word2vector之CBoW模型详解
深度学习入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
✨word2vector系列展示✨
一、CBOW
1、朴素CBOW模型
本篇
2、基于分层softmax的CBOW模型
基于分层softmax的CBoW模型详解_tt丫的博客-CSDN博客
3、基于高频词抽样+负采样的CBOW模型
基于高频词抽样+负采样的CBOW模型_tt丫的博客-CSDN博客
二、Skip_Gram
word2vector之Skip_Gram模型详解_tt丫的博客-CSDN博客
(关于Skip_Gram的分层softmax和负采样,与CBOW类似)
目录
一、前景知识
二、CBoW模型思想
三、CBoW模型结构分析
1、网络结构图
2、CBoW模型 Vs NNLM
3、网络层次级分析
四、代码实现
一、前景知识
这些可以根据需要跳着看
NLP之文本预处理详解_tt丫的博客-CSDN博客
NLP之文本特征提取详解_tt丫的博客-CSDN博客
二、CBoW模型思想
通过上下文来预测当前值,即像我们的填词游戏。
CBoW模型等价于一个词袋模型的向量乘一个矩阵,得到一个连续的embedding向量。
三、CBoW模型结构分析
1、网络结构图
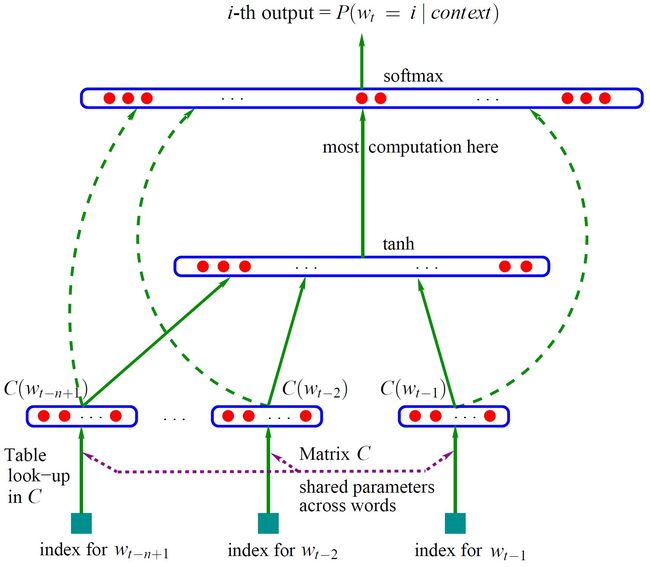
网络结构如图所示:(左图是CBoW模型;右图是NNLM模型)

2、CBoW模型 Vs NNLM
(1)最直观的就是它的输入了:CBoW模型考虑了上下文(t - 1,t + 1);NNLM只考虑前文
(2)舍掉NNLM前向反馈神经网络中非线性的hidden layer,直接将中间层的embedding layer与输出层的softmax layer连接
3、网络层次级分析
(1)INPUT:
输入的是上下文单词的one hot编码。假设单词向量空间的维度为V,即整个词库大小为V,上下文单词窗口的大小为C。所以输入大小 C * V。
(2)Hidden :
假设hidden layer最终得到的词向量的维度大小为N,INPUT到Hidden的权值共享矩阵(“共享”即每个词乘的W一样)为W。W的大小为 V ∗ N,并且初始化。
我们将C个1 * V大小的向量分别同一个上述所说的V ∗ N大小的W相乘,得到的是C个1 ∗ N 大小的向量。再将这C个1 ∗ N大小的向量取平均,得到一个1 ∗ N 大小的向量。
(3)OUTPUT:
初始化输出权重矩阵大小为N ∗ V的W’
将Hidden layer1 ∗ N 的向量与W’相乘,并且用softmax处理,得到1 ∗ V的向量,此向量的每一维代表词库中的一个词。概率中最大的index所代表的单词即为预测出的中间词。
四、代码实现
导入所需的库
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F从文件中读取数据,并且进行一定的处理(解析详见NNLM中的代码解析,就上面前景知识的链接)
path = "1.txt"
f = open(path, 'r', encoding= 'utf-8', errors= 'ignore')
text = []
piece = ''
for line in f:
for uchar in line:
if uchar == '\n':
continue
if uchar == '.' or uchar == '?' or uchar == '!':
text.append(piece)
piece = ''
else:
piece = piece + uchar
word_list = " ".join(text).split()
#将分词后的结果去重
vab = list(set(word_list))
#对单词建立索引
word_dict = {w:i for i, w in enumerate(vab)} #单词-索引对输入的数据进行处理(针对上下文的输入)
data = []
for i in range(2, len(word_list) - 2):
context = [word_list[i - 2], word_list[i - 1],
word_list[i + 1], word_list[i + 2]]
target = word_list[i]
data.append((context, target))CBoW模型构建
class CBOW(nn.Module):
'''''
word_size相当于V;
embedding_dim:嵌入词向量的维度;
context_size相当于一半上下文的大小。
'''''
def __init__(self, word_size, embedding_dim, context_size):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(word_size, embedding_dim)
self.linear1 = nn.Linear(2*context_size * embedding_dim, 128)
#N为128
self.linear2 = nn.Linear(128, word_size)
def forward(self, inputs):
embeds = self.embeddings(inputs).view((1, -1))
out = F.relu(self.linear1(embeds))
out = self.linear2(out)
probs = F.log_softmax(out, dim=1)
return probs网络配置准备
EMBEDDING_DIM = 10
CONTEXT_SIZE = 2
losses = []
loss_function = nn.NLLLoss()
model = CBOW(len(vab), EMBEDDING_DIM, CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.001)训练
for epoch in range(500):
total_loss = 0
for context, target in data:
# 准备好进入模型的数据
idxs = [word_dict[w] for w in context]
context_idx = torch.tensor(idxs, dtype=torch.long)
# 梯度置零
model.zero_grad()
# 进入模型训练
log_probs = model(context_idx)
# 计算损失函数
loss = loss_function(log_probs, torch.tensor([word_dict[target]], dtype=torch.long))
# 反向传播并更新梯度
loss.backward()
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
print(losses) 欢迎大家在评论区批评指正,谢谢啦~