【ESMM论文精读】Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion
文章目录
-
- 原始论文
- 摘要 (ABSTRACT)
- 关键词 (KEYWORDS)
- 1. 介绍 (INTRODUCTION)
- 2. 提出的方法 THE PROPOSED APPROACH
-
- 2.1 符号 Notation
- 2.2 CVR建模和挑战 CVR Modeling and Challenges
-
- (1) 样本选择偏差 Sample selection bias (SSB) [12]
- (2) 数据稀疏性 Data sparsity (DS)
- (3) 其他挑战 other challenges
- 2.3 ESMM模型 Entire Space Multi-Task Model
-
-
- (1)在整个空间建模 Modeling over entire space.
- (2)特征表示迁移学习 Feature representation transfer.
-
- 3 实验 EXPERIMENTS
-
- 3.1 实验设置 Experimental Setup
-
- (1)数据集 Datasets.
- (2)对比算法 Competitors.
- (3)效果度量 Metric.
- 3.2 公开数据集(少量)实验结果 Results on Public Dataset
- 3.3 生产数据集(全量)实验结果 Results on Product Dataset
- 4 总结与后续 CONCLUSIONS AND FUTUREWORK
原始论文
- 本博客仅作为学习交流材料,论文版权归原作者所有:
- ArXiv: https://arxiv.org/abs/1804.07931v2
- MLA:
Ma, X. , et al. "Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate." The 41st International ACM SIGIR Conference ACM, 2018.

摘要 (ABSTRACT)
Estimating post-click conversion rate (CVR) accurately is crucial for ranking systems in industrial applications such as recommendation and advertising.
准确地估计(注:某商品被)点击后的转化率(CVR),对于工业应用中的排序系统,例如推荐、广告,是至关重要的。
Conventional CVR modeling applies popular deep learning methods and achieves state-of-the-art performance.
传统的CVR模型,采用了流行的深度学习方法,实现了优异的性能。
However it encounters several task-specific problems in practice, making CVR modeling challenging.
然而,在实践中,它们(注:传统的CVR模型)遭遇了一些任务特异性的(注:因实际任务导致的)问题,使得CVR建模具有挑战性。
For example, conventional CVR models are trained with samples of clicked impressions while utilized to make inference on the entire space with samples of all impressions. This causes a sample selection bias problem.
例如,传统的CVR模型,在训练时,使用的是被点击的曝光样本;然而在应用时,却要在整个曝光样本空间(注:既包括被点击,也包含未被点击的曝光样本)中进行推断。这导致了 样本选择偏差问题 。
Besides,there exists an extreme data sparsity problem, making the model fitting rather difficult.
此外,还存在严重的数据稀疏的问题,使得模型的拟合过程更加困难。
In this paper, we model CVR in a brand-new perspective by making good use of sequential pattern of user actions,i.e., impression → click → conversion.
在本文中,我们以一种全新的视角,对CVR进行建模,充分利用了用户行为的序列模式,即:曝光 → 点击 → 转化(购买)。
The proposed Entire-Space Multi-task Model (ESMM) can eliminate the two problems simultaneously by
(本文)提出的全空间多任务模型(ESMM),可以同时消除这两个问题,通过:
i) modeling CVR directly over the entire space,
ii) employing a feature representation transfer learning strategy.
- i) 在整个空间上直接建模CVR,
- ii) 采用特征表示迁移学习策略
Experiments on dataset gathered from traffic logs of Taobao’s recommender system demonstrate that ESMM significantly outperforms competitive methods.
我们收集淘宝推荐系统的交易日志,组成了数据集。在该数据集上进行的实验表明,ESMM的性能明显优于其他方法。
We also release a sampling version of this dataset to enable future research.
同时,我们发布了该数据集的一个抽样版本,用于未来的研究。
To the best of our knowledge, this is the first public dataset which contains samples with sequential dependence of click and conversion labels for CVR modeling.
据我们所知,这是第一个公开数据集:其中的样本具有单击和转化(购买)的行为标签,具有序列依赖性,可以用于CVR建模。
关键词 (KEYWORDS)
post-click conversion rate, multi-task learning, sample selection bias, data sparsity, entire-space modeling
点击后转化率,多任务学习,样本选择偏差,数据稀疏性,全空间建模
1. 介绍 (INTRODUCTION)

Conversion rate (CVR) prediction is an essential task for ranking system in industrial applications, such as online advertising and recommendation etc. For example, predicted CVR is used in OCPC (optimized cost-per-click) advertising to adjust bid price per click to achieve a win-win of both platform and advertisers [4]. It is also an important factor in recommender systems to balance users’ click preference and purchase preference.
在线广告、推荐等工业应用中,转化率(CVR)预测是排名系统的一项重要任务。例如,CVR预测 被应用于在OCPC(最优点击成本)广告任务中,用于调整每次点击竞价,达到平台和广告主的双赢[4]。此外,平衡(注:预估)用户的点击偏好和购买倾向,也是推荐系统的一个重要因素(注:重要需求)。
In this paper, we focus on the task of post-click CVR estimation. To simplify the discussion, we take the CVR modeling in recommender system in e-commerce site as an example. Given recommended items, users might click interested ones and further buy some of them. In other words, user actions follow a sequential pattern of impression → click → conversion. In this way, CVR modeling refers to the task of estimating the post-click conversion rate, i.e., pCVR = p(conversion|click, impression).
