118云原生编程语言Golang学习笔记
Golang学习笔记
文章目录
- 1.Go简介
-
- 1.1 简介
- 1.2 设计初衷
- 1.3 Golang vs Java
- 1.4 应用领域
- 1.5 用go语言的公司
- 2.Go下载和安装
-
- 2.1 开发工具
- 2.2 Go下载
- 2.3 Go安装
- 2.4 Idea安装go插件
- 2.5 DOS命令
- 3.基础语法
-
- 3.1 Go执行流程
-
- 3.1.1 Go基本目录结构
- 3.1.2 第一个HelloWord
- 3.1.3 编译teset.go
- 3.1.4 执行test.ext
- 3.1.5 编译+执行
- 3.1.6 Golang执行流程
- 3.2 标识符
- 3.3 语法注意事项
- 3.4 注释
- 3.5 代码风格
- 3.6 API
- 3.7 关键字
- 4.变量与基本数据类型
-
- 4.1 整数类型
- 4.2 浮点类型
- 4.3 字符类型
- 4.4 布尔类型
- 4.5 字符串类型
- 4.6 基本数据类型默认值
- 4.7 基本数据类型转换
- 4.8 基本类型转为string
- 4.9 string转为基本类型
- 4.10 go变量
- 4.11 指针
- 5.运算符
-
- 5.1 算术运算符
- 5.2 赋值运算符
- 5.3 关系运算符
- 5.4 逻辑运算符
- 5.5 位运算符
- 5.6 其他运算符
- 5.7 运算符的优先级别
- 6.流程控制
-
- 6.1 if分支
- 6.2 switch分支
- 6.3 for循环
- 6.4 关键字
-
- 6.4.1.break
- 6.4.2 continue
- 6.4.3 goto
- 6.4.4 return
- 7.函数和包
-
- 7.1 为什么要使用函数
- 7.2 函数的定义
- 7.3 基本语法
- 7.4 函数的调用案例
- 7.5 包
-
- 7.5.1 使用包的原因
- 7.5.2 案例展示包
- 7.6 init函数
- 7.7 匿名函数
- 7.8 闭包
- 7.9 defer
- 7.10 系统函数
- 7.11 日期和时间相关函数
- 7.12 内置函数
- 7.13 错误处理
- 8.数组和切片
-
- 8.1 练习引入
- 8.2 数组解决练习
- 8.3 内存分析
- 8.4 数组的遍历
- 8.5 数组的初始化方式
- 8.6 数组的注意事项
- 8.7 二位数组
-
- 8.7.4 二维数组的初始化
- 8.7.5 二维数组的遍历
- 8.8 切片
-
- 8.8.1 切片介绍
- 8.8.2 代码
- 8.8.3 切片内存分析
- 8.8.4 切片的定
- 8.8.5 切片的遍历
- 8.8.6 注意事项
- 8.8.7 切片的拷贝
- 9.map
-
- 9.1 map介绍
- 9.2 map基本语法
- 9.3 代码
- 9.4 map的创建方式
- 9.5 map的操作
-
- 9.5.1 增加和更新操作
- 9.5.2 删除操作
- 9.5.3 清空操作
- 9.5.4 查找操作
- 9.5.5 获取长度
- 9.6 遍历:for-range
- 9.7 加深难度
- 10.面向对象
-
- 10.1 面向对象的引入
- 10.2 结构体
-
- 10.2.1 结构体的引入
- 10.2.2 代码
- 10.2.3 内存分析
- 10.2.4 结构体实例创建方式
- 10.2.5 结构体之间的转换
- 10.3 方法
-
- 10.3.1 基本介绍
- 10.3.2 方法的声明和调用
- 10.3.3 方法快速入门
- 10.3.4 方法的调用和传参机制原理
- 10.3.5 方法的声明(定义)
- 10.3.6 方法注意事项和细节讨论
- 10.3.7 课堂练习题
- 10.3.8 方法和函数的区别
- 10.4 面向对象编程应用实例
-
- 10.4.1 步骤
- 10.4.2 学生案例
- 10.5 工厂模式
-
- 10.5.1 结构体首字母小写
- 10.5.2 字段首字母小写
- 10.6 封装
-
- 10.6.1 封装介绍
- 10.6.2 封装的理解和好处
- 10.6.3 如何体现封装
- 10.6.4 封装的实现步骤
- 10.6.5 快速入门案例
- 10.7 继承
-
- 10.7.1 为什么需要继承
- 10.7.2 继承介绍
- 10.7.3 基本语法
- 10.7.4 快速入门案例
- 10.7.5 继承的好处
- 10.7.6 继承的深入讨论
- 10.7.7 课堂练习
- 10.7.8 多重继承
- 10.8 接口
-
- 10.8.1 接口介绍
- 10.8.2 为什么需要接口
- 10.8.3 接口快速入门
- 10.8.4 接口语法
- 10.8.5 接口应用场景
- 10.8.6 注意实现和细节
- 10.8.7 课堂练习
- 10.8.8 接口最佳实践
- 10.8.9 接口和继承的比较
- 10.9 多态
-
- 10.9.1 基本介绍
- 10.9.2 快速入门
- 10.9.3 接口体现多态特征
- 11.Go并发
-
- 11.1 goroutine引入
- 11.2 goroutine基本介绍
-
- 11.2.1 进程和线程说明
- 11.2.2 示意图
- 11.2.3 并发和并行
- 11.2.4 Go主线程和Go协程
- 11.3 goroutine快速入门
-
- 11.3.1 案例说明
- 11.3.2 快速入门小结
- 11.4 goroutine调度模型
-
- 11.4.1 MPG模式基本介绍
- 11.4.2 MPG模式运行的状态1
- 11.4.3 MPG模式运行的状态2
- 11.5 设置Golang运行的cpu数
- 11.6 channel管道
-
- 11.6.1 不同的goroutine之间如何通讯
- 11.6.2 全局变量的互斥锁
- 11.6.3 为什么需要channel
- 11.6.4 channel的基本介绍
- 11.6.5 定义/声明channel
- 11.6.6 管道的操作
- 11.6.7 channel使用的注意事项
- 11.6.8 案例演示
- 11.6.9 channel的关闭
- 11.6.10 channel的遍历
- 11.6.11 协程配合channel案例
- 11.6.12 协程配合channel阻塞
- 11.6.13 协程求素数
- 11.6.14 channel使用细节
- 11.6.11 协程配合channel案例
- 11.6.12 协程配合channel阻塞
- 11.6.13 协程求素数
- 11.6.14 channel使用细节
1.Go简介
1.1 简介
Go(又称Golang Go语言)是Google的Robert Griesemer,Rob Pike及Ken Thompson(C语言)开发的一种计算机编程语言。
Golang,也叫Go语言,也简称Go. 3个名字,1个意思。
Go语言是谷歌推出的一种编程语言,可以在不损失应用程序性能的情况下降低代码的复杂性。谷歌首席软件工程师罗布派克(Rob Pike)说:我们之所以开发Go,是因为过去10多年建软件开发的难度令人沮丧。派克表示,和今天的C++或C一样,Go是一种系统语言。他解释道,“使用它可以进行快速开发,同时它还是一个真正的编译语言,我们之所以现在将其开源,原因是我们认为它已经非常有用和强大。”
2007年开发第一版。
罗伯特.格瑞史莫(Robert Griesemer)、罗伯派克(Rob Pike)、肯.汤普逊(Ken Thompson)于2007年9月开始设计Go,稍后lan Lance Taylor、Russ Cox加入项目。
肯.汤普逊(Ken Thompson)==:unix设计者 C语言发明者 B语言发明者 飞行员 83年 图灵奖 美国工程院院士
罗伯派克(Rob Pike): utf-8格式 射箭(奥运会奖牌)
罗伯特.格瑞史莫(Robert Griesemer):
发展简史:
2007年 开始设计
2009年11月 Google将Go语言以开放源代码的方式向全球发布
2015年8月,Go1.5版本发布,本地更新中移除了“最后参与的c代码”
2017年2月,Go语言Go1.8版本
2017年8月,Go语言Go1.9版本
2018年2月,GO语言Go1.10版本
2018年8月,Go语言Go 1.11版本
2019年2月,Go语言Go1.12版本
2019年9月,Go语言Go1.13版本
2020年2月,Go语言GO1.14版本
2020年8月,Go语言Go1.15版本
…一直迭代
Go语言吉祥物:金花鼠

1.2 设计初衷
(1)计算机硬件技术更新频繁,性能提高很快。目前主流的编程语言发展明显落后于硬件,不能合理利用多核多CPU的优势提升软件性能。
(2)软件系统复杂度越来越高,维护成本越来越高,目前缺乏一个足够简洁高效的编程语言。
(3)企业运行维护很多的C/C++的项目,C/C++程序运行速度虽然很快,但是编译速度确实很慢,同时还存在内存泄漏的一系列的困扰需要解决。
Go语言是Google公司大佬开发的,主要起因于Google公司有大量的C程序项目,但是开发起来效率太低,维护成本高,于是就开发了Go语言来提高效率,而且性能只是差一点。
1.3 Golang vs Java
Golang侵占Java份额,主要是中间件编写。
架构师:
中间件开发 ------ 选择 Golang
业务逻辑 ------- 选择Java
问题来了,为什么中间件开发,要选择golang语言?
-----因为golang天生支持高并发。
Golang内置并发性允许同时处理多项任务。Python 也使用并发性,但并非内置,它通过线程实现并行化。
这意味着如果你打算处理大型数据集,Golang 似乎是更适合的选择。
1.4 应用领域
(1)中间件开发 docker k8s都是go开发的
(2)Go分布式/云计算软件工程师 cdn 云计算能力
(3)区块链工程师 go就是区块链技术的主流开发语言
1.5 用go语言的公司
(1)Google
(2)FaceBook
(3)腾讯
(4)百度
(5)京东
(6)小米
(7)360
美团、滴滴、新浪、阿里、七牛
Golang特别适合做网络并发的服务,这是他的强项。
2.Go下载和安装
2.1 开发工具
(1)Visual Studio Code 简称: vs Code
下载地址:https:code.visualstudio.com/download
(2)Sublime
(3)Vim
(4)Eclipse
(5)LiteIDE
(6==)IntelliJ IDEA==,需要安装Go插件
2.2 Go下载
SDK (Software Development kit软件开发工具包)
SDK是提供给开发人员使用的,其中包含了对应开发语言的工具包。
SDK下载: Go语言官网:golang.org
Goland中文社区:https://studygolang.com/dl (1.15.6版本)
下载之后的文件:

2.3 Go安装
(1)解压

解压后目录:

测试安装是否成功:

如果想要在任意的路径下执行某个命令,就需要将这个命令所在的目录配置到环境变量path中去,将命令“注册”到当前的计算机中。
配置go的环境变量:

2.4 Idea安装go插件
2.5 DOS命令
黑窗口 显得高大上
1.进入盘符: d:
2.显示详细信息: dir
3.改变当前目录: cd zhaoss
4.返回上一层: cd …
5.清屏 csl
6.切换上下命令: 上下箭头
7.补全命令:Tab键
8.创建目录 md
9.删除目录 rd
3.基础语法
3.1 Go执行流程
3.1.1 Go基本目录结构
在VSCode下写代码:在VSCode中打开上面的目录:
3.1.2 第一个HelloWord

3.1.3 编译teset.go
对源文件test.go进行编译
go build test.go
![]()

3.1.4 执行test.ext
![]()
3.1.5 编译+执行
go run test.go
![]()
3.1.6 Golang执行流程
1.执行流程分析:


2.上述两种执行流程方式的区别
(1)在编译时,编译器将程序运行依赖的库文件包含在可执行文件中,所以,可执行文件变大了很多:
(2)如果我们先编译生成了可执行文件,那么我们可以将该可执行文件拷贝到没有go开发环境的机器上,仍然可以运行
(3)如果我们是直接go run 源代码,那么如果要在另外一个机器上这么运行,也需要go开发环境,否则无法执行
3.注意事项:
编译后的文件可以另外指定名字。
3.2 标识符
[1] 标识符:读音 biao zhi fu Java里面叫变量的名称
[2]什么是标识符?
变量,方法等,只要是起名字的地方,那个名字就是标识符,
var age int = 19 var price float64 = 9.8
[3] 标识符的定义规则:
1.三个可以(组成部分):数字,字母,下划线_
ps:字母含义比较广泛,使用汉字也是可以的,不建议使用,建议用字母:26个字母
2.四个注意:不可以以数字开头,严格区分大小写,不能包含空格,不可以使用Go中的保留关键字
3.见名知意:增加可读性
4.下划线"_"本身在Go中是一个特殊的标识符,称为空标识符。可以代表任意其他的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)。所以仅能被作为占位符使用,不能单独作为标识符使用。
5.可以用如下形式,但是不建议:var int int = 32 (int,float32,float64等不算关键字,但是也尽量不要使用)
6.长度无限制,但是不建议太长 abddfdbbdgadfdasfasdgfdsagadsgagadsgadsg
7.起名规则:
(1)包名:尽量保持package的名字和目录保持一致,尽量采取有意义的包名,简短,有意义,
和标准库不要冲突
.为什么之前在定义源文件的时候,一般我们都用package main包?
main包是一个程序的入口包,所以你main函数它所在的包建议定义为main包,如果不定义为main包,那么就不能得到可执行文件
(2) 变量名、函数名、常量名:采用驼峰法
就是单词按照大小写分开
(3)如果变量名、函数名、常量名首字母大写,则可以被其他的包访问
如果首字母小写,则只能在本包中使用
注意:import导入语句通常放在文件开头包声明语句的下面。
导入的包名需要使用双引号包裹起来
包名是从$GOPATH/src/后开始计算的,使用/进行路径分隔。
util.go
package test
import "fmt"
func main() {
var StuNum = 36
fmt.Println(StuNum)
}
test.go
package main
import (
"fmt"
"com.tangguanlin/main/test"
)
func main() {
fmt.Println(util.StuNum)
}
3.3 语法注意事项
1.源文件以“go”为扩展名
2.程序的执行入口是main()函数
Java叫方法
Go叫函数
3.严格区分大小写
4.方法由一条条语句构成,每个语句后不需要分号(Go语言会在每行后自动加分号),这也体现了Golang的简洁性
结尾加上分号也不会报错
5.Go编译器是一行行进行编译的,因此我们一行就写一条语句,不能把多条语句写在同一个,否则报错
6.定义的变量或者import的包人工没有使用到,代码不能编译通过
定义了变量,没有被使用会报错,多余的东西会报错
7.大括号都是成对出现的,缺一不可
3.4 注释
1.注释的作用:
用于注解说明解释程序的文字就是注释,注释提高了代码的阅读性;
注释是一个程序员必须要具有的良好编程习惯。
将自己的思想通过注释先整理出来,再用代码去体现。
2.Golang中注释的类型
(1) 行注释 // vscode快捷键 ctrl+/ 再按一次取消
(2) 块注释 /**/ vscode快捷键:shift+alt+a 再按一次取消
3.5 代码风格
1.注意缩进
向后缩进 Tab键
向前取消缩进:shift+Tab键
通过命令完成格式化操作:gofmt -w test.go 才会写入到源文件中
2.成对编程{} () “” ‘’
3.运算符两边加空白
4.注释:推荐行注释
5.以下代码是错误的:

