机器学习Sklearn——SVM支持向量机(基础理论、决策过程可视化)
目录
1 概念
1.1 线性SVM做二分类的损失函数最初形态
1.2 函数间隔与几何间隔
1.3 求解损失函数
1.3.1 将损失函数从最初形态转换为拉格朗日乘数形态
1.3.2 将拉格朗日函数转换为拉格朗日对偶函数
1.3.3 求解拉格朗日函数及KKT条件
2 Sklearn中的支持向量机
2 .1 Sklearn.svm.SVC
2.2 线性SVM决策过程的可视化
2.2.1 导入需要的模块
2.2.2 实例化数据集,可视化数据集
2.2.3 画决策边界,理解函数contour
2.2.4 画决策边界:制作网格,理解函数 meshgrid
2.2.5 . 建模,计算决策边界并找出网格上每个点到决策边界的距离
2.2.6 将绘图过程包装成函数
2.2.7 探索建好的模型
2.2.8 推广到非线性情况
2.2.9 为非线性数据增加维度并绘制3D图像
1 概念
支持向量机,(SVM,也称作支持向量网络)是有监督的机器学习算法,他可用于分类和回归,最主要是用在分类上。可以说是机器学习天花板的存在,仅次于深度学习的神经网络模型。

目标:支持向量机的分类方法,是在这组分布中找到一个超平面作为决策边界,使其能将两类完全分开的同时,离最近的数据点间隔尽量远。
约束条件:这样才能将两类完全分开。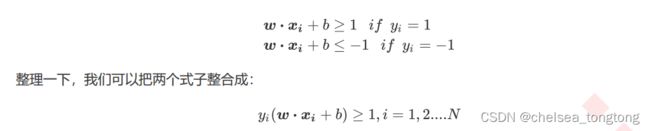
1.1 线性SVM做二分类的损失函数最初形态
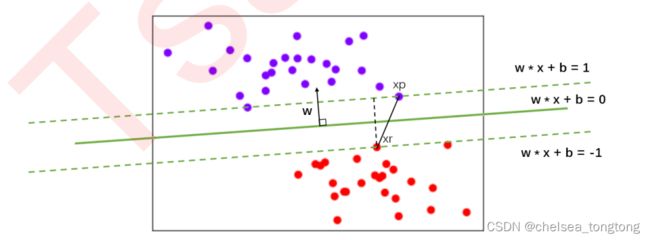

超平面:在几何中,超空间是一个空间的子空间,它是维度比所在空间小一维的空间。如果数据空间本身是三维的,则其超平面是二维平面;如果数据空间本身是二维的,则其超平面是一维的直线。
在二分类问题中,如果一个超平面能够将数据划分为两个集合,其中每个集合包含一个单独的类别,我们就说这个超平面是数据的“决策边界”。上图绿色直线就是“决策边界”。
1.2 函数间隔与几何间隔
- 函数间隔可以表示分类预测的正确性以及确信度
- 几何间隔除以w的模场就得到几何间隔

1.3 求解损失函数
1.3.1 将损失函数从最初形态转换为拉格朗日乘数形态
- 为什么要进行转换?

得使w为0是不满足的,而为了考虑到函数间隔这个约束条件,一种业界认可的使用方法是拉格朗日乘数法。
- 为什么可以转换?

- 怎样进行转换?

1.3.2 将拉格朗日函数转换为拉格朗日对偶函数

1.3.3 求解拉格朗日函数及KKT条件
这个推导过程有点复杂,我看的是机器学习-白板推导系列(六)-支持向量机SVM(Support Vector Machine)_哔哩哔哩_bilibili
上面展示公式推导的也是菜菜机器学习的教案
【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
想要感受数学之美的宝宝们可以继续手撕了,我撕过一次发现到这里撕不动放弃了!