本文中,我们主要研究点击后CVR的估计任务。为了简化讨论,我们以电子商务网站中,推荐系统的CVR建模为例。给定若干推荐商品,用户可能会点击他感兴趣的一部分,进一步可能购买。换句话说,用户的操作遵循一个序列模式:曝光→点击→转化(购买)。在这里,CVR建模任务,指的是估算物品被点击后的转化概率,即pCVR = p(转化|点击,曝光)。
In general, conventional CVR modeling methods employ similar techniques developed in click-through rate (CTR) prediction task, for example, recently popular deep networks [2, 3]. However, there exist several task-specific problems, making CVR modeling challenging. Among them, we report two critical ones encountered in our real practice:
一般来说,传统的CVR建模方法采用了与点击率(CTR)预测任务相似的技术,例如最近流行的深度网络[2,3]。然而,CVR建模存在一些特定于任务的问题(注:理解为,任务不同,导致问题不同),这使得CVR建模具有挑战性。其中,我们指出实践中遇到两个突出问题:
i) sample selection bias (SSB) problem [12]. As illustrated in Fig.1, conventional CVR models are trained on dataset composed of clicked impressions, while are utilized to make inference on the entire space with samples of all impressions. SSB problem will hurt the generalization performance of trained models.
- (1)样本选择偏差(Sample Selection Bias, SSB) 问题[12]。如图1所示,传统的CVR模型在被点击的曝光样本组成的数据集上进行训练,然而在应用时,却要在整个曝光空间进行推断(注:也包含了未被点击的曝光样本)。样本选择偏差(SSB)问题会降低训练模型的泛化性能。
ii) data sparsity (DS) problem. In practice, data gathered for training CVR model is generally much less than CTR task. Sparsity of training data makes CVR model fitting rather difficult.
- (2)数据稀疏性(Data Sparsity, DS) 问题。在实践中,可用于训练CVR模型的数据,通常远少于CTR任务。训练数据的稀疏性,使得CVR模型的拟合过程更加困难。
There are several studies trying to tackle these challenges.
有一些研究方向,试图解决这些挑战:
In [5], hierarchical estimators on different features are built and combined with a logistic regression model to solve DS problem. However, it relies on a priori knowledge to construct hierarchical structures, which is difficult to be applied in recommender systems with tens of millions of users and items.
- 在[5]中,建立了不同特征上的分层估计器,并结合逻辑回归模型来解决数据稀疏(DS)问题。但是,该方案依赖先验知识来构建层次结构,难以应用于拥有数千万用户和物品的推荐系统。
Oversampling method [11] copies rare class examples which helps lighten sparsity of data but is sensitive to sampling rates.
- 过采样方案[11]通过对罕见类别的样本进行复制,缓解了数据的稀疏性,但对采样率很敏感。
All Missing As Negative (AMAN) applies random sampling strategy to select un-clicked impressions as negative examples [6]. It can eliminate the SSB problem to some degree by introducing unobserved examples, but results in a consistently underestimated prediction.
- AMAN方案(All Missing As Negative)采用随机抽样策略,选取未被点击的曝光数据作为负样本[6]。它可以在一定程度上消除样本选择偏差(SSB)问题,即通过引入未被观察到的样本(注:原本不存在于真实数据集中,因为没有被点击,所以缺少点击和转化标签),但该方案可导致持续低估问题。
Unbiased method [10] addresses SSB problem in CTR modeling by fitting the truly underlying distribution from observations via rejection sampling. However, it might encounter numerical instability when weighting samples by division of rejection probability.
- 去偏差方法[10]通过拒绝抽样,拟合观测数据的真实的潜在分布,以解决CTR建模中的样本选择偏差(SSB)问题。但是,该方案可能会遭遇数值不稳定,因为计算样本权重时,会有除以拒绝概率的操作(注:可能会除0或除以小值,引发病态问题)。
In all, neither SSB nor DS problem has been well addressed in the scenario of CVR modeling, and none of above methods exploits the information of sequential actions.
总之,在CVR建模场景中,SSB和DS问题都没有得到很好的解决,而且 上述方案都没有利用序列行为的信息 。
In this paper, by making good use of sequential pattern of user actions, we propose a novel approach named Entire Space Multitask Model (ESMM), which is able to eliminate the SSB and DS problems simultaneously.
本文通过充分利用用户行为的序列模式,提出了一种新的方法,称为全空间多任务模型(ESMM),能够同时消除SSB和DS问题。
In ESMM, two auxiliary tasks of predicting the post-view click-through rate (CTR) and post-view click-through & conversion rate (CTCVR) are introduced.
在ESMM中,引入了两个辅助任务,即预测浏览后点击率(CTR) 和 浏览后点击转化率(CTCVR)。
Instead of training CVR model directly with samples of clicked impressions, ESMM treats pCVR as an intermediate variable which multiplied by pCTR equals to pCTCVR.
ESMM不直接用点击曝光样本训练CVR模型,而是将pCVR作为中间变量,乘以pCTR,得到pCTCVR。
Both pCTCVR and pCTR are estimated over the entire space with samples of all impressions, thus the derived pCVR is also applicable over the entire space. It indicates that SSB problem is eliminated.
pCTCVR和pCTR都是在包含所有曝光样本的整个空间中估算的,因此导出的pCVR也适用于整个空间。因此样本选择偏差(SSB)问题可以消除。
Besides, parameters of feature representation of CVR network is shared with CTR network. The latter one is trained with much richer samples. This kind of parameter transfer learning [7] helps to alleviate the DS trouble remarkablely.
另外,CVR网络中的特征表示参数与CTR网络共享,而后者是在更大的样本空间训练得到的,因此这种参数迁移学习[7]有助于显著缓解数据稀疏(DS)问题。
For this work, we collect traffic logs from Taobao’s recommender system. The full dataset consists of 8.9 billions samples with sequential labels of click and conversion. Careful experiments are conducted. ESMM consistently outperforms competitive models, which demonstrate the effectiveness of the proposed approach.