原因:go的设计者想要开发者有统一的代码风格,一个问题尽量只有一个解决方案是最好的
6.行长约定
一行最长不超过80个字符,超过的请使用换行展示,尽量保持格式优雅
3.6 API
API(Application Programming Interface) 应用程序接口
可以理解为 产品说明书 接口说明书
Go语言提供了大量的标准库,因此Google公司也为这些标准库提供了相应的API文档,用于告诉开发者如何使用这些标准库,以及标准库包括的方法:
官方位置: https://golang.org
Golang中文网在线标准文档: https://studygolang.com/pkgdoc


对应源代码:
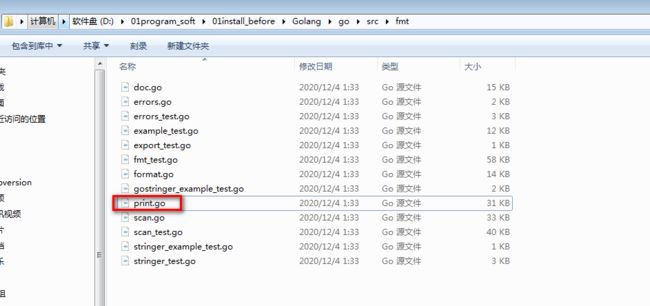
Println函数对应源代码:

3.7 关键字
1.关键字寄宿程序发明者规定的特殊含义的单词,又叫保留字。
go语言中一共25个关键字。

2.预定义标识符:一共36个预定义标识符,包含基础数据类型和系统内嵌函数

4.变量与基本数据类型
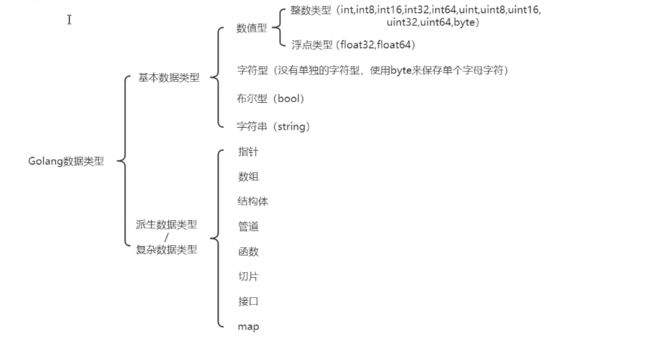
变量的数据类型:
4.1 整数类型
1.整数类型:就是用于存放整数值的,比如10,-45,,6712等待
2.有符号的整数类型:

package main
import "fmt"
func main(){
var test1 int8 = 121
fmt.Println(test1)
}
运行结果:
3.符号的整数类型:

4.其他整数类型:

注意:Golang的整数类型,默认声明为int类型
var num11 = 28
//Println函数的作业就是:格式化的,把num11的类型填充到T%的位置上
fmt.Println("num11的类型是:%T",num11) //num11的类型是:int
5.这么多整数类型,使用的时候该如何选择?
Golang程序中整型变量在使用时,遵守保小不保大的原则,
即:在保证程序正确运行下,尽量使用占用空间小的数据类型
4.2 浮点类型
1.浮点类型介绍:
简单的说,就是用于存放小数,比如3.14,0.28,-7.19等待
2.浮点类型种类:

没有float类型
注意:底层存储空间和操作系统无关
浮点类型底层存储:符号位+指数位+尾数位,所以尾数指数存了一个大概,很可能会出现精度的损失。
3.代码:
float.go
package main
import "fmt"
/**
* 浮点型数据类型
*/
func main(){
//定义浮点类型的数据
var num1 float32 = 3.14;
fmt.Println(num1)
//可以表示正浮点数,也可以表示负否定式
var num2 float32 = -3.14;
fmt.Println(num2)
//浮点数可以用十进制表示形式,也可以用科学计数法表示形式,E大小写都可以的
var num3 float32 = 314E-2;
fmt.Println(num3)
var num4 float32 = 314E+2;
fmt.Println(num4)
var num5 float64 = 314e+2;
fmt.Println(num5)
//浮点数有精度的损失,所以通常情况下,建议你使用:float64
var num6 float32 = 256.00000000916;
fmt.Println(num6)
var num7 float64 = 256.00000000916;
fmt.Println(num7)
//golang中默认的浮点类型为:float64
var num9 = 3.19
fmt.Printf("num9对应的默认的类型为:%T",num9)
}
运行结果:

4.3 字符类型
1.Golang中没有专门的字符类型,如果要存储单个字符(字母),一般使用byte来保存
2.Golang中字符使用UTF-8编码
3.ASCII码表
4.代码
package main
import "fmt"
func main(){
var c1 byte ='a'
fmt.Println(c1);
var c2 byte ='6'
fmt.Println(c2);
var c3 byte ='('
fmt.Println(c3);
//字符类型:本质上就是一个整数,也可以直接参与运算,输出字符的时候,会将对应的码值做一个输出
//字母 数字 标点,顶层是按照ASCII进行存储
var c4 int ='中'
fmt.Println(c4);
//汉子字符,底层对应的是Unicode码值
//对应的码值为20013,byte类型溢出,可以用int
//总结:Golang的字符对应的使用的是 UTF-8编码(Unicode是对应的字符集,UTF-8是Unicode的其中一种编码方案)
//ASCII码是Unicode的前128位
var c5 = 'A'
//想显示对应的字符,必须采用格式化输出
fmt.Printf("c5对应的具体的字符为:%c",c5)
}
运行结果:

6.转义字符
\n 换行
\‘’ 双引号原样输出
\ \ 输出\
4.4 布尔类型
1.布尔类型也叫bool类型,bool类型数据只允许取值true和false
2.布尔类型占一个字节
3.布尔类型适用于逻辑云想,一般用于程序流程控制
4.代码:
bool.go
package main
import "fmt"
/**
* 布尔类型
*/
func main(){
var flag01 bool = true
fmt.Println(flag01)
var flag02 bool = false
fmt.Println(flag02)
var flag03 bool = 5<10
fmt.Println(flag03)
}
运行结果:

4.5 字符串类型
1.字符串就是一串固定长度的字符连接起来的字符序列 string
2.字符串的使用:
string.go
package main
import "fmt"
/**
* 字符串类型
*/
func main(){
//1.定义一个字符串
var s1 string = "你好全面拥抱Golang"
fmt.Println(s1)
//2.字符串是不可变的
//不可变的意思不是指s2不能重新赋值,而是指s2对应的abc的值不能更改为atc
var s2 string = "abc";
s2 = "def"
//s2[0] = 't'
fmt.Println(s2)
//3.字符串的表示形式:
//(1)如果字符串中没有特殊字符,字符串的表示形式用双引号
var s3 string = "asddfdfdg"
fmt.Println(s3)
//(2)如果字符串中含有特殊字符,字符串的表示形式用反引号``(数字键1前面的那个键)
var s4 =`package main
import "fmt"
/**
* 布尔类型
*/
func main(){
var flag01 bool = true
fmt.Println(flag01)
var flag02 bool = false
fmt.Println(flag02)
var flag03 bool = 5<10
fmt.Println(flag03)
}`
fmt.Println(s4)
//4.字符串的拼接
var s5 string = "abd" + "def" + "abd" + "def" +
"abd" + "def" + "abd" + "def" +
"abd" + "def" + "abd" + "def" +
"abd" + "def" + "abd" + "def"
fmt.Println(s5)
}
运行结果:

4.6 基本数据类型默认值
整数类型默认值: 0
float32默认值: 0
float64默认值: 0
布尔类型默认值: false
string类型默认值: 空
代码:
defaultValue.go
package main
import "fmt"
/**
基本数据类型默认值
*/
func main() {
var a int
var b float32
var c float64
var d bool
var e string
fmt.Println("整数类型默认值:",a)
fmt.Println("float32默认值:",b)
fmt.Println("float64默认值:",c)
fmt.Println("布尔类型默认值:",d)
fmt.Println("string类型默认值:",e)
}
运行结果:

4.7 基本数据类型转换
1.Go在不同类型的变量之间赋值时需要显式转换,并且只有显式转换(强制转换)
2.语法:
表达式 T(v)将值v转换为类型T
T: 就是数据类型
v: 就是要转换的变量
3.代码:
package main
import "fmt"
/**
基本数据类型相互转换
*/
func main() {
//进行类型转换
var n1 int =100;
//var n2 float32 = n1 在这里自动转换不好使
var n2 float32 = float32(n1);
fmt.Println(n1);
fmt.Println(n2);
//注意:n1的类型其实还是int类型,只是将n1的值100转为float32而已,n1还是int的类型
//将int64转为int8的时候,编译不会出错,但是会数据的溢出
var n3 int64 = 8888888
var n4 int8 = int8(n3)
fmt.Println(n4) //56 溢出
var n5 int32 = 12
//一定要匹配等号作业的数据类型
var n6 int64 = int64(n5) + 30
fmt.Println(n6)
var n7 int64 =12
var n8 int8 = int8(n7) +127 //编译通过,但是结果会溢出
//var n9 int8 = int8(n7) + 128 //编译不会通过
fmt.Println(n8) //-127 溢出
//fmt.Println(n9)
}
运行结果:
100
100
56
42
-117
4.8 基本类型转为string
1.基本数据类型和string的转换介绍
在程序开发中,我们经常需要将基本数据类型转为string类型,或者将string类型转换成基本数据类型
2.基本类型转string类型
方式一:fmt.Sprintf("%参数",表达式)
方式二:使用strconv包的函数
3.代码
方式一: 推荐使用
package main
import "fmt"
/**
基本数据类型转为string类型
*/
func main() {
var n1 int = 19
var n2 float32 = 4.78
var n3 bool = false
var n4 byte = 'a'
var s1 string = fmt.Sprintf("%d",n1)
fmt.Printf("s1对应的类型是:%T,s1 = %v",s1,s1)
fmt.Println()
var s2 string = fmt.Sprintf("%f",n2)
fmt.Printf("s2对应的类型是:%T,s2 = %v",s2,s2)
fmt.Println()
var s3 string = fmt.Sprintf("%t",n3)
fmt.Printf("s3对应的类型是:%T,s3 = %v",s3,s3)
fmt.Println()
var s4 string = fmt.Sprintf("%c",n4)
fmt.Printf("s4对应的类型是:%T,s4 = %v",s4,s4)
fmt.Println()
}
方式二:
用的少 不好用
package main
import (
"fmt"
"strconv"
)
/**
基本数据类型转为string类型
*/
func main() {
//方式二:
var n11 int = 10
//第1个参数必须转为int64类型,第2个参数是进制形式
var s11 string = strconv.FormatInt(int64(n11),10)
fmt.Println(s11)
//不好用,还是用原生的类型转换
var n12 float64 = 4.29
var s12 string = strconv.FormatFloat(n12,'f',9,64)
fmt.Println(s12)
}
4.9 string转为基本类型
1.string类型转为基本数据类型
方式:使用strconv包下面的函数
2.代码:
package main
import (
"fmt"
"strconv"
)
/**
string类型转为基本数据类型
*/
func main() {
//1.string转bool
var s1 string = "true"
var b bool
//ParseBool这个函数的返回值有两个:(value bool,err error)
//value就是我们得到的布尔类型的数据,err出现的错误
//我们只关注得到的布尔德行的数据,err可以直接忽略
b,_ = strconv.ParseBool(s1);
fmt.Println(b)
//2.string转int
var s2 string = "19"
var num1 int64
num1,_ = strconv.ParseInt(s2,10,64)
fmt.Println(num1)
//2.string转float
var s3 string = "3.14"
var f1 float64
f1,_ = strconv.ParseFloat(s3,64)
fmt.Println(f1)
//注意:string向基本数据类型转换的时候,一定要确保是string 类型能够转换成有效的数据类型
//否则,最后得到的结果就是按照对应类型的默认值输出
var s4 string = "golang"
var b1 bool
b1,_ = strconv.ParseBool(s4)
fmt.Println(b1)
var s5 string = "golang"
var num2 int64
num2,_ = strconv.ParseInt(s5,10,64)
fmt.Println(num2)
}
运行结果:
true
19
3.14
false
0
4.10 go变量
一个程序就是一个世界
不论是使用哪种高级程序语言编写程序,变量都是其程序的基本组成单位
变量相当于内存中一个数据存储空间的表示
变量的使用步骤:
1.声明
2.赋值
3.使用
package main
import "fmt"
func main(){
//1.变量的声明
var age int
//2.变量的赋值
age = 18
//3.变量的使用
fmt.Println(age)
//声明和赋值可以合成一句:
var age2 int = 20
fmt.Println("age2=",age2)
//不可以在赋值的时候给与不匹配的类型
var num int = 12.56
fmt.Println("num=",num)
}
运行结果:
变量的4种使用形式:
package main
import "fmt"
func main(){
//第1种:变量的使用形式:指定变量的类型,并且赋值
var num int = 18
fmt.Println("num=",num)
//第2种:指定变量的类型,但是不赋值,使用默认值
var num2 int
fmt.Println("num2",num2)
//第3种:如果没有写变量的类型,那么根据=后面的值进行判定变量的类型(自动类型推断) ---用这种
var num3 = 10.25
fmt.Println("num3=",num3)
//第4种:省略var,注意 := 冒号等号 不能写为 =
sex := "男"
fmt.Println("sex=",sex)
}
运行结果:

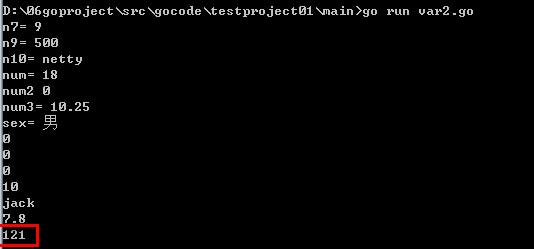
一次性声明多个声明(多变量声明)
package main
import "fmt"
func main(){
//一次性声明多个变量
var n1,n2,n3 int
fmt.Println(n1)
fmt.Println(n2)
fmt.Println(n3)
var n4,name,n5 = 10,"jack",7.8
fmt.Println(n4)
fmt.Println(name)
fmt.Println(n5)
}
全局变量:
定义在函数外的变量
package main
import "fmt"
//全局变量:定义在函数外的变量
var n7 = 9
//设计者认为上面的全局变量的写法太麻烦了,可以一次性声明:
var (
n9 = 500
n10 = "netty"
)
func main(){
fmt.Println("n7=",n7)
fmt.Println("n9=",n9);
fmt.Println("n10=",n10);
}
运行结果:

4.11 指针
1.基本数据类型和内存
package main
import "fmt"
func main() {
var age int = 18
//&符号+变量,就可以获取这个变量内存的地址
fmt.Println(&age) //0xc00011e058
}
运行结果:
0xc0000a2058
2.指针数据类型
总结:指针就是内存地址
package main
import "fmt"
func main() {
//定义一个指针变量:
//var 代表要声明一个变量
//ptr 指针变量的名字
//ptr 对应的类型是: *int是一个指针类型(可以理解为 指向int类型的指针)
//&age 就是一个地址,是ptr变量的具体的值
var ptr *int = &age
fmt.Println("指针ptr的值",ptr)
//想获取ptr这个指针或者这个地址指向的数据
//*ptr
fmt.Println("ptr指向的数值",*ptr) //18
}
运行结果:
指针ptr的值 0xc0000a2058
ptr指向的数值 18
(1)可以通过指针改变指向值
package main
import "fmt"
/**
指针
*/
func main() {
var num int =10
fmt.Println(num)
var ptr *int = &num
*ptr = 20
fmt.Println(num)
}
(2)指针变量接收的一定是地址值
(3)指针变量的地址不可以不 匹配
package main
import "fmt"
/**
指针
*/
func main() {
var num int =10
fmt.Println(num)
//地址类型不匹配 一个是int,一个是float32
var ptr2 *float32 = &num //错误
fmt.Println(ptr2)
}
注意:*float32意味着这个指针指向的是float32类型的数据,但是&num对应的是int类型的,不可以。
(4)基本数据类型(又叫值类型),都有对应的指针类型,形式为*数据类型,
比如int的对应的指针就是*int,float32对应的指针类型就是 *float32,以此类推。
5.运算符
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等

go语言中,没有三元运算符
5.1 算术运算符
【1】算术运算符:+ - * / % ++ –
【2】介绍:算术运算符是对数值类型的变量进行运算的,比如,加减乘除
【3】代码展示
package main
import "fmt"
/**
加法运算符 +
1.正数
2.相加操作
3.字符串拼接
*/
func main() {
var n1 int = +10
fmt.Println(n1)
var n2 int = 4+7
fmt.Println(n2)
var s1 string = "abc" + "def"
fmt.Println(s1)
// /除号
fmt.Println(10/3) //3 两个int类型数据运算,结果为int类型
fmt.Println(10.0/3) //3.33333 浮点类型参与运算,结果为浮点型
// % 取模
fmt.Println(10%3) //1
fmt.Println(-10%3) //-1
fmt.Println(10%-3) //1
fmt.Println(-10%-3) //-1
// ++ 自增 -- 自减
var a int = 10
a++
fmt.Println(a)
}
运行结果:
10
11
abcdef
3
3.3333333333333335
1
-1
1
-1
11
go语言里,++,–非常简单,只能单独使用,不能参与到运算中去
go语言里,++,–只能在变量后面,不能写在变量的前面:++a,–a 都是错误写法
5.2 赋值运算符
【1】赋值运算符: = += -= /= %= -=*=
【2】赋值运算符就是将某个运算后的值,赋给指定的变量
【3】代码展示
package main
import (
"fmt"
)
func main() {
var num1 int = 10
fmt.Println(num1)
var num2 int = (10+20)%3+3 -7
fmt.Println(num2)
//练习:交换两个数的值并输出结果:
var a int = 8
var b int = 4
fmt.Printf("a= %v,b=%v ",a,b)
var t int
t = a
a = b
b = t
fmt.Printf("a= %v,b=%v",a,b)
}
运算结果:
10
-4
a= 8,b=4
a= 4,b=8
5.3 关系运算符
【1】关系运算符: == != < = > <= >=
关系运算符的结果都是bool型,也就是要么是true,要么是false
【2】关系表达式经常用在流程控制中
【3】代码展示:
package main
import "fmt"
/**
关系运算符
*/
func main() {
//判断左右的值是否相等,相等返回true 不相等返回false
fmt.Println(5==9);
fmt.Println(5!=9)
fmt.Println(5>9)
fmt.Println(5<9)
fmt.Println(5<=9)
fmt.Println(5>=9)
}
运行结果:
false
true
false
true
true
false
5.4 逻辑运算符
【1】逻辑运算符: && (逻辑与) ||(逻辑或) !(逻辑非)
【2】用来进行逻辑运算的
【3】代码展示
(省略)
5.5 位运算符
(省略)
5.6 其他运算符
【1】其他运算符:
&: 返回变量的存储地址
*: 取指针变量对应的数值
【2】代码:
package main
import "fmt"
/**
其他运算符 & *
*/
func main() {
var age int = 18
//age对应的存储空间的地址为: 0xc00011e058
fmt.Println("age对应的存储空间的地址为:",&age)
var ptr *int = &age
fmt.Println(ptr)
fmt.Println("ptr指针指向的数值的",*ptr)
}
运行结果:
age对应的存储空间的地址为: 0xc000016090
0xc000016090
ptr指针指向的数值的 1
5.7 运算符的优先级别
Go语言有几十种运算符,被分成十几个级别,有的运算符优先级不同,
有的运算符优先级相同,请看下表。
一句话:为了提高优先级,可以加()

6.流程控制
【1】 流程控制的作用
流程控制语句是用来控制程序中各语句执行顺序的,可以把语句组合成能完成一定功能的小逻辑模块。
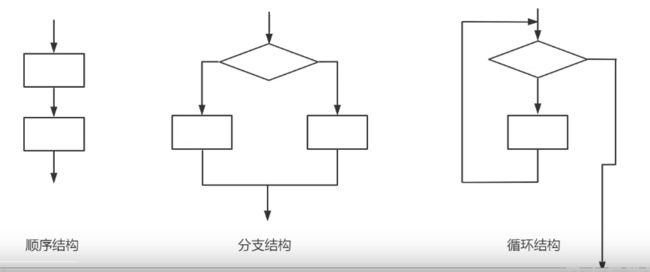
【2】控制语句的分类
控制语句分为三类:顺序、选择、循环
“顺序结构”代表 “先执行a,再执行b”的逻辑。
“条件判断结构”代表“如果...,则.....”的逻辑。
“循环结构”代表"如果.....,则再继续...."的逻辑。
三种流程控制语句就能表示所有的事情,不信,你可以试着拆分你遇到的各种事情,这三种基本逻辑结构是相互支撑的,它们共同构成了算法的基本结构,物流怎样复杂的逻辑结构,都可以通过它们来表达。所有任何一种高级语言都具备上述两种结构。
【3】流程控制的流程:
6.1 if分支
1.if单分支
【1】基本语法
if 条件表达式 {
逻辑代码
}
当条件表达式为true时,就会执行代码
注意:条件表达式左右的()可以不写,也建议不写
if和表达式中间,一定要有空格
在Golang中,{}是必须有的,就算你只有一行代码。
【2】代码:
package main
import "fmt"
/**
if单分支
*/
func main() {
//实现功能:如果口罩的库存小于30个,就提示库存不足
var count int = 20
//单分支
if count < 30 {
fmt.Println("口罩存量不足")
}
//if后面的表达式,返回结果一定是true或者false
//如果返回结果为true的话,那么{}中的代码就会执行
//如果返回结果为false的话,那么{}中的diam就不会执行
//if后面一定要有空格,和条件表达式分隔开来
//{}一定不能省略
//条件表达式左右的()是可以省略的
//在golang里,if后面可以并列的加入变量的定义:
if count:=20;count <30 {
fmt.Println("对不起,口罩存量不够")
}
}
运行结果:
口罩存量不足
对不起,口罩存量不够
2.if多分支
【1】基本语法
if 条件表达式 {
逻辑代码1
}else{
逻辑代码2
}
当表达式成立,记执行逻辑代码1,否则执行逻辑代码2。{}也是必须的。
注意:下面的格式是错误的:
if 条件表达式 {
逻辑代码1
}
else{
逻辑代码2
}
PS:空格加上,美观规范
【2】代码:
package main
import "fmt"
/**
if多分支
*/
func main() {
//实现功能:如果口罩的库存小于30个,提示:库存不足
// 否则提示:库存充足
var count int = 33
if count < 30 {
fmt.Println("库存不足")
} else{
fmt.Println("库存充足")
}
//双分支一定会二选一 走其中一个分支
}
运行结果:
库存充足
3.if双分支
【1】基本语法:
if 条件表达式1 {
逻辑代码1
}else if 条件表达式2 {
逻辑代码2
}
…
else{
逻辑代码n
}
【2】代码:
package main
import "fmt"
/**
if多条件分支
*/
func main() {
//实现功能:根据给出的学生分数,判断学生的等级:
// >=90 -----A
// >=80 -----B
// >=70 -----C
// >=60 -----D
// <60 -----E
var score int = 76
if score >= 90{
fmt.Println("你的成绩为A级别")
}else if score >= 80{
fmt.Println("你的成绩为B级别")
}else if score >= 70 {
fmt.Println("你的成绩为C级别")
}else if score >= 60 {
fmt.Println("你的成绩为D级别")
}else {
fmt.Println("你的成绩为E级别")
}
}
运行结果:
你的成绩为C级别
6.2 switch分支
【1】基本语法:
switch 表达式{
case 值1,值2,…
语句块1
case 值3,值4,…
语句块2
…
default:
语句块
}
【2】代码
package main
import "fmt"
/**
switch分支
*/
func main() {
//实现功能:根据给出的学生分数,判断学生的等级:
// >=90 -----A
// >=80 -----B
// >=70 -----C
// >=60 -----D
// <60 -----E
//给出一个学生分数:
var score int = 87
//根据分数判断等级:
//switch后面是表达式,这个表达式的结果依次跟case进行比较,满足结果的话,就执行冒号后面的代码
//default是用来兜底的分支,其他case分支不走的情况下就会走default分支
switch score/10 {
case 10,11,12 :
fmt.Println("您的等级为A级")
case 9 :
fmt.Println("您的等级为B级")
case 8 :
fmt.Println("您的等级为C级")
case 7 :
fmt.Println("您的等级为D级")
case 6 :
fmt.Println("您的等级为E级")
case 5 :
fmt.Println("您的等级为E级")
case 4 :
fmt.Println("您的等级为E级")
case 3 :
fmt.Println("您的等级为E级")
case 2 :
fmt.Println("您的等级为E级")
case 1 :
fmt.Println("您的等级为E级")
default:
fmt.Println("您的成绩有误")
}
}
运行结果:
您的等级为C级
【3】注意事项:
1.switch后是一个表达式(即:常量值,变量、一个有返回值的函等都可以)
2.case后面的表达式如果是常量值,则要求不能重复
3.case后面的各个值的数据类型,必须和switch的表达式数据类型一致
4.case后面可以带多个值,使用逗号分隔,比如case 值1,值2
5.case后面不需要带break,Java中需要加break
6.default语句不是必须的,位置也是可以随意的
7.switch后也可以不带表达式,当做if分支来使用 -----不推荐
8.switch后也可以直接声明/定义一个变量,分号结束,不推荐
9.switch穿透,利用fallthrough关键字,如果在case语句块后增加fallthrough,
则会继续执行下一个case,也叫switch穿透 ----不推荐使用
6.3 for循环
【1】语法结构:
for(初始表达式;布尔表达式;迭代因子){
循环体
}
for循环语句是支持迭代的一种通用结构,是最有效、最灵活的循环结构。for循环在第一次反复之前要进行初始化,即执行初始化表达式;随后,对布尔表达式进行判定,如判定结果为true,则执行循环体,否则,终止循环,最后在每一次反复的时候,进行某种形式的“步进”,即执行迭代因子。
1.初始化部分是设置变量的初值
2.条件判断部分为任意布尔表达式
3.迭代因子控制循环变量的增减
for循环在执行条件判断后,先执行的循环体部分,再执行步进。
for循环结构的流程图如图所示:
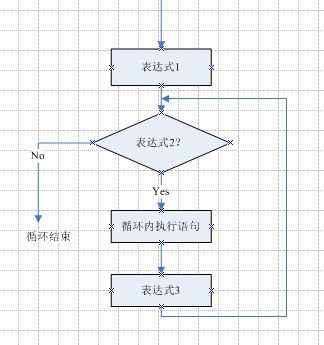
go语言没有while和do…while,只有for循环
for的初始表达式不能用var定义变量的形式,要用 :=
for循环实际上就是让程序员写代码的效率高了,但底层该怎么执行还是怎么执行的,底层效率没有提高
只是程序员写代码简洁了。
【2】代码
package main
import "fmt"
/**
for循环
*/
func main() {
//实现一个功能:求和:1+2+3+4+5
//求和
var sum int = 0
for i:=1 ; i<6 ; i++ {
sum = sum + i
}
fmt.Println(sum)
}
运行结果:
15
【3】注意事项
1.格式灵活
var i int =1
for i<6{
sum = sum + i
i++
}
fmt.Println(sum)
2.死循环
for{
fmt.Println("Golang")
}
for ; ; {
fmt.Println("Golang")
}
3.for range循环 —foreach
for range结构是Go语言特有的一种迭代结构,在许多情况下非常有用,for range可以遍历数组、切片、字符串、map及通道,for range语法上类似于其他语言的foreach语句,一般形式为:
for key,value := range coll{
…
}
代码:
package main
import "fmt"
/**
for range
*/
func main() {
var str string = "hello golang"
for i,value := range str{
fmt.Printf("索引为%d,具体的值为%c \n",i,value)
}
}
运行结果:
索引为0,具体的值为h
索引为1,具体的值为e
索引为2,具体的值为l
索引为3,具体的值为l
索引为4,具体的值为o
索引为5,具体的值为
索引为6,具体的值为g
索引为7,具体的值为o
索引为8,具体的值为l
索引为9,具体的值为a
索引为10,具体的值为n
索引为11,具体的值为g
6.4 关键字
6.4.1.break
跳出循环体
【1】感受break在循环中的作用
package main
import "fmt"
/**
break
*/
func main() {
//功能:求1--100的和,当和第一次超过300的时候,停止程序
var sum int = 0
for i:=1;i<=100;i++{
sum = sum + i
fmt.Println(sum)
if sum >= 300 {
//停止正在执行的这个循环
break
}
}
fmt.Println("-----------------ok")
}
运行结果:
1
3
6
10
15
21
28
36
45
55
66
78
91
105
120
136
153
171
190
210
231
253
276
300
-----------------ok
总结:
1.switch分支中,每个case分支后都用break结束当前分支,但是在go语言中break可以省略不写
2.break可以结束正在执行的循环
【2】深入理解
break的作用结束离它最近的循环
6.4.2 continue
结束本次循环
【1】continue的作用
package main
import "fmt"
/**
continue
*/
func main() {
//功能:输出1-100中国能被6整除的数
for i := 1;i<=100; i++{
if i%6 != 0{
continue
}
fmt.Println(i)
}
}
运行结果:
6
12
18
24
30
36
42
48
54
60
66
72
78
84
90
96
【2】深入理解
总结:continue的作用是结束离它近的那个循环
6.4.3 goto
【1】Golang的goto语句可以无条件地转移到程序中指定的行
【2】goto语句通常和条件语句配合使用,可以用来实现条件转移
【3】在Go程序设计中一般不建议使用goto语句,以免造成程序流程的混乱。
【4】代码展示
package main
import "fmt"
/**
goto
*/
func main() {
fmt.Println("helo golang")
fmt.Println("helo golang")
fmt.Println("helo golang")
if 1==1 {
goto label1
}
fmt.Println("helo golang")
fmt.Println("helo golang")
fmt.Println("helo golang")
label1:
fmt.Println("helo golang")
fmt.Println("helo golang")
fmt.Println("helo golang")
}
运行结果:
helo golang
helo golang
helo golang
helo golang
helo golang
helo golang
6.4.4 return
【1】return的作用
结束当前的函数(方法)
【2】代码
package main
import "fmt"
/**
return
*/
func main() {
for i := 1;i<= 100;i++ {
fmt.Println(i)
if i == 14 {
return //结束当前的函数
}
}
fmt.Println("-----ok")
}
运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
7.函数和包
在Java中叫方法
7.1 为什么要使用函数
提高代码的复用性,减少代码的冗余,代码的维护性也提高了
7.2 函数的定义
为完成某一个功能的程序指令(语句)的集合,称为函数
7.3 基本语法
func 函数名(形参列表)(返回值列表){
执行语句
return 返回值列表
}
7.4 函数的调用案例
package main
import "fmt"
//自定义函数:功能: 两个数相加
func cal(num1 int,num2 int)(int){ //如果返回值类型就只有一个的话,那么()是可以省略不写的
var sum int = 0
sum = sum + num1
sum = sum + num2
return sum
}
func main() {
//功能:10+20
var num1 int = 10
var num2 int = 20
//调用自定义函数
sum = cal(num1,num2)
fmt.Println(sum)
}
1.函数:对特定功能进行提取,形成一个代码片段,这个代码片段就是我们所说的函数
2.函数的作用:提高代码的复用性
3.函数和函数是并列的关系,所以我们定义的函数不能写到main函数中
4.函数名:
遵循标识符命名规范:见名知意 驼峰命名
首字母不能是数字
首字母大写改函数可以被本包文件和其他包文件使用(类似public)
首字母小写只能被本包文件使用,其他包文件不能使用(类似private)
5.形参列表:
个数:可以是一个参数,可以是n个参数,也可以是0个参数
形式参数列表作用:接收外来的数据
实际参数:实际传入的数据
6.返回值类型列表:函数的返回值对应的类型应该写在这个列表中
可以返回0个数据
可以返回1个数据
可以返回多个数据
如果返回值类型就只有一个的话,那么()是可以省略不写的
返回多个结果代码:不建议使用
package main
import "fmt"
func cal2(num1 int,num2 int)(int,int){
var sum int = 0
var sub int = 0
sum = num1 + num2
sub = num1 - num2
return sum,sub
}
func main() {
var num1 int = 10
var num2 int = 20
var sum int = 0
var sub int = 0
sum,sub = cal2(num1,num2)
fmt.Println(sum)
fmt.Println(sub)
sum,_ = cal2(num1,num2) //只需要1个结果
fmt.Println(sum)
}
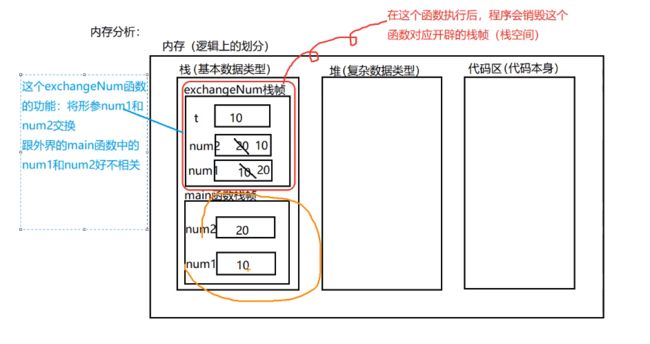
7.通过案例感受函数的内存分析:值传递
8.Golang中函数不支持重载
9.Golang中支持可变参数(如果你希望函数电邮可变数量的参数)
func cal3(args... int){ //可以传入多个可变参数
//函数内部处理可变参数的时候,将可变参数当做切片来处理 当做数组
for i:= 0;i<len(args);i++{
fmt.Println(args[i])
}
}
10.基本数据类型和数组默认都是值传递的,即进行值拷贝。在函数内修改,不会影响原来的值。
在Java中,数组是地址传递,但在Go语言中,是值传递
package main
import "fmt"
func test(num int){
num = 30
fmt.Println(num)
}
func main() {
var num int = 10
test(num)
fmt.Println(num)
}
运行结果:
30
10
11.以值传递方式的数据类型,如果希望在函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以
指针的方式操作变量。从效果来看,类似引用传递。
package main
import "fmt"
func test(num *int){
*num = 30
fmt.Println(*num)
}
func main() {
var num int = 10
test(&num)
fmt.Println(num)
}
运行结果:
30
30
内存分析:

12.在Go中,函数也是一种数据类型,可以赋值给一个变量,则变量就是一个函数类型的变量了。通过该变量可以
对函数进行调用。
package main
import "fmt"
func test2(num int){
fmt.Println(num)
}
func main() {
a := test2
fmt.Printf("a的数据类型是:T%,test函数的类型是:T%",a,test2)
//通过该变量可以对函数调用
a(10) //等价于test(10)
}
运行结果:
a的数据类型是:T%!,(func(int)=0x4a73a0)
test函数的类型是:T%!(NOVERB)%!(EXTRA func(int)=0x4a73a0)
10
13.函数既然是一种数据类型,因此在Go中,函数可以作为形参,并且调用(把函数本身当做一种数据类型)
package main
import "fmt"
func test2(num int){
fmt.Println(num)
}
func test3(num1 int,num2 float32,testFunc func(int)){
fmt.Println("----test3-----")
}
func main() {
a := test2
//调用test3
test3(10,3.19,test2)
test3(10,3.19,a)
}
运行结果:
----test3-----
----test3-----
14.为了简化数据类型定义,Go支持自定义数据类型,
基本语法:
type 自定义数据类型名 数据类型
可以理解为:相当于起了一个别名
例如:type myInt int —>这时,myInt就等价于int来使用了

例如:type mySum func(int,int) int —>这时mySum就等价一个函数类型func(int,int) in
type myFunc func(int)
func test03(num1 int,num2 float,testFunc myFunc){
fmt.Println("-----test02----")
}
15.支持对函数返回值命名
func test4(num1 int,num2 int)(int,int){
sum := num1 + num2
sub := num1 + num2
return sum,sub
}
//函数返回值命名,里面顺序就无所谓了,顺序不用对应
func test5(num1 int,num2 int)(sum int,sub int){
sum = num1 + num2
sub = num1 + num2
return
}
7.5 包
7.5.1 使用包的原因
(1) 我们不可能把所有的函数都放在同一个源文件中,可以分门别类的把函数放在不同的源文件中
(2) 解决同名问题:两个人都想定义一个同名的函数,在同一个文件中是不可以定义相同名字的函数的。
此时可以用包来区分

7.5.2 案例展示包
项目结构:

main.go

util.go
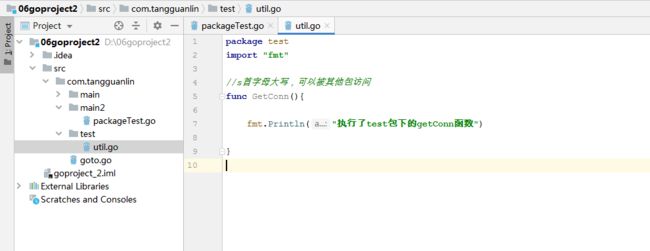
运行结果:
执行了test包下的getConn函数
您好,这是main函数的执行
说明:
1.package进行包的声明,建议:包的声明这个包和所在文件夹同名
2.main包是程序的入口包,一般main函数会放在这个包下
3.打包语法
package 包名
4.引入包的语法:import “包的路径”
包名是从 $GOPATH/src/后开始计算的,使用/进行路径分隔
5.如果有多个包,建议一次性导入,格式如下:
import(
"fmt"
"gocode/testproject01/unit5/demo09/crm/dbutils"
)
6.在函数调用的时候前面要定位到所在的包
7.首字母大写,函数可以被其他包访问
8.一个目录下不能有重复的函数
同一个包下,不能有重复的函数,同一个包下的不同类也不行
9.包名和文件夹的名字,可以不一样
10.一个目录下的同级文件归属一个包
一个源文件用了别名的包,那同目录下的同级文件也要用这个别名的包
11.包到底是什么:
(1)在程序层面,所有使用相同package包名的源文件组成的代码模块
(2)在源文件夹层面就是一个文件夹
(3)包相当于是一个类,包含包目录下所有函数的类,访问下面函数通过 包名.函数名 访问
12.可以被包取别名,去别名后,原来的包名就不能使用了

7.6 init函数
【1】init函数:初始化函数,可以用来进行一些初始化的操作
每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被Go运行框架调用
package main
import (
"fmt"
"com.tangguanlin/test"
)
func init() {
fmt.Println("先执行init函数")
}
func main() {
test.GetConn();
fmt.Println("您好,这是main函数的执行")
}
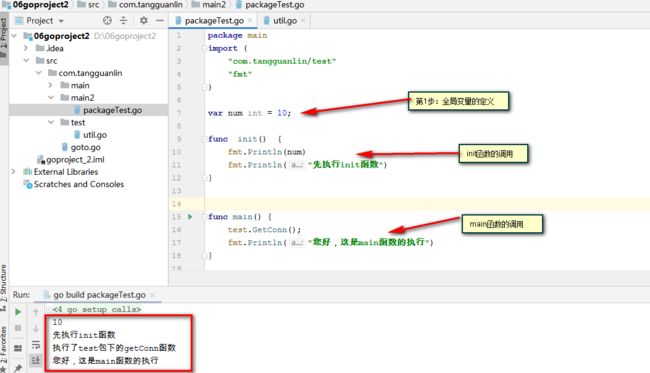
运行结果:
先执行init函数
执行了test包下的getConn函数
您好,这是main函数的执行
【2】全局变量定义:init函数,main函数的执行流程?
先执行init函数,再试下main函数
【3】多个源文件都有init函数的时候,如何执行?
main.go
package main
import (
"com.tangguanlin/test"
"fmt"
)
var num int = 10;
func init() {
fmt.Println(num)
fmt.Println("main.go中的init函数被执行")
}
func main() {
test.GetConn();
fmt.Println("您好,这是main函数的执行")
}
util.go
package test
import "fmt"
func init(){
fmt.Println("util.go中的init函数被执行")
}
//s首字母大写,可以被其他包访问
func GetConn(){
fmt.Println("执行了test包下的getConn函数")
}
运行结果:
util.go中的init函数被执行
10
main.go中的init函数被执行
执行了test包下的getConn函数
您好,这是main函数的执行
运行顺序总结:

7.7 匿名函数
【1】Go支持匿名函数,如果我们某个函数只是希望使用一次,可以考虑使用匿名函数
匿名函数,该函数没有函数名称
【2】匿名函数的使用方式:
(1)在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次 ----最常用,用得多
package main
import (
"fmt"
)
func main() {
//定义匿名函数的同时调用
sum := func(num1 int, num2 int) int {
return num1 + num2
}(10, 20)
fmt.Println(sum)
}
运行结果:
30
(2)将匿名函数赋给一个变量(该变量就是函数变量),再通过改变量来调用匿名函数
这种情况下,可以直接定义为普通函数,可以反复调用
sub := func(num1 int, num2 int)(int){
return num1 - num2
}
result := sub(20,10)
fmt.Println(result)
运行结果:
10
(3)如何让一个匿名函数,可以在整个程序中有效呢?将匿名函数给一个全局变量就可以了
package main
import "fmt"
var func01 = func(num1 int,num2 int) int{
return num1*num2
}
func main() {
result3 :=func01(3,4)
fmt.Println(result3)
}
7.8 闭包
【1】闭包就是一个函数和与其相关的引用环境组合的一个整体
【2】案例展示
package main
import "fmt"
/*
闭包
*/
//函数的功能:求和
//函数的名字:getSum 参数为空
//getSum函数返回值为一个函数,这个函数的参数是一个int类型的参数,返回值也是in类型
func getSum() func(int) int{
var sum int = 0
return func(num int) int{
sum = sum + num
return sum
}
}
//闭包:返回的匿名函数+匿名函数以外的变量num
func main() {
f := getSum()
fmt.Println(f(1)) //1
fmt.Println(f(2)) //3
fmt.Println(f(3)) //6
}
运行结果:
1
3
6
感受:匿名函数中引用的那个变量会一直保存在内存中,可以一直使用
【3】闭包的本质
闭包的本质依旧是一个匿名函数,只是这个函数引入外界的变量/参数
匿名函数 + 引用的变量/参数 = 闭包