2 Sklearn中的支持向量机
SVM 是一种二类分类模型。它的基本思想是在特征空间中寻找间隔最大的分离超平面使数据得到高效的二分类,具体来讲,有三种情况(不加核函数的话就是个线性模型,加了之后才会升级为一个非线性模型):
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
- 当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
- 当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
2 .1 Sklearn.svm.SVC
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=- 1, decision_function_shape='ovr', break_ties=False, random_state=None)
| 参数 | 含义 |
| kernel | 字符,可不填,默认"rbf" 指定要在算法中使用的核函数类型,可以输入’linear’, ‘poly’, ‘rbf’, ‘sigmoid’,'precomputed’或者可调用对象(如函数,类等) 。 如果给出可调用对象,则这个对象将被用于从特征矩阵X预先计算内核矩阵;该矩阵应该是是一个(n_samples, n_samples)结构的数组。 |
| degree | 整数,可不填,默认3 多项式核函数的次数(‘poly’) ,如果核函数没有选择"poly",这个参数会被忽略。 |
| gamma | 浮点数,可不填,默认"auto “ 核函数的系数,仅在参数Kernel的选项为” rbf",“poly"和"sigmoid"的时候有效。 当输入"auto”, 自动使用1/(n features)作为gamma的取值。 在sklearn0.22版本中,将可输入"scale",则使用1/(n features * X.std())作为gamma的取值。 若输入"auto_deprecated",则表示没有传递明确的gamma值(不推荐使用)。 |
| coefo | 浮点数,可不填,默认=0.0 核函数中的独立项,它只在参数kernel为’poly’和sigmoid’的时候有效。 |
| C | 浮点数,可不填,默认1.0,必须大于等于0 松弛系数的惩罚项系数。如果C值设定比较大,那SVC可能会选择边际较小的,能够更好地分类所有训练点的决策边界。 如果C的设定值较小,那SVC会尽量最大化边界,决策功能会更简单, 但代价是训练的准确度。 换句话说, C在SVM中的影响就像正则化参数对逻辑回归的影响。 |
2.2 线性SVM决策过程的可视化
我们可以使用sklearn中的式子来为可视化我们的决策边界。支持向量、以及决策边界平行的两个超平面。
2.2.1 导入需要的模块
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as npX,y = make_blobs(n_samples=50, centers=2, random_state=0,cluster_std=0.6)
- make_blobs函数是为聚类产生数据集,产生相应数据和标签
| n_samples | 表示数据样本点个数,默认值100 |
| n_features | 是每个样本的特征(或属性)数,也表示数据的维度,默认值是2 |
| centers | 表示类别数(标签的种类数),默认值3 |
| cluster_std | 表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0],浮点数或者浮点数序列,默认值1.0 |
| center_box | 中心确定之后的数据边界,默认值(-10.0, 10.0) |
| shuffle | 将数据进行洗乱,默认值是True |
| random_state | 官网解释是随机生成器的种子,可以固定生成的数据,给定数之后,每次生成的数据集就是固定的。若不给定值,则由于随机性将导致每次运行程序所获得的的结果可能有所不同。在使用数据生成器练习机器学习算法练习或python练习时建议给定数值。 |