在这项工作中,我们从淘宝的推荐系统中收集了交易日志。完整的数据集由89亿样本组成,带有单击和转化的顺序标签。经过精细的实验,ESMM始终优于其他竞争模型,这证明了所提方法的有效性。
We also release our dataset 1 ^1 1 for future research in this area.
(Note 1: https://tianchi.aliyun.com/datalab/dataSet.html?dataId=408)
同时,我们还发布了我们的数据集 1 ^1 1,用于该领域的进一步研究。
(原文注释1:https://tianchi.aliyun.com/datalab/dataSet.html?dataId=408)
2. 提出的方法 THE PROPOSED APPROACH
2.1 符号 Notation
We assume the observed dataset to be S = { ( x i , y i → z i ) } ∣ i = 1 N } \mathcal{S} = \{(x_i,y_i→z_i)\} |_{i=1}^N \} S={(xi,yi→zi)}∣i=1N} with sample ( x , y → z ) (x,y → z) (x,y→z) drawn from a distribution D D D with domain X × Y × Z \mathcal{X \times Y \times Z} X×Y×Z, where X \mathcal{X} X is feature space, Y \mathcal{Y} Y and Z \mathcal{Z} Z are label spaces, and N N N is the total number of impressions.
定义观测数据集为 S = { ( x i , y i → z i ) } ∣ i = 1 N } \mathcal{S} = \{(x_i,y_i→z_i)\} |_{i=1}^N \} S={(xi,yi→zi)}∣i=1N} ,假设其中的样本 ( x , y → z ) (x,y→z) (x,y→z)取自分布 D D D,所在域为 X × Y × Z \mathcal{X \times Y \times Z} X×Y×Z,其中 X \mathcal{X} X为特征空间, Y \mathcal{Y} Y和 Z \mathcal{Z} Z为标签空间, N N N为总曝光数。
x x x represents feature vector of observed impression, which is usually a high dimensional sparse vector with multi-fields [8], such as user field, item field etc.
x x x表示观察到的曝光(注:曝光事件或曝光场景)的特征向量,通常是一个高维稀疏向量,有多个特征域[8],如用户域、物品域等。
y y y and z z z are binary labels with y = 1 y = 1 y=1 or z = 1 z = 1 z=1 indicating whether click or conversion event occurs respectively. y → z y → z y→z reveals the sequential dependence of click and conversion labels that there is always a preceding click when conversion event occurs.
y y y和 z z z是0-1标签, y = 1 y = 1 y=1或 z = 1 z = 1 z=1分别表示出现了点击行为和转化(购买)行为。 y → z y → z y→z表明了点击和转化标签的先后依赖关系:当出现转化(购买)行为时,前面总是会有一个点击行为。
Post-click CVR modeling is to estimate the probability of p C V R = p ( z = 1 ∣ y = 1 , x ) pCVR = p(z = 1|y = 1, x) pCVR=p(z=1∣y=1,x).
点击后CVR建模,即估计概率 p C V R = p ( z = 1 ∣ y = 1 , x ) pCVR = p(z = 1|y = 1, x) pCVR=p(z=1∣y=1,x)。
Two associated probabilities are: post-view click-through rate (CTR) with p C T R = p ( z = 1 ∣ x ) pCTR = p(z = 1|x) pCTR=p(z=1∣x) and post-view click&conversion rate (CTCVR) with p C T C V R = p ( y = 1 , z = 1 ∣ x ) pCTCVR = p(y = 1, z = 1|x) pCTCVR=p(y=1,z=1∣x).
两个相关的概率是:浏览后的点击概率(CTR),即 p C T R = p ( y = 1 ∣ x ) pCTR = p(y = 1|x) pCTR=p(y=1∣x)(注:原文应该是出现了笔误,这里直接进行了修正,z改成了y),以及 浏览后点击并转化概率(CTCVR),即 p C T C V R = p ( y = 1 , z = 1 ∣ x ) pCTCVR = p(y = 1, z = 1|x) pCTCVR=p(y=1,z=1∣x)。
Given impression x x x, these probabilities follow Eq.(1):
给定曝光事件的特征向量 x x x,上述概率遵循公式(1):

2.2 CVR建模和挑战 CVR Modeling and Challenges
Recently deep learning based methods have been proposed for CVR modeling, achieving state-of-the-art performance.
最近,很多基于深度学习的CVR建模方法被提出,并取得了优异的效果。
Most of them follow a similar Embedding & MLP network architecture, as introduced in [3]. The left part of Fig.2 illustrates this kind of architecture, which we refer to as BASE model, for the sake of simplicity.
它们大多数遵循了一种相似的Embedded & MLP神经网络架构,如文献[3]中所介绍。图2的左边展示了这种架构,为了简单起见,我们将其称为BASE模型。

In brief, conventional CVR modeling methods directly estimate the post-click conversion rate p ( z = 1 ∣ y = 1 , x ) p(z = 1|y = 1, x) p(z=1∣y=1,x).
简而言之,传统的CVR建模方法,直接估算点击后转化率 p ( z = 1 ∣ y = 1 , x ) p(z = 1|y = 1, x) p(z=1∣y=1,x)。
They train models with samples of clicked impressions, i.e., S c = { ( x j , z j ) ∣ y j = 1 } ∣ j = 1 M \mathcal{S_c} = \{(x_j , z_j )|y_j = 1 \} |_{j=1}^M Sc={(xj,zj)∣yj=1}∣j=1M. M M M is the number of clicks over all impressions. Obviously, S c \mathcal{S_c} Sc is a subset of S \mathcal{S} S.
