【数据分析师---数据可视化】第一章:Matplotlib绘图
第一章:Matplotlib绘图
- 1 Matplotlib概念与安装
- 2 Matplotlib使用
-
- 2.1 绘制折线图
-
- 2.1.1 最简单的图形
- 2.1.2 添加图形标记
- 2.1.3 设置图形颜色
- 2.1.4 设置图线宽度
- 2.1.5 单独设置图形和标记颜色
- 2.1.6 显示标题
- 2.1.7 同x轴多折线图
- 2.1.8 图形风格
- 2.1.9 格式化样式
- 2.1.10 保存图片
- 2.2 绘制柱状图
-
- 2.2.1 处理绘图数据
- 2.2.2 处理x轴标签过密问题
- 2.2.3 绘制纵向堆叠图
- 2.2.4 绘制横向堆叠图
- 2.3 绘制直方图
-
- 2.3.1 指定分箱数量
- 2.3.2 绘制标注线
- 2.4 绘制堆叠图
-
- 2.4.1 旧知识补充完善
- 2.4.2 新知识拓展延伸
- 2.4.3 堆叠直线图
- 2.5 绘制带有阴影面积的折线图
- 2.6 绘制饼图
-
- 2.6.1 绘制饼图相关参数介绍
- 2.6.2 数据实操
- 2.7 绘制散点图
-
- 2.7.1 绘制散点图相关参数介绍
- 2.7.2 数据实操
- 2.8 时序数据可视化
-
- 2.8.1 字符串时间数据和Datetime时间数据绘图对比
- 2.8.2 动手实操
- 2.9 实时数据可视化
-
- 2.9.1 实时数据绘制的原理以及模块调用
- 2.9.2 动手实操
- 2.10 图表的多重绘制
-
- 2.10.1 通过plt.subplots绘制子图
- 2.10.2 通过fig.add_subplot绘制子图
- 2.10.3 通过plt.subplot2grid绘制子图
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/119253495(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 Matplotlib概念与安装
Matplotlib 图形可视化 Python 包,它提供了一种高度交互式界面,便于大家能够做出多种有吸引力的统计图表;同时,可以使用这些工具创建各种图形:包括简单的散点图、正弦曲线,甚至是三维图形;
在 Python 科学计算社区,经常使用它完成数据可视化的工作;在接下来的梳理,学习一下这个库的神奇功能!
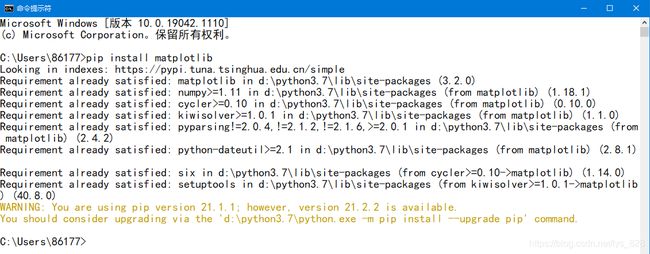
如果使用的是Anaconda环境,在下载软件完毕后,Matplotlib模块也就自动安装在环境中了,如果是本地环境,就需要打开命令行进行安装,操作如下
2 Matplotlib使用
2.1 绘制折线图
核心代码:plt.plot()
2.1.1 最简单的图形
最简单的折线图,只给定x和y的数据,进行图形绘制
from matplotlib import pyplot as plt
x = [0,1,2,3,4,5]
y = [0,1,9,3,4,5]
plt.plot(x,y)
输出结果如下:(没有任何图表修饰元素,仅根据数据出图)

2.1.2 添加图形标记
核心参数:marker/markersize
这两个参数分别控制标记有无(样式)和大小尺寸
#控制标记以.显示
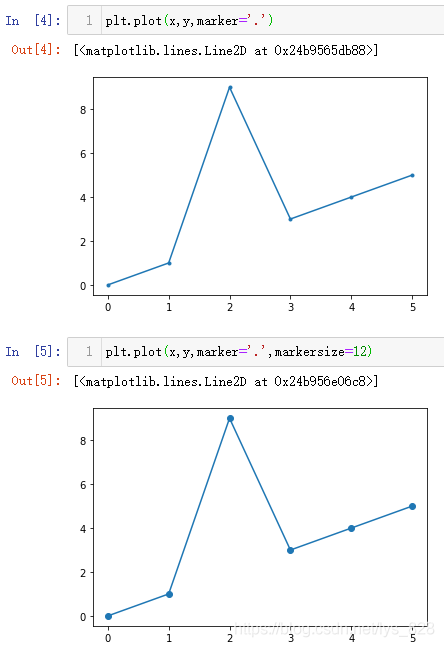
plt.plot(x,y,marker='.')
#控制标记.的显示大小为12
plt.plot(x,y,marker='.',markersize=12)
输出结果如下:(markersize参数使用是在有marker参数的前提下)
关于marker标记的样式,可以直接调出参考文档进行查阅,输出结果如下

比如任意挑里面其中的一个进行绘制,输出结果如下。除了三角形之外,里面的其它参数可以根据自己的需求进行设置

2.1.3 设置图形颜色
核心参数:color
plt.plot(x,y,marker='v',markersize=10,color='g')
输出结果如下:(图线和标记都进行了颜色的改变)

查看说明文档,看一下color参数可以指定哪些颜色,输出如下
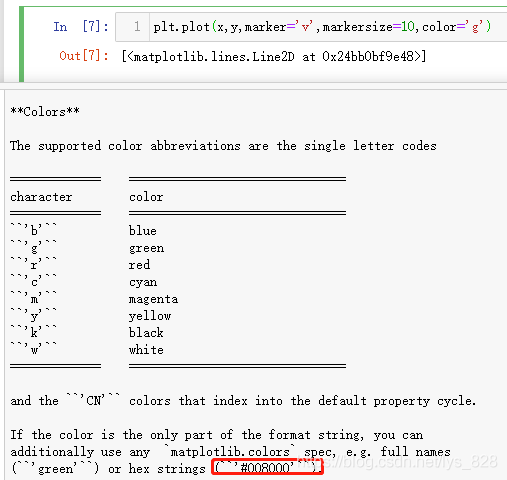
可以发现该参数既可以使用常见颜色的全拼,也可以使用简写,最重要的一个提醒就是上面图片上红框的部分,可以通过指定三原色的方式进行自定义。
关于三方色查找可以直接百度搜索一下,找到一些调色板,也可以直接在网页上按住F12键调出调试界面,然后里面的任何一个包含color参数部分点击一下就会出现调色板,操作如下
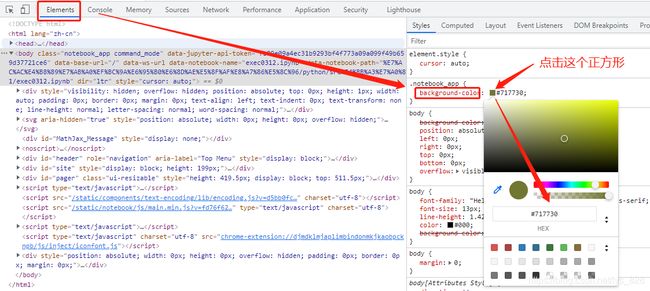
比如就选用上面指定的颜色进行绘制(这样就能自定义指定任何想要的颜色)
2.1.4 设置图线宽度
核心参数:linewidth/lw

这个参数可以使用全拼也可以使用简写,上面颜色参数也可以全拼和简写,如下
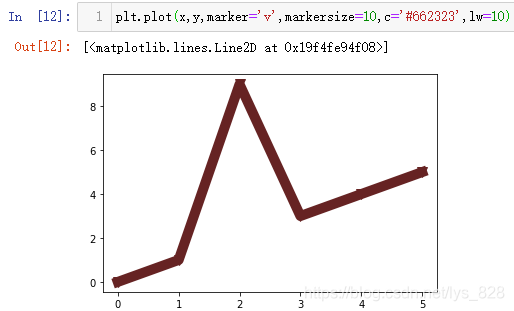
2.1.5 单独设置图形和标记颜色
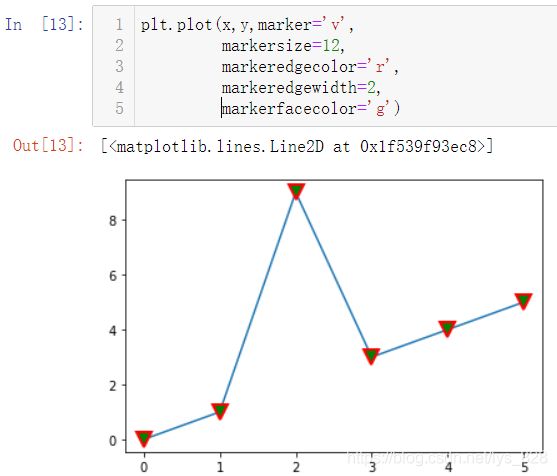
有些时候需要进行图线颜色和标记颜色的单独设置,就需要用上另外几个参数,markeredgecolor(标记边缘颜色)、markeredgewidth(标记边缘宽度)、markerfacecolor(标记填充颜色)
2.1.6 显示标题
核心代码:
- 显示x轴标题:
plt.xlabel() - 显示y轴标题:
plt.ylabel() - 显示图像标题:
plt.title() - 设置中文字体显示:
plt.rcParams['font.sans-serif']=['SimHei']
plt.plot(x,y,marker='.',markersize=15,color='g',
lw=4,markeredgecolor='r' ,
mew=2,
markerfacecolor='b')
plt.rcParams['font.sans-serif']=['SimHei']
plt.xlabel("x轴数据")
plt.ylabel("y轴数据")
plt.title("这张图的内容介绍")
输出结果如下:

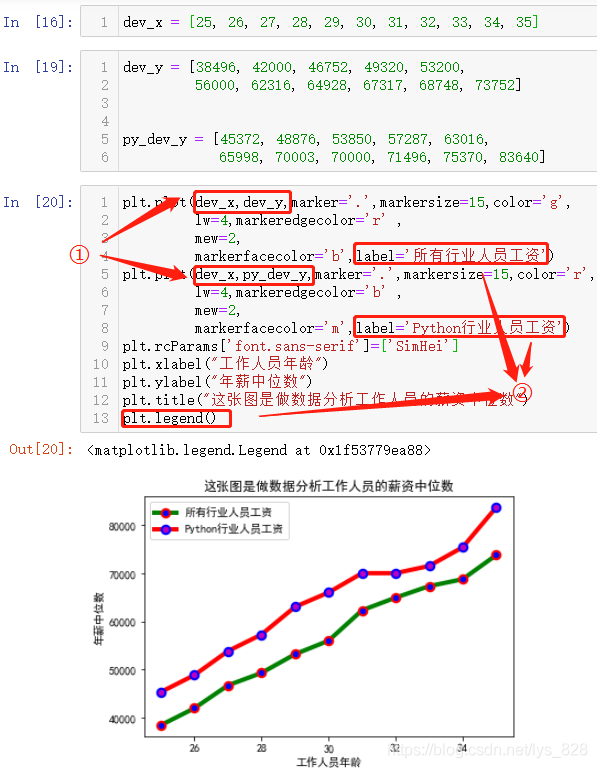
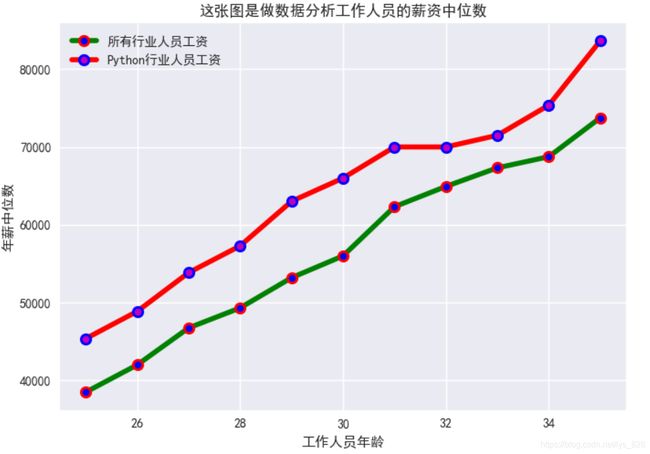
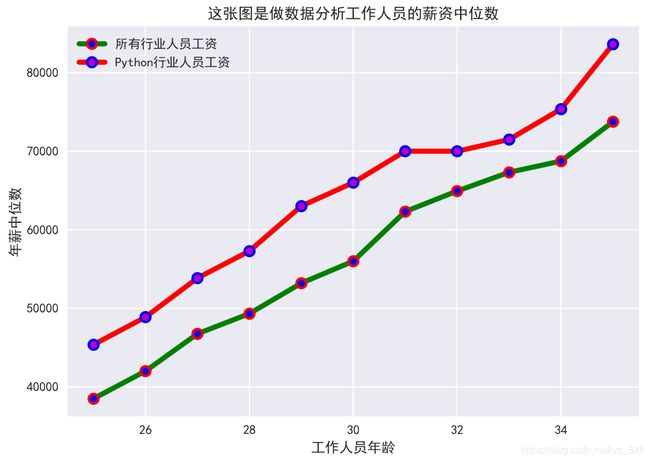
2.1.7 同x轴多折线图
就是使用同一个x轴,然后根据指定的多份数据进行绘制多个y值,测试数据和执行代码如下
#x数据
dev_x = [25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35]
#y1数据
dev_y = [38496, 42000, 46752, 49320, 53200,
56000, 62316, 64928, 67317, 68748, 73752]
#y2数据
py_dev_y = [45372, 48876, 53850, 57287, 63016,
65998, 70003, 70000, 71496, 75370, 83640]
plt.plot(dev_x,dev_y,marker='.',markersize=15,color='g',
lw=4,markeredgecolor='r' ,
mew=2,
markerfacecolor='b',label='所有行业人员工资')
plt.plot(dev_x,py_dev_y,marker='.',markersize=15,color='r',
lw=4,markeredgecolor='b' ,
mew=2,
markerfacecolor='m',label='Python行业人员工资')
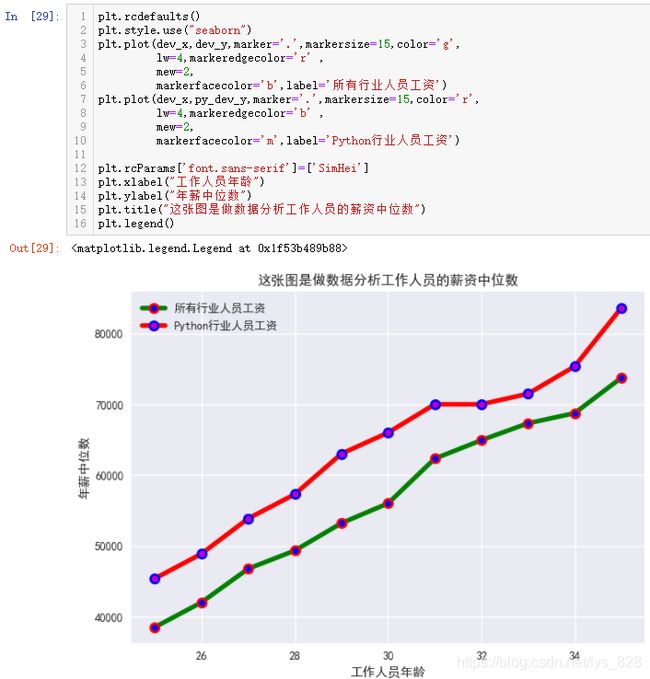
plt.rcParams['font.sans-serif']=['SimHei']
plt.xlabel("工作人员年龄")
plt.ylabel("年薪中位数")
plt.title("这张图是做数据分析工作人员的薪资中位数")
plt.legend()
输出结果如下:(注意①部分就是显示同轴多折线绘制,就是针对同一个x数据,给定y不同,然后②部分,就是绘制出的多个图形要进行分辨, 这时候可以通过给每个图形指定label,最后需要配合plt.legend(),标签就显示出来了)
2.1.8 图形风格
上面的图形都是使用空白的画布进行绘制,其实也可以直接加载预设画布和风格类型,具体可以使用的风格样式可以通过plt.style.available查看,一共有26款样式,输出如下

比如随便指定一个样式,具体的代码指令为:plt.style.use("fivethirtyeight"),放置在绘制图形的最开始的第一行
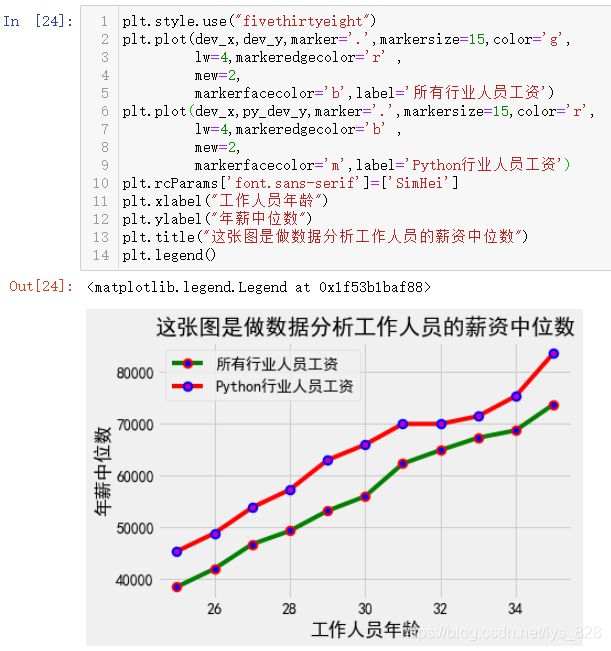
对于内置的风格可以根据自己的需求进行切换,此外还有一种Q版卡通的绘图风格是直接封装为函数,执行代码为:plt.xkcd(),输出结果如下(这种风格需要出现的字都为英文,中文会出现找不到对应字体的提醒)

还需要注意到一点就是在同一个notebook中执行时候,当指定一个主题后,后面的所有绘图样式都会是同一个主题,如果不需要这个主题,重新设置主题,可以使用执行代码:plt.rcdefaults(),也是在绘图代码的第一行添加,输出结果如下
2.1.9 格式化样式
除了前面的具体参数的设置以及预置的各种风格样式,matplotlib中还有一个fmt格式化样式,先给出一个简单的示例如下
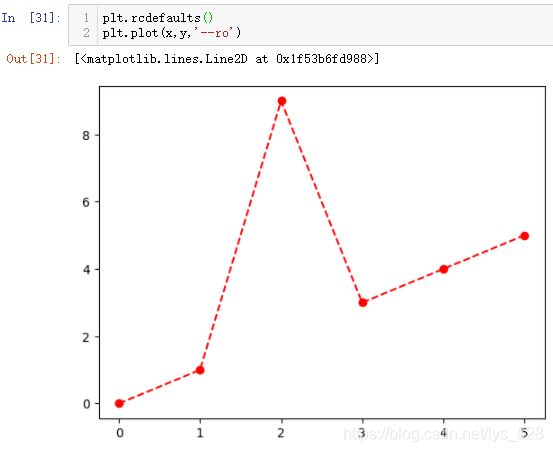
具体使用方式就是第三个参数进行位置传参,详细的使用方式可以参照一下说明文档,如下(可以指定标记、线的样式和颜色)
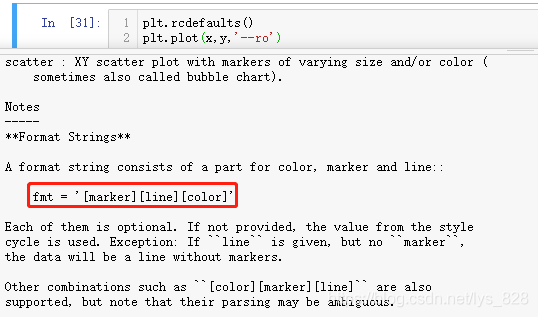
这种方式可以简单快捷出图,如果是要进行图表详细化的设置,比如粗细,各组样式的设置等,还是要使用到具体的参数赋值,因此上面总共有三种关于样式设置的方式,根据实际需求进行选择即可
2.1.10 保存图片
核心代码:plt.savefig()
这个代码需要放置在绘图区的最后一行中,输出如下
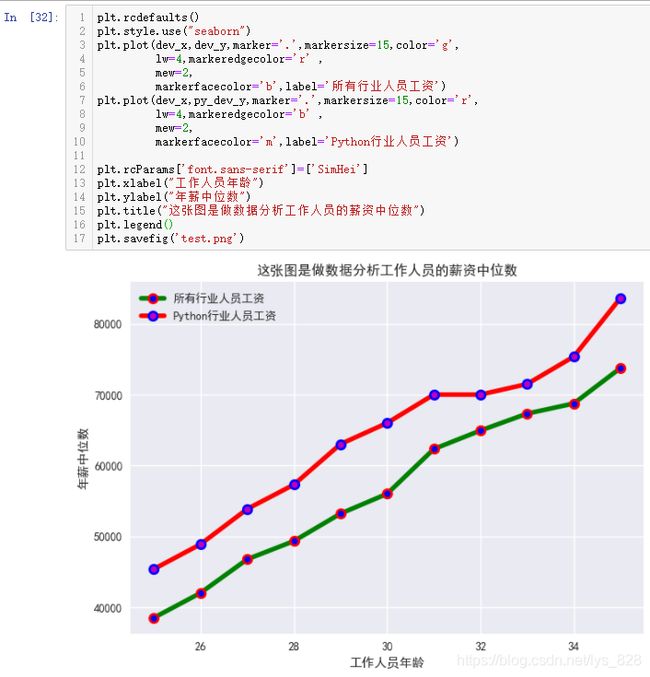
此外有一个很重要的参数就是dpi,如果直接默认输出,最终的图片的分辨率很很差,放大后会看的不是很清楚,还有出现模糊的现象,通过指定dpi,就可以使得图片的分辨率提升,比如论文中常见的要求dpi=600,下面就对比默认输出的图形和指定dpi=600后的图像在同一比例下的结果
默认的输出:
dpi=600的输出结果:(两者的结果在生成完毕后自己打开后就会有明显感觉到清晰与模糊的对比)
2.2 绘制柱状图
这里不对条状图和柱状图进行细分,默认这个两个图形就是一个类型的图像。条形图:条形图用长条形表示每一个类别(类别数据),长条形的长度表示类别的频数,宽度表示类别
核心代码:plt.bar()/plt.barh()
2.2.1 处理绘图数据
假定测试数据是Github上面的项目仓库中每个项目所使用到的编程语言,读取的数据内容如下(第一列就是对应的项目编号,第二列就是项目中使用到的语言,使用ggplot的绘图风格)

