【莫烦Python】机器要说话 NLP 自然语言处理教程 W2V Transformer BERT Seq2Seq GPT 笔记
【莫烦Python】机器要说话 NLP 自然语言处理教程 W2V Transformer BERT Seq2Seq GPT 笔记
- 教程与代码地址
- P1 NLP行业大佬采访
- P2 NLP简介
- P3 1.1 课程目标
- P4 2.1 搜索引擎简介
- P5 2.2 搜索引擎算法(TF-IDF 检索)
- P6 2.3 Sklearn 搜索的扩展
- P7 3.1 词向量可以这样理解
- P8 3.2 训练词向量 W2V CBOW算法
- P9 3.3 词向量Skip Gram 算法
- P10 4.1 理解句子 句向量
- P11 4.2 Seq2Seq 语言生成模型
- P12 4.3 CNN也能理解语言
- P13 5.1 注意力 语言模型
- P14 5.2 Attention 注意力算法
- P15 5.3 请注意 注意力
- P16 5.4 Transformer 自注意语言模型
- P17 6.1 大规模预训练模型
- P18 6.2 一词多义 ELMo
- P19 6.3 GPT 单向语言模型
- P20 6.4 BERT 双向语言模型
- P21 7.1 语言模型的应用
教程与代码地址
笔记中,图片和代码基本源自up主的视频和代码
视频地址: 【莫烦Python】机器要说话 NLP 自然语言处理教程 W2V Transformer BERT Seq2Seq GPT
代码地址: https://github.com/MorvanZhou/NLP-Tutorials
讲义地址:https://mofanpy.com/tutorials/machine-learning/nlp/
如果想要爬虫视频网站一样的csdn目录,可以去这里下载代码:https://github.com/JeffreyLeal/MyUtils/tree/%E7%88%AC%E8%99%AB%E5%B7%A5%E5%85%B71
P1 NLP行业大佬采访
动手敲代码,复现代码,做项目最重要
P2 NLP简介
将文本转化成一串数字(encode),然后让机器去理解,再生成一串数字,再转化成文本(decode)。
P3 1.1 课程目标
P4 2.1 搜索引擎简介
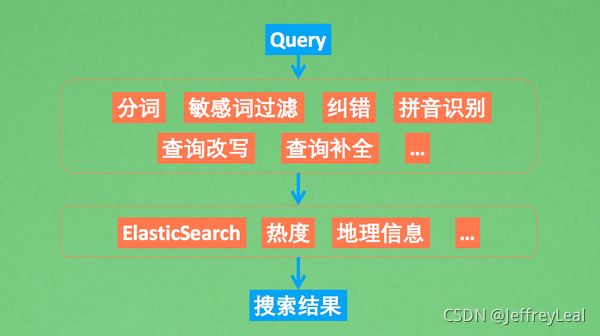
在一篇文章可以被搜索之前,搜索引擎安排小蜘蛛spider爬取网页重点部分,分别对待,比如重点关注标题、时间、正文。将这些信息给予不同的权重后,存储在便于快速检索的数据库中。
传统的构建索引方法:索引图片视频等是基于它周围的文字信息,如标题等。
深度学习的构建索引方法:在用户用文字搜索时,将搜索的文字内容转换成深度学习能识别的数字内容,然后再和之前存储的图片、视频数字信息进行匹配,对比两种数字之间的关联性,然后找到最相近的内容。这种搜索,我们有一个专业名词叫作"多模态"搜索。
批量召回,粗排数据量都非常大,精排的数据量小,适合用深度学习
 假设你开了家咨询公司,手上有100篇材料。这时有人来找你咨询NLP的问题,你会怎么在这100篇材料中找到合适的内容呢?
假设你开了家咨询公司,手上有100篇材料。这时有人来找你咨询NLP的问题,你会怎么在这100篇材料中找到合适的内容呢?
正排索引:我们一篇一篇地阅读,找到所有包含NLP内容的材料,然后返回给提问者。
缺点:这种方法需要我们在每次搜索的时候,都对所有材料进行一次阅读,然后在材料中找到关键词,并筛选出材料,效率其实非常差。
倒排索引:我们在第一次拿到所有材料时,把它们通读一遍,然后构建关键词和文章的对应关系。当用户在搜索特定词的时候,比如“红”,就会直接返回“红”这个【关键词索引】下的文章列表。
优点:能够将这种索引,放在后续的搜索中复用,搜索也就变成了一种词语匹配加返回索引材料的过程。
问题:但当处理的是海量数据的时候,通过倒排索引找到的文章可能依然是海量。
解决:对这些文章进行排序操作,再选取排名靠前的文章列表也能帮我们节省大量的时间。处理匹配排序,最有名的算法之一叫做TF-IDF。
TF-IDF用于粗排