他们用被点击的曝光样本训练模型,即 S c = { ( x j , z j ) ∣ y j = 1 } ∣ j = 1 M \mathcal{S_c} = \{(x_j , z_j )|y_j = 1 \} |_{j=1}^M Sc={(xj,zj)∣yj=1}∣j=1M. 其中 M M M是所有曝光样本的点击量。显然, S c \mathcal{S_c} Sc是 S \mathcal{S} S的子集。
Note that in S c \mathcal{S_c} Sc , (clicked) impressions without conversion are treated as negative samples and impressions with conversion (also clicked) as positive samples.
需要指出的是,在 S c \mathcal{S_c} Sc中,(被点击的)没有发生转化的曝光样本被视为负样本,而发生转换(也被点击)的曝光样本被视为正样本。
In practice, CVR modeling encounters several task-specific problems, making it challenging.
在实践中,CVR建模会遇到一些特定于任务的问题,使其具有挑战性。
(1) 样本选择偏差 Sample selection bias (SSB) [12]
In fact, conventional CVR modeling makes an approximation of p ( z = 1 ∣ y = 1 , x ) ≈ q ( z = 1 ∣ x c ) p(z = 1|y = 1, x) ≈ q(z = 1|x_c) p(z=1∣y=1,x)≈q(z=1∣xc) by introducing an auxiliary feature space X c \mathcal{X_c} Xc.
事实上,传统的CVR建模通过引入辅助特征空间 X c \mathcal{X_c} Xc,来近似 p ( z = 1 ∣ y = 1 , x ) ≈ q ( z = 1 ∣ x c ) p(z = 1|y = 1, x)≈q(z = 1|x_c) p(z=1∣y=1,x)≈q(z=1∣xc)。
X c \mathcal{X_c} Xc represents a limited 2 ^2 2 space associated with S c \mathcal{S_c} Sc. ∀ x c ∈ X c \forall x_c \in \mathcal{X_c} ∀xc∈Xc there exists a pair ( x = x c , y x = 1 ) (x = x_c ,y_x = 1) (x=xc,yx=1) where x ∈ X x \in \mathcal{X} x∈X and y x y_x yx is the click label of x.
(Note 2: Space X c \mathcal{X_c} Xc equals to X \mathcal{X} X under the condition that ∀ X ∈ X , p ( y = 1 ∣ x ) > 0 \forall X \in \mathcal{X}, p(y = 1|x ) > 0 ∀X∈X,p(y=1∣x)>0 and the number of observed impressions is large enough. Otherwise, space X c \mathcal{X_c} Xc is part of X \mathcal{X} X.)
X c \mathcal{X_c} Xc表示一个与 S c \mathcal{S_c} Sc相关的有限空间 2 ^2 2。 ∀ x c ∈ X c \forall x_c \in \mathcal{X_c} ∀xc∈Xc,存在一个数据对 ( x = x c , y x = 1 ) (x = x_c,y_x = 1) (x=xc,yx=1),其中 x ∈ X x \in \mathcal{X} x∈X, y x y_x yx中是 x x x的点击标签。
(原文注释2:当且仅当 ∀ x ∈ X , p ( y = 1 ∣ x ) > 0 \forall x \in \mathcal{X}, p(y = 1|x ) > 0 ∀x∈X,p(y=1∣x)>0并且被观测到的曝光事件足够多,样本空间 X c \mathcal{X_c} Xc才会与 X \mathcal{X} X相同;否则,样本空间 X c \mathcal{X_c} Xc只是 X \mathcal{X} X的一个子集)(注:原文注释里可能有笔误,这里把其中的 X X X修改 x x x)。
In this way, q ( z = 1 ∣ x c ) q(z = 1|x_c) q(z=1∣xc) is trained over space X c \mathcal{X_c} Xc with clicked samples of S c \mathcal{S_c} Sc. At inference stage, the prediction of p ( z = 1 ∣ y = 1 , x ) p(z = 1|y = 1, x) p(z=1∣y=1,x) over entire space X \mathcal{X} X is calculated as q ( z = 1 ∣ x ) q(z = 1|x) q(z=1∣x) under the assumption that for any pair of ( x , y x = 1 ) (x, y_x = 1) (x,yx=1) where x ∈ X x \in \mathcal{X} x∈X, x x x belongs to X c \mathcal{X_c} Xc.
这样,(注:在训练阶段) q ( z = 1 ∣ x c ) q(z = 1|x_c) q(z=1∣xc)在样本空间 X c \mathcal{X_c} Xc训练,使用被点击的样本集合 S c \mathcal{S_c} Sc。在推断阶段,预测值 p ( z = 1 ∣ y = 1 , x ) p(z = 1|y = 1, x) p(z=1∣y=1,x)却要在整个样本空间 X \mathcal{X} X进行估计,并被近似为 q ( z = 1 ∣ x ) q(z = 1|x) q(z=1∣x). 这(注:从 X c \mathcal{X_c} Xc外推到 X \mathcal{X} X,以及概率近似的合理性)基于一个假设:对于任何一个 x ∈ X x \in \mathcal{X} x∈X的数据对 ( x , y x = 1 ) (x, y_x = 1) (x,yx=1), x x x属于 X c \mathcal{X_c} Xc。
This assumption would be violated with a large probability as X c \mathcal{X_c} Xc is just a small part of entire space X \mathcal{X} X. It is affected heavily by the randomness of rarely occurred click event, whose probability varies over regions in space X \mathcal{X} X.
这个假设很可能并不成立,因为 X c \mathcal{X_c} Xc只是整个空间 X \mathcal{X} X中的一小部分。它容易受到随机性的严重的影响:因为点击行为很少出现,存在着太多的随机性,在空间 X \mathcal{X} X的不同区域,(点击行为)往往有着不同的概率分布。
Moreover, without enough observations in practice, space X c \mathcal{X_c} Xc may be quite different from X \mathcal{X} X. This would bring the drift of distribution of training samples from truly underling distribution and hurt the generalization performance for CVR modeling.