【4】特点
(1) 返回的是一个匿名函数,但是这个匿名函数引用到函数外的变量/参数,因此这个匿名函数就和变量/参数形成了一个整体,构成闭包
(2) 闭包中使用的变量/参数会一直保持在内存中,所以会一直使用—>意味着闭包不可滥用
(3)不使用闭包的时候,想保留的值,不可以反复使用
(4)闭包应用场景:闭包可以保留上次引用的某个值,我们传入一次就可以反复使用了
第1次调用和第n次调用,形成一个for循环
7.9 defer
【1】defer关键字的作用:
在函数中,程序员经常需要创建资源,为了在函数执行完毕后,及时的释放资源,Go的设计者提供了defer关键字。
【2】案例展示:
package main
import "fmt"
/**
defer关键字
*/
func main() {
fmt.Println(add(30,60))
}
func add(num1 int,num2 int) int{
//在go语言中,程序遇到defer关键字,不会立即执行defer后的语句,而是将defer后的语句压入一个栈中
//然后继续执行函数后面的语句
defer fmt.Println("num1=",num1)
defer fmt.Println("num2=",num2)
//栈的特点是先进后出
//在函数执行完毕以后,从栈中取出语句开始执行,按照先进后出的规则执行语句
var sum int = num1 + num2
fmt.Println("sum=",sum)
return sum
}
运行结果:
sum= 90
num2= 60
num1= 30
90
【3】代码变动一下,再次看结果:
package main
import "fmt"
/**
defer关键字
*/
func main() {
fmt.Println(add(30,60))
}
func add(num1 int,num2 int) int{
//在go语言中,程序遇到defer关键字,不会立即执行defer后的语句,而是将defer后的语句压入一个栈中
//然后继续执行函数后面的语句
defer fmt.Println("num1=",num1)
defer fmt.Println("num2=",num2)
num1 += 90
num2 += 50
//栈的特点是先进后出
//在函数执行完毕以后,从栈中取出语句开始执行,按照先进后出的规则执行语句
var sum int = num1 + num2
fmt.Println("sum=",sum)
return sum
}
运行结果:
sum= 230
num2= 60
num1= 30
230
发现:遇到defer关键字,会将后面的语句压入栈中,也会将相关的值同时拷贝入栈中,不会随着函数后面的变化
而变化。
【4】defer应用场景:
比如你想关闭某个使用的资源,在使用的时候直接随手defer,因为defer有延迟执行机制(函数执行完毕再执行defer压入栈的语句),所以你用完随手写个关闭,比较省心,省事。
7.10 系统函数
【1】统计字符串的长度,按字节进行统计
len(str)
使用内置函数不用导包,直接用就行
package main
import "fmt"
/**
内置函数
*/
func main() {
str := "golang你好" //在golang中,汉子是utf-8字符集,一个汉子3个字节
fmt.Println(len(str)) //12个字节
}
运行结果:
12
【2】字符串遍历:
方式一: 方式一:利用键值循环:for-range
//对字符串进行遍历
//利用键值循环:for-range
for i,value := range str{
fmt.Printf("索引为:%d,具体的值为%c \n",i,value)
}
运行结果:
索引为:0,具体的值为g
索引为:1,具体的值为o
索引为:2,具体的值为l
索引为:3,具体的值为a
索引为:4,具体的值为n
索引为:5,具体的值为g
索引为:6,具体的值为你
索引为:9,具体的值为好
方式二:利用r:[]rang(str)
r := []rune(str)
for i:= 0;i<len(r);i++{
fmt.Printf("%c \n",r[i])
}
运行结果:
g
o
l
a
n
g
你
好
【3】字符串转整数
strconv.Atoi()
num1,_ := strconv.Atoi("666")
fmt.Println(num1)
【4】整数转字符串
strconv.Itoa()
str1 := strconv.Itoa(777)
fmt.Println(str1)
【5】查找子串是否在指定的字符串中
【6】统计一个字符串有几个指定的子串
strings.Count(“golangandjava”,“go”)
count := strings.Count("golangandjava","go")
fmt.Println(count)
【7】不区分大小写的字符串比较
strings.EqualFold(“hello”,“HELLO”)
flag := strings.EqualFold("hello","HELLO")
fmt.Println(flag)
//区分大小写的字符串比较
fmt.Println("hello"=="HELLO")
【8】返回子串在字符串第一次出现的索引值,如果没有返回-1
strings.Index(“golangandjavaga”,“ga”)
index := strings.Index("golangandjavaga","ga")
fmt.Println(index)
【9】字符串的替换
strings.Replace(“goandjavagogo”,“go”,“golang”,-1)
str11 := strings.Replace("goandjavagogo","go","golang",-1)
fmt.Println(str11)
【10】按照指定的某个字符,为分隔标识符,将一个字符串拆分成字符串数组
strings.Split(“go-python-java”,"-")
arr := strings.Split("go-python-java","-")
fmt.Println(arr)
【11】将字符串的字母进行大小写的转换
strings.ToLower(“Go”)
strings.ToUpper(“go”)
str12 := strings.ToLower("Go")
fmt.Println(str12)
str13 := strings.ToUpper("go")
fmt.Println(str13)
【12】将字符串左右两边的空格去掉
strings.TrimSpace(" go and java")
str14 := strings.TrimSpace(" go and java")
fmt.Println(str14)
运行结果:
go and java
【13】将字符串左边指定的字符串去掉
strings.Trim(“golang”,"~")
str15 := strings.Trim("~golang~","~")
fmt.Println(str15)
运行结果:
golang
【14】将字符串左边指定的字符去掉
strings.TrimLeft(“golang”,"~")
str16 := strings.TrimLeft("~golang~","~")
fmt.Println(str16)
【15】将字符串右边指定的字符去掉
strings.TrimRight(“golang”,"~")
str17 := strings.TrimRight("~golang~","~")
fmt.Println(str17)
【16】判断字符串是否以指定的字符串开头
strings.HasPrefix(“http://java.sun.com”,“http”)
flag1 := strings.HasPrefix("http://java.sun.com","http")
fmt.Println(flag1)
【17】判断字符串是否以指定的字符串结尾
strings.HasSuffix(“demo.png”,“jpg”)
flag2 := strings.HasSuffix("demo.png","jpg")
fmt.Println(flag2)
7.11 日期和时间相关函数
【1】时间和日期的函数,需要导入time包,所以你获取当前,就要调用函数Now函数
package main
import (
"fmt"
"time"
)
/**
日期和时间函数
*/
func main() {
//时间和日期的函数,需要导入time包,所以你获取当前,就要调用函数Now函数
now := time.Now()
fmt.Printf("%v------对应的类型是 %T",now,now)
fmt.Printf("年:%v \n",now.Year())
fmt.Printf("月:%v \n",now.Month())
fmt.Printf("月:%v \n",int(now.Month()))
fmt.Printf("日:%v \n",now.Day())
fmt.Printf("时:%v \n",now.Hour())
fmt.Printf("分:%v \n",now.Minute())
fmt.Printf("秒:%v \n",now.Second())
//fmt.Sprint可以得到字符串,后续使用
datastr := fmt.Sprint("当前年月日: %d-%d-%d 时分秒:%d:%d:%d",
now.Year(),int(now.Month()),now.Day(),
now.Hour(),now.Minute(),now.Second())
fmt.Println(datastr)
}
【2】日期的格式化
(1)将日期以年月日时分秒按照格式输出为字符串
time.Now()
fmt.Sprint()
//时间和日期的函数,需要导入time包,所以你获取当前,就要调用函数Now函数
now := time.Now()
fmt.Printf("%v------对应的类型是 %T",now,now)
fmt.Printf("年:%v \n",now.Year())
fmt.Printf("月:%v \n",now.Month())
fmt.Printf("月:%v \n",int(now.Month()))
fmt.Printf("日:%v \n",now.Day())
fmt.Printf("时:%v \n",now.Hour())
fmt.Printf("分:%v \n",now.Minute())
fmt.Printf("秒:%v \n",now.Second())
//fmt.Sprint可以得到字符串,后续使用
datastr := fmt.Sprint("当前年月日: %d-%d-%d 时分秒:%d:%d:%d",now.Year(),int(now.Month()),now.Day(),now.Hour(),now.Minute(),now.Second())
fmt.Println(datastr)
(2)按照指定格式:
now2.Format(“2006/01/02 15/04/05”)
now2 := time.Now()
//这个参数字符串的各个数字必须是固定的,必须这样写
str16 := now2.Format("2006/01/02 15/04/05") //这个太过分了
fmt.Println(str16)
//选择任意的组合都是可以的,根据需求自己选择就可以(自己任意组合)
str17 := now2.Format("2006/01/02") //年月日
fmt.Println(str17)
7.12 内置函数
【1】什么是内置函数
Golang设计者为了编程方便,提供了一些函数,这些函数不用导包就可以直接使用,我们称为Go的内置函数
【2】内置函数的存放位置
在builtin包下,使用内置函数,直接用就行
【3】常用函数:
(1)len函数
统计字符串的长度,按字节进行统计
(2)new函数
分配内存,主要用来分配值类型(int系列,float系列,bool,string,数组,和结构图struct)
func new(Type) *Type
内置函数new分配内存,其第一实参为类型,而非值。其返回值为指向该类型的新分配的零值的指针
//new分配内存,new函数的实参是一个类型而不是具体数值,new函数返回值是对应类型的指针 num:*int
num101 := new(int)
fmt.Println(num101)
运行结果:
0xc00000a0d8
(3)make函数
分配内存,主要用来分配引用类型(指针,slice切片,map,管道chan,interface等)
7.13 错误处理
【1】展示错误
(略)
【2】错误的处理/捕获机制
go中追求代码的优雅,引入机制:defer+recover机制处理错误
内置函数:recover
package main
import "fmt"
/**
错误处理
*/
func main() {
test()
fmt.Println("上面的除法操作执行成功...")
}
func test(){
//利用defer+decover捕获错误
defer func(){
//调用recover内置函数,可以捕获错误
err := recover()
//如果没有捕获错误,返回为零值:nil
if err!= nil {
fmt.Println("当前的错误已经捕获")
fmt.Println("err是:",err)
}
}()
num1 := 10
num2 := 0
result := num1/num2
fmt.Println(result)
}
优点:提高 了程序的健壮性
自定义错误
【1】自定义错误:需要调用errors包下的New函数:函数返回error类型
errors.New(“除数不能为0~~~”)
package main
import (
"errors"
"fmt"
)
/**
错误处理
*/
func main() {
err := test()
if err != nil{
fmt.Println("自定义错误为:",err)
}
fmt.Println("上面的除法操作执行成功...")
}
func test()(err error){
num1 := 10
num2 := 0
if num2 == 0{
//抛出自定义错误
return errors.New("除数不能为0~~~")
}else{
//如果除数不为0,那么正常执行就可以了
result := num1/num2
fmt.Println(result)
//如果没有错误,返回零值
return nil;
}
}
运行结果:
自定义错误为: 除数不能为0~~~
上面的除法操作执行成功...
有一种情况:程序出现错误以后,后续代码就没有必要执行,想让程序中断,退出程序
借助:builtin包下内置函数:panic
代码:
package main
import (
"errors"
"fmt"
)
/**
错误处理
*/
func main() {
err := test()
if err != nil{
fmt.Println("自定义错误为:",err)
panic(err) //再次将程序中断
}
fmt.Println("上面的除法操作执行成功...")
}
func test()(err error){
num1 := 10
num2 := 0
if num2 == 0{
//抛出自定义错误
return errors.New("除数不能为0~~~")
}else{
//如果除数不为0,那么正常执行就可以了
result := num1/num2
fmt.Println(result)
//如果没有错误,返回零值
return nil;
}
}
运行结果:
自定义错误为: 除数不能为0~~~
panic: 除数不能为0~~~
goroutine 1 [running]:
main.main()
D:/06goproject2/src/com.tangguanlin/main2/errorTest.go:16 +0x166
8.数组和切片
8.1 练习引入
(略)
缺点:成绩变量定义个数太多,成绩管理费劲,维护费劲 ----->将这个成绩找个地方存起来---->数组
----> 存储相同类型的数据
8.2 数组解决练习
package main
import "fmt"
/**
数组
*/
func main() {
//实现功能:给出5个学生的成绩,求出成绩的总和,平均数
//定义一个数组
var scores [5]int
//将成绩存入数组
scores[0] = 95
scores[1] = 91
scores[2] = 39
scores[3] = 60
scores[4] = 21
var sum int = 0
//求和
for i := 0;i < len(scores);i++{
sum = sum + scores[i]
}
//平均数
avg := sum/len(scores)
//输出
fmt.Printf("成绩的总和为:%v,成绩的平均数为:%v",sum,avg)
}
运行结果:
成绩的总和为:306,成绩的平均数为:61
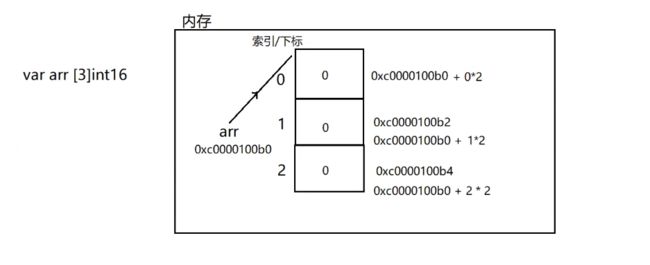
总结:数组定义格式: var 数组名 []数据类型
比如: var scores [5]int
每个每个空间占用的字节数取决于数组类型
8.3 内存分析
数组优点:访问/查询/读取 速度快
8.4 数组的遍历
(1)普通的for循环
for i := 0;i < len(scores);i++{
sum = sum + scores[i]
fmt.Println("第%d个学生的成绩为:%d",i+1,scores[i])
}
(2)键值循环 for range
for range结构是Go语言特有的一种迭代结构,在许多情况下都非常有用,for range可以遍历数组,切片,字符串,map及通道,for range语法上类似于其他语言的foreach语句,一般形式为:
for key,val := range coll{
…
}
注意:1.coll就是你要遍历的数组
2.每次遍历得到的索引用key接收,每次遍历得到的索引位置上的值用value接收
3.key、value的名字随便起名 k、v key、value
4.key、value属于在这个循环中的局部变量
5.你想忽略某个值,用_就可以了
for _,value := range scores{
fmt.Printf("第%d个学生的成绩是%d \n",key,value)
}
代码:
for key,value := range scores{
fmt.Printf("第%d个学生的成绩是%d \n",key,value)
}
运行结果:
第0个学生的成绩是95
第1个学生的成绩是91
第2个学生的成绩是39
第3个学生的成绩是60
第4个学生的成绩是21
8.5 数组的初始化方式
//第1种
var arr1 [3]int = [3]int{3,6,9}
fmt.Println(arr1)
//第2种
var arr2 = [3]int{1,4,7}
fmt.Println(arr2)
//第3种
var arr3 = [...]int {4,5,6,7}
fmt.Println(arr3)
//第4种
var arr4 = [...]int {2:66,0:33,1:99,3:88}
fmt.Println(arr4)
运行结果:
[3 6 9]
[1 4 7]
[4 5 6 7]
[33 99 66 88]
8.6 数组的注意事项
1.长度属于类型的一部分
2.Go中数组属性类型,在默认情况下是值传递,因此沪进行值拷贝。
package main
import "fmt"
func main() {
var arr5 = [3]int{3,6,9}
test1(arr5)
fmt.Println(arr5) //[3 6 9]
}
func test1(arr [3]int){
arr[0] = 7
}
运行结果:
[3 6 9]
内存分析:

3.如果想在其他函数中,去修改原来的数组,可以使用引用传递(指针方式)
package main
import "fmt"
func main() {
var arr5 = [3]int{3,6,9}
test1(&arr5) //传入arr3数组的地址
fmt.Println(arr5) //[3 6 9]
}
func test1(arr *[3]int){
arr[0] = 7
}
运行结果:
[7 6 9]
内存分析:

8.7 二位数组
### 8.7.1 二维数组定义
二维数组的定义,并且有默认初始值:
var arr [2][3]int
fmt.Println(arr)
### 8.7.2 二维数组内存分析

### 8.7.3 二维数组赋值
package main
import "fmt"
/**
二维数组
*/
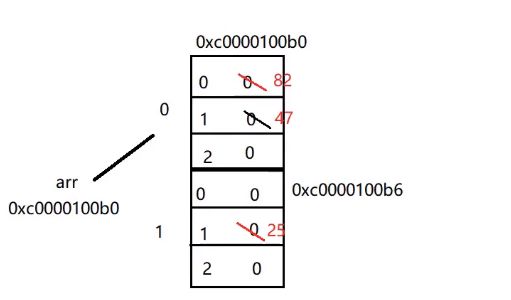
func main() {
var arr [2][3]int
arr[0][1] = 47
arr[0][0] = 82
arr[1][1] = 25
fmt.Println(arr)
}
运行结果:
[[82 47 0] [0 25 0]]
内存分析:
8.7.4 二维数组的初始化
代码:
var arr1 [2][3]int = [2][3]int{{1,4,7},{2,5,8}}
fmt.Println(arr1)
var arr2 = [2][3]int{{1,4,7},{2,5,8}}
fmt.Println(arr2)
运行结果:
[[1 4 7] [2 5 8]]
8.7.5 二维数组的遍历
方式1:普通for循环
代码:
for i := 0;i < len(arr3);i++{
for j := 0;j < len(arr3[i]);j++{
fmt.Println(arr3[i][j])
}
}
运行结果:
1
4
7
2
5
8
3
6
9
方式2:for range循环
代码:
for key,value := range arr3{
for key1,value1 := range value{
fmt.Printf("第[%d][%d]个数组的值是%d \n",key,key1,value1)
}
}
运行结果:
第[0][0]个数组的值是1
第[0][1]个数组的值是4
第[0][2]个数组的值是7
第[1][0]个数组的值是2
第[1][1]个数组的值是5
第[1][2]个数组的值是8
第[2][0]个数组的值是3
第[2][1]个数组的值是6
第[2][2]个数组的值是9
8.8 切片
8.8.1 切片介绍
【1】切片(slice)是golang中一种特有的数据类型
【2】数组有特定的用处,但是却有一些呆板(数组长度固定不可变),所以在Go语言的代码里并不是特别常见。相对的切片却是随处可见的,切片是一种建立在数组类型之上的抽象,它构建在数组之上并且提供更强大的能力和便捷。
【3】切片(slice)是对数组一个连续片段的引用,所以切片是一个引用类型。这个片段可以是整个数组,或者是由起始索引标识的一些项的子项。需要注意的是,终止索引标识的项不包括在切片内。切片提供了一个相关数组的动态窗口。
8.8.2 代码
切片的语法
var slice []int = intarr[1:3]
package main
import "fmt"
/**
切片
*/
func main() {
//定义数组:
var intarr [6]int = [6]int{3,6,9,1,4,7}
//切片构建在数组之上
//定义一个切片名字为slice,[]动态变化的数组长度不写,int类型,intarr是原数组
//[1:3]切片--切出的一段片段 -索引:从1开始,到3结束(不包含3)--[1,3)
//var slice []int = intarr[1:3]
slice := intarr[1:3]
fmt.Println(slice)
//切片元素个数
fmt.Println("clice的元素个数:",len(slice))
//获取切片的容量:容量可以动态变化
fmt.Println("clice的容量:",cap(slice))
}
运行结果:
[6 9]
clice的元素个数: 2
clice的容量: 5
8.8.3 切片内存分析

