DenseNet详解
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
✨完整代码在我的github上,有需要的朋友可以康康✨
https://github.com/tt-s-t/Deep-Learning.git
目录
一、DenseNet网络的背景
二、DenseNet网络结构
1、Dense Block——特征重用
2、Transition层
3、网络结构
四、DenseNet优缺点
1、优点
(1)相比ResNet拥有更少的参数数量
(2)传播与预测都保留了低层次的特征
(3)旁路加强了特征的重用,导致直接的监督
(4)网络更易于训练,并具有一定的正则化效果
(5)缓解了梯度消失/爆炸和网络退化的问题
2、不足
五、DenseNet代码实现
1、DenseLayer
2、DenseBlock
3、Transition
4、DenseNet整体构建
一、DenseNet网络的背景
DenseNet模型的基本思路与ResNet一致,但它建立的是前面所有层与后面层的密集连接(即相加变连结),它的名称也是由此而来。
DenseNet的另一大特色是通过特征在通道上的连接来实现特征重用。这些特点让DenseNet的参数量和计算成本都变得更少了(相对ResNet),效果也更好了。
ResNet解决了深层网络梯度消失问题,它是从深度方向研究的。宽度方向是GoogleNet的Inception。而DenseNet是从feature入手,通过对feature的极致利用能达到更好的效果和减少参数。
DenseNet斩获CVPR 2017的最佳论文奖。
二、DenseNet网络结构
1、Dense Block——特征重用
DenseBlock包含很多层,每个层的特征图大小相同(才可以在通道上进行连结),层与层之间采用密集连接方式。
如下图所示:


上图是一个包含5层layer的Dense Block。可以看出Dense Block互相连接所有的层,具体来说就是每一层的输入都来自于它前面所有层的特征图,每一层的输出均会直接连接到它后面所有层的输入。所以对于一个L层的DenseBlock,共包含 L*(L+1)/2 个连接(等差数列求和公式),如果是ResNet的话则为(L-1)*2+1。从这里可以看出:相比ResNet,Dense Block采用密集连接。而且Dense Block是直接concat来自不同层的特征图,这可以实现特征重用(即对不同“级别”的特征——不同表征进行总体性地再探索),提升效率,这一特点是DenseNet与ResNet最主要的区别。
Note:k —— DenseNet中的growth rate(增长率),这是一个超参数。一般情况下使用较小的k(比如12),就可以得到较佳的性能。
假定输入层的特征图的通道数为k0,那么L层输入的channel数为 k0+k*(L-1),因此随着层数增加,尽管k设定得较小,DenseBlock中每一层输入依旧会越来越多。
另外一个特殊的点:DenseBlock中采用BN+ReLU+Conv的结构,平常我们常见的是Conv+BN+ReLU。这么做的原因是:卷积层的输入包含了它前面所有层的输出特征,它们来自不同层的输出,因此数值分布差异比较大,所以它们在输入到下一个卷积层时,必须先经过BN层将其数值进行标准化,然后再进行卷积操作。
通常为了减少参数,一般还会先加一个1x1conv来减少参数量。所以DenseBlock中的每一层采用BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv的结构(或者BottleNeck)。
2、Transition层
它主要用于连接两个相邻的DenseBlock,整合上一个DenseBlock获得的特征,缩小上一个DenseBlock的宽高,达到下采样效果,特征图的宽高减半。Transition层包括一个1x1卷积(用于调整通道数)和2x2AvgPooling(用于降低特征图大小),结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。因此,Transition层可以起到压缩模型的作用 。
超参调节:θ是压缩系数,取值(0,1],当θ=1时,原feature维度不变,即无压缩;
而当压缩系数小于1时,这种结构称为DenseNet-C(文中使用θ=0.5);
对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。后面在使用的DenseNet默认都是DenseNet-BC,因为它的效果最好。
3、网络结构
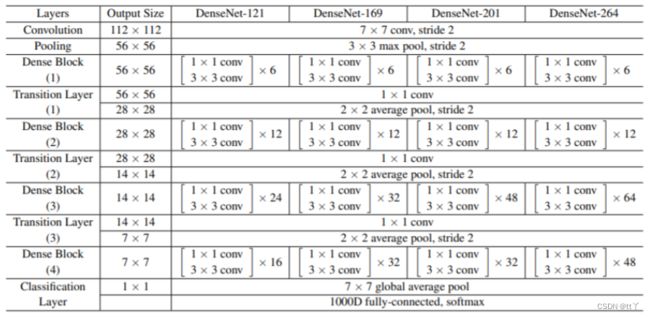
DenseNet的网络结构主要由DenseBlock和Transition组成,一个DenseNet中有3个或4个DenseBlock。而一个DenseBlock中也会有多个Bottleneck layers。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器,得到每个类别所属分数。
四、DenseNet优缺点
1、优点
(1)相比ResNet拥有更少的参数数量
参数减少,计算效率更高,效果更好(相较于其他网络)
(2)传播与预测都保留了低层次的特征
在以前的卷积神经网络中,最终输出只会利用最高层次的特征。而DenseNet实现特征重用,同时利用低层次和高层次的特征。
(3)旁路加强了特征的重用,导致直接的监督
因为每一层都建立起了与前面层的连接,误差信号可以很容易地传播到较早的层,所以较早的层可以从最终分类层获得直接的监督。
(4)网络更易于训练,并具有一定的正则化效果
(网上资料都有说这一句,但是我不太清楚他是怎么体现正则化效果的)
(5)缓解了梯度消失/爆炸和网络退化的问题
特征重用实现了梯度的提前传播,也至少保留了前面网络的能力,不至于变弱(最少也是个恒等变换)
2、不足
由于需要进行多次Concatnate操作,数据需要被复制多次,显存容易增加得很快,需要一定的显存优化技术。因此在训练过程中,训练的时间要比Resnet作为backbone长很多。所以相对而言,ResNet更常用。
并且ResNet更加的简洁,变体也多,更加成熟,因此后来更多使用的是ResNet,但是DenseNet的思想贡献也是如今很常见的。
五、DenseNet代码实现
完整代码在我的github上,用自行搭建的DenseNet实现对cifar10数据的分类(里面超参数是我一拍脑袋设的,要有好的分类效果还要调一调,这里主要是想自己搭一下网络实现而已)
https://github.com/tt-s-t/Deep-Learning.git
以下展示网络搭建
1、DenseLayer
import torch
import torch.nn as nn