此外,如果在实际应用中没有足够的观察信息(注:观察到的事件较少,数据收集不全面),空间 X c \mathcal{X_c} Xc可能与 X \mathcal{X} X大不相同。这可能使训练样本的分布发生漂移,远离真实的潜在分布,进而影响CVR模型的泛化性能。
(2) 数据稀疏性 Data sparsity (DS)
Conventional methods train CVR model with clicked samples of S c \mathcal{S_c} Sc. The rare occurrence of click event causes training data for CVR modeling to be extremely sparse.
传统的方法,是利用点击样本组成的数据集 S c \mathcal{S_c} Sc训练CVR模型。由于点击行为极少出现,使得可用于CVR建模的训练数据极其稀少。
Intuitively, it is generally 1-3 orders of magnitude less than the associated CTR task, which is trained on dataset of S \mathcal{S} S with all impressions.
直观上,它通常比相关的CTR任务少1-3个数量级,后者可以利用所有曝光样本组成的数据集 S \mathcal{S} S进行训练。
Table 1 shows the statistics of our experimental datasets, where number of samples for CVR task is just 4% of that for CTR task.
表1显示了我们实验数据集的统计结果,其中CVR任务的样本数量仅为CTR任务的4%。

(3) 其他挑战 other challenges
It is worth mentioning that there exists other challenges for CVR modeling, e.g. delayed feedback [1].
值得一提的是,CVR建模还存在其他挑战,如延迟反馈[1]。
This work does not focus on it. One reason is that the degree of conversion delay in our system is slightly acceptable. The other is that our approach can be combined with previous work [1] to handle it.
本文工作并没有聚焦于此。一个原因是,在我们的系统中,延迟转化(注:没有立即购买)的程度是稍微可以接受的;另一个原因是,我们的方法可以与之前的工作[1]结合,解决这个问题。
2.3 ESMM模型 Entire Space Multi-Task Model
The proposed ESMM is illustrated in Fig.2, which makes good use of the sequential pattern of user actions. Borrowing the idea from multi-task learning [9], ESMM introduces two auxiliary tasks of CTR and CTCVR and eliminates the aforementioned problems for CVR modeling simultaneously.
本文提出的ESMM模型如图2所示(上面2.2节),它很好地利用了用户行为的序列模式。借鉴多任务学习[9]的思想,ESMM引入了CTR和CTCVR两个辅助任务,同时消除了CVR建模的上述问题(注:样本选择偏差 和 数据稀疏)。
On the whole, ESMM simultaneously outputs pCTR, pCVR as well as pCTCVR w.r.t. a given impression. It mainly consists of two sub-networks: CVR network illustrated in the left part of Fig.2 and CTR network in the right part. Both CVR and CTR networks adopt the same structure as BASE model. CTCVR takes the product of outputs from CVR and CTR network as the output.
总的来说,当给定一个曝光事件(注:输入曝光事件的特征向量 x x x)ESMM同时输出pCTR、pCVR和pCTCVR。它主要由两个子网络组成: 图2左侧的CVR网络,图2右侧的CTR网络。CVR和CTR网络采用与BASE模型相同的结构。CTCVR以CVR和CTR网络输出的乘积作为输出。
There are some highlights in ESMM, which have notable effects on CVR modeling and distinguish ESMM from conventional methods.
区别于传统方法,ESMM方法在CVR建模中有一些突出的亮点,对CVR建模有显著的效果。(注:如下)
(1)在整个空间建模 Modeling over entire space.
(注:在整个曝光空间 X \mathcal{X} X)
Eq.(1) gives us hints, which can be transformed into Eq.(2).
公式1给我们提供了思路,因此可以导出公式2:
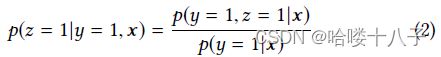
Here p ( y = 1 , z = 1 ∣ x ) p(y = 1, z = 1|x) p(y=1,z=1∣x) and p ( y = 1 ∣ x ) p(y = 1|x) p(y=1∣x) are modeled on dataset of S \mathcal{S} S with all impressions. Eq.(2) tells us that with estimation of pCTCVR and pCTR, pCVR can be derived over the entire input space X \mathcal{X} X, which addresses the sample selection bias problem directly.
这里 p ( y = 1 , z = 1 ∣ x ) p(y = 1, z = 1|x) p(y=1,z=1∣x) 和 p ( y = 1 ∣ x ) p(y = 1|x) p(y=1∣x) 是基于数据集 S \mathcal{S} S建模的,即使用全量的曝光数据。公式(2)告诉我们,通过估计pCTCVR和pCTR,pCVR可以在整个输入空间 X \mathcal{X} X上推导出来,这直接解决了样本选择偏差问题。
This seems easy by estimating pCTR and pCTCVR with individually trained models separately and obtaining pCVR by Eq.(2), which we refer to as DIVISION for simplicity. However, pCTR is a small number practically, divided by which would arise numerical instability.
还有另外一种看似很容易的方法,即单独训练的模型,分别估计pCTR和pCTCVR,再通过公式(2)得到pCVR,为了简化描述,我们称其为DIVISION方法(注:除法)。然而,pCTR实际上是一个很小的数,除以它会引起数值不稳定。
ESMM avoids this with the multiplication form. In ESMM, pCVR is just an intermediate variable which is constrained by the equation of Eq.(1). pCTR and pCTCVR are the main factors ESMM actually estimated over entire space.
