10.基于ML的中文短文本分类
1.任务描述
司法数据,需求是对每一条输入数据,判断事情的主体是谁,比如报警人被老公打,报警人被老婆打,报警人被儿子打,报警人被女儿打等来进行文本有监督的分类操作。
整个过程分为以下几个步骤:
- 语料加载
- 分词
- 去停用词
- 抽取词向量特征
- 分别进行算法建模和模型训练
- 评估、计算 AUC 值
- 模型对比
基本流程:
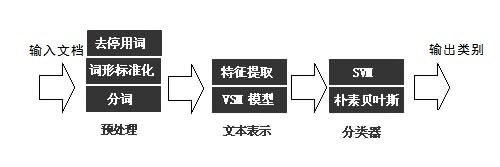
2.加载数据
import random
import jieba
import pandas as pd
ch_path = '动手实战基于ML的中文短文本分类/data/'
#加载停用词
stopwords=pd.read_csv(ch_path+'stopwords.txt',index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
stopwords=stopwords['stopword'].values
stopwords
#加载语料
laogong_df = pd.read_csv(ch_path+'beilaogongda.csv', encoding='utf-8', sep=',')
laopo_df = pd.read_csv(ch_path+'beilaopoda.csv', encoding='utf-8', sep=',')
erzi_df = pd.read_csv(ch_path+'beierzida.csv', encoding='utf-8', sep=',')
nver_df = pd.read_csv(ch_path+'beinverda.csv', encoding='utf-8', sep=',')
#删除语料的nan行
laogong_df.dropna(inplace=True)
laopo_df.dropna(inplace=True)
erzi_df.dropna(inplace=True)
nver_df.dropna(inplace=True)
#转换
laogong = laogong_df.segment.values.tolist()
laopo = laopo_df.segment.values.tolist()
erzi = erzi_df.segment.values.tolist()
nver = nver_df.segment.values.tolist()
定义分词、去停用词和批量打标签的函数,函数包含3个参数:content_lines 参数为语料列表;sentences 参数为预先定义的 list,用来存储分词并打标签后的结果;category 参数为标签。
3.分词、去停用词、批量打标签
#定义分词和打标签函数preprocess_text
#参数content_lines即为上面转换的list
#参数sentences是定义的空list,用来储存打标签之后的数据
#参数category 是类型标签
def preprocess_text(content_lines, sentences, category):
for line in content_lines:
try:
segs=jieba.lcut(line)
segs = [v for v in segs if not str(v).isdigit()]#去数字
segs = list(filter(lambda x:x.strip(), segs)) #去左右空格
segs = list(filter(lambda x:len(x)>1, segs)) #长度为1的字符
segs = list(filter(lambda x:x not in stopwords, segs)) #去掉停用词
sentences.append((" ".join(segs), category))# 打标签
except Exception:
print(line)
continue
# 调用函数,得到一个数据集sentences。
"""
调用函数、生成训练数据,根据我提供的司法语料数据,
分为报警人被老公打,报警人被老婆打,报警人被儿子打,报警人被女儿打,标签分别为0、1、2、3
"""
sentences = []
preprocess_text(laogong, sentences,0)
preprocess_text(laopo, sentences, 1)
preprocess_text(erzi, sentences, 2)
preprocess_text(nver, sentences, 3)
random.shuffle(sentences)
# 观察前10条数据
for sentence in sentences[:10]:
print(sentence[0], sentence[1])
4.抽取词向量特征
抽取特征,定义文本抽取词袋模型特征:
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(
analyzer='word', # 用字符符号标记
max_features=4000, # 保持最常见的 1000 ngrams
)
# 拆分数据集
from sklearn.model_selection import train_test_split
x, y = zip(*sentences)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1256)
# 把训练数据转换为词袋模型:
vec.fit(x_train)
# 查看一下
tmp = vec.transform(x_train)
print(tmp.shape)
5.进行算法建模和模型训练。
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(x_train), y_train)
6.评估、计算 AUC 值
print(classifier.score(vec.transform(x_test), y_test))
pre = classifier.predict(vec.transform(x_test))
0.9976133651551312
也就说整个过程有两个模型参与了训练。一个是词向量的训练,一个是业务模型(贝叶斯)的训练。
7.特征增强(N-gram模型,考虑词与词之间的顺序)
基于 sklearn 的词袋模型,尝试加入抽取 2-gram 和 3-gram 的统计特征,把词库的量放大,获得更强的特征。
把特征做得更强一点,尝试加入抽取 2-gram 和 3-gram 的统计特征,把词库的量放大一点。
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(
analyzer='word', # 用字符符号标记
ngram_range=(1,2), # 使用大小为1和2的ngrams
max_features=20000, # 保留最常见的 1000 ngrams
)
vec.fit(x_train)
#用朴素贝叶斯算法进行模型训练
classifier = MultinomialNB()
classifier.fit(vec.transform(x_train), y_train)
#对结果进行评分
print(classifier.score(vec.transform(x_test), y_test))
0.9785202863961814
# 改变训练模型,使用SVM
from sklearn.svm import SVC
svm = SVC(kernel='linear')
svm.fit(vec.transform(x_train), y_train)
print(svm.score(vec.transform(x_test), y_test))
0.9976133651551312