Python网络爬虫:爬取腾讯招聘网职位信息 并做成简单可视化图表
hello,大家好,我是wangzirui32,今天我们来学习如何爬取腾讯招聘网职位信息,并做成简单可视化图表,开始学习吧!
文章目录
- 1. 网页分析
- 2. 获取json数据
- 3. 转换为Excel
- 4. 招聘城市信息可视化
1. 网页分析
首先来到腾讯招聘网首页,搜索“Python”,同时打开开发者工具,选择Network,发现了API请求:
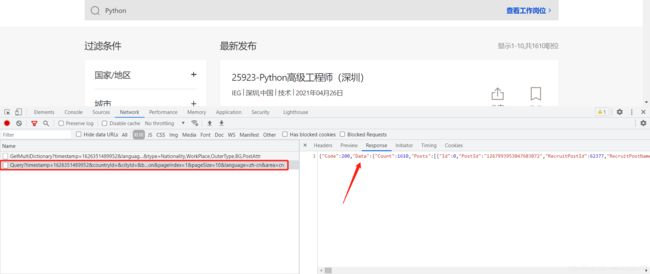
这个请求的网址如下:
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1626354057701&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=Python&pageIndex=1&pageSize=10&language=zh-cn&area=cn
网址太长,经测试,可以去除一些参数,简化后的网址如下:
https://careers.tencent.com/tencentcareer/api/post/Query?keyword=Python&pageIndex=1&pageSize=10&language=zh-cn&area=cn
URL参数的Python字典:
params = {
"keyword": "Python",
"pageIndex": 1, # 页数
"pageSize": 10, # 每页记录数
"language": "zh-cn",
"area": "cn",
}
再看这个URL的响应内容:
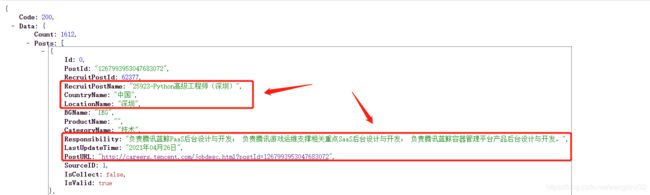
红框所圈起的是我们需要的数据。
2. 获取json数据
代码:
import requests
import json
from fake_useragent import UserAgent
json_data = []
# 获取30页
for i in range(1, 31):
params = {
"keyword": "Python",
"pageIndex": i,
"pageSize": 10,
"language": "zh-cn",
"area": "cn",
}
headers = {
"User-Agent": UserAgent().random
}
url = "https://careers.tencent.com/tencentcareer/api/post/Query"
json_data += requests.get(url, params=params, headers=headers).json()['Data']['Posts']
with open("data.json", "w", encoding="UTF-8") as f:
json.dump(json_data, f)
3. 转换为Excel
import json
from pandas import DataFrame
f = open("data.json")
data = json.load(f)
f.close()
excel_dict = {
"工作岗位名": [],
"招聘国家": [],
"招聘城市名": [],
"工作责任": [],
"最后更新时间": [],
"详细页网址": []
}
for i in data:
excel_dict["工作岗位名"].append(i['RecruitPostName'])
excel_dict["招聘国家"].append(i['CountryName'])
excel_dict["招聘城市名"].append(i['LocationName'])
excel_dict["工作责任"].append(i['Responsibility'])
excel_dict["最后更新时间"].append(i['LastUpdateTime'])
excel_dict["详细页网址"].append(i['PostURL'])
df = DataFrame(data=excel_dict)
df.to_excel("data.xlsx")
data.xlsx文件内容:

4. 招聘城市信息可视化
工作的城市地点有多少个?各个城市占比是多少?可以用下面的可视化程序解决这些问题:
from pyecharts.charts import Pie
import pyecharts.options as opts
import json
from collections import Counter
f = open("data.json")
data = json.load(f)
f.close()
# 获取所有城市
cities = [i['LocationName'] for i in data]
# 统计城市数量
city_num = list(Counter(cities).items())
pie = (
Pie(init_opts=opts.InitOpts(width='720px', height='720px'))
.add(series_name='招聘城市占比', data_pair=city_num)
)
pie.render("city_pie.html")
运行代码,打开city_pie.html:
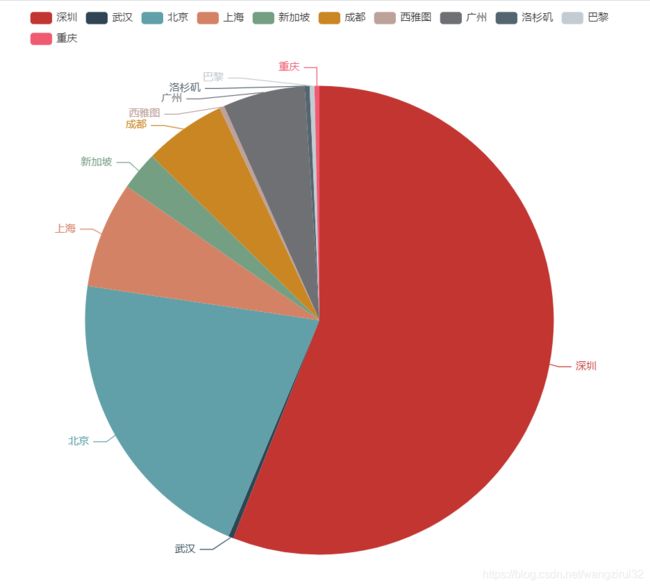
可以看到,工作地点在深圳的占比较大,其次是北京,上海。
好了,今天的课程就到这里,我是wangzirui32,喜欢的可以点个收藏和关注,我们下次再见!