8.8.4 切片的定
1.方式1:定义1个切片,然后让切片去引用一个已经创建好的数组
var slice []int = intarr[1:3]
var intarr [6]int = [6]int{3,6,9,1,4,7}
//切片构建在数组之上
//定义一个切片名字为slice,[]动态变化的数组长度不写,int类型,intarr是原数组
//[1:3]切片--切出的一段片段 -索引:从1开始,到3结束(不包含3)--[1,3)
//var slice []int = intarr[1:3]
slice := intarr[1:3]
fmt.Println(slice)
2.方式2:通过make内置函数来创建切片,基本语法:
var 切片名 type = make([],len,[cap])
package main
import "fmt"
/**
切片
*/
func main() {
//方式2: make方式 创建切片
//定义切片:make函数的参数: 1.切片类型 2.切片长度 3.切片容量
slice2 := make([]int,4,20)
fmt.Println(slice2)
fmt.Println("切片的长度:",len(slice2))
fmt.Println("切片的容量:",cap(slice2))
}
运行结果:
[0 0 0 0]
切片的长度: 4
切片的容量: 20
注意:make底层创建一个数组,对外不可见,所以不可以直接操作这个数组,要通过slice去间接的访问各个元
素,不可以直接对数组进行操作
3.方式3:定义一个切片,直接就指定具体数组,使用原理类似make的方式
slice3 := []int {1,4,7} 这其实就是定义了一个数组
slice3 := []int {1,4,7}
fmt.Println(slice3)
fmt.Println("切片的长度",len(slice3))
fmt.Println("切片的容量",cap(slice3))
运行结果:
[1 4 7]
切片的长度 3
切片的容量 3
8.8.5 切片的遍历
1.方式1:普通for循环
package main
import "fmt"
func main() {
//定义一个切片
slice5 := make([]int,4,20)
slice5[0] = 66
slice5[1] = 88
slice5[2] = 99
slice5[3] = 100
//方式1:普通for循环
for i := 0;i<len(slice5);i++{
fmt.Printf("slice[%d]的值%d \n",i,slice5[i])
}
}
运行结果:
slice[0]的值66
slice[1]的值88
slice[2]的值99
slice[3]的值100
2.方式2:for range
package main
import "fmt"
func main() {
//定义一个切片
slice5 := make([]int,4,20)
slice5[0] = 66
slice5[1] = 88
slice5[2] = 99
slice5[3] = 100
//方式2:for range
for key,value := range slice5{
fmt.Printf("slice[%d]的值%d \n",key,value)
}
}
运行结果:
slice[0]的值66
slice[1]的值88
slice[2]的值99
slice[3]的值100
8.8.6 注意事项
1.切片定义后不可以直接使用,需要让其引用到一个数组,或者make一个空间供切片来使用
var slice7 []int
fmt.Println(slice7)
运行结果:
[]
2.切片使用不能越界
3.简写方式:
(1) var slice = arr[0:end] ----> var slice := arr[:end]
(2) var slice = arr[start:len(arr)] ----->var slice = arr[start]
(3)var slice = arr[0:len(arr)] -----> var slice = arr[:]
4.切片可以继续切片
package main
import "fmt"
/**
切片
*/
func main() {
//定义数组:
var intarr [6]int = [6]int{3,6,9,1,4,7}
slice := intarr[1:3]
fmt.Println(slice)
slice6 := slice[1:2]
fmt.Println(slice6)
}
运行结果:
[9]
【5】切片可以动态增长
package main
import "fmt"
func main() {
//定义数组:
var intarr [6]int = [6]int{3,6,9,1,4,7}
//var slice []int = intarr[1:3]
slice := intarr[1:4]
fmt.Println(slice)
slice11 := append(slice, 88, 50)
fmt.Println("slice11:",slice11)
slice = append(slice, 88, 50)
fmt.Println(slice)
运行结果:
[6 9 1 88 50]
总结:
底层原理:
1.底层追加元素的时候,对数组进行扩容,老数组扩容为新数组
2.创建一个新数组,将老数组中的3,6,1复制到新数组中,在新数组中追加88,50
3.slice2底层数组的指向,指向的是新数组
4.在使用追加的时候,其实想要做的效果给sclice追加
slice = append(slice, 88, 50)
5.底层的新数组不能直接维护,需要通过切片间接维护操作
6.可以通过append函数将切片追加给切片
slice = append(slice,slice12…)
package main
import "fmt"
func main() {
var intarr [6]int = [6]int{3,6,9,1,4,7}
slice = append(slice, 88, 50)
slice12 := []int {99,44}
slice = append(slice,slice12...)
fmt.Println("切片中追加切片:",slice)
}
运行结果:
切片中追加切片: [6 9 1 88 50 99 44]
8.8.7 切片的拷贝
copy(b,a)
package main
import "fmt"
func main() {
var a []int = []int{1,4,7,3,6,9}
var b []int = make([]int,10)
//拷贝
copy(b,a) //将a中对应数组中元素内容复制到b中对应的数组中
fmt.Println(b)
}
运行结果:
[1 4 7 3 6 9 0 0 0 0]
9.map
9.1 map介绍
映射(map),Go语言中内置的一种类型,它将键值对相关联,我们可以通过键key来获取对应的值value,
类似其他语言的集合
键值对:一对匹配的信息
学生学号 -学生姓名
20095452 - 赵珊珊
20095459 - 张三
9.2 map基本语法
var map变量名 map[keytype]valuetype
PS: key、value的类型:bool、数字、string、指针、channel、
还可以是只包含前面几个类型的接口、结构体、数组
PS:key通常为int、string类型,value通常为数字(整数、浮点数)、string、map、结构体
PS:key: slice、map、function不可以
9.3 代码
map的特点:
(1)map集合在使用前一定要make
(2)map的key-value是无序的
(3)key是不可以重复的,如果重复,后一个value会替换前一个value
(4)value是可以重复的
(5)make函数的第二个参数size可以省略,默认就分配一个内存
package main
import "fmt"
/**
map
*/
func main() {
//定义一个map的变量
var userMap map[int]string
//只声明map,内存是没有分配控件
//比较通过make函数进行初始化,才会分配内存控件
userMap = make(map[int]string,10)
userMap[20095452] = "张三"
userMap[20095387] = "李四"
userMap[20096784] = "王五"
fmt.Println(userMap)
}
运行结果:
map[20095387:李四 20095452:张三 20096784:王五]
9.4 map的创建方式
1.方式1: make
var userMap map[int]string
userMap = make(map[int]string,10)
//定义一个map的变量
var userMap map[int]string
//只声明map,内存是没有分配控件
//比较通过make函数进行初始化,才会分配内存控件
userMap = make(map[int]string,10)
userMap[20095452] = "张三"
userMap[20095387] = "李四"
userMap[20096784] = "王五"
2.方式2:
b := make(map[int]string) 省略大小
b := make(map[int]string)
b[20095452] = "张三"
b[20095387] = "李四"
b[20096784] = "王五"
fmt.Println(b)
运行结果:
map[20095387:李四 20095452:张三 20096784:王五]
3.方式3:直接赋值
c := map[int]string{20095452:“张三”,20095387:“李四”,20096784:“王五”}
c := map[int]string{20095452:"张三",20095387:"李四",20096784:"王五"}
fmt.Println(c)
运行结果:
map[20095387:李四 20095452:张三 20096784:王五]
9.5 map的操作
9.5.1 增加和更新操作
map[“key”] = value ---->如果key还没有,就是增加,如果key存在就是修改
b := make(map[int]string)
b[20095452] = "张三"
b[20095387] = "李四"
b[20096784] = "王五"
运行结果:
map[20095387:李四 20095452:张三 20096784:王五]
9.5.2 删除操作
delete(map,“key”),delete是一个内置函数,
如果key存在,就删除该key-value,
如果key不存在,就不操作,但是也不会报错
c := map[int]string{20095452:"张三",20095387:"李四",20096784:"王五"}
delete(c,20095452)
运行结果:
map[20095387:李四 20096784:王五]
9.5.3 清空操作
(1)如果我们要删除map的所有key,没有一个专门的方法一次删除,可以遍历一下key,逐个删除
(2)或者map = make(…),make一个新的,让原来的成为垃圾,被gc回收
9.5.4 查找操作
value,flag := b[20095452]
b := make(map[int]string)
b[20095452] = "张三"
b[20095387] = "李四"
b[20096784] = "王五"
value,flag := b[20095452]
fmt.Println(value)
fmt.Println(flag)
运行结果:
张三
true
9.5.5 获取长度
len(map)
b := make(map[int]string)
b[20095452] = "张三"
b[20095387] = "李四"
b[20096784] = "王五"
fmt.Println(b)
fmt.Println(len(b))
运行结果:
map[20095387:李四 20095452:张三 20096784:王五]
3
9.6 遍历:for-range
b := make(map[int]string)
b[20095452] = "张三"
b[20095387] = "李四"
b[20096784] = "王五"
fmt.Println(b)
fmt.Println(len(b))
for key,value := range b{
fmt.Printf("key为%v,value为%v \n",key,value)
}
运行结果:
key为20095452,value为张三
key为20095387,value为李四
key为20096784,value为王五
9.7 加深难度
map里面的value放的又是map
package main
import "fmt"
/**
map
*/
func main() {
a := make(map[string]map[int]string)
a["班级1"] = make(map[int]string)
a["班级1"][20096677] = "露露"
a["班级1"][20098833] = "丽丽"
a["班级1"][20097722] = "菲菲"
a["班级2"] = make(map[int]string)
a["班级2"][20089911] = "小明"
a["班级2"][20085533] = "小龙"
a["班级2"][20087244] = "小飞"
for _,v1 := range a{
for k2,v2 := range v1{
fmt.Printf("key为:%v,value为%v \n",k2,v2)
}
}
}
运行结果:
key为:20096677,value为露露
key为:20098833,value为丽丽
key为:20097722,value为菲菲
key为:20089911,value为小明
key为:20085533,value为小龙
key为:20087244,value为小飞
10.面向对象
10.1 面向对象的引入
【1】Golang语言面向对象编程说明:
1.Golang也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。所以我们说Golang支持面向对象编程特性是比较准确的。
2.Golang没有类(class),Go语言的结构体(struct)和其他编程语言的类(class)有同等的地位,你可以理解Golang是基于struct来实现OOP特性的。
3.Golang面向对象编程非常简洁,去掉了传统的OOP语言的方法重载、构造函数和解析函数、隐藏的this指针等等。
4.Golang仍然有面向对象编程的继承、封装和多态的特性,只是实现的方式和其他OOP语言不一样,比如继承:Golang没有extends关键字,继承是通过匿名字段来实现的。
5.Golang面向对象(OOP)很优雅,OOP本身就是语言类型系统的一部分,通过接口(interface)关联,耦合性低,也非常灵活。后面同学们会充分体会到这个特点。也就是说在Golang中面向接口编程是非常重要的特性。
【2】结构体的引入
具体的对象:
一位老师:珊珊老师 姓名:赵珊珊 年龄:31岁 性别:女
可以使用变量来处理:
package main
/**
结构体的引入
*/
func main() {
//珊珊老师 姓名:赵珊珊 年龄:31 性别:女
var name string = "赵珊珊"
var age int = 31
var sex string = "女"
//马士兵
var name2 string = "马士兵"
var age2 int = 45
var sex2 string = "男"
}
缺点:
(1)不利于数据的管理、维护
(2)老师的很多属性属于一个对象,用变量管理太分散,后面获取一个对象的其他属性太麻烦了
10.2 结构体
10.2.1 结构体的引入
案例:老师结构体
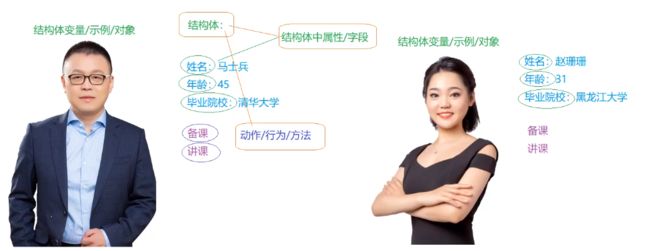
后续实践中按照自己的需求定义结构体即可
10.2.2 代码
package main
import "fmt"
/**
定义结构体
*/
//定义老师结构体,将老师中的各个属性统一放入结构体中管理
type Teacher struct {
//变量名字大写外界可以访问这个属性
Name string
Age int
School string
}
func main() {
//创建老师结构体的实例、对象
var t1 Teacher //var age int 一样
fmt.Println(t1)
t1.Name = "马士兵"
t1.Age = 45
t1.School = "清华大写"
fmt.Println(t1)
fmt.Println(t1.Name)
}
运行结果:
{ 0 }
{马士兵 45 清华大写}
马士兵
10.2.3 内存分析