然后我们的目的就是对第二列中的编程语言进行计数,并绘制条形图,故首先要解决的问题就是对编程语言这一列进行计数,计数之前进行一个简单的测试示例,方便更好的理解
list1 = [1,1,1,2,2,3,1]
#导入计数器函数
from collections import Counter
#添加计数器
cnt = Counter()
#遍历循环每一个数据
for i in list1:
#更新计数器
cnt.update(str(i))
输出结果为:(计数的操作共分为四步,见上面的代码解析,最后生成的数据,就是输出每一个元素以及对应的计数结果)

那么就可以直接是将此方法应用到第二列计数中,需要注意Counter应该重置计数(也就是重新进行赋值)
cnt = Counter()
lang = data.LanguagesWorkedWith
for i in lang[:]:
# print (i.split(';'))
cnt.update(i.split(';'))
cnt
输出结果为:(只截取部分输出结果)

接着就是获取计数结果中的键和对应的值分别组成x和对应的y,Counter中有一个函数可以获得前十名的计数内容:most_common(10),括号中的数值可以自行指定
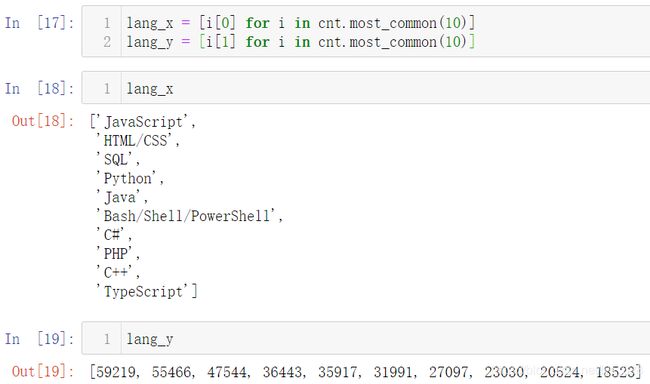
至此绘制图形需要的x和y的数据就准备完毕,绘图如下
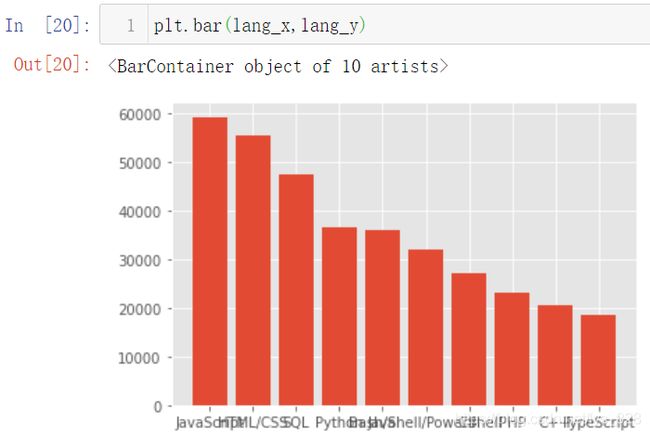
2.2.2 处理x轴标签过密问题
针对上面的输出结果,显然最终x轴的标签信息过于密集,显示效果不佳,这时候有三种解决方式,第一种是比较常见的方式:进行画布调大;第二种方式:进行xy轴交换;第二种就是对x轴标签信息进行旋转
(1)第一种方式
核心代码:plt.figure(figsize=(12,10)),括号中两个参数代表图表的长和宽

(2)第二种方式
核心代码:plt.barh(lang_x,lang_y),注意这里是barh,上面是bar。方法一可以看出有时候是可以解决标签信息过密的情况,但是这里中间有一个标签信息,即便是扩大了画布还是会存在遮挡的现象,所以可以尝试一下第二种方式,输出结果如下(此时最长的那个标签信息就不会被折叠了)
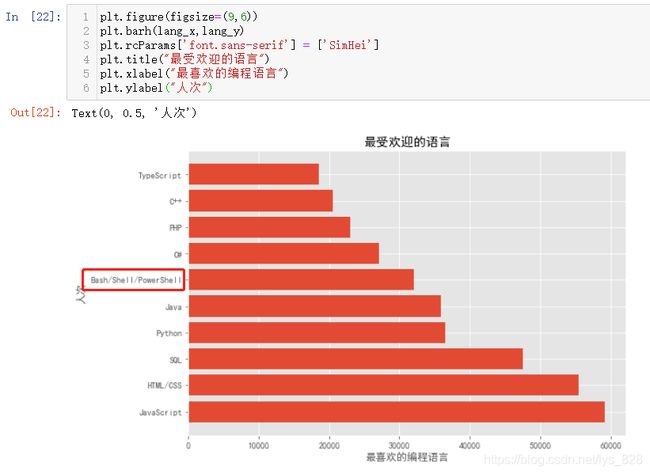
上面的图片如果进行反向的排序直接对x和y求反序就可以了,因为是列表数据,该数据类型有个reverse()函数,就可以实现,最终输出的结果如下(顺带把前面没有修改的x和y标题整改过来)

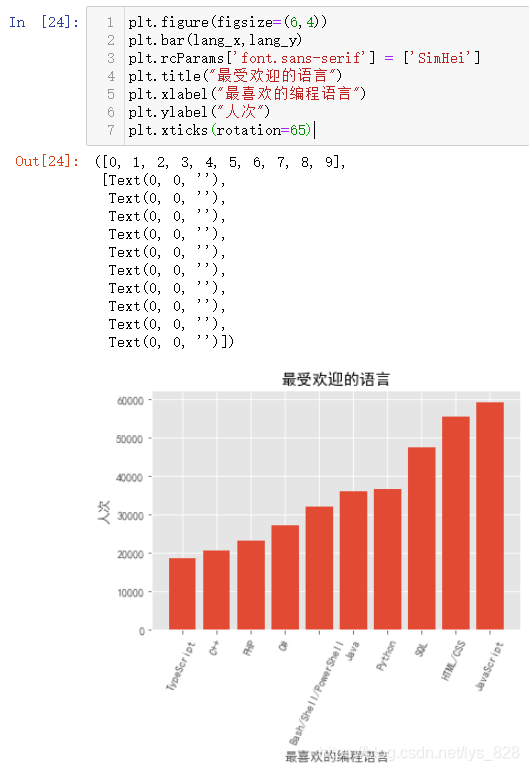
(3)第三种方式
核心代码:plt.xticks(rotation=65)
如果一定要坚定使用纵向条状图,就可以采用旋转x轴标签信息的方式完成
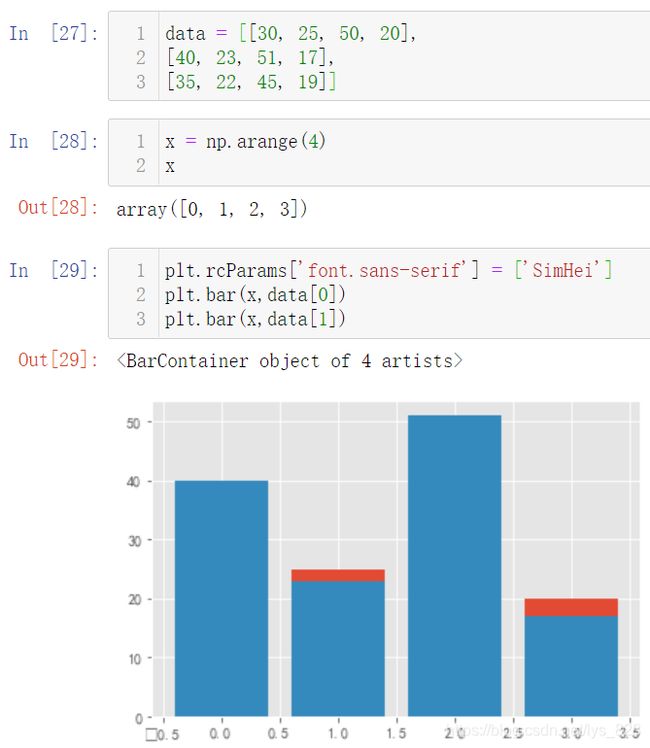
2.2.3 绘制纵向堆叠图
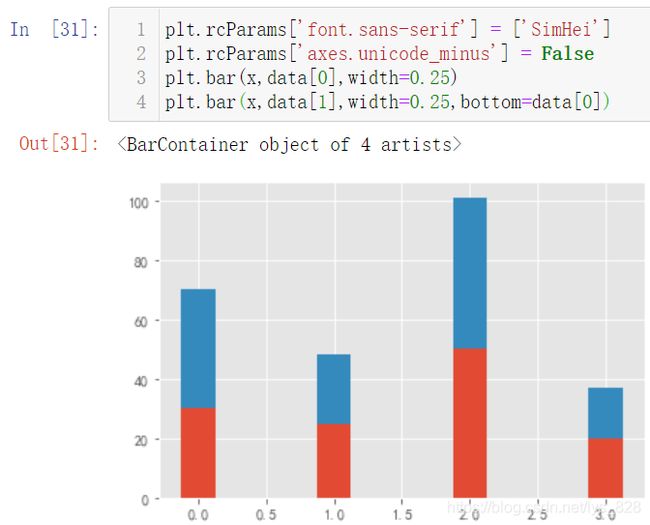
如果直接和绘制折线图一样,将两个条形图绘制在一个图中看一下输出结果(两个图形直接进行重叠了,但并不是堆叠,没有达到我们想要的结果,而且发现符负号没有办法正常显示)
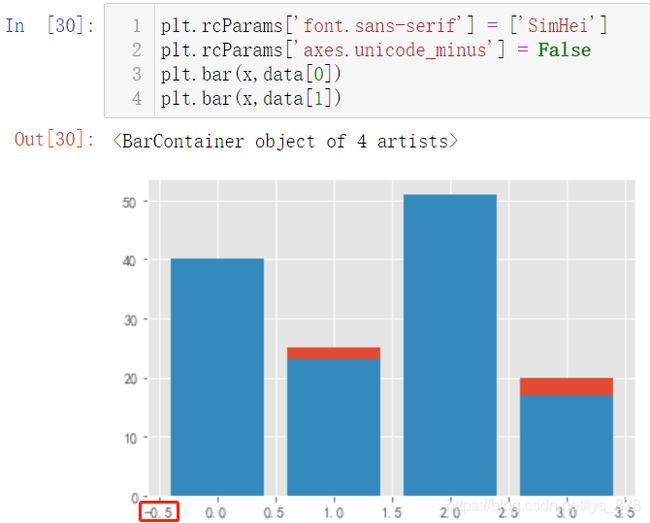
首先解决负号的问题:plt.rcParams['axes.unicode_minus'] = False,此外也可以彻底解决关于中文编码和符号显示的问题,可以参考这个梳理:Matplotlib库运行前系统参数设置(中文及负号不显示、网格线及透明度、刻度显示)
其次解决重叠的问题,其实就是要求第二个绘制的图形是基于第一个图形基础之上,核心参数:bottom=data[0],还可以配合着width参数进行各条状图间隔的设置
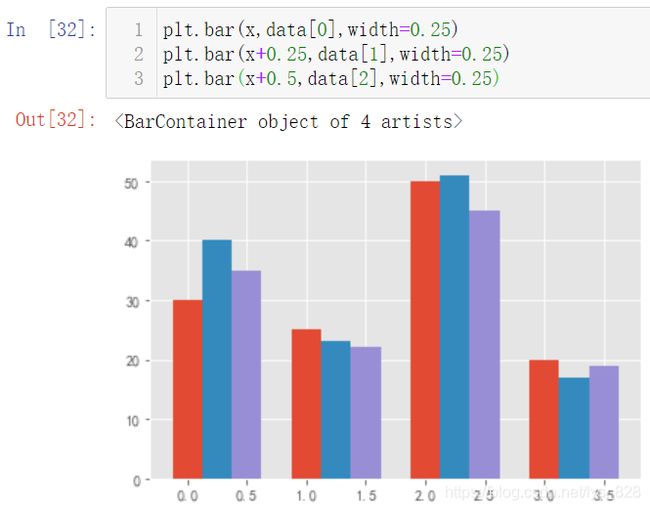
2.2.4 绘制横向堆叠图
这里就要用到上面的width参数,此外还要搭配着x参数的偏移量进行,且偏移量要和width成比例,输出结果如下
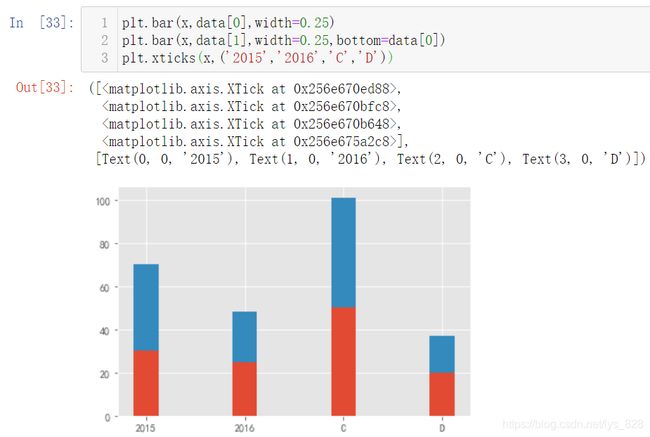
接下来就是小修,进行x轴标签信息的指定还有就是每个颜色代表的图例信息
先解决x轴标签信息,核心代码:plt.xticks(x,('2015','2016','C','D')),就是把你要显示的刻度放置于后一个括号中,输出结果如下
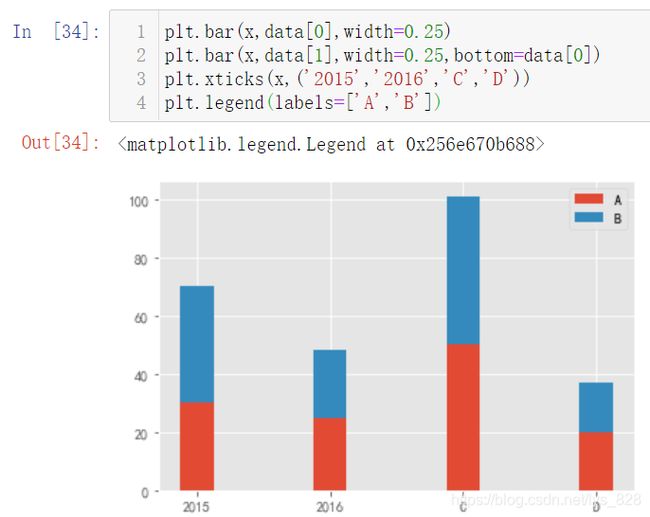
然后解决图例的问题,可以和之前一样在绘制图形的时候指定label参数,也可以选择在plt.legend()函数中直接指定
2.3 绘制直方图
核心代码:plt.hist()
直方图是一种统计报告图(针对连续数据),形式上也是一个个的长条形,但是直方图用长条形的面积表示频数;所以,长条形的高度表示频数组距,宽度表示组距,其长度和宽度均有意义
2.3.1 指定分箱数量
先导入三剑客(pandas,numpy和matplotlib),然后假定测试数据如下
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
ages = [18,19,21,25,26,26,30,32,38,45,55]
bins = [20,30,40,50,60]
plt.hist(ages)
输出结果为:(虽然有bins赋值变量,但是在绘制直方图时没有传递该参数,系统会按照默认分组进行绘制)

