文本匹配、文本相似度模型之DRCN
本文是我的匹配模型合集的其中一期,如果你想了解更多的匹配模型,欢迎参阅我的另一篇博文匹配模型合集
所有的模型均采用tensorflow进行了实现,欢迎start,[代码地址]https://github.com/terrifyzhao/text_matching
简介
DRCN和DIIN的结构十分相似,包括输入层与特征提取层, DRCN在特征提取阶段结合了DenseNet的连接策略与Attention机制,在interaction阶段,也、采取了更加多样化的交互策略,接下来就为大家详细介绍一下。
结构
DRCN分为三层,word representation layer、attentively connected RNN与interaction and prediction layer,其最核心的结构还是在于attentively connected RNN,总体结构如下图所示
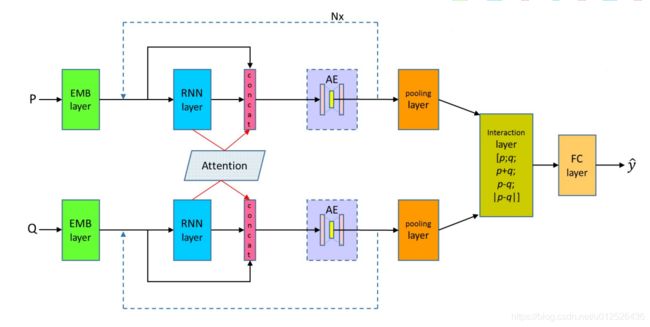
word representation layer
输入层包括四个部分,预训练的词向量,字向量与一个exact match flag,词向量采用w2v或glove,并且词向量还分为了静态与动态形式,静态形式即不修改预训练的词向量,动态形式是指根据当前任务动态调整embedding matrix,字向量采用的是embedding层来生成,然后过了一下卷积层和最大池化层,exact match flag是一个标志位,如果两个序列中有相同的词就标记位1,否则标记位0,最后将这四部分拼接起来。
p i = [ e p i t r ; e p i f i x ; c p i ; f p i ] p_i = [e_{p_i}^{tr};e_{p_i}^{fix};c_{p_i};f_{p_i}] pi=[epitr;epifix;cpi;fpi]
attentively connected RNN
本层也是该模型的关键所在,这里作者采用了5层BiLSTM堆叠在一起加上DenseNet的结构并循环了4次,我们详细看一下, l l l表示的是BiLSTM的层数, t t t表示的是时刻,其隐藏状态的值为:
h t l = H ( x t l , h t − 1 l ) x t l = h t l − 1 h_t^l = H(x_t^l,h_{t-1}^l) \\ x_t^l = h_t^{l-1} htl=H(xtl,ht−1l)xtl=htl−1
我们知道这样的结构在结构很深的时候很容易出现梯度消失或者梯度爆炸的情况,因此提出来了ResNet来解决这个问题,隐藏状态的值也变为了:
h t l = H ( x t l , h t − 1 l ) x t l = h t l − 1 + x t l − 1 h_t^l = H(x_t^l,h_{t-1}^l) \\ x_t^l = h_t^{l-1}+x_t^{l-1} htl=H(xtl,ht−1l)xtl=htl−1+xtl−1
然而残缺网络的结构也存在一定的弊端,其会阻碍信息在网络间的传递,因此DenseNet应运而生,其尾部不是相加的结构,而是拼接,这样既不阻碍信息的传递,也能保留原有信息,即使是第一层的输出值也能有效传递到最后一层,避免了防止梯度消失等问题,其隐藏状态为:
h t l = H ( x t l , h t − 1 l ) x t l = [ h t l − 1 ; x t l − 1 ] h_t^l = H(x_t^l,h_{t-1}^l) \\ x_t^l = [h_t^{l-1};x_t^{l-1}] htl=H(xtl,ht−1l)xtl=[htl−1;xtl−1]
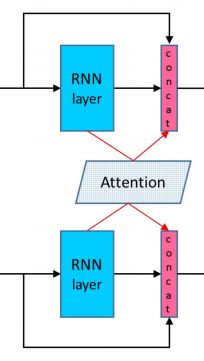
除了DenseNet的结构以外,这一层还引入了attention机制,attention在很多领域都取得了不错的成绩包括nlp。设经过BiLSTM之后的值为 h p i h_{p_i} hpi与 h h i h_{h_i} hhi,首先计算attention matrix,采用的是余弦相似度,然后经过softmax处理后计算出加权后的值,注意 p p p加权后的值是和 h h h相乘。
e i , j = c o s ( h p i , h h i ) α i , j = e x p ( e i , j ) ∑ k = 1 J e x p ( e i , k ) a p i = ∑ j = 1 J α i , j h h j e_{i,j} = cos(h_{p_i},h_{h_i}) \\ \alpha_{i,j} = \frac{exp(e_{i,j})}{\sum^J_{k=1}exp(e_{i,k})} \\ a_{p_i} = \sum^J_{j=1} \alpha_{i,j}h_{h_j} ei,j=cos(hpi,hhi)αi,j=∑k=1Jexp(ei,k)exp(ei,j)api=j=1∑Jαi,jhhj
此时,输入到下一层的值就是由三部分构成了,即下图红色部分所示,隐藏状态值为:
h t l = H ( x t l , h t − 1 l ) x t l = [ h t l − 1 ; a t l − 1 ; x t l − 1 ] h_t^l = H(x_t^l,h_{t-1}^l) \\ x_t^l = [h_t^{l-1};a_t^{l-1};x_t^{l-1}] htl=H(xtl,ht−1l)xtl=[htl−1;atl−1;xtl−1]
此时得到的值其实维度是很大的,并且参数量也很大,作者为了压缩维度加入了一个200个节点的autoencoder来降低维度。
interaction and prediction layer
本层的内容就很简单了,首先把上一层得到的值经过最大池化层,然后池化后的结果做一个相关处理,作者采用了三种关联策略,分别是对位相加,对位相减,对位取模,并和原来的值拼接在一起。
v = [ p ; h ; p + h ; p − h ; ∣ p − h ∣ ] v = [p;h;p+h;p-h;|p-h|] v=[p;h;p+h;p−h;∣p−h∣]
最后把得到的结果送入2个带relu激活函数的全连接层1个不带的全连接层和softmax层。
小结
DRCN在我看来就是DIIN的一个增强版本,把DIIN每一个模块的结构都变得更加复杂化。这也反应出了目前深度学习论文的一个现状,在没有理论支撑下,只要少量的结构改动参数就会变多,在保证不过拟合的情况下必然能对结果有进一步提升,希望在未来能看到更多像transformer这样的网络结构,而不是简单的组件模块堆砌。
参考文献
Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information