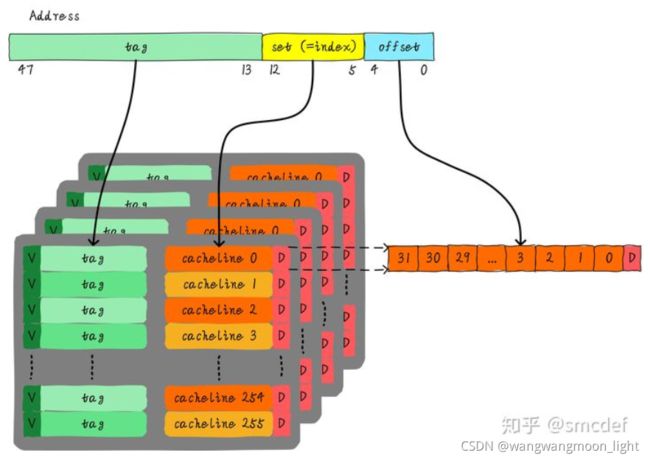
总共4路,因此每路大小是8 KB。cache line size是32 Bytes,因此一共有256组(8 KB / 32 Bytes)。由于cache line size是32 Bytes,所以offset需要5位。一共256组,所以index需要8位,剩下的就是tag部分,占用35位。这个cache可以绘制下图表示。
index 和 set 是一个概念。
6 Cache分配策略(Cache allocation policy)
cache的分配策略是指我们什么情况下应该为数据分配cache line。cache分配策略分为读和写两种情况。
读分配(read allocation)
当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。
写分配(write allocation)
当CPU写数据发生cache缺失时,才会考虑写分配策略。
当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。
当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。
7 Cache更新策略(Cache update policy)
cache更新策略是指当发生cache命中时,写操作应该如何更新数据。cache更新策略分成两种:写直通和回写。
写直通(write through)
当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。
写回(write back)
当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit(翻翻前面的图片,cache line旁边有一个D就是dirty bit)。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致。
同时思考个问题,为什么cache line大小是cache控制器和主存之间数据传输的最小单位呢?这也是因为每个cache line只有一个dirty bit。这一个dirty bit代表着整个cache line是否被修改的状态。
8 实例
假设我们有一个 64 Bytes 大小直接映射缓存,cache line大小是 8 Bytes,采用写分配和写回机制。当CPU从地址0x2a读取一个字节,cache中的数据将会如何变化呢?假设当前cache状态如下图所示(tag旁边valid一栏的数字1代表合法,0代表非法。后面Dirty的1代表dirty,0代表没有写过数据,即非dirty)。
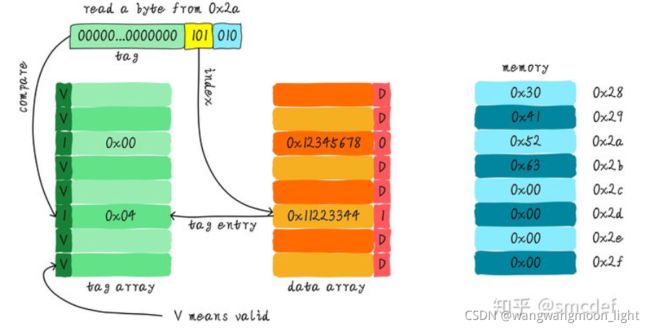
根据index找到对应的cache line,对应的tag部分valid bit是合法的,但是tag的值不相等,因此发生缺失。此时我们需要从地址0x28地址加载8字节数据到该cache line中。但是,我们发现当前cache line的dirty bit置位。因此,cache line里面的数据不能被简单的丢弃,由于采用写回机制,所以我们需要将cache中的数据0x11223344写到地址0x0128地址(这个地址根据tag中的值及所处的cache line行计算得到)。这个过程如下图所示。

当写回操作完成,我们将主存中0x28地址开始的8个字节(0x65524130是最新ddr的数据)加载到该cache line中,并清除dirty bit。然后根据offset找到0x52(第2Byte数据)返回给CPU。