学员成果分享:影像组学中stacking算法做后融合的整体思路(附代码,有平台的赶紧动手)
https://mp.weixin.qq.com/s?__biz=MzkxMTIxNzAwNg==&mid=2247486839&idx=1&sn=9413985f4986c7fd5adb51a440b41b0f&chksm=c11ed576f6695c60e30275d5637e2dfca43f5a71c090b93b6174e90b54a00e4dbcdd0a133419#rd
影像组学路径图
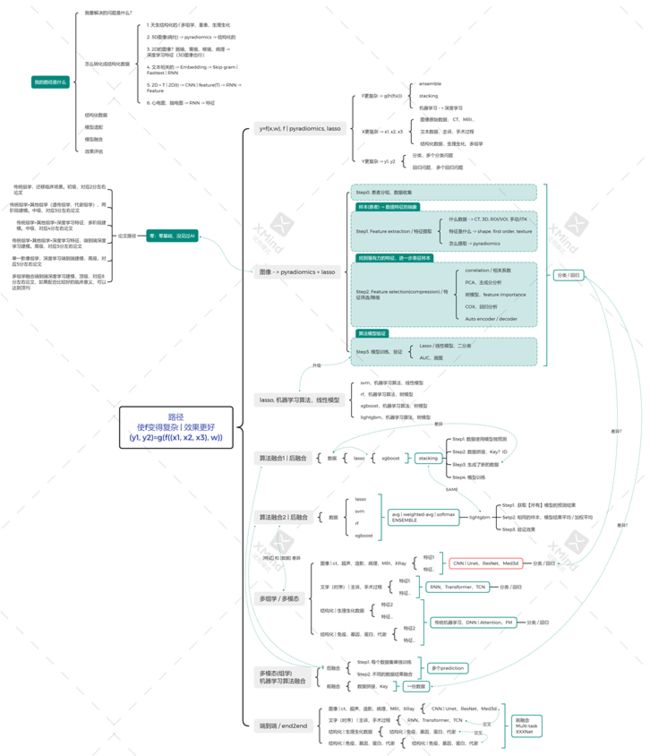
感谢《Young》同学分享的stacking算法的整体思路
参加培训班,争取进小班
(免费)你也可以做引路人
采用案例
参考了吴同学的代码,地址:http://www.medai.icu/thread/112
1、stacking整体思路:使用3个算法生成6个特征,与之前的31个特征合并后,再使用xgboost训练

2、拼接后的特征

3、代码
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import SGDClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score
#svm--训练集
model_svm = SVC(probability = True)
model_svm.fit(X_train, y_train) # X_train = 400行数据,y_train = 400行对应的结果0或1
train_score_svm = model_svm.predict_proba(X_train)
new_data_svm = np.concatenate([np.reshape(np.array(X_train_id),(-1,1)),train_score_svm], axis = 1)
new_data_svm = pd.DataFrame(new_data_svm, columns = ['id','prob1','prob2'])
new_data_svm['id'] = new_data_svm['id'].astype('int')
comb_X_train_svm = pd.merge(X_train_all,new_data_svm, how = 'left',on = ['id'])
#svm--测试集
test_score_svm = model_svm.predict_proba(X_test)
new_data_svm1 = np.concatenate([np.reshape(np.array(X_test_id),(-1,1)),test_score_svm], axis = 1)
new_data_svm1 = pd.DataFrame(new_data_svm1, columns = ['id','prob1','prob2'])
new_data_svm1['id'] = new_data_svm1['id'].astype('int')
comb_X_test_svm = pd.merge(X_test_all,new_data_svm1, how = 'left',on = ['id'])
#random forest--训练集
model_rf = RandomForestClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
model_rf.fit(X_train, y_train)
train_score_rf = model_rf.predict_proba(X_train)
new_data_rf = np.concatenate([np.reshape(np.array(X_train_id),(-1,1)),train_score_rf], axis = 1)
new_data_rf = pd.DataFrame(new_data_rf, columns = ['id','prob7','prob8'])
new_data_rf['id'] = new_data_rf['id'].astype('int')
comb_X_train_rf = pd.merge(comb_X_train_svm,new_data_rf, how = 'left',on = ['id'])
#random forest--测试集
test_score_rf = model_rf.predict_proba(X_test)
new_data_rf1 = np.concatenate([np.reshape(np.array(X_test_id),(-1,1)),test_score_rf], axis = 1)
new_data_rf1 = pd.DataFrame(new_data_rf1, columns = ['id','prob7','prob8'])
new_data_rf1['id'] = new_data_rf1['id'].astype('int')
comb_X_test_rf = pd.merge(comb_X_test_svm,new_data_rf1, how = 'left',on = ['id'])
#LGBM--训练集
model_lgb = LGBMClassifier(n_estimators=80, max_depth=4, objective='binary')
model_lgb.fit(X_train, y_train)
train_score_lgb = model_lgb.predict_proba(X_train)
new_data_lgb = np.concatenate([np.reshape(np.array(X_train_id),(-1,1)),train_score_lgb], axis = 1)
new_data_lgb = pd.DataFrame(new_data_lgb, columns = ['id','prob11','prob12'])
new_data_lgb['id'] = new_data_lgb['id'].astype('int')
comb_X_train_lgb = pd.merge(comb_X_train_rf,new_data_lgb, how = 'left',on = ['id'])
#LGBM--测试集
test_score_lgb = model_lgb.predict_proba(X_test)
new_data_lgb1 = np.concatenate([np.reshape(np.array(X_test_id),(-1,1)),test_score_lgb], axis = 1)
new_data_lgb1 = pd.DataFrame(new_data_lgb1, columns = ['id','prob11','prob12'])
new_data_lgb1['id'] = new_data_lgb1['id'].astype('int')
comb_X_test_lgb = pd.merge(comb_X_test_rf,new_data_lgb1, how = 'left',on = ['id'])
4、xgboost进行训练输出结果为:0.9440559440559441
未融合输出结果为:0.951049

5、ensemble融合思路:
由原来3个算法的6个特征,结果加权平均后输出为2个特征,再使用xgboost训练
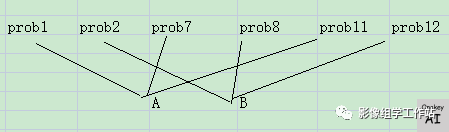
6、总结:算法融合的核心是使用一个算法输出的结果作为一个特征,拼接到原来的特征上,使用算法对新的数据特征进行训练输出结果,融合后模型精度是否提高需要多测试来确定。
7、问题:svm输出的两列prob1,prob2对应的是0,1的概率吗?网上的答案是0,1的概率。