2.2.2 实例化数据集,可视化数据集
- X的centers=2所以有两列,有两个标签
X,y = make_blobs(n_samples=50, centers=2, random_state=0,cluster_std=0.6)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")#rainbow彩虹色
plt.xticks([])
plt.yticks([])##x、y轴没有标签
plt.show()
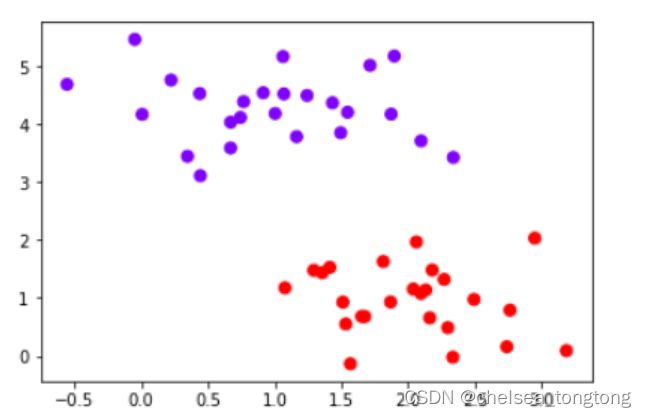
有了这个平面,我们需要在平面上制作一个足够细的网格,来代表我们“平面上的所有点”。
2.2.3 画决策边界,理解函数contour
matplotlib.axes.Axes.contour([X, Y,] Z, [levels], **kwargs) Contour
- 是我们专门用来绘制等高线的函数。等高线,本质上是在二维图像上表现三维图像的一种形式,其中两维X 和 Y 是两条坐标轴上的取值,而 Z 表示高度。 Contour 就是将由 X 和 Y构成平面上的所有点中,高度一致的点连接成线段的函数,在同一条等高线上的点一定具有相同的 Z 值。我们可以利用这个性质来绘制我们的决策边界。
- X、Y都需要二维的

回忆一下:我们的决策边界是,并在决策边界的两边找出两个超平面,使得超平面到决策边界的相对距离为 1 。那其实,我们只需要在我们的样本构成的平面上,把所有到决策边界的距离为 0的点相连,就是我们的决策边界,而把所有到决策边界的相对距离为 1的点相连,就是我们的两个平行于决策边界的超平面了。此时,我们的 Z 就是平面上的任意点到达超平面的距离。
那首先,我们需要获取样本构成的平面,作为一个对象。
2.2.4 画决策边界:制作网格,理解函数 meshgrid
- 使用meshgrid方法,你只需要构造一个表示x轴上的坐标的向量和一个表示y轴上的坐标的向量;然后作为参数给到meshgrid(),该函数就会返回相应维度的两个矩阵;
例如,你想构造一个2行3列的矩阵网格点,那么x生成一个shape(3,)的向量,y生成一个shape(2,)的向量,将x,y传入meshgrid(),最后返回的X,Y矩阵的shape(2,3) - v1.ravel(),v2.ravel()将多维数据展平为一维数据,可以选择不同的数据索引方式
理解函数meshgrid和vstack的作用
a = np.array([1,2,3])#a.shape是(3,)
b = np.array([7,8])#b.shape是(2,)
v1,v2=np.meshgrid(a,b)
v1=array([[1, 2, 3],
[1, 2, 3]])
v2=array([[7, 7, 7],
[8, 8, 8]])#a,b是二维
v1.ravel()=array([1, 2, 3, 1, 2, 3])
v2.ravel()=array([7, 7, 7, 8, 8, 8])
v = np.vstack([v1.ravel(), v2.ravel()]).T
v=array([[1, 7],
[2, 7],
[3, 7],
[1, 8],
[2, 8],
[3, 8]])
两两组合,会得到多少个坐标?答案是6个,分别是 (1,7),(2,7),(3,7),(1,8),(2,8),(3,8)
#获取平面上两条坐标轴的最大值和最小值
xlim = ax.get_xlim()
ylim = ax.get_ylim()
#在最大值和最小值之间形成30个规律的数据
axisx = np.linspace(xlim[0],xlim[1],30)
axisy = np.linspace(ylim[0],ylim[1],30)#生成一维的30个数据,(30,)
axisy,axisx = np.meshgrid(axisy,axisx)#生成二维的数据,把一维的数据复制一遍,(30,30)