ESMM避免了这种情况(注:数值不稳定),通过使用乘法的形式。在ESMM中,pCVR只是一个中间变量,并受到公式(1)约束。实际上,pCTR和pCTCVR才是主要的因素(注:建模的主要对象),ESMM在整个空间对其进行估计。
The multiplication form enables the three associated and co-trained estimators to exploit the sequential patten of data and communicate information with each other during training. Besides, it ensures the value of estimated pCVR to be in range of [0,1], which in DIVISION method might exceed 1.
乘法的形式,使得(注:上述)三个相互关联、共同训练的估计器,能够利用数据中的序列模式,并在训练期间相互传递信息。同时,也保证了pCVR的估计值在[0,1]的范围内,相反的,DIVISION方法中(注:pCVR)可能会超过1。
The loss function of ESMM is defined as Eq.(3). It consists of two loss terms from CTR and CTCVR tasks which are calculated over samples of all impressions, without using the loss of CVR task.
ESMM的损失函数定义为公式(3)。它包含两个损失项,分别来自CTR和CTCVR任务。这些损失项是在所有的曝光样本上计算的。损失函数不使用CVR任务的损失(注:损失函数不直接考虑CVR任务的损失,但相当于间接考虑)。

where θ c t r \theta_{ctr} θctr and θ c v r \theta_{cvr} θcvr are the parameters of CTR and CVR networks and l ( ⋅ ) l(·) l(⋅) is cross-entropy loss function.
其中, θ c t r \theta_{ctr} θctr 和 θ c v r \theta_{cvr} θcvr 是CRT网络和CVR网络的参数, l ( ⋅ ) l(·) l(⋅)为交叉熵损失函数。
Mathematically, Eq.(3) decomposes y → z y → z y→z into two parts 3 ^3 3: y y y and y & z y \And z y&z, which in fact makes use of the sequential dependence of click and conversion labels.
(Note 3: Corresponding to labels of CTR and CTCVR tasks, which construct training datasets as follows: i) samples are composed of all impressions, ii) for CTR task, clicked impressions)
数学上,公式3把 y → z y → z y→z 分解为两个部分 3 ^3 3(注:两个先后过程): y y y 和 y & z y \And z y&z,实际上,这样便应用到了点击标签和转化标签之间的序列依赖信息;
(原文注释3:这两个部分,分别对应着CTR和CTCVR任务的标签;构建训练数据集的方法如下:i)样本由所有曝光事件组成,ii)对于CTR任务,(注:样本由所有)被点击的曝光事件(注:组成))
(2)特征表示迁移学习 Feature representation transfer.
As introduced in section 2.2, embedding layer maps large scale sparse inputs into low dimensional representation vectors. It contributes most of the parameters of deep network and learning of which needs huge volume of training samples.
如2.2节所介绍的,embedding层将大尺度稀疏输入向量,映射为低维表示向量。它贡献了深度神经网络中的大部分参数,其训练过程需要大量的训练样本。
In ESMM, embedding dictionary of CVR network is shared with that of CTR network. It follows a feature representation transfer learning paradigm. Training samples with all impressions for CTR task is relatively much richer than CVR task. This parameter sharing mechanism enables CVR network in ESMM to learn from un-clicked impressions and provides great help for alleviating the data sparsity trouble.
在ESMM中,CVR网络的embedding表示字典与CTR网络共享。它遵循了特征表示迁移学习的模式。CTR任务的训练数据,由所有曝光样本组成,因此相对于CVR任务的训练数据要丰富得多。该参数共享机制,使ESMM中的CVR网络能够从未被点击的曝光数据中学习,为缓解数据稀疏问题,提供了很大的帮助。
Note that the sub-network in ESMM can be substituted with some recently developed models [2, 3], which might get better performance. Due to limited space, we omit it and focus on tackling challenges encountered in real practice for CVR modeling.
需要说明的是,ESMM中的子网络,也可以用其他新颖、先进的模型来替代[2,3],这可能会获得更好的性能。但由于篇幅有限,我们不作深入探索,本文仅专注于解决CVR建模在实践中遇到的挑战。
3 实验 EXPERIMENTS
3.1 实验设置 Experimental Setup
(1)数据集 Datasets.
During our survey, no public datasets with sequential labels of click and conversion are found in CVR modeling area.
我们在调研阶段发现,在CVR建模领域,没有关于 点击+转化 序列标签的公开数据集。
To evaluate the proposed approach, we collect traffic logs from Taobao’s recommender system and release a 1% random sampling version of the whole dataset, whose size still reaches 38GB (without compression).
为了评估上面所提出的方法,我们从淘宝的推荐系统中收集了交易日志,从整个数据集中随机抽样了1%,作为公开版本发布,其大小仍然达到38GB(压缩前)。
In the rest of the paper, we refer to the released dataset as Public Dataset and the whole one as Product Dataset.
在本文的后续部分中,我们将发布的数据集称为公开数据集,将完整的数据集称为生产数据集(注:1:100的比例,随机抽样的子集关系)。
Table 1 summarizes the statistics of the two datasets. Detailed descriptions can be found in the website of Public Dataset 1 ^1 1.
(Note 1: https://tianchi.aliyun.com/datalab/dataSet.html?dataId=408)
表1总结了两个数据集的统计情况。更加详细的描述,可以查阅公开数据集网站 1 ^1 1。
(原文注释1:https://tianchi.aliyun.com/datalab/dataSet.html?dataId=408)
(2)对比算法 Competitors.
We conduct experiments with several competitive methods on CVR modeling.
我们使用几个有竞争力的CVR建模方法,进行了(注:对比)实验。
(1) BASE is the baseline model introduced in section 2.2.
