YOLO-v4
yolo更新了最新的v4版本,这几天有关目标检测方面的公众号推送的全是关于yolo-v4的内容,趁热打铁,赶紧来了解一下性能强劲的yolo-v4!
这个版本的作者是Alexey Bochkovskiy,4.24这天放出了所有的源码和论文,其他内容什么的先不说,先赞一个开源万岁!原作者JosephRedmon在早前发文称自己要退出CV圈,原因是yolo的工作被应用到了军事武器以及侵犯大众隐私的其他商业软件中,自己的内心受到了很大的折磨,在内心不安中经过了众多考虑后决定退出CV圈。
乍一看觉得这个大神有点矫情,但是深思后觉得这个事情并不简单,或许是我们这些CV小白们把事情考虑的太简单了。CV对我们的影响有这么大么?
仔细一想,还真是!
随着计算机硬件水平的提高以及价格的走低,大街上出现了随处可见的摄像头,甚至我家里面都安装两个摄像头用来防盗(一个放在门外监控楼道,另外一个安在客厅)。一张无形的网笼罩了我们整个社会,我们的每个举动都有可能被监视,而监视我们的不一定是坐在另一头显示器前扣脚的大汉,有可能就是我们一直在致力于发展的CV。通过目标检测结合ip地址可以给每个人打上标签,标签内容甚至可以包括家庭关系,之后再通过街头巷尾的摄像头进行reID以及人体关键点识别,我们的所有行径所有动作都会被记录下来,有了这些数据分析出消费习惯、消费能力应该不是什么难事,当然如果仅仅是用于这些的话还好,只不过多了些定向投放的广告,如果这些数据被不坏好意的人如诈骗的人看到呢,他们也可以进行定向犯罪了,想想就后怕,一会儿就把客厅的摄像头拆了。
在战场上,更准确更快的目标检测算法可以让打击更加精确,凭人类的腾挪躲闪几乎无法躲避,这种要你三更死绝活不到五更的阎罗式打击可以让现代战争发展到另外一种可怕的境地,想想又后怕了。看到自己的学术成果被这样利用,JosephRedmon的心里很难受,这点是可以理解的。
不跑题了,进入正文。
继承了Ross Girshick的衣钵,Alexey Bochkovskiy继续将yolo发扬光大,利用了近两年出现的众多tricks来改进yolov-3,同时做了一点创新,将MS COCO数据集上的state-of-the-art提升到了43.5%AP(65.7% A P 50 AP_{50} AP50),速度达到了65 FPS (Tesla V100)。

为了方便众多计算条件有限的学习者,发布的代码及训练策略都是基于单GPU的,能够更好地推进YOLO在更多领域的应用。这篇论文偏向于工程实践的总结,事无巨细地记录了实验的过程,众多的实验数据可见作者投入的精力有多大。
作者将检测网络的结构分成了几个部分:分别是骨干
-
输入
-
骨干
-
脖子
-
头
其中输入就是图片,也可能是图一张图片的不同分辨率组成的图片金字塔
骨干是各种特征提取网络,包括resnet、vgg等基础网络。
脖子是对feature map做操作,包括对特征层加权重或重排序等,论文中提出的是FPN、PANet、Bi-FPN等
头就是各种目标检测网络的检测方法,分为基于anchor的和anchor-free两种,本文将检测方法分为两种:密集预测和稀疏预测,密集预测包括YOLO和SSD、cornernet等,这些方法都为每个位置处预测了多个尺寸的检测框,不同于密集预测,稀疏预测已经对候选的框做了筛选,候选框的数量比较少。
作者利用了近年来效果很好的tricks,包含了大量的论文。作者将这些方法分为两类:
-
Bag of freebies
这类tricks主要在不增加前向推理时间的前提下提升检测准确率,故称free,不用白不用
包括:
-
数据增强
- CutOut
- random erase
- MixUp
- GAN
-
难例处理
- 难例挖掘
- focal loss
-
loss形式
- IOU,代替 L 1 l o s s L_1 loss L1loss和 L 2 l o s s L_2 loss L2loss,能够实现尺度的统一
- GIOU,反应检测框的相交形式
- DIOU,反应检测框之间的距离
- CIOU,在DIOU基础上加入影响因子,表现最好的IOU loss
-
标签处理
- 标签平滑
-
-
Bag of specials
这类方法是牺牲很少的前向推理时间提升检测准确率。
主要包括对feature map的一些操作,包括SPP、SE、SAM等;此外还有激活函数的类型,包括ReLU系列,Swish和Mish;NMS的形式也采用了众多的形式,如DIOU NMS和soft NMS.
有了这么多的备选方法,作者做了以下选择:
基础网络: CSPDarknet53
Additional blocks:FPN,PAN,ASFF,BiFPN
激活函数:ReLU, leaky-ReLU, parametric-ReLU,ReLU6, SELU, Swish, or Mish
检测框回归:MSE,IoU,GIoU,CIoU,DIoU
数据增强:Cutout,MixUp,CutMix
防过拟合方法: DropOut, DropPath,spatial DropOut或者DropBlock
Normalization:BN,CBN,Cross-GPU BN
跳跃连接: Residual connections, Weighted residual connections, Multi-input weighted residual
connections, or Cross stage partial connection
作者的创新:
1.数据增强方法Mosaic,将四张图片拼成一张,增加单GPU的显存利用率,提升单GPU的训练能力。 还利用了Self-Adversarial Training。
2.优化超参数(严格不算创新吧)
3.对现有的方法做了改进,更时候单GPU训练,包括SAM,PAN,Cross mini-batch BN。

最后的yolov4选择了下面结构:
1.Backbone:CSPDarknet53
2.Neck:SPP,PAN
3.head:YOLOv3
作者做了非常详实的实验,花费了大量的精力。
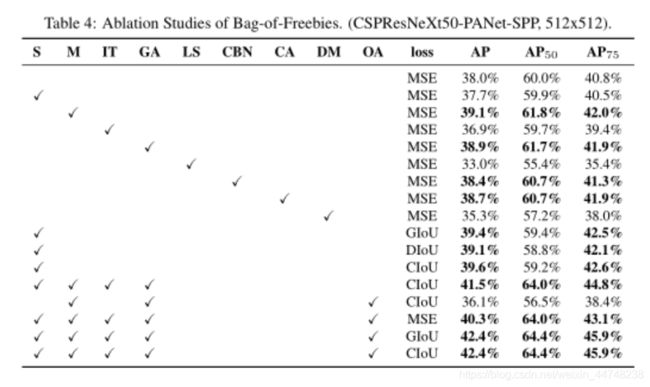
上述的S,M等是各种方法的简称,


然后作者与现有的几乎所有检测模型都做了对比,