然后按照指定的分组进行绘制,并设置一下边缘的分割线(输出结果中就按照想要的分组进行)

2.3.2 绘制标注线
除了简单的进行测试数据的绘图外,还可以直接导入Csv文件中的数据,进行绘制,操作如下(其实只需要把要绘制的那一列做为变量传递到一个参数位置上即可)

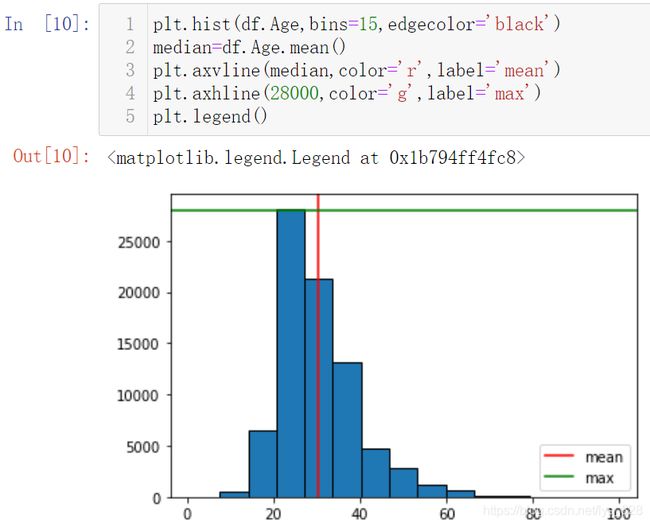
有时候需要在图形上添加一些辅助线,比如要知道最大值和中位数在什么位置等,需要用到的代码指令为:
- 纵向:
plt.axvline(median,color='r',label='mean') - 横向:
plt.axhline(28000,color='g',label='max')
2.4 绘制堆叠图
核心代码:df.plot(kind='bar',stacked=True)
前面简单的介绍了条状图的堆叠图绘制,其实者折线图也可以进行堆叠,接下来比较详细的介绍堆叠图的绘制
2.4.1 旧知识补充完善
首先导入模块进行测试数据准备
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#使用一个样式
plt.style.use('fivethirtyeight')
#一个x,三个y数据
minutes = [1, 2, 3, 4, 5, 6, 7, 8, 9]
player1 = [1, 2, 3, 3, 4, 4, 4, 4, 5]
player2 = [1, 1, 1, 1, 2, 2, 2, 3, 4]
player3 = [1, 5, 6, 2, 2, 2, 3, 3, 3]
输出结果如下:
为了方便x轴位置的计算,所以要将列表数据转化为array数据类型,方便加减,并指定每个条形状的偏移量

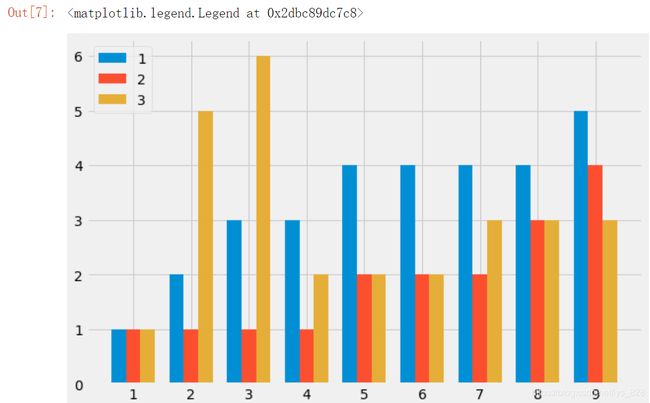
最后就是绘制堆叠条形图,先绘制横向堆叠图,代码如下
plt.figure(figsize=(9,6))
plt.bar(index_x-w,player1,width=w)
plt.bar(index_x,player2,width=w)
plt.bar(index_x+w,player3,width=w)
plt.xticks(list(range(1,10)))
plt.legend(labels=['1','2','3'])
输出结果如下:(中间的一个数据就是为原本的x轴数据,前后两个就是进行减加偏移量,最后添加指定表x标签和对应图例标签)
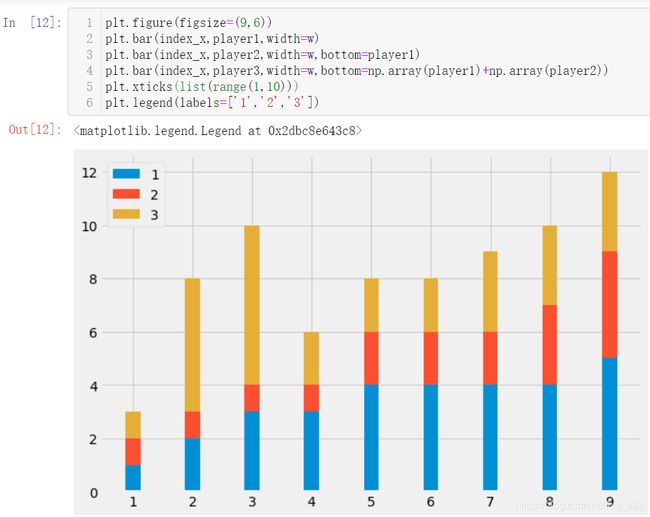
接着绘制纵向堆叠图,这里面有一个小坑,就是bottom参数不能直接进行简单的player1+player2

原因在于两个列表相加,最后的结果是以元素追加的形式形成新列表,而不是两两对应位置相加,处理的方式和前面x轴数据处理的一样转化为array数据类型即可,测试结果如下

最后就是可以完美绘制纵向堆叠条形图
2.4.2 新知识拓展延伸
接下来就不是直接使用matplotlib中的plt绘制图形,而是直接使用DataFrame的绘图接口进行绘制,构造测试数据如下
df = pd.DataFrame([['A', 10, 20, 10, 26], ['B', 20, 25, 15, 21], ['C', 12, 15, 19, 6],
['D', 10, 18, 11, 19]],
columns=['Team', 'Round 1', 'Round 2', 'Round 3', 'Round 4'])
df
输出结果为:

然后绘制堆叠条状图就是一行代码即可,首先绘制横向堆叠条状图,核心代码:df.plot(x='Team',kind='bar')