(2) AMAN [6] applies negative sampling strategy and best results are reported with sampling rate searched in {10%, 20%, 50%, 100%}.
(3) OVERSAMPLING [11] copies positive examples to reduce difficulty of training with sparse data, with sampling rate searched in {2, 3, 5, 10}.
(4) UNBIAS follows [10] to fit the truly underlying distribution from observations via rejection sampling. pCTR is taken as the rejection probability.
(5) DIVISION estimates pCTR and pCTCVR with individually trained CTR and CTCVR networks and calculates pCVR by Eq.(2).
(6) ESMM-NS is a lite version of ESMM without sharing of embedding parameters.
- (1) BASE模型是2.2节中介绍的基线模型。
- (2) AMAN模型[6]采用了负采样策略,在{10%,20%,50%,100%}中搜索最佳采样率,得到最佳结果。
- (3) 过采样方法[11]对正样本进行了复制,降低了用稀疏数据进行训练的难度;采样率在{2,3,5,10}中搜索。
- (4) UNBIAS方法(注:去偏差方法)遵循文章[10],通过拒绝抽样,来拟合观察数据的真实的底层分布。pCTR被用作拒绝概率(注:?)。
- (5) DIVISION 通过 单独训练的CTR和CTCVR网络,实现pCTR和pCTCVR的估计,并通过公式(2)计算pCVR。
- (6) ESMM-NS是精简版的ESMM,不共享嵌入参数(注:No Share)。
The first four methods are different variations to model CVR directly based on state-of-the-art deep network.
前四种方法,直接建立CVR模型,均基于深度神经网络,属于不同的变体。
DIVISION, ESMM-NS and ESMM share the same idea to model CVR over entire space which involve three networks of CVR, CTR and CTCVR.
DIVISION、ESMM-NS和ESMM三种方法,有着相同的思路,即在全空间建立CVR模型,涉及CVR、CTR和CTCVR三个网络模型。
ESMM-NS and ESMM co-train the three networks and take the output from CVR network for model comparison.
ESMM-NS 和 ESMM 共同训练三个网络,并从CVR网络中获取输出结果,用于模型对比。
To be fair, all competitors including ESMM share the same network structure and hyper parameters with BASE model, which
i) uses ReLU activation function,
ii) sets the dimension of embedding vector to be 18,
iii) sets dimensions of each layers in MLP network to be 360 × 200 × 80 × 2,
iv) uses adam solver with parameter β 1 = 0.9 , β 2 = 0.999 , ϵ = 1 0 − 8 \beta_1 = 0.9, \beta_2 = 0.999, \epsilon = 10^{−8} β1=0.9,β2=0.999,ϵ=10−8.
公平起见,包括ESMM在内的所有对比算法,都与BASE模型有着相同的网络结构和超参数:
- 使用ReLU激活函数,
- 设置embedding表示向量的维度为 18,
- 设置MLP网络各层大小为 360 × 200 × 80 × 2,
- 使用Adam求解器,参数 β 1 = 0.9 , β 2 = 0.999 , ϵ = 1 0 − 8 \beta_1 = 0.9, \beta_2 = 0.999, \epsilon = 10^{−8} β1=0.9,β2=0.999,ϵ=10−8。
(3)效果度量 Metric.
The comparisons are made on two different tasks:
- (1) conventional CVR prediction task which estimates pCVR on dataset with clicked impressions,
- (2) CTCVR prediction task which estimates pCTCVR on dataset with all impressions.
对比实验是在两个不同的任务上进行的:
- (1) 传统的CVR预测任务,即在被点击的曝光数据集上,估计pCVR;
- (2) CTCVR预测任务,即在整个曝光数据集上(注:含未被点击的曝光),估计pCTCVR。
Task (2) aims to compare different CVR modeling methods over entire input space, which reflects the model performance corresponding to SSB problem.
Task(2)的目的是,在整个输入空间上,比较不同的CVR建模方法,这反映了样本选择偏差问题对模型性能的影响。
In CTCVR task, all models calculate pCTCVR by pCTR × pCVR, where:
- i) pCVR is estimated by each model respectively,
- ii) pCTR is estimated with a same independently trained CTR network (same structure and hyper parameters as BASE model).
在CTCVR任务中,所有模型通过 pCTR × pCVR计算pCTCVR,其中:
- i) pCVR由各模型分别估计,
- ii) pCTR的估计,采用一个相同的、独立训练的CTR网络(结构和超参数与BASE模型相同)。
Both of the two tasks split the first 1/2 data in the time sequence to be training set while the rest to be test set.
两个任务,都按照时间顺序,将前1/2时间的数据分割为训练集,其余的作为测试集(注:避免时间穿越)。
Area under the ROC curve (AUC) is adopted as performance metrics. All experiments are repeated 10 times and averaged results are reported.
选取AUC作为性能指标。所有实验均重复10次,取其平均值,作为报告结果(注:10折交叉验证)。
3.2 公开数据集(少量)实验结果 Results on Public Dataset
Table 2 shows results of different models on public dataset.
表2显示了公开数据集上不同模型的结果。
(1) Among all the three variations of BASE model, only AMAN performs a little worse on CVR task, which may be due to the sensitive of random sampling. OVERSAMPLING and UNBIAS show improvement over BASE model on both CVR and CTCVR tasks.
- (1) 在三种BASE模型的变种中,只有AMAN模型在CVR任务上表现稍差,这可能与随机抽样的敏感性有关。在CVR和CTCVR任务中,过采样和UNBIAS均优于BASE模型。
(2) Both DIVISION and ESMM-NS estimate pCVR over entire space and achieve remarkable promotions over BASE model. Due to the avoidance of numerical instability, ESMM-NS performs better than DIVISION.
