词向量(Word Embedding)
一、词的表示
在自然语言处理任务中,首先需要考虑词如何在计算机中表示。通常,有两种表示方式:one-hot representation和distribution representation。简而言之,词向量技术是将词转化成为稠密向量,并且对于相似的词,其对应的词向量也相近。
1.1 离散表示(one-hot representation)
传统的基于规则或基于统计的自然语义处理方法将单词看作一个原子符号
被称作one-hot representation。one-hot representation把每个词表示为一个长向量。这个向量的维度是词表大小,向量中只有一个维度的值为1,其余维度为0,这个维度就代表了当前的词。
例如:
苹果 [0,0,0,1,0,0,0,0,0,……]
one-hot representation相当于给每个词分配一个id,这就导致这种表示方式不能展示词与词之间的关系。另外,one-hot representation将会导致特征空间非常大,但也带来一个好处,就是在高维空间中,很多应用任务线性可分。
1.2 分布式表示(distribution representation)
word embedding指的是将词转化成一种分布式表示,又称词向量。分布
式表示将词表示成一个定长的连续的稠密向量。
分布式表示优点:
(1)词之间存在相似关系:
是词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。
(2)包含更多信息:
词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
二、如何生成词向量
本小节来简单介绍词向量的生成技术。生成词向量的方法有很多,这些方法都依照一个思想:任一词的含义可以用它的周边词来表示。生成词向量的方式可分为:基于统计的方法和基于语言模型(language model)的方法。
2.1 基于统计方法
2.1.1 共现矩阵
通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数做为当前word的vector。具体来说,我们通过从大量的语料文本中构建一个共现矩阵来定义word representation。
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
则其共现矩阵如下:

矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
2.1.2 SVD(奇异值分解)
既然基于co-occurrence矩阵得到的离散词向量存在着高维和稀疏性的问
题,一个自然而然的解决思路是对原始词向量进行降维,从而得到一个稠密的连续词向量。
对2.1.1中矩阵,进行SVD分解,得到矩阵正交矩阵U,对U进行归一化得到矩阵如下:
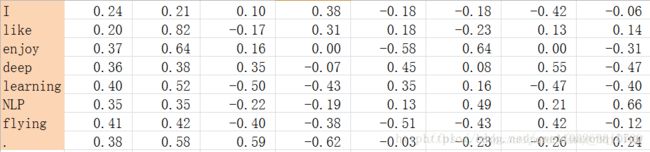
SVD得到了word的稠密(dense)矩阵,该矩阵具有很多良好的性质:语义相近的词在向量空间相近,甚至可以一定程度反映word间的线性关系。
**2.2语言模型(language model)**
语言模型生成词向量是通过训练神经网络语言模型NNLM(neural network language model),词向量做为语言模型的附带产出。NNLM背后的基本思想是对出现在上下文环境里的词进行预测,这种对上下文环境的预测本质上也是一种对共现统计特征的学习。
较著名的采用neural network language model生成词向量的方法有:Skip-gram、CBOW、LBL、NNLM、C&W、GloVe等。接下来,以目前使用最广泛CBOW模型为例,来介绍如何采用语言模型生成词向量。
三、词向量工具
词向量和分词一样,也是自然语言处理中的基础性工作。词向量一方面解决了词语的编码问题,另一方面也解决了词的同义关系,使得基于LSTM等深度学习模型的自然语言处理成为了可能。和分词不同,中英文文本,均需要进行词向量编码。2013年Google开源了word2vec工具,它可以进行词向量训练,加载已有模型进行增量训练,求两个词向量相似度,求与某个词接近的词语,等等。功能十分丰富,基本能满足我们对于词向量的需求。下面详细讲解怎么使用word2vec
3.1 模型训练
词向量模型训练只需要有训练语料即可,语料越丰富准确率越高,属于无监督学习。后面会讲词向量训练算法和代码实现,这儿先说怎么利用word2vec工具进行词向量模型训练。
# gensim是自然语言处理的一个重要Python库,它包括了Word2vec
import gensim
from gensim.models import word2vec
# 语句,由原始语句经过分词后划分为的一个个词语
sentences = [['网商银行', '体验', '好'], ['网商银行','转账','快']]
# 使用word2vec进行训练
# min_count: 词语频度,低于这个阈值的词语不做词向量
# size:每个词对应向量的维度,也就是向量长度
# workers:并行训练任务数
model = word2vec.Word2Vec(sentences, size=256, min_count=1)
# 保存词向量模型,下次只需要load就可以用了
model.save("word2vec_atec")
3.2 增量训练
有时候我们语料不是很丰富,但都是针对的某个垂直场景的,比如网商银行相关的语料。此时我们训练词向量时,可以先基于一个已有的模型进行增量训练,这样就可以得到包含特定语料的比较准确的词向量了。
# 先加载已有模型
model = gensim.models.Word2Vec.load("word2vec_atec")
# 进行增量训练
corpus = [['网商银行','余利宝','收益','高'],['贷款','发放','快']] # 新增语料
model.build_vocab(corpus, update=True) # 训练该行
model.train(corpus, total_examples=model.corpus_count, epochs=model.iter)
# 保存增量训练后的新模型
model.save("../data/word2vec_atec")
3.3 求词语相似度
可以利用词向量来求两个词语的相似度。词向量的余弦夹角越小,则相似度越高。
# 验证词相似程度
print model.wv.similarity('花呗'.decode('utf-8'), '借呗'.decode('utf-8'))
3.4 求与词语相近的多个词语
for i in model.most_similar(u"我"):
print i[0],i[1]
四、词向量训练算法
词向量可以通过使用大规模语料进行无监督学习训练得到,常用的算法有CBOW连续词袋模型和skip-gram跳字模型。二者没有本质的区别,算法框架完全相同。区别在于,CBOW利用上下文来预测中心词。而skip-gram则相反,利用中心词来预测上下文。比如对于语料 {“The”, “cat”, “jump”, “over”, “the”, “puddle”} ,CBOW利用上下文{“The”, “cat”, “over”, “the”, “puddle”} 预测中心词“jump”,而skip-gram则利用jump来预测上下文的词,比如jump->cat, jump->over。一般来说,CBOW适合小规模训练语料,对其进行平滑处理。skip-gram适合大规模训练语料,可以基于滑窗随机选择上下文词语。word2vec模型训练时默认采用skip-gram。
五、总结
深度学习模型具有比传统模型更强的特征抽取能力。在自然语言处理中,传统统计特征包含的信息量过少,这也一直限制着深度学习在自然语言处理中的应用。词向量由于包含了更丰富的信息,使得深度学习能够处理绝大多数自然语言处理应用。
词向量虽然为深度学习在自然语言处理领域带来了希望,但目前词向量仍有许多不完善的地方,例如:
虽然知道词向量比统计特征包含更多信息,但并不知道词向量包含了哪些
信息(如每维特征代表的意义)。
词向量的训练采用无监督方式,不能很好的利用先验信息。
词向量是神经网络语言模型的副产物,其损失函数不是由具体应用构建。
因此,不是词向量训练的越好,应用效果就越好。
随着词向量研究的深入,这些问题都将会得到解决。深度学习在自然语言
处理领域的前景将会更加光明。