10.2.4 结构体实例创建方式
1.方式1:直接创建
var t1 Teacher //var age int 一样
package main
import "fmt"
/**
定义结构体
*/
//定义老师结构体,将老师中的各个属性统一放入结构体中管理
type Teacher struct {
//变量名字大写外界可以访问这个属性
Name string
Age int
School string
}
func main() {
//创建老师结构体的实例、对象
var t1 Teacher //var age int 一样
fmt.Println(t1)
t1.Name = "马士兵"
t1.Age = 45
t1.School = "清华大写"
fmt.Println(t1)
fmt.Println(t1.Name)
}
2.方式2:
var t2 Teacher = Teacher{“赵珊珊”,31,“黑龙江大学”}
package main
import "fmt"
/**
定义结构体
*/
//定义老师结构体,将老师中的各个属性统一放入结构体中管理
type Teacher struct {
//变量名字大写外界可以访问这个属性
Name string
Age int
School string
}
func main() {
//方式2:
var t2 Teacher = Teacher{"赵珊珊",31,"黑龙江大学"}
fmt.Println(t2)
}
运行结果:
{赵珊珊 31 黑龙江大学}
3.方式3
var t3 *Teacher = new(Teacher)
package main
import "fmt"
/**
定义结构体
*/
//定义老师结构体,将老师中的各个属性统一放入结构体中管理
type Teacher struct {
//变量名字大写外界可以访问这个属性
Name string
Age int
School string
}
func main() {
//方式3:
var t3 *Teacher = new(Teacher)
//t是指针,t其实是指向的就是地址 应该给这个地址的指向的对象的字段赋值
(*t3).Name = "张三"
(*t3).Age = 31 //*t3的作用:根据地址取值
(*t3).School = "上海学院"
t3.School = "上海学院" //go编译器底层对 t3.School转换为(*t3).School
fmt.Println(*t3)
}
运行结果:
{张三 31 上海学院}
4.方式4
var t4 *Teacher = &Teacher{}
package main
import "fmt"
/**
定义结构体
*/
//定义老师结构体,将老师中的各个属性统一放入结构体中管理
type Teacher struct {
//变量名字大写外界可以访问这个属性
Name string
Age int
School string
}
func main() {
//方式4:
var t4 *Teacher = &Teacher{}
//t是指针,t其实是指向的就是地址 应该给这个地址的指向的对象的字段赋值
(*t4).Name = "张三"
(*t4).Age = 31
(*t4).School = "上海学院"
t4.School = "上海学院" //go编译器底层对 t3.School转换为(*t3).School
fmt.Println(*t4)
}
运行结果:
{张三 31 上海学院}
10.2.5 结构体之间的转换
1.结构体是用户单独定义的类型,和其他类型进行转换时需要有完全相同的字段(名字、个数和类型)
package main
import "fmt"
/**
结构体之间的转换
*/
type Student struct {
Age int
}
type Person struct {
Age int
}
func main() {
var s Student = Student{10}
var p Person = Person{ 15}
s = Student(p)
fmt.Println(s)
}
运行结果:
{15}
2.结构体进行type重新定义(相当于取别名),Golang认为是新的数据类型,但是相互间可以强转
s1 = Student(s2) 强转
package main
import "fmt"
/**
结构体之间的转换
*/
type Student struct {
Age int
}
type Stu Student
func main() {
var s1 Student = Student{19}
var s2 Stu = Stu{19}
s1 = Student(s2)
fmt.Println(s1)
fmt.Println(s2)
}
运行结果:
{19}
10.3 方法
10.3.1 基本介绍
在某些情况下,我们需要声明(定义)方法。比如Person结构体:除了有一些字段外(年龄,姓名…),Person结构体还有一些行为比如:可以说话、跑步…通过学习,还可以做算术题。这时就要用方法才能完成。
Golang中的方法是作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是struct.
10.3.2 方法的声明和调用
func(a A) test(){
}
type A struct{
Num int
}
func(a A) test(){
fmt.Println(a.Num)
}
调用: var t A
t.test()
说明:
1.func(a A) test(){} 表示A结构体有一个方法,方法名为test
2.(a A)体现test方法是和A类型绑定的
代码:
package main
import "fmt"
/**
方法
*/
type Person2 struct {
Name string
}
//给Person类型绑定一个方法
func (p Person2) test(){
fmt.Println("Test name = ",p.Name)
}
func main() {
var p Person2
p.Name = "tom"
p.test() //调用方法
}
运行结果:
Test name = tom
对上面的总结:
1.test方法和Person2类型绑定
2.test方法只能通过person类型的变量来调用,而不能直接调用,也不能使用其他类型变量来调用
3.func(p Person2) test{}… p表示哪个Person调用,p就表示谁,这点和函数传参非常相似,这里是值传递,拷贝一份传过去,p有点像Java里面的this
4.p这个形参名,可以由程序员指定,不是固定
10.3.3 方法快速入门
1.给Person结构体添加speak方法,输出xxx是一个好人
//给Person2结构体添加speak方法,输出 xxx是一个好人
func (p Person2) speak(){
fmt.Println(p.Name+"是一个好人")
}
2.给Person2结构体添加jisuan方法,可以计算1+…+1000的结果,说明方法体内可以函数一样,进行各种运算
func (p Person2) jisuan(){
result := 0
for i:= 1;i<=1000;i++{
result += i
}
fmt.Println(p.Name,"计算的结果是=",result)
}
3.给Person2结构体添加jisuan2方法,该方法可以接收一个数n,计算1+…+n的结果
func (p Person2) jisuan2(n int){
result := 0
for i:= 1;i<= n;i++{
result += i
}
fmt.Println(p.Name,"计算的结果是=",result)
}
4.给Person结构体添加getSum方法,可以计算两个数的和,并返回结果
func (p Person2) getSum(num1 int,num2 int) int{
return num1 + num2
}
调用:
result := p.getSum(10,20)
代码:
package main
import "fmt"
/**
方法
*/
type Person2 struct {
Name string
}
//给Person类型绑定一个方法
func (p Person2) test(){
fmt.Println("Test name = ",p.Name)
}
//给Person2结构体添加speak方法,输出 xxx是一个好人
func (p Person2) speak(){
fmt.Println(p.Name+"是一个好人")
}
//给Person结构体添加jisuan方法,可以计算从1+...+1000的结果
func (p Person2) jisuan(){
result := 0
for i:= 1;i<=1000;i++{
result += i
}
fmt.Println(p.Name,"计算的结果是=",result)
}
//给Person结构体添加jisuan2方法,该方法可以接收1个参数n,计算从1+...+n的结果
func (p Person2) jisuan2(n int){
result := 0
for i:= 1;i<= n;i++{
result += i
}
fmt.Println(p.Name,"计算的结果是=",result)
}
//给Person结构体添加getSum方法,可以计算两个数的和,并返回结果
func (p Person2) getSum(num1 int,num2 int) int{
return num1 + num2
}
func main() {
var p Person2
p.Name = "tom"
p.test() //调用方法
p.speak()
p.jisuan()
p.jisuan2(10)
result := p.getSum(10,20)
fmt.Println(result)
}
运行结果:
Test name = tom
tom是一个好人
tom 计算的结果是= 500500
tom 计算的结果是= 55
30
10.3.4 方法的调用和传参机制原理
说明:方法的调用和传参机制和函数基本一样,不一样的地方是方法调用时,会将调用方法的变量,也做实参也传递给方法。下面我们举例说明:
案例1:画出前面getSum方法的执行过程+说明

说明:
1.在通过一个变量去调用方法时,其调用机制和函数一样
2.不一样的地方是,变量调用方法时,该变量本身也会作为一个参数传递到方法(如果变量时值类型,则进行值拷贝,如果变量时引用类型,则进行地址拷贝)
案例2:请编写一个程序,要求如下:
(1)声明一个结构体Circle,字段为radius
(2)声明一个方法area和Circle绑定,可以返回面积
提示:画出area执行过程+ 说明
代码:
package main
import "fmt"
type Circle struct {
radius float64
}
func (circle Circle) area() float64{
total := 3.14 * circle.radius * circle.radius
return total
}
func main() {
var circle Circle
circle.radius = 4.0
total := circle.area()
fmt.Println(total)
}
运行结果:
50.24
内存分析:
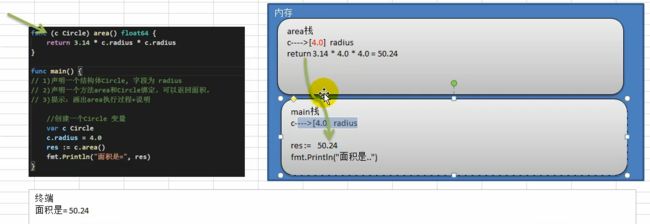
10.3.5 方法的声明(定义)
func (recevier type) methodName(参数列表) (返回值列表){
方法体
return 返回值
}
例:
func (circle Circle) area() float64{
total := 3.14 * circle.radius * circle.radius
return total
}
1.参数列表:表示方法输入
2.recevier type:表示这个方法和type这个类型绑定,或者说该方法作用于type类型
3.recevier type:type可以是结构体,也可以其他的自定义类型
4.recevier:就是type类型的一个变量(实例),比如:Person结构体的一个变量
5.返回值列表:表示返回的值,可以多个
6.方法主体:表示为了实现某一功能代码块
7.return 语句不是必须的,
如果没有返回值列表,就没有return,
如果有返回值列表,就有return
10.3.6 方法注意事项和细节讨论
(1)结构体类型是值类型,在方法调用中,遵守值类型的传递机制,是值拷贝传递方式
(2)如果程序员希望在方法中,修改结构体变量的值,可以通过结构体指针的方式来处理
package main
import "fmt"
type Circle struct {
radius float64
}
//为了提高效率,通常我们方法和结构体指针类型绑定
func (circle *Circle) area2() float64{
//因为circle是指针,因此我们标准的访问其字段的方式是(*circle).radius
//total := 3.14 * (*circle).radius * (*circle).radius
//(*circle).radius 等价 circle.radius
total := 3.14 * circle.radius * circle.radius
return total
}
func main() {
var circle Circle
circle.radius = 4.0
total2 := (&circle).area()
//编译器底层做了优化,(&circle)等价 circle.area()
//因为编译器会自动的给加上 &circle
total3 := circle.area()
fmt.Println(total2)
fmt.Println(total3)
fmt.Println(total)
}
运行结果:
50.24
内存分析:
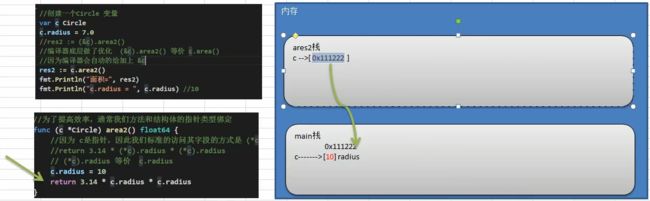
(3)Golang中的方法作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是Struct,比如int,float32等都可以有方法
(4)方法的访问范围控制的规则,和函数一样。方法名首字母小写,只能在本包访问,方法首字母大写,可以在本包和其他包访问
(5)如果一个类型实现了string()这个方法,那么fmt.Println默认会调用这个变量的string()进行输出
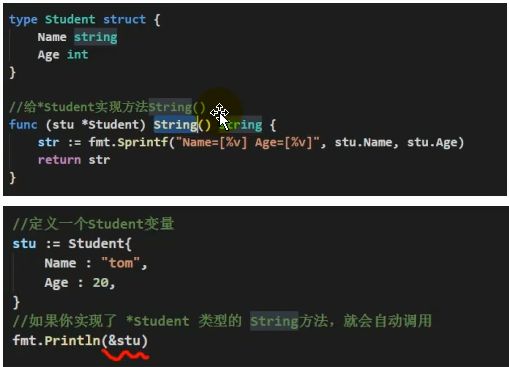
10.3.7 课堂练习题
1.编写结构体(MethodUtils),编程一个方法,方法不需要参数,在方法中打印一个10*8的矩形,在main方法中调用该方法。
代码:
package main
import "fmt"
type Range struct {
}
func (range1 *Range) Print(){
for i := 0;i< 10;i++{
for j := 0;j <= 8;j++{
fmt.Print("*")
}
fmt.Println("\n")
}
}
func main() {
var range1 Range
range1.Print()
}
运行结果:
***********
***********
***********
***********
***********
***********
***********
***********
2.编写一个方法,提供m和n两个参数,方法中打印一个m*n的矩形
代码:
package main
import "fmt"
type Range struct {
}
func (range1 *Range) Print(m int,n int){
for i := 0;i< m;i++{
for j := 0;j <=n ;j++{
fmt.Print("*")
}
fmt.Println("\n")
}
}
func main() {
var range1 Range
range1.Print(5,6)
}
运行结果:
*******
*******
*******
*******
*******
3.编写一个方法算该矩形的面积(可以接收长len,宽width),将其作为方法返回值。在main方法中调用该方法,接收返回的面积并打印。
代码:
package main
import "fmt"
type Range struct {
len int
width int
}
func (range1 *Range) Print(){
for i := 0;i< range1.len;i++{
for j := 0;j <=range1.width ;j++{
fmt.Print("*")
}
fmt.Println("\n")
}
}
func main() {
var range1 Range = Range{10,8}
range1.Print()
}
运行结果:
*********
*********
*********
*********
*********
*********
*********
*********
*********
*********
10.3.8 方法和函数的区别
1.调用方式不一样
函数的调用方式: 函数名(实参列表)
方法的调用方式: 变量.方法名(实参列表)
2.对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
3.对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样可以
总结:
(1)不管调用形式如何,真正决定是值拷贝还是地址拷贝,看这个方法是和哪个类型绑定
(2)如果是和值类型绑定,比如(p Person),则是值拷贝
如果是和指针类型绑定,比如(p *person),则是地址拷贝
10.4 面向对象编程应用实例
10.4.1 步骤
1.声明(定义)结构体,确定结构体名
2.编写结构体字段
3.编写结构体的方法
10.4.2 学生案例
1.编写一个Student结构体,包含name、gender、age、id、score字段,
分别为string,string,int,int,float64类型。
2.结构体中声明一个say方法,返回string类型,方法返回信息中包含所有字段值
3.在main方法中,创建Student结构体实例(变量),并访问say方法,并将调用结果打印输出。
代码:
package main
import "fmt"
/**
面向对象实例
*/
type Student2 struct {
Name string
Gender string
Age int
Id int
Score float64
}
func (student *Student2) say() string{
infoStr := fmt.Sprintf("student的信息 name=[%v] gender=[%v] age=[%v] id=[%v] score=[%v]",
student.Name,student.Gender,student.Age,student.Id,student.Score)
return infoStr
}
func main() {
var student Student2 = Student2{"张三","男",23,0701,87.6}
sayStr := student.say()
fmt.Println(sayStr)
}
运行结果:
student的信息 name=[张三] gender=[男] age=[23] id=[449] score=[87.6]
10.5 工厂模式
10.5.1 结构体首字母小写
如果model包中的结构体首字母小写,引入后,不能直接使用,可以工厂模式解决。
代码:
结构体文件:
package model
/**
学生model类
*/
type student3 struct {
Name string
Score float64
}
//因为student3结构体首字母小写,因此只能在model中使用
//我们通过工厂模式来解决
func NewStudent(n string,s float64) *student3{
return &student3{
Name: n,
Score: s,
}
}
main文件:
package main
import (
"com.tangguanlin/main2/model"
"fmt"
)
/**
工厂方法解决结构体首字母小写
*/
func main() {
var stu = model.NewStudent("tom",88.8)
fmt.Println("name=",stu.Name," score=",stu.Score)
}
运行结果:
name= tom score= 88.8
10.5.2 字段首字母小写
如果字段首字母小写,则在其他包不可以直接访问,我们可以提供一个方法解决
结构体文件:
package model
/**
学生model类
*/
type student3 struct {
name string
score float64
}
//因为student3结构体首字母小写,因此只能在model中使用
//我们通过工厂模式来解决
func NewStudent(n string,s float64) *student3{
return &student3{
name: n,
score: s,
}
}
//如果score字段首字母小写,则在其他包不可以直接访问
//我们可以提供一个方法来解决
func (stu *student3) GetScore() float64{
return stu.score
}
func (stu *student3) SetScore(score float64){
stu.score = score
}
main文件:
package main
import (
"com.tangguanlin/main2/model"
"fmt"
)
/**
工厂方法解决字段首字母小写
*/
func main() {
var stu = model.NewStudent("tom",88.8)
fmt.Println(" score=",stu.GetScore())
}
运行结果:
name= tom score= 88.8
10.6 封装
10.6.1 封装介绍
封装就是把抽象出的字段和对字段的操作封装在一起,数据被保护在内部,程序的其他包只有被授权的操作(方法),才能对字段进行操作。
10.6.2 封装的理解和好处
(1)隐藏实现细节
(2)可以对数据进行验证,保证安全合理
10.6.3 如何体现封装
(1)对结构体中的属性进行封装 ----属性小写
(2)通过方法,包实现封装
10.6.4 封装的实现步骤
1.将结构体、字段(属性)的首字母小写(不能导出了,其他包不能使用,类似private)
2.给结构体所在的包提供一个工厂模式的函数,首字母大写。类似一个构造函数
3.提供一个首字母大写的SetXxx方法(类似于其他语言的public),用于对属性判断并赋值
func (var 结构体类型名) SetXXX(参数列表)(返回值列表){
//加入数据校验的业务逻辑
var.字段 = 参数
}
4.提供一个首字母大写的GetXxx方法(类似于其他语言的public),用于获取属性的值
func (var 结构体类型名) GetXxx(){
return var.age
}
特别说明:在Golang开发中并没有特别强调封装,这点并不像Java,所以体现学过Java的朋友,不用总是用Java的语法特性来看待Golang,Golang本身对面向对象的特性做了简化。
10.6.5 快速入门案例
请大家写一个程序(person.go),不能随便查看人的年龄,工资等隐私,并对输入的年龄进行合理的验证。
设计:model包(person.go)
main包(main.go 调用person结构体)
代码实现:
person.go
package model
import "fmt"
type person struct {
Name string
age int
sal float64
}
func NewPerson(name string) *person{
return &person{Name: name,}
}
func (p *person) GetAge() int{
return p.age
}
func (p *person) SetAge(age int) {
if(age >0 && age < 150){
p.age = age
}else{
fmt.Println("年龄不符合范围")
}
}
func (p *person) GetSal() float64{
return p.sal
}
func (p *person) SetSal(sal float64){
if(sal >= 3000 && sal <=30000){
p.sal = sal
}else{
fmt.Println("薪水范围不正确")
}
}
main.go
package main
import (
"com.tangguanlin/main2/model"
"fmt"
)
/**
封装快速入门案例
*/
func main() {
p := model.NewPerson("smith")
p.SetAge(86)
p.SetSal(3012.28)
fmt.Println(p.Name)
fmt.Println(p.GetAge())
fmt.Println(p.GetSal())
}
运行结果:
smith
86
3012.28
10.7 继承
10.7.1 为什么需要继承
1.Pupil和Graduate两个结构体的字段和方法几乎相同,但是我们却写了相同的2份代码,代码复用性不强
2.出现代码冗余,而且代码不利于维护,同时也不利于功能的扩展
3.解决方法-通过继承方式来解决 代码的复用性
10.7.2 继承介绍
继承可以解决代码复用,让我们的编程更加靠近人类思维。
当多个结构体存在相同的属性和方法时,可以从这些结构体中抽象出结构体(比如从小学生和大学生中抽象出student),在该结构体中定义这些相同的属性和方法。
其他结构体不需要重新定义这些属性和方法,只需要嵌套一个student匿名结构体即可。
也就是说:在Golang中,如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性。