import torch.nn.functional as F
class DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(DenseLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(num_input_features)
self.relu1 = nn.ReLU()
self.conv1 = nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(bn_size*growth_rate)
self.relu2 = nn.ReLU()
self.conv2 = nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)
self.drop_rate = drop_rate
def forward(self, x):
output = self.bn1(x)
output = self.relu1(output)
output = self.conv1(output)
output = self.bn2(output)
output = self.relu2(output)
output = self.conv2(output)
if self.drop_rate > 0:
output = F.dropout(output, p=self.drop_rate)
return torch.cat([x, output], 1)2、DenseBlock
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(DenseBlock, self).__init__()
for i in range(num_layers):
if i == 0:
self.layer = nn.Sequential(
DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,drop_rate)
)
else:
layer = DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,drop_rate)
self.layer.add_module("denselayer%d" % (i+1), layer)
def forward(self,input):
return self.layer(input)3、Transition
class Transition(nn.Sequential):
def __init__(self, num_input_feature, num_output_features):
super(Transition, self).__init__()
self.bn = nn.BatchNorm2d(num_input_feature)
self.relu = nn.ReLU()
self.conv = nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(2, stride=2)
def forward(self,input):
output = self.bn(input)
output = self.relu(output)
output = self.conv(output)
output = self.pool(output)
return output4、DenseNet整体构建
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# 前部
self.features = nn.Sequential(
#第一层
nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(),
#第二层
nn.MaxPool2d(3, stride=2, padding=1)
)
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, num_features, bn_size, growth_rate,drop_rate)
if i == 0:
self.block_tran = nn.Sequential(
block
)
else:
self.block_tran.add_module("denseblock%d" % (i + 1), block)#添加一个block
num_features += num_layers*growth_rate#更新通道数
if i != len(block_config) - 1:#除去最后一层不需要加Transition来连接两个相邻的DenseBlock
transition = Transition(num_features, int(num_features*compression_rate))
self.block_tran.add_module("transition%d" % (i + 1), transition)#添加Transition
num_features = int(num_features * compression_rate)#更新通道数
# 后部 bn+ReLU
self.tail = nn.Sequential(
nn.BatchNorm2d(num_features),
nn.ReLU()
)
# classification layer
self.classifier = nn.Linear(num_features, num_classes)
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):#如果是卷积层,参数kaiming分布处理
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):#如果是批量归一化则伸缩参数为1,偏移为0
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):#如果是线性层偏移为0
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
block_output = self.block_tran(features)
tail_output = self.tail(block_output)
out = F.avg_pool2d(tail_output, 7, stride=1).view(tail_output.size(0), -1)#平均池化
out = self.classifier(out)
return out欢迎大家在评论区批评指正,谢谢大家~