DRCN(Deeply-Recursive Convolutional Network for Image Super-Resolution)超分辨网络-详细分析
对超分有兴趣的同学们可直接关注微信公众号,这个号的定位就是针对图像超分辨的,会不断更新最新的超分算法解读。
正文开始
Contents
- 1. Introduction
- 2. Related Work
-
- 2.1. Single-Image Super-Resolution
- 2.2. Recursive Neural Network in Computer Vision
- 3. Proposed Method
-
- 3.1. Basic Model
- 3.2. Advanced Model
- 3.3. Training
- 4. Experimental Results
-
- 4.1. Datasets
- 4.2. Training Setup
- 4.3. Study of Deep Recursions
- 4.4. Comparisons with State-of-the-Art Methods
- References
1. Introduction
这篇文章的作者和VDSR的作者完全相同。Jiwon Kim等。
通过增加循环可以增加网络深度,进一步增加网络的感受野尺寸。利用循环的好处是可以避免引入新的参数。但使用深度网络可能使得梯度爆炸和消失,为了避免这一问题,作者提出了两个方法:循环监督和跳层连接。
我们已经在VDSR中提到过感受野的重要性、LR与HR共享大量相同的信息这些事实了,这篇文章又一次提到了,划重点。另外说一下增加感受野的方式:增加kernel的size和网络深度。在这篇文章中,作者提到,欲增加receptive field需增加conv层和pool层,很明显都是在网络深度上下功夫。但增加conv会引入更多的参数,增加pool会丢失更多的像素信息导致重建图像丢失细节(因此图像重建类的工作都不使用pool)。因此我们只能考虑用conv增加网络深度,但过大的网络又会导致两个问题:需要用大量的数据来避免过拟合、网络模型的存储和加载困难。
由此就引出了用相同的循环层(16次)来代替不同的卷积层,这样既能提高网络深度,又不会引入过多的参数,网络结构也不复杂。
DRCN的主要贡献:为了解决DRCN使用SGD难以收敛的问题(原因是梯度爆炸消失问题、网络长期信息记忆问题),提出了解决方案:循环监督(每次循环后都与重建层直接连接)和跳层连接(共享低频信息)。在重建SR阶段,使用了自集成的方法!
2. Related Work
2.1. Single-Image Super-Resolution
常见的SR方法:邻域嵌入、稀疏编码、卷积网络、随机森林。对比与SRCNN,SRCNN中运用了卷积层的简单堆叠,增加了参数量,同时,需要用大量的数据来训练网络避免过拟合。
2.2. Recursive Neural Network in Computer Vision
作者提出使用单层网络进行16层循环的思想,加深了循环深度,证明了深度循环能够提升网络性能。
3. Proposed Method
3.1. Basic Model
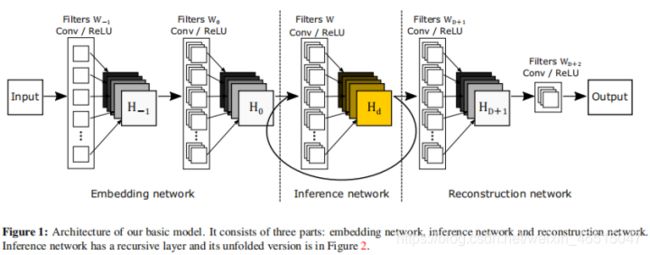
整个网络可以分为3个子网络:嵌入、推理、重建。早期使用dl方法的网络大致都遵循同样的思路:即子网络1先对LR提取特征(图)(指定通道数),然后子网络2再对提取到的LR特征图进行SR,得到SR图像,最后利用子网络3按照HR图像尺寸,对SR图像进行重建。
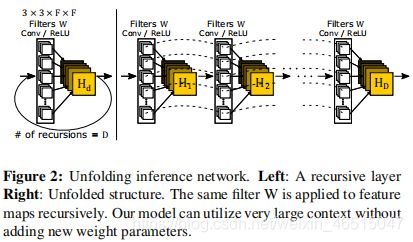
嵌入网络的任务是将输入的单/三通道图表征为指定通道数的特征图。推理网络是进行SR过程的关键组成(如图2所示),推理网络使用循环操作,每次循环都使用同样的卷积核及relu激活。通过使用尺寸大于1的核,随着循环的不断加深,感受野的范围越来越大。重建网络将多通道的特征图转回输入图像的形状(单/三通道)。三个子网络使用的卷积核尺寸均为3X3。
Mathematical Formulation网络仍然没有克服预插值的缺陷,然是在输入网络前对LR进行插值为HR尺寸。y△=f(x),x为插值后的LR图像,y△为SR图像,f表示整个网络映射。f又可分为f1,f2,f2分别表示嵌入、推理、重建三部分。所以f=f3(f2(f1(x)))。
嵌入网络f1,输入为LR图像x,输出为H0,中间隐藏层的输出为H-1。其中max意味着relu操作,网络可表示如下:
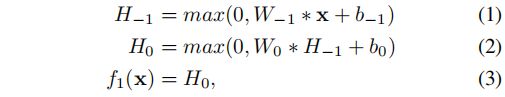
推理网络f2,输入为H0输出为HD,g表示任一次循环的映射过程,D表示循环次数。由上文可知,每次循环的权重w和偏置b都相同。其中的一次循环可表示为:
![]()
推理网络的整个循环可表示为:
![]()
重建网络f3,输入为HD(即抽象的SR),输出为目标图像(即和HR有同样形状的SR),隐藏层的输出为HD+1。重建网络可视为嵌入网络的逆操作,表示如下:

整个模型的性质如下:循环层的弊端是因为循环过深而导致训练困难,而导致这一结果的原因如下:
梯度的爆炸和消失。关于梯度爆炸,是因为由于过深的网络,导致梯度链不断相乘,在偏导大于一的情况下,多级相乘必将导致梯度爆炸(我是不是说的有些绝对了)。而梯度消失,是因为网络的长期传输,梯度以指数形式衰减。因此长距离的像素学习非常困难。
不仅如此,由于整幅图像都在网络中进行传输,这就牵扯到了网络的记忆能力和传输过程中的信息丢失,但是LR和HR图像的低频信息又是相同的,这就设计到了残差学习的思想。
循环层的深度也是值得讨论的问题。
3.2. Advanced Model
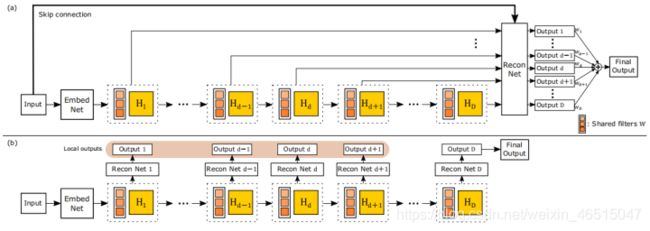

Recursive-Supervision 旨在解决梯度爆炸和消失的问题,提出了监督各层循环的思想,使网络能够直接监督各循环层,提升效率(如图3a)。使用每次循环的输出直接与重建层相连,最终得到D个重建SR图像,在对这D幅SR图像进行加权求和,即可获得最终的重建SR图像。这里的加权求和的权重也是网络根据数据学习得到的。
作者还比较了自己的循环监督和深度监督(如图3b)的区别和利弊。
深度监督需要对每次循环分别使用不同的重建层(D个),对图像进行重建,实现循环监督,但这会引入新的参数,有悖于使用循环卷积的初衷(即限制参数量),另外会导致网络效率降低。
深度监督在测试时会摒弃前D-1个重建层的重建图像,也就是说前D-1个重建层的参数在测试阶段并不起作用。
作者提出的方案在网络梯度进行反向传播时,每层梯度来源于两个方面:1. 直接有重建层传来的;2. 由重建层经过多次循环层传来。由于进行循环监督,所以循环的深度在梯度问题上显得不那么重要。
如果各循环层的参数没有共享,则网络的参数会急剧增长,如图3c所示。
Skip-Connection 因为LR和HR之间的低频结构信息一致,所以可以考虑直接通过跳层连接将LR信息直接传输到SR重建层。这样做的两个优势是:1. 节省了信息长距离传输的算力;2. 可以更精确的复现低频结构。通过跳层连接,可以明显提升学习过程。
Mathematical Formulation 整个网络(图3a)的函数可以描述如下:
![]()
表示对来自于特征提取层的结果f1(x)进行d次循环g,然后在于LR图像进行运算,得到最终SR图像。而f3函数作者表述为:f3(x,Hd) = x + f2(Hd)。并且提出如何将得到的高频细节和LR图像x相融合是值得探索的。最后对来自个循环层的重建图像进行加权求和,遵循如下准则,其中权重是学习得到的:
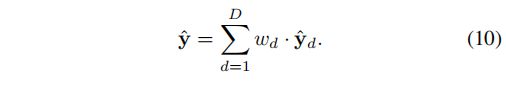
3.3. Training
仍然是以提升PSNR为目标,循环层的损失函数如下:

其中d表示循环层深度,N表示batch size。
重建层的损失函数如下:

同样是以优化MSE为基础的。
总的训练损失函数使用权重衰减(L2惩罚)的正则化操作:
![]()
其中β代表权重衰减系数,α越大,早期的循环层训练越稳定,而在训练后期,减小α可以使得网络性能提高。
4. Experimental Results
这部分主要描述了训练数据集、训练设置、循环次数、以及与SOTA的比较。
4.1. Datasets
训练使用91数据集,测试使用set5、set14、B100、Urban100.
4.2. Training Setup
设置循环次数为16,当展开循环时,整个网络有20层卷积
感受野的范围:41X41
SGD中的动量参数:0.9
权重衰减系数β:0.0001
网络中滤波器的尺寸均为:3X3X256
patch size:41X41
batch size:64
权重初始化:使用何凯明论文中的方法,而循环层的权重和偏置均设置为0
学习率:0.01,若5个epoch后loss没有下降,则学习率缩小10倍,若5个epoch后loss下降了,则保持之前学习率。若学习率低于0.000001,训练终止。
最终网络在Titan X GPU训练了6天。
4.3. Study of Deep Recursions
图8反映了随循环层加深,PSNR的变化情况,可以看到,循环加深,PSNR越来越大,但似乎文章中的图并不能完全反映PSNR随循环深度的变化情况,因为图像末端,折线仍是上升趋势。

图9反映了循环层中间层的重建结果和最终集成过(ensemble)的网络的重建结果的对比。

4.4. Comparisons with State-of-the-Art Methods
A+、RFL等方法和SRCNN一样,都不能预测图像的边缘像素。
表1给出了不同数据集下的各方法的数据对比结果
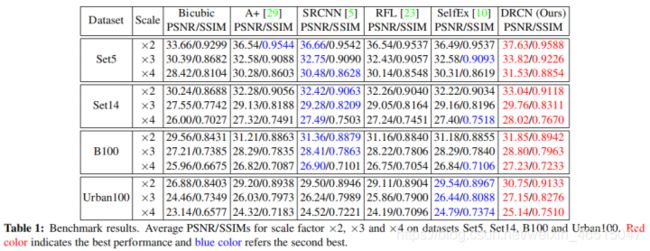
图4、5、6、7是实际图像的不同方法的对比结果图:




References
- DRCN超分辨网络-详细分析