#我们将使用这里形成的二维数组作为我们contour函数中的X和Y
#使用meshgrid函数将两个一维向量转换为特征矩阵
#核心是将两个特征向量广播,以便获取y.shape * x.shape这么多个坐标点的横坐标和纵坐标
xy = np.vstack([axisx.ravel(), axisy.ravel()]).T#(900,2)
#其中ravel()是降维函数,vstack能够将多个结构一致的一维数组按行堆叠起来
#xy就是已经形成的网格,它是遍布在整个画布上的密集的点
plt.scatter(xy[:,0],xy[:,1],s=1,cmap="rainbow")
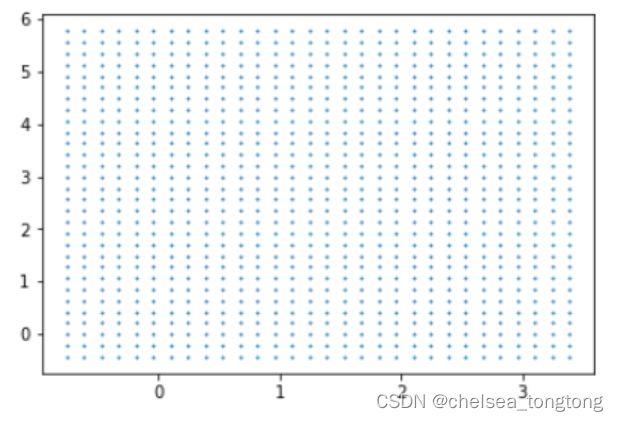
有了网格后,我们需要计算网格所代表的 “ 平面上所有的点 ”到我们的决策边界的距离。所以我们需要我们的模型和决策边界。
2.2.5 . 建模,计算决策边界并找出网格上每个点到决策边界的距离
- Z.shape,axisx.shape,axisy.shape是(30,30)
- contour函数里面linestyles=["--","-","--"],"--"表示的是虚线,"-"表示的是实线
- z计算900个点到决策边界的距离
#建模,通过fit计算出对应的决策边界
clf = SVC(kernel = "linear").fit(X,y)#计算出对应的决策边界
Z = clf.decision_function(xy).reshape(axisx.shape)
#重要接口decision_function,返回每个输入的样本所对应的到决策边界的距离
#然后再将这个距离转换为axisx的结构,这是由于画图的函数contour要求Z的结构必须与X和Y保持一致
#首先要有散点图
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
ax = plt.gca() #获取当前的子图,如果不存在,则创建新的子图
#画决策边界和平行于决策边界的超平面
ax.contour(axisx,axisy,Z
,colors="k"
,levels=[-1,0,1] #画三条等高线,分别是Z为-1,Z为0和Z为1的三条线
,alpha=0.5#透明度
,linestyles=["--","-","--"])
ax.set_xlim(xlim)#设置x轴取值
ax.set_ylim(ylim)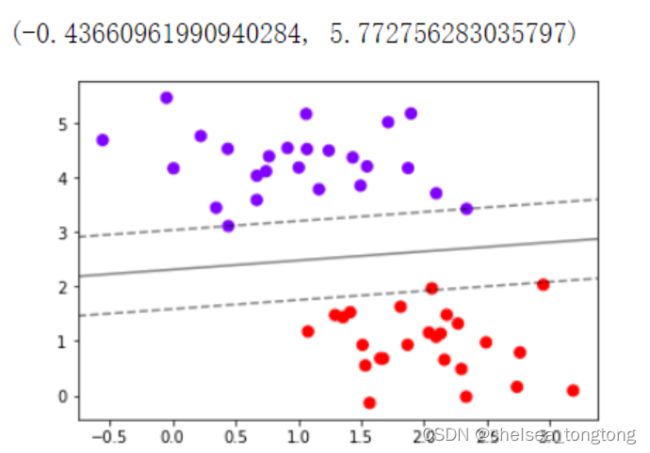
- 记得Z的本质么?是输入的样本到决策边界的距离,而contour函数中的level其实是输入了这个距离。让我们用一个点来试试看。
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plt.scatter(X[10,0],X[10,1],c="black",s=50,cmap="rainbow")#取 的x点的第十个点,是900个点中的一个clf.decision_function(X[10].reshape(1,2))#结果是-3.33917354
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
ax = plt.gca()
ax.contour(axisx,axisy,Z
,colors="k"
,levels=[-3.33917354]
,alpha=0.5
,linestyles=["--"])经过这个点的虚线上所有点到决策边界的距离都是-3.33917354

2.2.6 将绘图过程包装成函数
- plot_svc_decision_function(model,ax=None)写好的函数,可以随意适用不同数据集
- python—contour绘制轮廓线(等高线)_哎呦-_-不错的博客-CSDN博客_contour python
#将上述过程包装成函数:
def plot_svc_decision_function(model,ax=None):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