再绘制纵向堆叠条状图,核心代码:df.plot(x='Team',kind='bar',stacked=True)
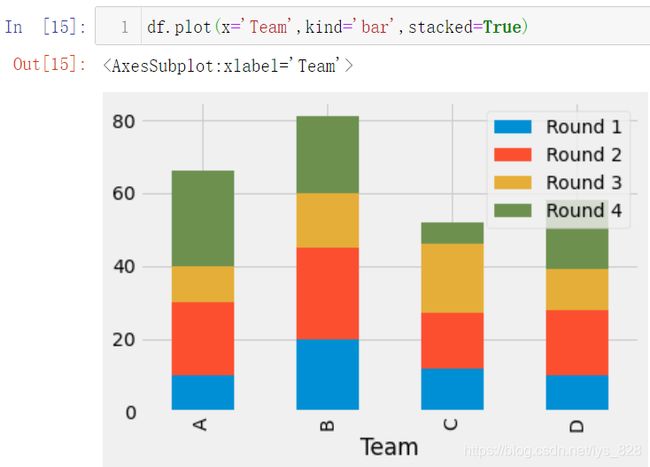
可以发现直接通过DataFrame绘制堆叠图超级简单,省去了好多一点点计算的操作,一步到位
2.4.3 堆叠直线图
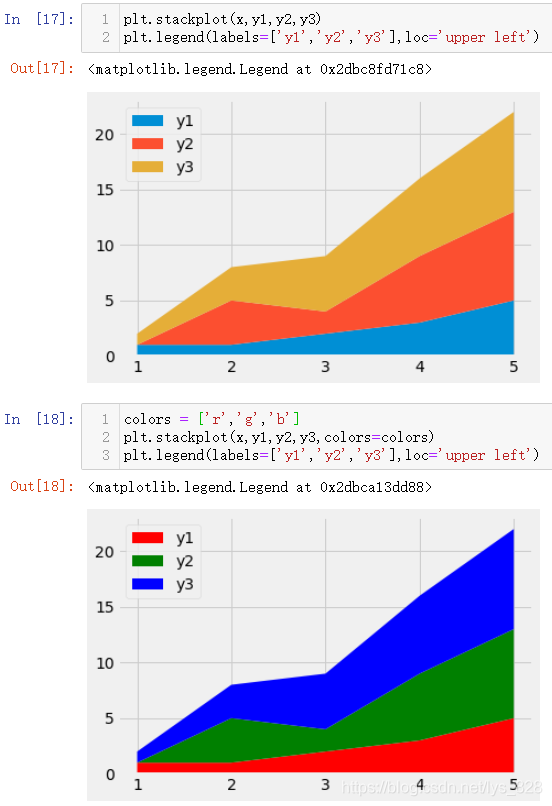
除了条状图,折线图照样可以进行堆叠,这种堆叠往往就变成了面积图,每个折线之间围成的区域就是表示彼此间相差的体量,核心代码:plt.stackplot(x,y1,y2,y3)
测试数据如下
x = [1, 2, 3, 4, 5]
y1 = [1, 1, 2, 3, 5]
y2 = [0, 4, 2, 6, 8]
y3 = [1, 3, 5, 7, 9]
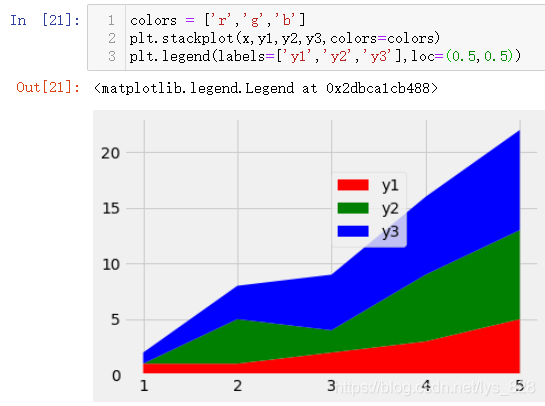
绘制堆叠图和自定义颜色操作,最终结果如下(可以通过loc参数指定显示图例的位置,可以通过字符串指定也可以通过坐标指定,具体的可以查看一下说明手册)
loc参数可以取得字符串对应的位置如下

此外使用坐标进行图例的位置放置如下(这种基本上就是在指定上面字符串对应的位置不满意的基础上进行位置的微调)
如果需要更进一步了解百分比堆叠条状图的绘制,梳理内容可以进行参考:封装接口直接利用DataFrame绘制百分比堆叠条状图
2.5 绘制带有阴影面积的折线图
核心代码:plt.fill_between()
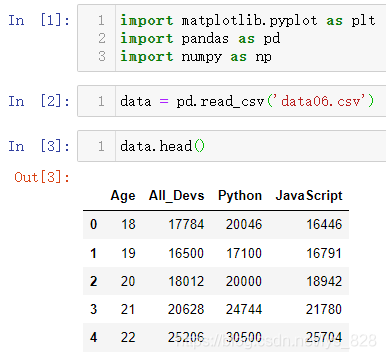
导入三剑客模块和测试数据
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_csv('data06.csv')
data.head()
输出结果如下:(如果文件读取失败,记得把光标移动至最后一行,按一下退格键回到有数据的一行保存后再读取)
简单地绘制出所有的行业薪资和python薪资的情况
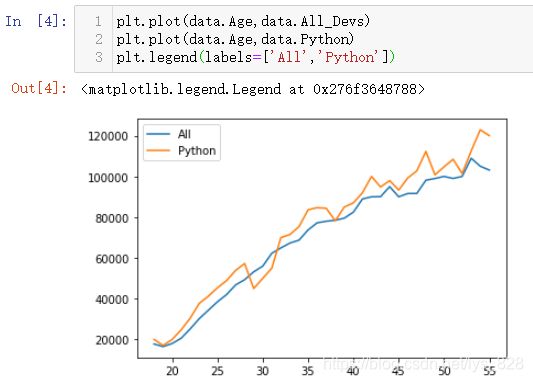
我们目标就是实现标注出大于所有的行业薪资和小于python薪资的部分,并且以不同的颜色进行表示,那么就看一下fill_between()直接使用会有什么效果,比如指定x为年龄,y1为所有的行业薪资

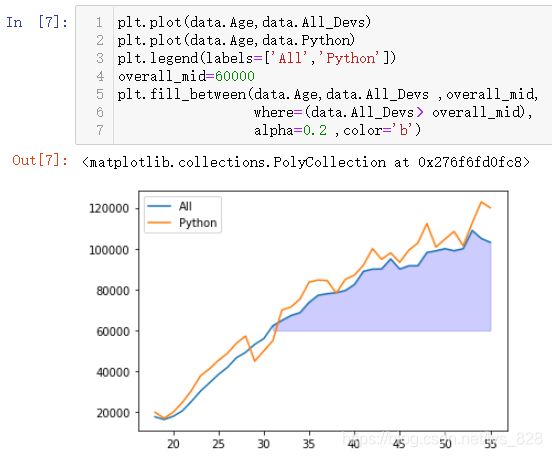
函数中还有y2参数和where参数进行对比的限定,比如y2指定一个固定值,然后where就是指定与这个固定值的对比如下(最后一行添加了两个显示透明度alpha和颜色的参数)
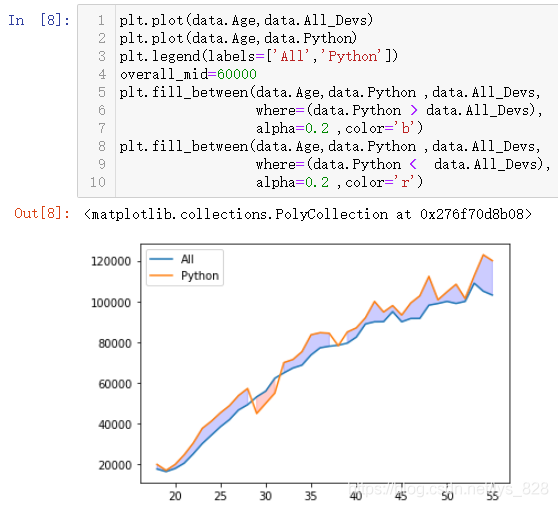
由此就有了启发,既然是以python的薪资和全行业的薪资作为标准,那么y1就是python的薪资,y2就是全行业的薪资,在进行where对比时候只能选取一侧,故可以进行两次函数的调用,这样就能实现最初的目的
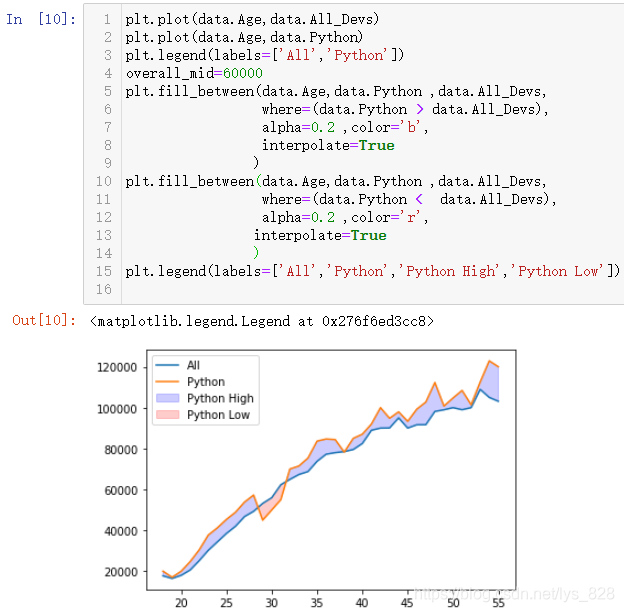
从上图中可以看出交叉的部分区域存在着空白,因为这部分数据缺失导致,那么也可以通过interpolate拟合差值进行填充,具体实现就是指定interpolate=True,输出结果如下(完美解决问题)
2.6 绘制饼图
核心代码:plt.pie()
2.6.1 绘制饼图相关参数介绍
导入三剑客模块以及测试使用的数据

绘制最简单的饼图,直接使用:plt.pie(list2),其中list2就是要进行绘图的数值数据,输出结果如下(图像上面的文字输出部分就是绘制的这个图对应的信息,包含了图形的边界和各个部分的扇形组块)
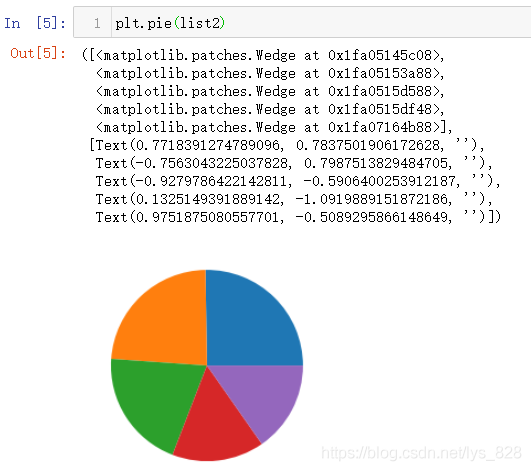
函数中常用的参数如下:
- 标签:
labels - 部分突出:
explode - 阴影:
shadow - 数据标注:
autopct - 起始角度:
startangle - 边缘设置:
wedgeprops
explo=[0,0,0,0.2,0]
plt.pie(list2,labels=list1,explode=explo,
shadow=True,
autopct='%1.2f%%' ,
startangle=190,
wedgeprops={'edgecolor':'black'}
)
输出结果如下:(关于labels参数就是指定数值对应的标签信息;explode参数是以列表形式给出,列表元素的个数要和绘制的标签的数量一致,默认值为0时,该标签代表的扇形不突出,大于0时显示突出,为了美观的效果这个突出值一般不要太大;shadow参数就是给饼图增加一个阴影效果,让图形看上去更立体;autopct参数是给图形加上文字标注,显示百分比的形式,使用时候就按照下面的书写就可,然后保留的位数修改.和f之间的数值即可;startangle参数表示调整图形的位置,为了美观可以进行旋转角度;wedgeprops参数设置边缘属性,除了边缘颜色外还可以设置粗细,也是通过字典的方式传入参数)

