周志华《机器学习》——降维与度量学习
有些数据集是包含非常多的属性的,这使得后续数据处理和计算非常困难。因此需要对数据进行降维,需要找到一种合理的方法,在减少需要分析的属性同时,尽量减少信息的损失。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。
根据对降维后数据的要求不同,有如下几种常用的数据降维方法:
1、 MDS
MDS降维后的数据满足,从原始空间D到d维空间后,样本两两间距不变。
2、 线性变换
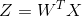 是一种线性变换。新空间中的属性是原空间中属性的线性组合
是一种线性变换。新空间中的属性是原空间中属性的线性组合
根据对低维空间性质的不同要求,不同的任务会在上式的基础上施加不同的约束,主成分分析就是一种线性变换
2.1 主成分分析PAC
PCA是一种线性变换。这个线性变换的约束是最近重构性和最大可分性。
- 最近重构性:样本点到这个超平面的距离都足够近
- 最大可分性:样本点在这个超平面的投影能够尽可能分开
上述两个约束对W的约束结果是一样的,优化目标都是
对上述优化目标的求解方法是:
对协方差矩阵 进行特征值分解,将求的的特征值排序,因为X的维度是D*m,所以特征值一共D个,取前d个特征值对应的特征向量,构成
进行特征值分解,将求的的特征值排序,因为X的维度是D*m,所以特征值一共D个,取前d个特征值对应的特征向量,构成![]() ,这就是主成分分解方法得到的低维空间。
,这就是主成分分解方法得到的低维空间。
从逻辑上将,PAC的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面d个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
4、核化线性降维
线性降维方法假设从高维空间到低维空间的函数映射是线性的,当需要非线性映射才能找到合适的低维嵌入时,可以使用核化的方法。

比如上图中,图a是从图b中采样然后以S型曲面嵌入三维空间的。成功的降维应该从图a再降回图b数据才可分。如果用线性方法进行降维,就会得到图c的结果,数据不再可分了,在这种情况下可以采用核化线性降维,实现从a到b。
和SVM中使用核函数相似,核函数的意义是将数据线映射到高维空间,然后再在高维空间中进行线性降维。
5、流形学习
流形学习的定性描述可参见此文。为了避免文章丢失,额外复制一份留档。
上节中说到,如果数据从当前维度到低维映射不是线性的,需要把数据先映射到更高维度,然后再降维,也就是使用核函数。
***************************个人认为,不确定对不对***************************************************************************************
个人认为,流形学习是一种通用于线性和非线性高低维关系的降维方法。
因为,在高维向低维映射的过程中,肯定是要满足一定的约束条件的,比如MDS的两点距离不变,或者PAC的最近重构性、最大可分性。
这样,降维的过程中就必然涉及对两个样本间距离进行计算。
线性降维方法中计算距离时都是计算两点的直线距离,也就是下图的黑线,但是实际上如图中所示,表征两点间距离的是沿着图形表面的弯曲的红色线组成的距离
解决上述问题的方法是
1、先把样本映射到高维空间,让其线性可分,也就是把红线拉直,然后计算直线距离。
2、就在样本的当前空间中,沿着图形表面直接计算红线距离。
核方法是1,流形学习是2,不同的流形学习方法就是计算红线距离的不同方法。

*************************************************************************************************************************************************
5.1 等度量映射Isomap
Isomap的思路是基于流形在局部上和欧式空间同胚(也就是距离很小时可以用欧氏距离近似)。
1、对初始点找到其近邻点,近邻点间可连接,非近邻点不可连接(保证路径是顺着图形面走的,不会直接走黑线)
2、计算从初始点到结束点,沿着最近邻点行进的最短路径
5.2 局部线性嵌入LLE
Isomap是试图保持近邻样本之间距离不变,局部线性嵌入LLE是基于保持邻域内样本之间的线性关系。
LLE假定样本坐标x可以通过她的邻域样本x1,x2和x3的坐标通过线性组合重构出来,即x=w1x1+w2x2+w3x3
LEE保持上式关系在低维空间中不变。
6.度量学习
降维是为了解决属性爆炸问题,也就是如何组合原来的D个属性成d个属性,d个属性可以不变形地表达样本之间的相对关系/距离,这样就可以在较小的d维数据集上进行计算。
所以其实降维的过程是在寻找,如何有效地利用原来的D维属性,计算样本之间距离/相似度的过程。
度量学习就是尝试直接“学习”初一个合适的距离度量。
原本的距离度量都是固定的,如欧式平方距离是两个样本d个属性距离的平方和 。度量学习为每个属性的距离的平方加一个权重
。度量学习为每个属性的距离的平方加一个权重 变成
变成 ,然后计算出
,然后计算出