x = np.linspace(xlim[0],xlim[1],30)
y = np.linspace(ylim[0],ylim[1],30)
Y,X = np.meshgrid(y,x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
ax.contour(X, Y, P,colors="k",levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.set_xlim(xlim)
ax.set_ylim(ylim)
#则整个绘图过程可以写作:
clf = SVC(kernel = "linear").fit(X,y)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plot_svc_decision_function(clf)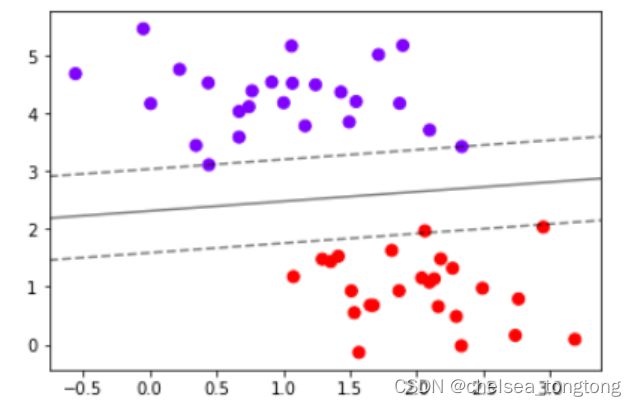
2.2.7 探索建好的模型
- 在支持向量机中,距离超平面最近的且满足一定条件的几个训练样本被称为支持向量。
- 黑色实线就是最大间隔超平面,在这个例子中,蓝色的虚线上两个点和红色虚线左边的点到该超平面的距离相等。
- 这些点非常特别,因为超平面的参数完全由这三个点决定。该超平面与其他任何点无关。如果改变其他点的位置,只要其他点不落入虚线上或者虚线内,那么超平面的参数都不会改变。
clf.predict(X)
#根据决策边界,对X中的样本进行分类,返回的结构为n_samples
#返回[0,1,1,0,1,1......]
clf.score(X,y)
#返回给定测试数据和标签的平均准确度
clf.support_vectors_
#返回支持向量坐标,返回三个点
clf.n_support_#array([2, 1])
#返回每个类中支持向量的个数
'''
array([2, 1])表示第一类中有两个支持向量,第一个有一个支持向量
'''2.2.8 推广到非线性情况
我们之前所讲解的原理,以及绘图的过程,都是基于数据本身是线性可分的情况。如果把数据推广到非线性数据,比如说环形数据上呢?
from sklearn.datasets import make_circles
X,y = make_circles(100, factor=0.1, noise=.1)
X.shape#(100,2)
y.shape#(100,)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plt.show()
试试看用我们已经定义的函数来划分这个数据的决策边界:
clf = SVC(kernel = "linear").fit(X,y)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plot_svc_decision_function(clf)
clf.score(X,y)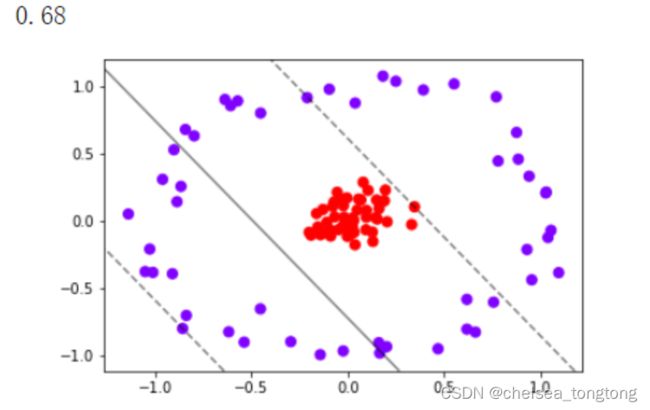
明显,现在线性SVM已经不适合于我们的状况了,我们无法找出一条直线来划分我们的数据集,让直线的两边分别是两种类别。这个时候,如果我们能够在原本的X和y的基础上,添加一个维度r,变成三维,我们可视化这个数据,来看看添加维度让我们的数据如何变化。
2.2.9 为非线性数据增加维度并绘制3D图像
- from mpl_toolkits import mplot3d
- elev表示上下旋转的角度
azim表示平行旋转的角度
#定义一个由x计算出来的新维度r
r = np.exp(-(X**2).sum(1))
rlim = np.linspace(min(r),max(r),100)
from mpl_toolkits import mplot3d
#定义一个绘制三维图像的函数
#elev表示上下旋转的角度
#azim表示平行旋转的角度
def plot_3D(elev=30,azim=30,X=X,y=y):