2.6.2 数据实操
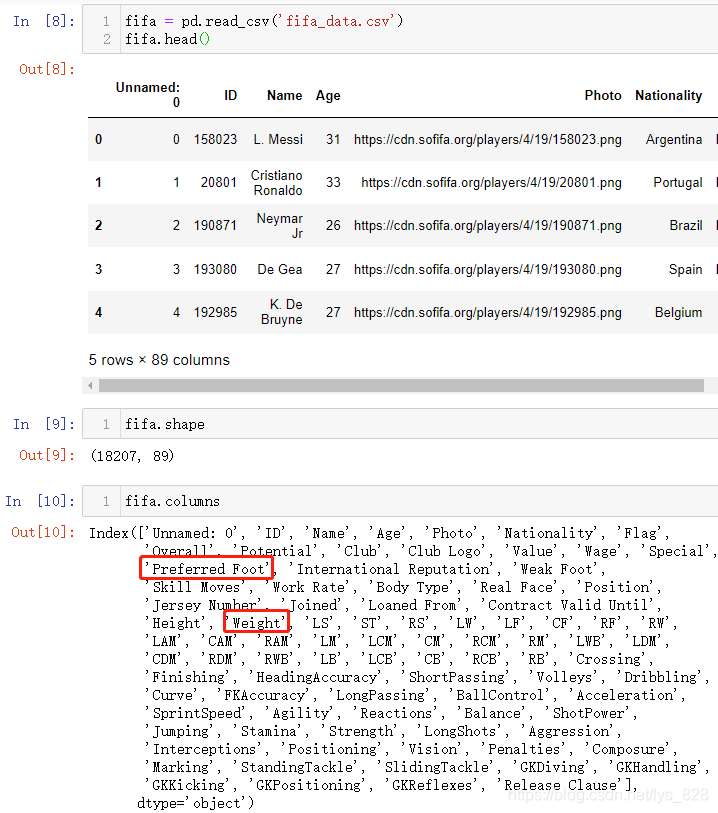
测试数据为足球场上的球员踢球的信息统计,加载数据如下(数据量总共有18207条,89个字段,但是我们需要就是下面红框标出的字段:球员踢球偏向使用哪一只脚以及球员的体重字段)
首先绘制一个简单点图形,就是对球员踢球使用哪只脚的偏好进行统计占比绘制饼图,统计分类数据的数量使用代码:fifa['Preferred Foot'].value_counts(),输出如下(对某一字段中出现的类别进行统计,就是统一的标准DataFrame['字段名'].value_counts())

有了数据后就可以直接进行绘制了,先进行数值和标签的赋值,然后把上面绘制饼图的代码复制粘贴一下,修改部分内容即可
labels = fifa['Preferred Foot'].value_counts().index.tolist()
labels
values = fifa['Preferred Foot'].value_counts().values.tolist()
values
explo=[0.08,0]
plt.pie(values,labels=labels,explode=explo,
shadow=True,
autopct='%1.2f%%',
startangle=0,
wedgeprops={'edgecolor':'black'}
)
plt.title("Fifa Pie chart")
plt.tight_layout()
输出结果如下:(分类计数统计之后,对应的数据类型为Series,可以通过index获取第一列标签数据,values获取第二列数值数据,然后tolist()就数据生成为列表数据,最后可以添加饼图的标题和设置紧凑布局)

第一个简单的实操饼图完成了,接下来就是一个稍微复杂一点的球员体重的饼图绘制,首先看一下该字段的内容情况,如下(由于数据量较大,这里只显示前10条,可以发现基本上每条数据后面都有lbs的后缀)
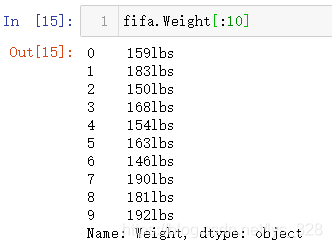
需要处理一下这个后缀,不过这里不需要验证是不是每条数据后面都有lbs,因为使用的处理方式是直接将lbs替换为空,如果有的数据中没有lbs,也就不需要替换,示例代码指令:float('159lbs'.replace('lbs',''))。应用在全部的字段数据中,操作如下
def func1(f):
if type(f)==str:
return float(f.replace('lbs',''))
fifa.Weight = fifa.Weight.apply(func1)
输出结果为:(对比上方查看的前10条数据以及输出的dtype数据类型,可以核实后缀已经替换完毕,且数据类型也变成了float)

之前绘制的饼图使用的是分类标签数据,这里的数据是数值型连续数据,要想绘制饼图就需要先进行数据分箱操作(也就是按照体重范围进行分组,分组的操作也就是之前的pandas中介绍的索引取值),假定分组范围:[125,125-150,150-175,175-200,200],然后得到对应每个区间的计数和对应的标签labels
有了数据和标签就可以完成饼图的绘制,还是复制粘贴代码,修改一下里面的部分变量即可,输出的饼图如下
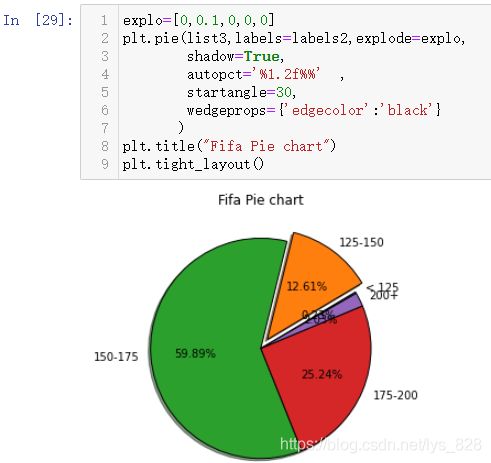
此外也可以使用前面保存图片的方法,将生成的图形保存在本地
2.7 绘制散点图
核心代码:plt.scatter()
2.7.1 绘制散点图相关参数介绍
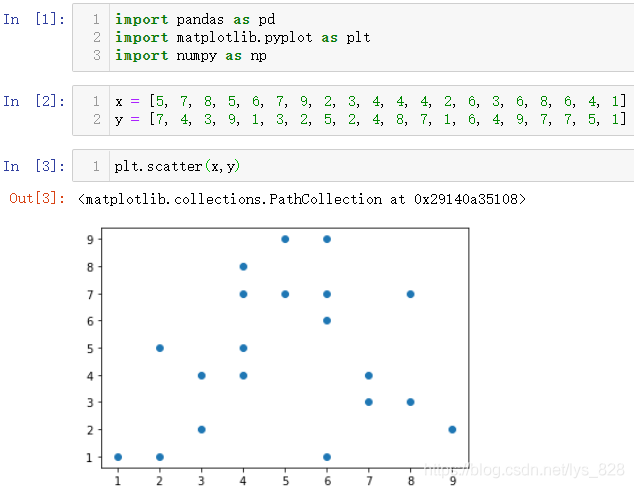
导入模块和相关的测试数据,并绘制最简单的散点图
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
x = [5, 7, 8, 5, 6, 7, 9, 2, 3, 4, 4, 4, 2, 6, 3, 6, 8, 6, 4, 1]
y = [7, 4, 3, 9, 1, 3, 2, 5, 2, 4, 8, 7, 1, 6, 4, 9, 7, 7, 5, 1]
plt.scatter(x,y)
输出结果如下:
散点图中的常用的参数如下:
- 设置散点大小:
s - 设置散点颜色:
c - 设置散点边缘颜色:
edgecolor - 设置散点边缘线宽:
linewidth - 设置散点透明度:
alpha - 设置散点色谱图:
cmap
比如绘制带有黑色边缘,线宽为1的红色透明度为0.7大小为100的散点图(并开启网格线:plt.grid())
plt.scatter(x,y,s=100,c='red',edgecolor='black',linewidth=1,alpha=0.7)
plt.grid()
输出结果如下:

此外c和s两个参数可以使用列表的方式进行传参,最后输出的颜色和大小就会根据列表中的数值进行变化,常常用于绘制分类散点图,如下
x = [5, 7, 8, 5, 6, 7, 9, 2, 3, 4, 4, 4, 2, 6, 3, 6, 8, 6, 4, 1]
y = [7, 4, 3, 9, 1, 3, 2, 5, 2, 4, 8, 7, 1, 6, 4, 9, 7, 7, 5, 1]
colors = [1, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2, 2, 1]
sizes = [209, 486, 381, 255, 191, 315, 185, 228, 174,
538, 239, 394, 399, 153, 273, 293, 436, 501, 397, 539]
plt.scatter(x,y,s=sizes,c=colors,edgecolor='black',linewidth=1,alpha=0.95)
plt.grid()
plt.legend(labels = ['1','2'])
输出结果如下:(注意最后一行代码,按照之前学过的内容对分类数据添加标签,最终输出的结果中并不没有显示出想要的样式)