- (2) DIVISION和ESMM-NS模型,均在整个(注:曝光)空间对pCVR进行估计,相比于BASE模型取得了显著提升。由于避免了数值不稳定的问题,ESMM-NS的性能优于DIVISION。
(3) ESMM further improves ESMM-NS. By exploiting the sequential patten of user actions and learning from un-clicked data with transfer mechanism, ESMM provides an elegant solution for CVR modeling to eliminate SSB and DS problems simultaneously and beats all the competitors.
- (3) ESMM进一步提升了ESMM-NS的效果。它利用了用户行为的序列模式,并基于迁移学习机制,从未被点击的数据中进行学习,为CVR建模提供了一个优雅的解决方案,可以同时消除 样本选择偏差 和 数据稀疏 问题,击败了所有竞争算法。
Compared with BASE model, ESMM achieves absolute AUC gain of 2.56% on CVR task, which indicates its good generalization performance even for biased samples. On CTCVR task with full samples, it brings 3.25% AUC gain. These results validate the effectiveness of our modeling method.
与BASE模型相比,ESMM在CVR任务上获得了2.56%的绝对AUC增益,这表明,即使使用有偏样本,ESMM也具有良好的泛化性能。在全量样本的CTCVR任务中,ESMM模型带来了3.25%的AUC增益。这些结果验证了ESMM建模方法的有效性。

3.3 生产数据集(全量)实验结果 Results on Product Dataset
We further evaluate ESMM on our product dataset with 8.9 billions of samples, two orders of magnitude larger than public one.
进一步的,我们使用了生产数据集,对ESMM模型进行了评估,样本数量89亿,比公开数据集大两个数量级。
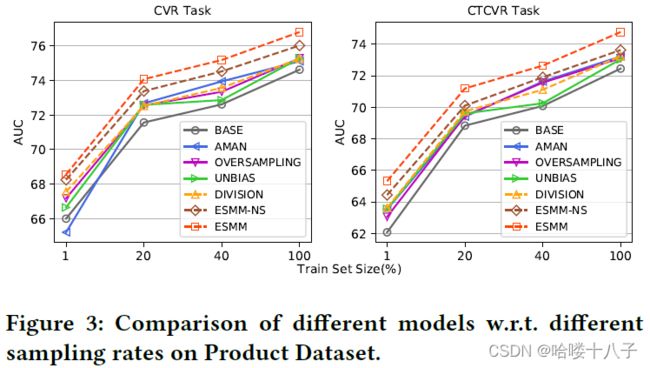
To verify the impact of the volume of the training dataset, we conduct careful comparisons on this large scale datasets w.r.t. different sampling rates, as illustrated in Fig.3.
为了验证训练集大小对模型的影响,我们使用这个大规模数据集,进行了精细的对比实验,通过不同抽样比例,如图3所示。
First, all methods show improvement with the growth of volume of training samples. This indicates the influence of data sparsity. In all cases except AMAN on 1% sampling CVR task, BASE model is defeated.
首先,随着训练集样本量的增加,所有的算法效果均有提高。这说明了数据稀疏性对模型的影响。在所有情况中,除了【CVR任务 + 1%训练集 + AMAN模型】这一组数据,BASE模型的效果都相对较差。
Second, ESMM-NS and ESMM outperform all competitors consistently w.r.t. different sampling rates. In particular, ESMM maintains a large margin of AUC promotion over all competitors on both CVR and CTCVR tasks.
其次,在不同采样率下,ESMM-NS 和 ESMM始终优于所有其他算法。尤其是ESMM,相比于其他算法,ESMM始终保持着很大的AUC提升,无论在CVR还是CTCVR任务。
BASE model is the latest version which serves the main traffic in our real system. Trained with the whole dataset, ESMM achieves absolute AUC gain of 2.18% on CVR task and 2.32% on CTCVR task over BASE model. This is a significant improvement for industrial applications where 0.1% AUC gain is remarkable.
BASE模型是我们实际系统中使用的最新版本,为大部分交易提供着支持。使用全量数据集训练的ESMM模型,与BASE模型相比,可以在CVR任务中达到2.18%的AUC绝对增益,在CTCVR任务中达到2.32%的AUC绝对增益。在工业应用中,这是一个显著的提升,因为(注:在工业应用的场景中)即使只带来0.1%的AUC增益,也是重要的成就(注:将带来可观的的经济收益增长)。
4 总结与后续 CONCLUSIONS AND FUTUREWORK
In this paper, we propose a novel approach ESMM for CVR modeling task. ESMM makes good use of sequential patten of user actions.
在本文中,我们提出了一种新的方法ESMM,用于CVR建模。它很好地利用了用户操作的序列模式。
With the help of two auxiliary tasks of CTR and CTCVR, ESMM elegantly tackles challenges of sample selection bias and data sparsity for CVR modeling encountered in real practice.
在CTR和CTCVR两项辅助任务的帮助下,ESMM优雅地解决了样本选择偏差和数据稀疏问题,这两个问题在CVR建模的实际应用中会经常遇到。
Experiments on real dataset demonstrate the superior performance of the proposed ESMM.
在实际数据集上的实验,证明了本文提出的ESMM模型的优越性能。
This method can be easily generalized to user action prediction in scenario with sequential dependence.
该方法可以轻易地推广到(注:其他)用户行为预测任务中,在该场景下,用户行为具有序列依赖性。
In the future, we intend to design global optimization models in applications with multi-stage actions like request → impression → click → conversion.
在未来,我们希望设计全局最优的模型,应用到具有多步行为的任务中,例如 请求 → 曝光 → 点击 → 转化。
(The End)