超分辨率重建DRCN
Deeply-recursive convolutional network for image super-resolution
引言
作者认为卷积神经网络感受野越大其可以利用的上下文信息就越多,那么就可以推理出更多的高频信息。提高感受野的方法:增加网络的深度(即增加卷积层的个数或者是增加池化层的个数。但是这两种方法都有缺点,卷积层引入了更多的参数,池化层丢失了一些关键信息)
感受野越大可以利用的上下文信息就越多
一般在图像复原这样的任务中,不会使用池化层。
引入卷积层会导致参数大,容易过拟合
基于此,作者提出了DRCN。重复的利用卷积层,参数不会增加,感受野变大。
但是用随机梯度下降方法会导致梯度爆炸/消失、Learning long-range
dependencies between pixels with a single weight layer is
very difficult.
减轻过拟合
- 递归监督。(每次递归后的特征图都用于图像重建。因为每次递归后产生的特征图都是不一样的,因此可以将不同级别的输出结合起来)
- 输入到重构的跳跃连接。(输入和输出是相似的)
相关工作
单图像超分辨率
However, this significantly increases the number of parameters and requires more data to
prevent overfitting. In this work, we seek to design a convolutional network that models long-range pixel dependencieswith limited capacity. Our network recursively widens the
receptive field without increasing model capacity
方法
基础模型
网络有三部分组成:
1 嵌入层。 将输入图像表示成一组特征图
2 推理层。
3 重建层。
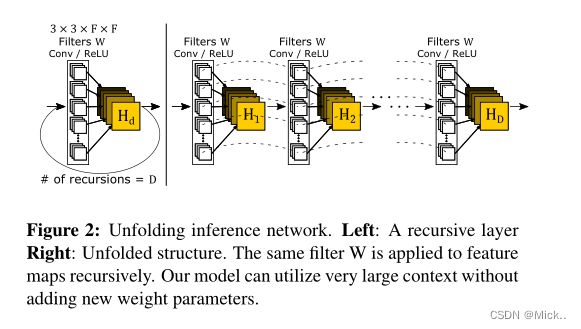
这种模型容易导致梯度消失/爆炸。
递归的数量难以确定。
梯度爆炸:训练过程中梯度范数大幅增加。这是因为的链式法则的连乘效应。
改进的模型
递归监督:
- 递归监督自然减轻了训练递归网络的难度。如果监督信号直接从损失层到早期递归,反向传播只经过少量层。将不同预测损失反向传播的所有梯度相加,可以得到平滑效果。消除了沿一条反向传播路径的消失/爆炸梯度的对抗效应
- 选择最优递归次数的重要性也降低了,因为我们的监督能够利用所有中间层的预测。如果递归对于给定的任务来说太深,我们预计后期预测的权重会较低,而早期预测的权重会较高
跳跃连接:
- 输入信号的可以精确的传递网络的尾端
- 输入和输出是高度相似的。因此很多图像都是对图像的细节进行预测

import torch
import torch.nn as nn
class Net(torch.nn.Module):
def __init__(self, num_channels, base_channel, num_recursions, device):
super(Net, self).__init__()
self.num_recursions = num_recursions
self.embedding_layer = nn.Sequential(
nn.Conv2d(num_channels, base_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(base_channel, base_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.conv_block = nn.Sequential(nn.Conv2d(base_channel, base_channel, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True))
self.reconstruction_layer = nn.Sequential(
nn.Conv2d(base_channel, base_channel, kernel_size=3, stride=1, padding=1),
nn.Conv2d(base_channel, num_channels, kernel_size=3, stride=1, padding=1)
)
self.w_init = torch.ones(self.num_recursions) / self.num_recursions
self.w = self.w_init.to(device)
def forward(self, x):
h0 = self.embedding_layer(x)
h = [h0]
for d in range(self.num_recursions):
h.append(self.conv_block(h[d]))
y_d_ = list()
out_sum = 0
for d in range(self.num_recursions):
y_d_.append(self.reconstruction_layer(h[d+1]))
out_sum += torch.mul(y_d_[d], self.w[d])
out_sum = torch.mul(out_sum, 1.0 / (torch.sum(self.w)))
final_out = torch.add(out_sum, x)
return y_d_, final_out
def weight_init(self):
for m in self._modules:
weights_init_kaiming(m)
def weights_init_kaiming(m):
class_name = m.__class__.__name__
if class_name.find('Linear') != -1:
torch.nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
m.bias.data.zero_()
elif class_name.find('Conv2d') != -1:
torch.nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
m.bias.data.zero_()
elif class_name.find('ConvTranspose2d') != -1:
torch.nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
m.bias.data.zero_()
elif class_name.find('Norm') != -1:
m.weight.data.normal_(1.0, 0.02)
if m.bias is not None:
m.bias.data.zero_()
损失函数
该网络有D个递归输出,所以存在D+1个目标函数需要去优化

实验
数据集
训练集采用91张图片
测试集采用Set5 [19] Set14 B100 Urban100
训练设置
递归使用了16次
我们设置动量参数为0.9,权重衰减为0.0001。
卷积层设置为256个3*3大小的。
训练集 以步长为21划分为41*41的图像块。
batchsize设置为64.
权值初始化
对于递归层: 所有权值偏置都为0,除了自连接
对于非递归层,使用 He 提出的初始化方法。
学习率最初设置为0.01,然后如果5个epoch的验证错误没有减少,学习率降低10倍。
当学习率小于10−6时,训练中止。
递归层数的影响

与其他算法的对比
对于基准测试,我们使用公共代码A+ [29], SRCNN [5], RFL[23]和SelfEx[10]。我们只像处理其他方法一样处理亮度分量。