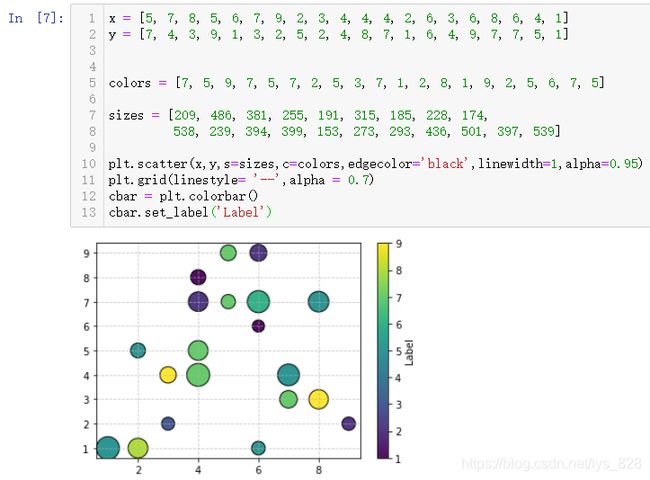
如何显示出不同颜色代表的意义,上面代码的最后一句无效了,就需要另外的方式进行,解决问题的方式就是添加颜色条,代码指令为:cbar = plt.colorbar()
x = [5, 7, 8, 5, 6, 7, 9, 2, 3, 4, 4, 4, 2, 6, 3, 6, 8, 6, 4, 1]
y = [7, 4, 3, 9, 1, 3, 2, 5, 2, 4, 8, 7, 1, 6, 4, 9, 7, 7, 5, 1]
colors = [7, 5, 9, 7, 5, 7, 2, 5, 3, 7, 1, 2, 8, 1, 9, 2, 5, 6, 7, 5]
sizes = [209, 486, 381, 255, 191, 315, 185, 228, 174,
538, 239, 394, 399, 153, 273, 293, 436, 501, 397, 539]
plt.scatter(x,y,s=sizes,c=colors,edgecolor='black',linewidth=1,alpha=0.95)
plt.grid(linestyle= '--',alpha = 0.7)
cbar = plt.colorbar()
cbar.set_label('Label')
输出结果如下:(对于网格线,其中也有很多的使用参数,比如这里显示虚线,同时也有透明度的设置,对于颜色条也是如此,实例化之后也有很多的函数可以使用,比如添加标签)
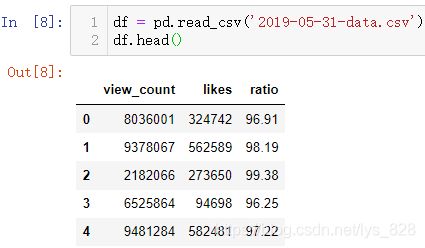
2.7.2 数据实操
测试数据为影片的观看数量以及点赞数量信息,有三个字段,读取数据如下
简单绘制散点图,将观看数量以及点赞数量传入绘制图形如下(这里x和y的指定,直接将要绘制的字段放在对应的位置上即可)
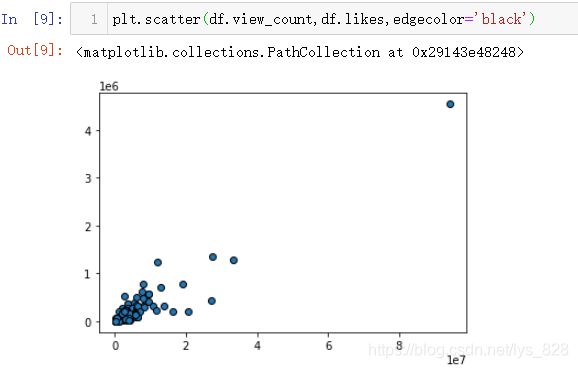
对于此类数据量的量级很大的情况(比如最后x轴的坐标都到了10的7次方),可以采用对数转化,将x轴的数据转化为对数表示,代码指令:plt.xscale('log'),plt.yscale('log')
plt.figure(figsize=(10,6))
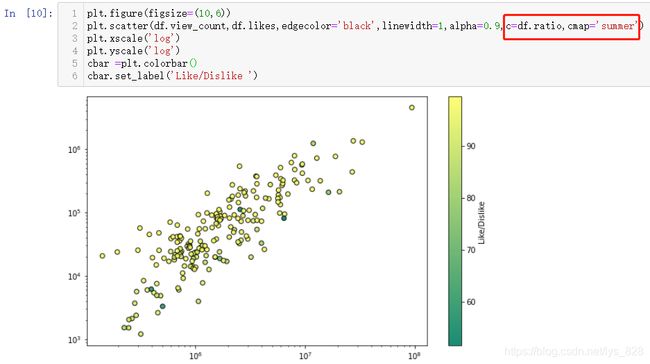
plt.scatter(df.view_count,df.likes,edgecolor='black',linewidth=1,alpha=0.9,c=df.ratio,cmap='summer')
plt.xscale('log')
plt.yscale('log')
cbar =plt.colorbar()
cbar.set_label('Like/Dislike ')
输出结果如下:(直接指定c颜色,颜色的显示会和字段中的取值有很强的关联,如果字段中的数值极差较大,最后的颜色的对比差别也会很大,为了让图形显示一个较为和谐的色调,可以调用cmap参数进行调整)
2.8 时序数据可视化
2.8.1 字符串时间数据和Datetime时间数据绘图对比
如果表示时间的数据做为x轴信息,时间数据的类型会影响最终的作图展示,具体可以分为没有处理的字符串数据类型的时间数据和转化后的Datetime时间类型数据。首先先看一下字符串数据类型的时间直接作为x轴信息,导入第三方库和测试数据,简单绘制折线图
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime,timedelta
from matplotlib import dates as mpl_dates
x = ['2019-5-24','2019-5-25','2019-5-26','2019-5-27','2019-5-28','2019-5-29','2019-5-30','2019-6-30']
y = [0,1,3,4,6,5,7,3]
plt.figure(figsize=(9,6))
plt.plot(x,y)
输出结果如下:(测试结果中最后两个时间字符串是相邻显示)

如果将字符串时间类型数据转化为Datetime数据类型,再进行绘制,对比输出结果如下:(期间省略的日期时间也会被显示出来,时期连续)
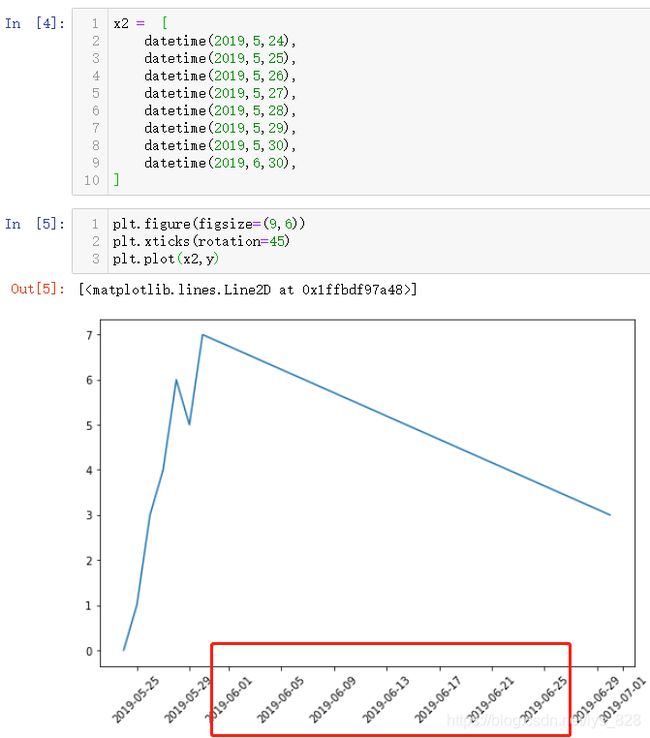
对比字符串时间数据和Datetime时间数据作为x轴绘制图形,可以发现前者只是将时间作为一个样例,忽略了时间的连续性,而后者证实体现了时间连续性,在绘制图形上没有忽略中间缺失的时间
2.8.2 动手实操
测试数据为某一股票数据,读取结果如下:
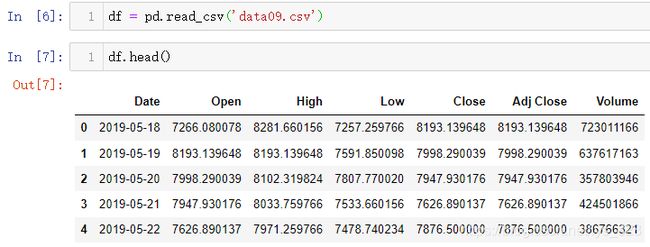
发现Date字段中存在时间数据,需要查看对应的数据类型,代码指令:type(df.Date[0])。通过简单查看字段中的一个数据的类型就知道这个字段是不是符合想要的数据类型,结果输出的时间格式为字符串
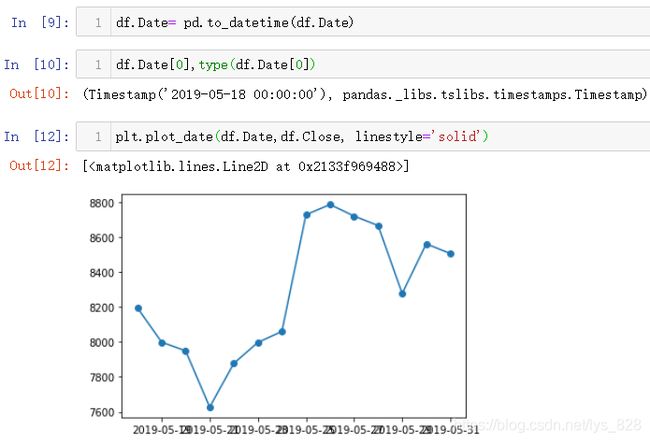
需要进一步转化,然后绘制图形(转换后的数据类型就是数据具体Datetime数据类型,然后绘制的图形汇总x轴存在着信息覆盖的现象,可以参考前面讲解的三种方式进行解决)
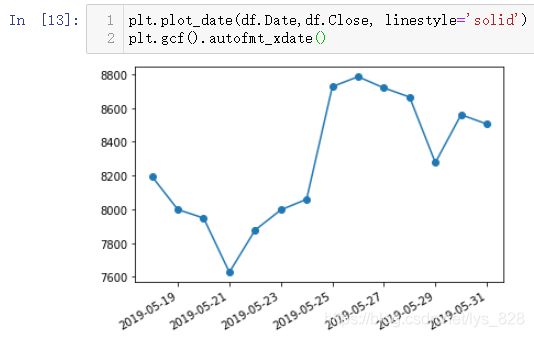
这里再介绍第四种处理x轴信息重叠的方法(针对时间或者时期数据),代码指令:plt.gcf().autofmt_xdate()
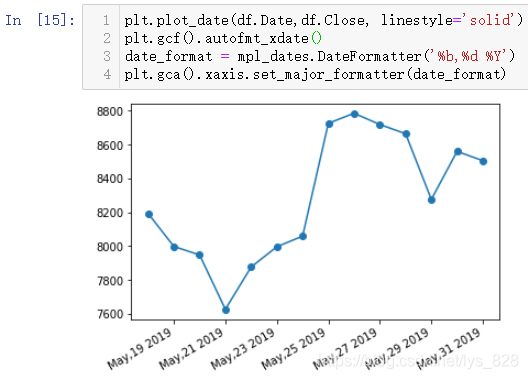
而且输出的时间还可以按照格式化的方式进行,代码指令:
date_format = mpl_dates.DateFormatter('%b,%d %Y')
plt.gca().xaxis.set_major_formatter(date_format)
输出结果如下:(这两条代码只是进行x轴显示时间的格式调整,不会改变默认的显示位置,需要配合上一条指令代码进行位置调整格式化输出)
2.9 实时数据可视化
2.9.1 实时数据绘制的原理以及模块调用
前面介绍的简单测试数据或者直接从Csv中读取的数据都是属于静态数据,接下来就是介绍关于实时数据可视化。首先进行一个小示例演示,方便理解实时数据显示的原理
首先直接给出测试代码
#导入要使用的模块
import pandas as pd
import matplotlib.pyplot as plt
import random
from itertools import count #用于计数
from IPython.display import HTML
#设定风格
plt.style.use('fivethirtyeight')
#创建两个空列表,用于收集数据
x1=[]
y1=[]
#计数值初始化,为0
index =count()
def animate():
#基于前面的调用结果+1,产生一个x
x1.append(next(index))
#产生一个y
y1.append(random.randint(0,10))
#每次绘制完毕后进行图形的擦除
plt.cla()
#再次绘制图形
plt.plot(x1,y1)
animate()
输出结果为:(每次执行都会刷新图片,当数据量增多的时候,x和y轴范围最大值也在发生改变)
实时动态图片的绘制就是上面绘制的原理,但是刚刚演示的动态效果需要自己一次一次的运行,最后结果也是一帧一帧的刷新,如果调用模块进行绘制则不会出现上面跳动的现象
#导入绘制动态图片的模块
from matplotlib.animation import FuncAnimation
#需要重新计数,函数中必须要有一个参数
index =count()
def animate1(i):
x1.append(next(index))
y1.append(random.randint(0,10))
plt.cla()
plt.plot(x1,y1)
#指定绘制的图像:plt.gcf(),具体怎么样绘制:animate,刷新绘制的间隔:interval=1000代表着1秒
ani = FuncAnimation(plt.gcf(),animate,interval=1000)
#将动态图片生成为html形式,可以直接在notebook的cell下输出并且查看
HTML(ani.to_jshtml())
输出结果为:(最终会生成一个带有控制按钮的动态图,可以进行加速或者减速,甚至直接跳到图形开始或者结束位置)
2.9.2 动手实操
上面使用的数据都是随机产生的随机数,接下来就是创建一个文件,再将生成的数据一直追加到该文件中,模拟动态实时数据
假定预生成的数据为股票数据,x为序号,y1为apple的股价;y2为google的股价;y3位amazon的股价,x的基数为0,y1-y3的基数都是1000,即生成的数据汇总序号是从1开始,y1-y3的数值在1000上下浮动
import csv
import random
import time
x_value = 0
y1 = 1000
y2 = 1000
y3 = 1000
#设置文件的字段名称
fieldname=["x","y1","y2","y3"]
#先将字段名称写入csv文件汇总
with open('data110.txt','w') as csvfile:
csv_w = csv.DictWriter(csvfile,fieldnames=fieldname)
csv_w.writeheader()
#再通过无限循环的方式想创建的文件中写入数据
while True:
with open('data110.txt','a') as csvfile:
csv_w = csv.DictWriter(csvfile,fieldnames=fieldname)
info = {
"x" : x_value,
"y1" : y1 ,
"y2" : y2 ,
"y3" : y3 ,
}
x_value +=1
y1 = y1 + random.randint(-10,10)
y2 = y2 + random.randint(-5,5)
y3 = y3 + random.randint(-15,15)
csv_w.writerow(info)
time.sleep(0.3)
代码执行后文件中输出的结果为:(只截取部分,每次刷新就会有新的数据产生,设置的刷新时间为0.3秒)