TF是词频,计算词在当前文章中出现的频率,频率越高,越能代表文章

但像“我”、“是”这种词也很高频,这时候就需要IDF了。
IDF是逆文本频率指数,计算词在这么多篇文章中出现的频率的倒数,在多篇文章都出现,频率就越高,频率的倒数就越小,表示这个词在多篇文章中没有区分度;只在少数的文章中出现,甚至只在一篇文章中出现,频率就越低,频率的倒数就越大,表示这个词在多篇文章中有很高的区分度,能代表这篇文章。
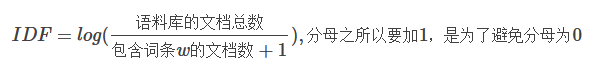 结合TF和IDF就是TF-IDF了
结合TF和IDF就是TF-IDF了
![]()
P5 2.2 搜索引擎算法(TF-IDF 检索)
代码见tf_idf.py,这个是up自己写的
写路径的时候,字符串最好使用原始字符串,即
str = r‘./image/xxx.jpg’
P6 2.3 Sklearn 搜索的扩展
代码见tf_idf_sklearn.py,可以使用sklearn现成的方法去写
全局指的事数据库的全局,不是互联网的全局
Query -> 搜索词标准化 -> 搜索算法 -> 搜索结果
P7 3.1 词向量可以这样理解
P8 3.2 训练词向量 W2V CBOW算法
代码见CBOW.py
词仅在词向量空间进行相加,而没有在前后文空间进行相加,相比之下,Skip Gram更好。
P9 3.3 词向量Skip Gram 算法
代码见skip-gram.py
CBOW和Skip Gram都没有办法处理一词多义的问题。
P10 4.1 理解句子 句向量
简而言之,Encoder负责理解上文,Decoder负责将思考怎么样在理解的句子的基础上做任务。这一套方法就是在自然语言处理中风靡一时的Seq2Seq框架。
P11 4.2 Seq2Seq 语言生成模型
代码见seq2seq.py
decoder预测

在使用GreedyEmbeddingSampler()作为decode的方法是有局限性的,有时候会因为忽略了前期的低分数而错过了后期的整体高分策略, 类似于前面芝麻最好,所以捡了芝麻,但后面却错过了捡西瓜的机会。而这种因局部信息不全而导致的策略不优,可以靠Beam search的筛选策略弥补。 如果使用 beam search, 我们不仅仅关注当前最优策略, 而且每预测一个词时,还保持关注当时刻所有候选词的N个最优策略,结束预测时,就有很大概率能够找到全局比较优的路径。 举个例子,如果我们用beam search size = 2, 意味着每次预测都记录最优的两个预测,然后沿着这两个预测继续预测, 每次后续的预测都只挑选下一步最好的两个预测。 这样加大了搜索范围,使我们有机会接触到全局较优路径。
P12 4.3 CNN也能理解语言
代码见cnn-lm.py
CNN做句向量encoding的时候有一个局限性,它要求有个句子最长的限制,句子如果超过这个长度,那么就最好截断它。 因为就像在给图像做卷积,图像也是要定长定宽的,不然卷积和池化会有尺度上的问题。这是一个相比RNN的硬伤。之后我们在介绍Transformer类型的语言模型时, 也会介绍到这个硬伤。
P13 5.1 注意力 语言模型
P14 5.2 Attention 注意力算法
P15 5.3 请注意 注意力
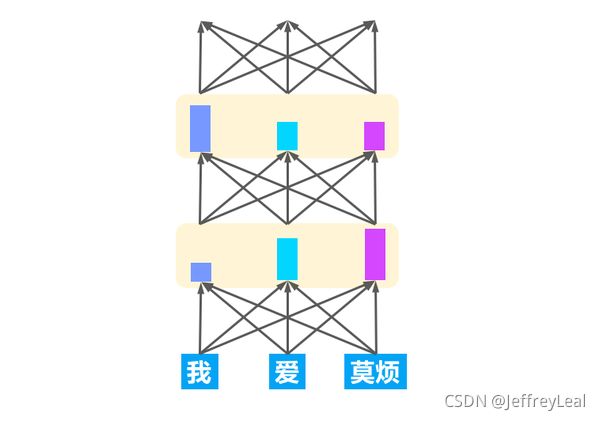
Transformer模型:多层注意力的叠加,它使用的是一个个注意力矩阵来表示在不同位置的注意力强度。通过控制强度来控制信息通道的阀门大小。
P16 5.4 Transformer 自注意语言模型
代码见transformer.py
P17 6.1 大规模预训练模型
P18 6.2 一词多义 ELMo
代码见ELMo.py
ELMo对你来说,只是另一种双向RNN架构。ELMo里有两个RNN(LSTM), 一个从前往后看句子,一个从后往前看句子,每一个词的向量表达,就是下面这几个信息的累积:
- 从前往后的前文信息;
- 从后往前的后文信息;
- 当前词语的词向量信息。
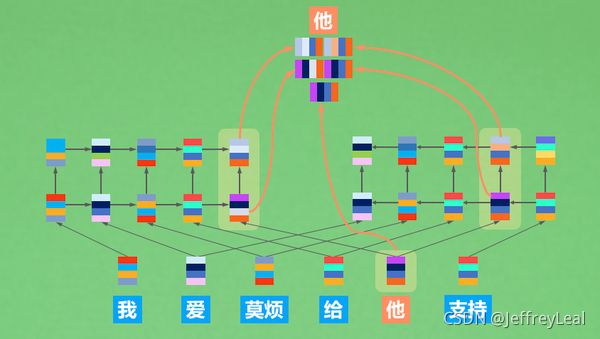
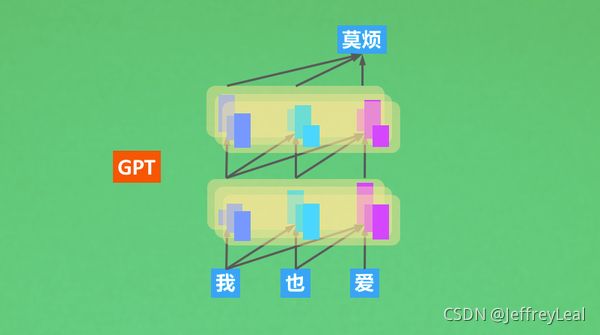
P19 6.3 GPT 单向语言模型
代码见GPT.py
GPT 单向语言模型