卷积神经网络-识别手写体数字

卷积

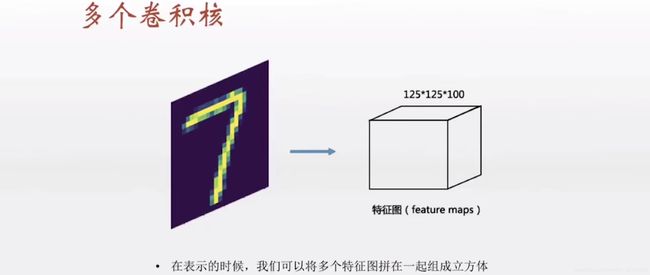
有多少个卷积核就可以做多少次卷积,从而得到多少个特征图,然后拼成立方体
池化操作->maxpooling
 再卷积
再卷积
这次的输入时上一次池化输出的特征值结果
再池化
Flatten() ->把特征图拉平,形成一个一维的向量,再以全连接的方式拼接一个前馈网络
logsoftmax层
数据加载器的建立
import torchvision.dataset as dsets
import torchvision.transforms as transforms
#定义数据集管理对象
train_dataset =dsets.MINIST(root='./data',#文件路径
train=True,#提取训练集
transform=transforms.ToTensor(),#将图像转换为Tensor
download=True)
test_dataset = dsets.MINIST(root='./data',
train=False,
transform=transform.ToTensor())
#数据集的加载
train_loader=torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader=torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=False)
构建数据集
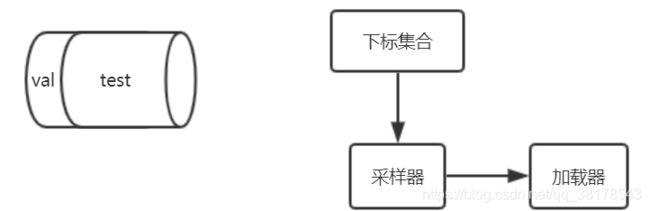
#首先,定义下标数组indices,它相当于对所有test_dataset中数据的编码
#然后定义下标indices_val来表示验证集数据的下班,indices_test表示测试集的下标
indices=range(len(test_dataset))
indices_val=indices[:5000]#5000之前是验证集
indices_test=indices[5000:]#5000之后是测试集
#根据这些下标,构造两个数据集的SubsetRandomSample采样器,采样器会对下标进行采样
sampler_val=torch.utils.data.sampler.SubsetRandomSample(indices_val)
sampler_test=torch.utils.data.sampler.SubsetRandomSample(indices_test)
#根据两个采样器来定义加载器,注意将sampler_val和sampler_test分别赋值给了validation_loader和test_loader
validation_loader=torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True,
sampler=sampler_val)
test_loader=torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True,
sampler=sampler_test)
卷积神经网络的实现
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet,self).__init__()
self.conv1=nn.Conv2d(1,4,5,padding=2)#(输入图片通道数,输出通道数即卷积核个数,卷积窗口的大小)
self.pool=nn.MaxPool2d(2,2)
self.conv2=nn.Conv2d(4,8,5,padding=2)
self.fc1=nn.Linear(image_size//4*image_size//4*8,512)#(输入单元数,输出单元数)
self.fc2=nn.Linear(512,num_classes)
def forward(self,x):#该函数在执行网络的前向传播的时候调用
x=F.relu(self.conv1(x))
x=self.pool(x)
x=F.relu(self.conv2(x))
x=self.pool(x)
x=x.view(-1,image_size//4*image_size//4*8)
x=F.relu(self.fc1(x))
x=F.dropout(x,traing=self.training)#防止过拟合,只在训练时使用,测试时不使用
x=self.fc2(x)
x=F.log_softmax(x)
return x
循环训练/测试
#循环训练
for epoch in range(num_epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data,target=Variable(data),Variable(target)
#模型在训练集上训练
net.train()#打开叫做training的内部变量,这时dropout生效,调用convNet的forward方法生效
output=net(data)#模型预测
loss=criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100==0
#打印和记录数据
#在验证集上测试
net.eval()#关闭叫做training的内部变量,dropout无效
val_rights=[]
for (data,target) in validation_loader: #这这里加入了验证集的验证过程
data,target=Variable(data),Variable(target)
output=net(data)#完成一次预测
val=rightness(output,target)
#在测试集上运行
net.eval()#关闭叫做training的内部变量,dropout无效
test.loss=0
correct=0
for data,target in test_loader:
data,target=Variable(data),Variable(target)
output=net(data)
val=rightness(output,target)
总结
可以将卷积过程理解为模板匹配
卷积核与特征图是一一对应的
池化操作是一个粗糙化原始图像的过程
dropout是一个防止过拟合的技术