接着就是读取生成的数据进行绘制图形,函数中获取数据是通过读取Csv文件,然后指定x以及要绘制的y,最终生成的结果如下

2.10 图表的多重绘制
核心代码:plt.subplots()/fig.add_subplot()/plt.subplot2grid()
图表的多重绘制,即是对子图的绘制,之前的绘图都是把多条内容放在一个图形上,接下来介绍把每一个对应的内容放在一个子图上。回顾一下原来绘制的图像过程
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("fivethirtyeight")
data = pd.read_csv("data11.csv")
data.head()
plt.plot(data.Age,data.All_Devs)
plt.plot(data.Age,data.Python)
plt.plot(data.Age,data.JavaScript)
plt.legend(labels=['All_Devs','Python','JavaScript'])
输出结果如下:(所有绘制的折线均在一张图上)

2.10.1 通过plt.subplots绘制子图
如果要把每一图例对应的图像单独进行绘制,需要了解一下plt绘制图像的构成,直接绘制就相当于是一个fig,然后fig里面可以有多个ax组成,ax上面可以绘制图形,因此也就可以用绘制子图,先看plt.subplots()绘制1行3列的结果返回的对象结果,输出如下

对应两个变量,其中fig就是指整个绘图的大容器,包含了所有的ax
ax就对应指定的各子图,数据类型就是一个array列表

一般知道要绘制的行和列都是自定义输入,因此生成的子图数量就已经清楚了,所以建议使用一个元祖的方式将对应的子图分别赋值给对应的变量,这样可以减少重复的代码,示例如下

利用创建的子图,将数据绘制在对应的位置上,代码如下
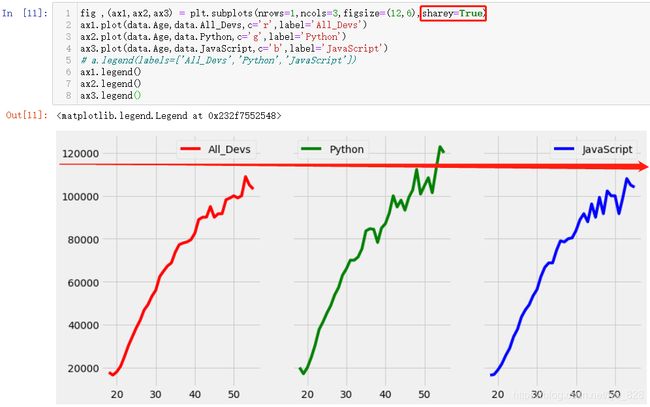
fig ,(ax1,ax2,ax3) = plt.subplots(nrows=1,ncols=3)
ax1.plot(data.Age,data.All_Devs,c='r')
ax2.plot(data.Age,data.Python,c='g')
ax3.plot(data.Age,data.JavaScript,c='b')
输出结果为:(直接出的图会比较粗糙,可以看出图像之间过于紧密)

按照之前介绍的第一种方式扩大画布看看效果,代码指令:plt.figure(figsize=(12,8)),输出结果中发现这行指令在此处没有生效,原因就在于下面绘制的这张图都是以fig下的子图ax进行绘制,并不是直接通过plt进行绘制,无法改变图像的画布大小,同理对于图例的添加也是

正确的操作是在plt.subplots()函数中指定绘制画布的参数,通过ax绘制图例

多张子图放在同一行或者同一列自动就形成了一种对比,为了更突出彼此之间的差异,应该有一个维度的参照标准是相同的,比如都放在行,对比自然是y值;如果放置在同一列,对比的就是x值,因此有必要将要对比的维度标准化为统一,需要用到的参数为:sharex和sharey。输出结果如下,以python为主要技能的薪资要比整个编程行业和JS的薪资的最大值都高
绘图的风格可以自行进行切换,前面已经介绍过如何使用内置的一些绘图风格,比如切换成为seaborn,排列的方式变成1行3列(这里默认就是已经x轴刻度范围一致,也就不用指定sharex参数,其它样式的出图也可以试试,找个自己倾向的即可)

2.10.2 通过fig.add_subplot绘制子图
这种方式是先将图像实例化,然后在向对象中添加子图
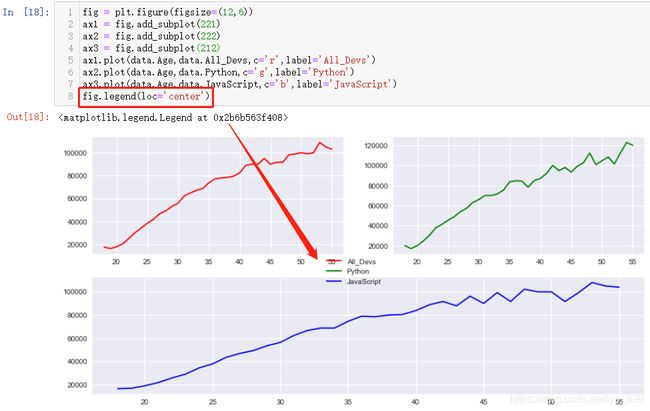
fig = plt.figure(figsize=(12,6))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(212)
输出结果为:(函数中的数字解释:ax1和ax2所在行的代码表示绘制2行2列中第1行的第1个和第2个的位置图形,主要疑惑点在于第三行代码表示绘制2行1列第2行的位置,这里的1列就是将上面绘制的2个图形看成了一个整体)

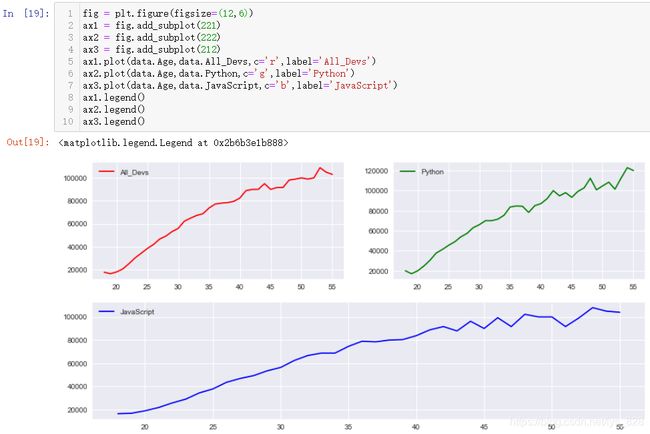
然后基于此绘制子图,输出结果如下(既然fig是实例化的对象,直接可以使用它调用显示图例的函数,但是最终得效果是把所有的图例放在了一起,如果要单独显示图例还是需要单端使用ax进行指定)
单独使用ax指定图例,输出结果如下(这时候就没有前面的函数的共享x轴或者y轴的参数,这种方法的使用主要在于位置布局上有优势)
2.10.3 通过plt.subplot2grid绘制子图
通过第2种方式绘图,有一个很容易搞迷糊的点就是进行跨行或者跨列合并,因此为了使得这个过程更清晰,可以考虑使用plt.subplot2grid方式进行位置布局,直接给出代码示例
fig = plt.figure(figsize=(12,6))
ax1 = plt.subplot2grid((6,2),(0,0),rowspan=2,colspan=1)
ax2 = plt.subplot2grid((6,2),(0,1),rowspan=2,colspan=1)
ax3 = plt.subplot2grid((6,2),(2,0),rowspan=1,colspan=2)
ax4 = plt.subplot2grid((6,2),(4,0),rowspan=2,colspan=1)
ax5 = plt.subplot2grid((6,2),(4,1),rowspan=2,colspan=1)
ax1.plot(data.Age,data.All_Devs,label='All')
ax2.plot(data.Age,data.Python,label='Python',color='g')
ax3.plot(data.Age,data.JavaScript,label='JS',color='r')
ax4.plot(data.Age,data.Python,label='Python',color='g')
ax5.plot(data.Age,data.JavaScript,label='JS',color='r')
ax1.legend()
ax2.legend()
ax3.legend()
输出结果为:(函数中的第一个参数(6,2)是指定要绘制的图形行和列,共6行2列;第二个参数就是图形绘制的起始位置,比如(0,0),代表第1行第1列的位置;第3,4个参数就是图形跨过的行和列的数量,比如rowspan=2,colspan=1代表图形跨2行,只占1列。ax3绘制的图形解析:绘制的图像都是在6行2列的画布上,起始点在第3行第1列,然后跨1行跨2列)
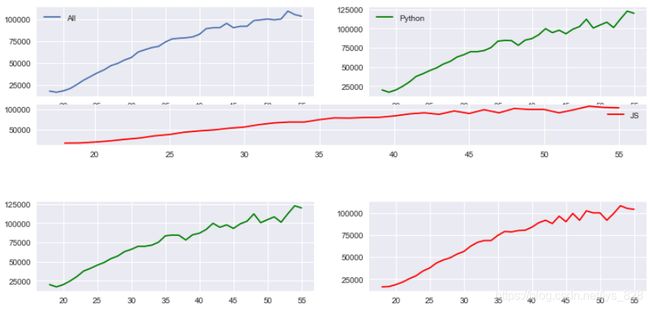
通过上图发现第3个图像把上面第1,2图像的x轴刻度信息覆盖了,这种可以尝试通过指定画布大小进行解决,输出如下(比如指定figsize=(12,10),也就是增加一下图形的高度,自然在纵向上就拥挤了)

以上就是关于Matplotlib绘图知识点的全部梳理,当然使用matplotlib绘图的样式不止这么多,更多的图形和样式都可以通过官网给的图形已经对应的源代码获取到,有兴趣的可以再看看官方的示例:Matplotlib官方示例图库
完结撒花,✿✿ヽ(°▽°)ノ✿