学习-Java输入输出之Reader类之字符数据输入
第1关:学习-Java输入输出之Reader类之字符数据输入
- 任务描述
- 相关知识
- 什么是字符
- Reader 类(字符输入流)
- 常用子类
- 编程要求
- 测试说明
任务描述
本关任务:使用字符输入流读取给定路径中的文件数据。
相关知识
在学习字符数据输入 Reader 类之前,我们先来了解一下什么是字符。
什么是字符
我们想象一下,给你一串二进制码(如 1010),要你来分辨它是什么含义,是代表数字还是字母还是汉字,你能有效的分辨吗?
显然不能,一般来说,我们是比较难以理解一串二进制码代表的含义的,而且一串二进制码是代表什么含义也无法很直观的表示出来。
我们比较好识别的是文字、字母和符号。
所以就有了字符,字符是指计算机中使用的文字和符号,比如1、2、3、A、B、C、~!·#¥%……—*()——+、等等。
字符在计算机中可以看做:字节+编码表。什么意思呢?
我们知道,计算机是只识别二进制的,但是我们日常操作电脑,需要输入文字,字母,数字这些,我们不可能先去记住一串二进制数字,比如说 A 这个字母的二进制是什么,因为这样太麻烦,也记不住,所以编码表就诞生了,编码表的作用就是在我们进行输入的时候,将我们输入的字符转换成计算机能识别的二进制,在我们阅读数据的时候,将二进制转换成我们人能识别的文字、字母和数字。
最先普及就是如下图 1 的 ASCLL 码表,ASCLL 码表是美国信息交换标准代码,是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
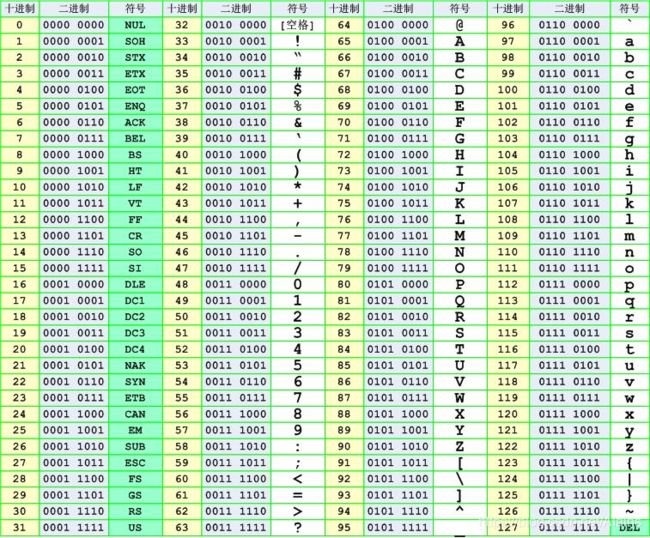
图1 ASCLL 码表
看到这你肯定会有疑问,这 ASCLL 码表只有英语和西欧语呀,那汉语呢,其他语言呢?
是的,自从 ASCLL 码表推出之后,很多国家也都推出了本国语言的编码表。像中国就有 GB2312 和 GBK 等等。
现在我们一起设想一个场景,当我们编辑一个文本文件,输入了很多字符,这些字符都用 ASCLL 码表编码,然后我们查看这个文本文件的时候,是使用的 GBK 码表解码,会出现什么问题吗?
相信你已经有答案了,这会出现软件开发中非常常见的问题:乱码。
当我们对字节进行编码的时候使用的是一种编码表,而解码的时候使用的是另一种编码表的时候,就会出现乱码的问题了,是因为每一个编码表,它的字符对应二进制的字节是不一致的。
但是互联网是一个互联互通的平台,所以如果每个国家都使用自己的一套编码器,就会出现许多问题。
在 1992 年的时候,推出了 UTF-8 编码规范,是一种针对 Unicode 的可变长度字符编码,又称万国码,UTF-8 用 1 到 6 个字节编码 Unicode 字符。用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。它也是我们目前在应用开发中使用的最多的编码格式。
Reader 类(字符输入流)
Reader 类是 Java 的 IO 库提供的另一个输入流接口。它和 InputStream 类的区别是,InputStream 类是一个字节流,即以 byte 为单位读取,而 Reader 是一个字符流,即以 char 为单位读取。
Reader 类是所有字符输入流的超类,它最重要的方法是 read() 方法,这个方法读取字符流的下一个字符,并返回字符表示的 int 值,范围是 0~65535。如果已读到末尾,返回 -1。
常用子类
以下表中列出了 Reader 类的常用子类。
| 子类名 | 子类说明 |
|---|---|
| FileReader() 类 | 实现了文件字符流输入,使用时需要指定编码 |
| CharArrayReader()类 | 把一个 char[] 数组变成一个字符输入流 |
| StringReader()类 | 把字符串变成一个字符输入流 |
和 InputStream 类类似,Reader 类也是一种资源,需要保证出错的时候也能正确关闭,所以我们需要用 try (resource) 来保证 Reader 类在无论有没有 IO 错误的时候都能够正确地关闭。
我们以 FileReader() 类为例,演示如何完整地读取一个 FileReader 的所有字符:
public static void main(String[] args) throws IOException{// 创建一个FileReader对象:Reader reader = new FileReader("/test/a.txt");for (;;) {// 反复调用read()方法,直到返回-1int n = reader.read();if (n == -1) {break;}// 打印读取到的数据System.out.print((char)n);}// 关闭流reader.close();}
已知/test目录下的a.txt文件中的内容为一个 hello 字符串。 以上程序执行结果为:
hello
和 InputStream 一样,Reader 也是一种资源,需要保证出错的时候也能正确关闭,所以我们需要用 try (resource) 来保证 Reader 在无论有没有 IO 错误的时候都能够正确地关闭:
try (Reader reader = new FileReader("/test/a.txt") {}
Reader 还提供了一次性读取若干字符并填充到 char[] 数组的方法 read(char[] c),它返回实际读入的字符个数,最大不超过 char[] 数组的长度。返回 -1 表示流结束。利用这个方法,我们可以先设置一个缓冲区,然后,每次尽可能地填充缓冲区:
public static void main(String[] args) throws IOException {// 创建 FileReader 对象try (Reader reader = new FileReader("/test/a.txt")) {// 创建缓存字符数组char[] buffer = new char[100];int n;// 打印字符个数while ((n = reader.read(buffer)) != -1) {System.out.print("读到" + n + "个字符");}}}
已知/test目录下的a.txt文件中的内容为一个 hello 字符串。 以上程序执行结果为:
读到5个字符
编程要求
仔细阅读右侧编辑区内给出的代码框架及注释,在 Begin-End 间编写程序代码,使用字符输入流读取给定路径中的文件数据,具体要求如下:
- 接收给定的一行字符串(如:/test/a.txt。代表文件路径);
- 使用字符输入流读取给定路径中的文件内容;
- 输出文件内容。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。
例: 测试输入:
/test1/e.txt
预期输出:
inrggreheput
开始你的任务吧,祝你成功!
import java.io.*;
import java.util.Scanner;
public class FileTest {
public static void main(String[] args) throws IOException {
// 请在Begin-End间编写完整代码
/********** Begin **********/
// 定义变量
Scanner input = new Scanner(System.in);
// 接收给定字符串
String str= input.next();
// 创建Reader对象
Reader reader = new FileReader(str);
// 打印字符
for(;;){
int n = reader.read();
if(n==-1){
break;
}
System.out.print((char)n);
}
// 读取并打印数据
try{
reader.close();
}catch(Exception e){
}
/********** End **********/
}
}