ax = plt.subplot(projection="3d")
ax.scatter3D(X[:,0],X[:,1],r,c=y,s=50,cmap='rainbow')
ax.view_init(elev=elev,azim=azim)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("r")
plt.show()
plot_3D()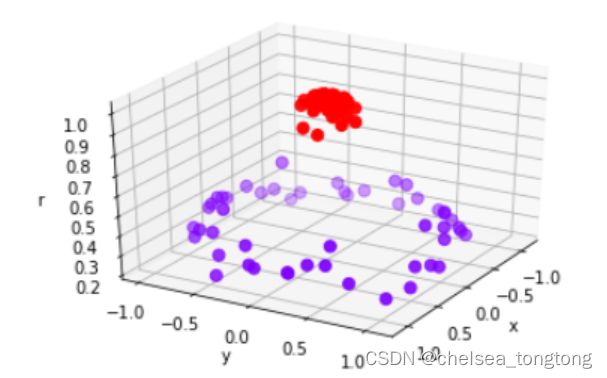
可以看见,此时此刻我们的数据明显是线性可分的了:我们可以使用一个平面来将数据完全分开,并使平面的上方的所有数据点为一类,平面下方的所有数据点为另一类。
2.2.10 将上述过程放到 Jupyter Notebook 中运行
- 得到一个可以互动的页面,0°显示非常明显可以划分为两类,90°如上俯视图
- 在jupyter notebook而不是jupyter lab进行实现,因为其内核是ipython
#如果放到jupyter notebook中运行
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_circles
X,y = make_circles(100, factor=0.1, noise=.1)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
def plot_svc_decision_function(model,ax=None):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
x = np.linspace(xlim[0],xlim[1],30)
y = np.linspace(ylim[0],ylim[1],30)
Y,X = np.meshgrid(y,x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
ax.contour(X, Y, P,colors="k",levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.set_xlim(xlim)
ax.set_ylim(ylim)
clf = SVC(kernel = "linear").fit(X,y)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plot_svc_decision_function(clf)
r = np.exp(-(X**2).sum(1))
rlim = np.linspace(min(r),max(r),100)
from mpl_toolkits import mplot3d
def plot_3D(elev=30,azim=30,X=X,y=y):
ax = plt.subplot(projection="3d")
ax.scatter3D(X[:,0],X[:,1],r,c=y,s=50,cmap='rainbow')
ax.view_init(elev=elev,azim=azim)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("r")
plt.show()
from ipywidgets import interact,fixed
interact(plot_3D,elev=[0,30,60,90],azip=(-180,180),X=fixed(X),y=fixed(y))
plt.show()
此时我们的数据在三维空间中,我们的超平面就是一个二维平面。明显我们可以用一个平面将两类数据隔开,这个平面就是我们的决策边界了。我们刚才做的,计算 r ,并将 r 作为数据的第三维度来将数据升维的过程,被称为 “核变换 ”,即是将数据投影到高维空间中,以寻找能够将数据完美分割的超平面,即是说寻找能够让数据线性可分的高维空间。为了详细解释这个过程,我们需要引入 SVM 中的核心概念:核函数。