python中graphviz画决策树
1.安装
需要先安装graphviz软件并配置环境变量后再安装graphviz包。
a) 软件下载并安装:链接:https://pan.baidu.com/s/1hw-AaPmyLf2V2BpXUvD1nQ 提取码:5sz0
b) 配置环境变量,(我的安装路径为C:\Program Files (x86)\Graphviz2.38):
① 在用户变量的path中新增 C:\Program Files (x86)\Graphviz2.38\bin
② 在系统环境变量的path中新增 C:\Program Files (x86)\Graphviz2.38\bin\dot.exe
③ 配置完成后可在命令行输入dot -version观察安装效果,如输出如下图所示即安装成功。
c) 安装pyphon包:pip install graphviz
2.使用
#使用红酒数据集观察
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine()
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy",max_depth=5)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚',
'类黄酮','非黄烷类酚类','花青素','颜色强度',
'色调','稀释葡萄酒','脯氨酸']
import graphviz
dot_data = tree.export_graphviz(clf
,out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph.save('D:/fhchen/wine_tree.dot') #保存决策树
需要注意的是,此时保存的决策树是一个dot文件,要转换成图片格式可以用如下命令进行转换
dot -Tpng D:\fhchen\wine_tree.dot -o D:\fhchen\wine_tree.png
如果节点中包括中文,则转换后的图片会出现乱码,如下图所示

这是因为生成的dot文件中默认字体格式为helvetica,找到生成的dot文件,打开并编辑,将
digraph Tree {
node [shape=box, style="filled, rounded", color="black", fontname=helvetica] ;
edge [fontname=helvetica] ;
替换为
digraph Tree {
node [shape=box, style="filled, rounded", color="black", fontname=SimHei] ;
edge [fontname=SimHei] ;
其中字体可以自己选择,如想要宋体可以将SimHei替换为 NSimSun。
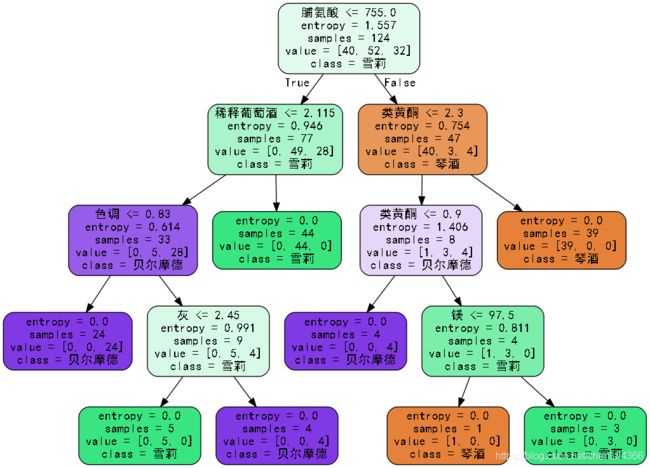
最终生成的决策树如下:
3.xgboost画出子树
import pandas as pd
from xgboost.sklearn import XGBClassifier
import xgboost as xgb
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #windows下用来正常显示中文
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine()
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = XGBClassifier(
n_estimators=30,#三十棵树
learning_rate =0.3,
max_depth=4,
min_child_weight=1,
gamma=0.3,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=12,
scale_pos_weight=1,
reg_lambda=1,
seed=27)
'''
在xgboost的新版本(0.8)中,已无需生成fmap来获取列名。
只需要在训练的时候将数据转换为DataFrame且列名标记为特征即可
'''
clf.fit(pd.DataFrame(Xtrain,columns=wine.feature_names), Ytrain)
#中间节点形状
condition_node_params = {'shape':'box',
'style':'filled,rounded',
'fillcolor':'#78bceb'
}
#叶子节点形状
leaf_node_params = {'shape':'box',
'style':'filled',
'fillcolor':'#e48038'
}
graph = xgb.to_graphviz(clf,num_trees=1,condition_node_params=condition_node_params,leaf_node_params=leaf_node_params,**{'size':str(12)})
graph.render('xgboost1') #输出pdf文件
目前没找到解决to_graphviz输出的图中中文乱码的办法,就先用英文了。
生成结果如下:

参考文献:
https://blog.csdn.net/HNUCSEE_LJK/article/details/86772806
https://blog.csdn.net/pipixiu/article/details/79057885