kNN分类
一、 概述
kNN(k nearest neighbor,k近邻)是一种基础分类算法,基于“物以类聚”的思想,将一个样本的类别归于它的邻近样本。
![在这里插入图片描述] 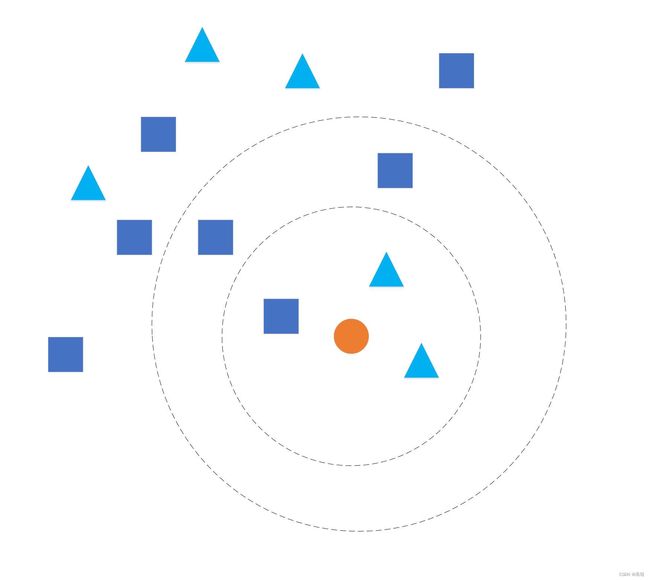
二、算法描述
1.基本原理
给定训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\left\{ \left( x_1,y_1 \right),\left( x_2,y_2 \right),...,\left( x_N,y_N \right) \right\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中 x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( n ) ) x_i=\left( x_{i}^{(1)},x_{i}^{(2)},...,x_{i}^{(n)} \right) xi=(xi(1),xi(2),...,xi(n))为特征向量, y i y_i yi为样本类别。对于一个待测样本 x x x,计算 x x x与训练集样本的距离,找到离它最近的 k k k个邻居,考察这 k k k个邻居,它们更倾向于哪个类别,就把 x x x归到那个类别。算法由三个基本要素构成: k k k值选择、距离度量、分类决策规则。
k值选择:
若 k k k 值过小,模型偏向复杂,易于过拟合;若 k k k 值过大,模型偏向简单,易于欠拟合。通常由交叉验证法选择最优的 k k k值,一般不超过20。
距离度量:
距离度量的方式有很多,通常使用欧氏距离,也就是差向量的 L 2 L2 L2范数。对两个样本向量 A = ( x 11 , x 12 , . . . , x 1 n ) A=\left( x_{11},x_{12},...,x_{1n} \right) A=(x11,x12,...,x1n)和 B = ( x 21 , x 22 , . . . , x 2 n ) B=\left( x_{21},x_{22},...,x_{2n} \right) B=(x21,x22,...,x2n),它们之间的欧氏距离为 d = ∑ k = 1 n ( x 1 k − x 2 k ) 2 d=\sqrt{\sum_{k=1}^{n}{\left( x_{1k}-x_{2k} \right)^{2}}} d=k=1∑n(x1k−x2k)2
分类决策规则:
一般是多数表决,即由 k k k个邻居中较多的决定。也可以根据距离的远近,赋以样本不同的权重。
2.算法描述
输入:训练数据集 T T T ;待测样本 x x x.
输出: x x x所属类别.
(1)计算 x x x与训练样本间的距离.
(2)确定与 x x x最近的 k k k个邻居.
按距离对样本进行排序,选取前 k k k 个距离最小的样本,构成邻居集合 N k ( x ) N_{k}\left( x \right) Nk(x).样本数量为 ∣ N k ( x ) ∣ = M \left| N_k\left( x \right) \right|=M ∣Nk(x)∣=M
(3)确定 x x x 的类别 y y y .
多数表决,由邻居集合中类别的多数决定
y = arg m a x c j ∑ x i ∈ N k ( x ) I ( y i = c j ) y=\arg max_{c_j}{\sum_{x_i\in N_k\left( x \right)}{I\left( y_i=c_j \right)}} y=argmaxcjxi∈Nk(x)∑I(yi=cj)
其中 I I I 为指示函数
I = { 1 i f ( y i = c j ) 0 i f ( y i ≠ c j ) I= \left\{ \begin{array}{lr} 1 \quad if\left( y_i=c_j \right)&\\ 0 \quad if\left( y_i\ne c_j \right) \end{array} \right. I={1if(yi=cj)0if(yi=cj) i = 1 , 2 , . . . , M i=1,2,...,M i=1,2,...,M; j = 1 , 2 , . . . , K j=1,2,...,K j=1,2,...,K.
三、 python实现
'''
功能:由sklearn实现kNN分类。
'''
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
## 1.构造训练集和待测样本
#训练集数据
train_x=[
[1.1, 2, 3, 4],
[1, 2.2, 3, 4],
[1, 2, 3.3, 4],
[1, 2, 3, 4.4],
[1.1, 2.2, 3, 4],
[1, 2, 3.3, 4.4]
]
#训练集数据标签
train_y=[
1,
2,
2,
3,
3,
1
]
train_y = list(map(float,train_y)) #浮点化
#待测样本
test_x = [
[1.2, 2, 3, 4],
[1, 2.3, 3, 4]
]
#转为array形式
train_x = np.array(train_x)
train_y = np.array(train_y)
test_x = np.array(test_x)
## 2.定义分类器
knnClf = KNeighborsClassifier(
n_neighbors=2, #选取的k值,即邻居样本数
weights='uniform', #分类决策权重,默认uniform,为均等权重
algorithm='auto',
leaf_size=30,
p=2,metric='minkowski', #距离度量,闵可夫斯基空间下的欧氏距离(p=2)
metric_params=None,
n_jobs=None
)
## 3.训练
Fit_knnClf = knnClf.fit(train_x,train_y)
## 4.预测
pre_y = Fit_knnClf.predict(test_x)
print('预测类别:')
print(pre_y)
End.
参考
1.李航.《统计学习方法》.清华大学出版社
2. https://blog.csdn.net/Albert201605/article/details/81040556?spm=1001.2014.3001.5502