10.7.3 基本语法
嵌套匿名结构体的基本语法
type Goods struct{ //父类
Name string
Price int
}
type Book struct{ //子类
Goods //这里就是嵌套匿名结构体Goods
Writer string
}
10.7.4 快速入门案例
案例:我们对extends.go改进,使用嵌套匿名结构体的方式来实现继承特性,请大家注意体会这样编程的好处。
代码:
package main
import (
"fmt"
)
/**
继承
*/
//学生结构体 父类
type student4 struct {
Name string
Age int
score float64
}
//小学生结构体 子类
type Pupil struct {
student4 //嵌入Student匿名结构体
}
//大学生结构体 子类
type Graduate struct {
student4 //嵌入Student匿名结构体
}
func (stu *student4) ShowInfo(){
fmt.Printf("学生名=%v 年龄=%v 成绩=%v \n",stu.Name,stu.Age,stu.score)
}
func (stu *student4) SetScore(score float64){
stu.score = score
}
func (stu *student4) GetScore() float64{
return stu.score
}
func (pupil *Pupil) testing(){
fmt.Println("小学生正在考试中....")
}
func (graduate *Graduate) testing(){
fmt.Println("大学生正在考试中....")
}
//使用
func main() {
pupil := &Pupil{}
pupil.student4.Name = "tom"
pupil.student4.Age = 8
pupil.testing()
pupil.student4.SetScore(70)
pupil.student4.ShowInfo()
graduate := &Graduate{}
graduate.student4.Name = "mary"
graduate.student4.Age = 28
graduate.testing()
graduate.student4.SetScore(90)
graduate.student4.ShowInfo()
}
运行结果:
小学生正在考试中....
学生名=tom 年龄=8 成绩=70
大学生正在考试中....
学生名=mary 年龄=28 成绩=90
10.7.5 继承的好处
1.代码的复用性提高了
2.代码的扩展性和维护性提高了
10.7.6 继承的深入讨论
1.结构体可以使用嵌套匿名结构体所有的字段和方法,即:首字母大写或者小写的字段、方法,都可以使用
2.匿名结构体字段访问可以简化
pupil.student4.ShowInfo()
可以简化为:
pupil.ShowInfo()
func main() {
pupil := &Pupil{}
pupil.student4.Name = "tom"
pupil.student4.Age = 8
pupil.testing()
pupil.student4.SetScore(70)
pupil.student4.ShowInfo()
//上面的写法可以简化
pupil.SetScore(71)
pupil.ShowInfo()
graduate := &Graduate{}
graduate.student4.Name = "mary"
graduate.student4.Age = 28
graduate.testing()
graduate.student4.SetScore(90)
graduate.student4.ShowInfo()
//方面的写法可以简化
graduate.SetScore(91)
graduate.ShowInfo()
}
对上面的代码小结:
(1)当我们直接通过pupil访问字段或者方法时,期执行流程如下,比如pupil.Name
(2)编译器会先看pupil对应的类型有没有Name,如果有,则直接调用Pupil类型的Name字段
(3)如果没有就去看pupil中嵌入的匿名结构体Student有没有声明Name字段,如果有就调用,如果没有继续查找,如果都找不到就报错。
3.当结构体和匿名结构体有相同的字段或者方法时,编译器采用就近原则访问,
如希望访问匿名结构体的字段和方法,可以通过匿名结构体名来区分。
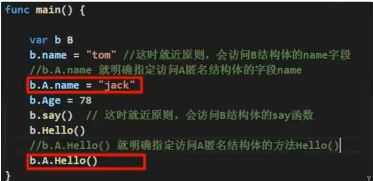
4.结构体嵌入两个或多个匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时,就必须明确指定匿名结构体名字,否则编译报错。
type A struct{
Name string
age int
}
type B struct{
Name string
Score float64
}
type c struct{
A
B
//name string
}
func main(){
var c C
//如果c没有Name字段,而A和B有Name,这时就必须通过指定匿名结构体名字来区分
//所以,c.Name就会报编译错误,这个规则对方法也是一样的
c.A.Name = "tom"
fmt.Println(c)
}
5.如果一个struct嵌套了一个有名结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方法时,必须带上结构体的名字。
type A struct{
Name string
Age int
}
type c struct{
a A //有名结构体 组合关系
}
func main(){
//如果C中是一个有名结构体,则访问有名结构体的字段时,就必须带上有名结构体的名字
//比如 c.A.Name
var c C
c.Name = "jack" //报错
c.A.Name = "jack" //正确
}
6.嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值。
package main
import "fmt"
type Goods struct{ //商品
Name string
Price float64
}
type Brand struct{ //品牌
Name string
Address string
}
type TV struct{ //电视剧
Goods
Brand
}
func main(){
tv1 := TV{Goods{"电视剧001",5000.99},Brand{"海尔","青岛"},}
tv2 := TV{Goods{Name:"电视剧002",Price:5000.99},
Brand{Name:"海尔",Address:"青岛"},
}
fmt.Println("tv1",tv1)
fmt.Println("tv2",tv2)
}
运行结果:
tv1 {{电视剧001 5000.99} {海尔 青岛}}
tv2 {{电视剧002 5000.99} {海尔 青岛}}
10.7.7 课堂练习
结构体的匿名字段是基本数据类型,如何访问。下面代码输出什么?
type Monster struct{
Name string
Age int
}
type E struct{
Monster
int
n int
}
func main(){
var e E
e.Name = "狐狸精"
e.Age = 30
e.int = 20 //没有变量名,就直接给int赋值
e.n = 40 //赋值时要指定变量名
}
说明:
1.如果一个结构体有int类型的匿名字段,就不能有第二个
2.如果需要有多个int的字段,则必须给int字段指定名字
10.7.8 多重继承
如果一个struct嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名结构体的字段和方法,从而实现了多重继承。
package main
import "fmt"
type Goods struct{ //商品
Name string
Price float64
}
type Brand struct{ //品牌
Name string
Address string
}
type TV struct{ //电视剧
Goods
Brand
}
func main(){
tv1 := TV{Goods{"电视剧001",5000.99},Brand{"海尔","青岛"},}
tv2 := TV{Goods{Name:"电视剧002",Price:5000.99},
Brand{Name:"海尔",Address:"青岛"},
}
fmt.Println("tv1",tv1)
fmt.Println("tv2",tv2)
fmt.Println(tv.Goods.Name) //通过匿名结构体类型名来区分
}
运行结果:
tv1 {{电视剧001 5000.99} {海尔 青岛}}
tv2 {{电视剧002 5000.99} {海尔 青岛}}
多重继承细节说明:
1.如嵌入的匿名结构体有相同的字段名或者方法名,则在访问时,需要通过匿名结构体类型名来区分
fmt.Println(tv.Goods.Name)
2.为了保证代码的简洁性,建议大家尽量不使用多重继承。(在很多语言都把多重继承拿掉了,比如Java)
10.8 接口
interface
10.8.1 接口介绍
一个程序就是一个世界,在现实世界存在的情况,在程序中也会出现。我们用程序来模拟一下前面的应用场景。
按顺序,我们应该讲解多态,但是在讲解多态前,我们需要讲解接口(interface),因为在Golang中,多态特性主要是通过接口来体现的。
interface类型可以定义一组方法,但是这些不需要实现。并且interface不能包含任何变量。到某个自定义类型(比如结构体Phone)要使用的时候,再根据具体情况把这些方法写出来。
10.8.2 为什么需要接口

10.8.3 接口快速入门
代码:
package main
import "fmt"
/**
接口快速入门
*/
//定义一个接口
type Usb interface {
//定义了2个没有实现的方法
Start()
Stop()
}
//手机
type Phone struct {
}
//让phone 实现Usb接口方法
func (p Phone) Start(){
fmt.Println("手机开始工作...")
}
func (p Phone) Stop(){
fmt.Println("手机停止工作...")
}
//相机
type Camera struct {
}
//让Camera实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作...")
}
func (c Camera) Stop(){
fmt.Println("相机停止工作....")
}
//计算机
type Computer struct {
}
//编写一个方法 working
//方法接收usb接口类型变量,只要是实现了Usb接口
//所谓实现了Usb接口,就是指实现了Usb接口定义的所有方法
func (c Computer) Working(usb Usb){ //这里体现的是 多态的概念
//通过usb接口变量来调用start和stop方法
usb.Start()
usb.Stop()
}
//主方法
func main() {
//先创建结构体变量
computer := Computer{}
phone := Phone{}
camera := Camera{}
//关键点
computer.Working(phone)
computer.Working(camera)
}
运行结果:
手机开始工作...
手机停止工作...
相机开始工作...
相机停止工作....
说明:上面的代码就是一个接口编程的快速入门案例。
10.8.4 接口语法
接口语法:
type 接口名 interface {
method1(参数列表) 返回值列表
method2(参数列表) 返回值列表
}
比如:
//定义一个接口
type Usb interface {
//定义了2个没有实现的方法
Start()
Stop()
}
实现接口语法: 必须实现所有方法
func(t 自定义类型1) method1(参数列表) 返回值列表{
//方法实现
}
func(t 自定义类型) method2(参数列表) 返回值列表{
//方法实现
}
如:
//让phone 实现Usb接口方法
func (p Phone) Start(){
fmt.Println("手机开始工作...")
}
func (p Phone) Stop(){
fmt.Println("手机停止工作...")
}
小结说明:
1.接口里的方法都没有方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低耦合的思想。
2.Golang中的接口,不需要显示的实现。只要一个变量,含有接口类型中的所有方法,那么这个变量就实现了这个接口。因此,Golang中没有implement这样的关键字。
10.8.5 接口应用场景
对于初学者来讲,理解接口的概念并不算太难,难的是不知道什么时候使用接口,下面我列举几个应用场景:
1.说现在美国要制造轰炸机,武装直升机,专家只需要把飞机需要的功能/规格定下来即可,然后让别的人具体实现即可。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TSrbCNca-1639223522785)(https://gitee.com/tangguanlin2006/image/raw/master/20211128231940.png)]
2.说现在有一个项目经理,管理3个程序员,开发一个软件,为了控制和管理软件开发,项目经理可以定义一些借口,然后由程序员具体实现。

10.8.6 注意实现和细节
1.接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)
var a A = stu //接口实现类 可以赋值给接口
package main
import "fmt"
type A interface {
Say()
}
type Stu2 struct {
Name string
}
func (stu Stu2) Say(){
fmt.Println("stu Say()")
}
func main() {
var stu Stu2
var a A = stu //接口实现类 可以赋值给接口
fmt.Println(a)
}
2.接口中所有的方法都没有方法体,即都是没有实现的方法
3.在Golang中,一个自定义elixir需要将某个接口的所有方法都实现,我们说这个自定义类型实现了该接口。
4.一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型
5.只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型
6.一个自定义类型可以实现多个接口
package main
import "fmt"
type A interface {
Say()
}
type B interface {
Hello()
}
type Monster struct {
}
func (m Monster) Say(){ //Monster实现A接口
fmt.Println("say....")
}
func (m Monster) Hello(){ //Monster实现B接口
fmt.Println("hello...")
}
func main() {
//Monster实现了A接口和B接口
var monster Monster
var a2 A = monster
var b B = monster
a2.Say()
b.Hello()
}
运行结果:
say....
hello...
7.Golang接口中不能有任何变量
8.一个接口(比如A接口)可以继承多个别的接口(比如B、C接口),这时如果要实现A接口,也必须将B、C接口的方法也全部实现。
package main
import "fmt"
/**
接口实现接口
*/
type BB interface { //BB接口
testBB()
}
type CC interface { //CC接口
testCC()
}
type AA interface { //AA接口 实现了BB接口和CC接口
BB
CC
testAA()
}
//如果我们需要实现AA这个接口,就需要将BB接口,CC接口的方法都实现
type Student5 struct {
}
func (stu Student5) testBB(){
fmt.Println("testBB")
}
func (stu Student5) testCC(){
fmt.Println("testCC")
}
func (stu Student5) testAA(){
fmt.Println("testAA")
}
func main() {
var stu5 Student5
var aa AA = stu5
aa.testAA()
var bb BB = stu5
bb.testBB()
var cc CC = stu5
cc.testCC()
}
运行结果:
testAA
testBB
testCC
9.interface类型默认是一个指针(引用类型),如果没有对interface初始化就使用,那么会输出nil
10.空接口interface{} 没有任何方法,所以所有类型都实现了空接口,即我们可以把任何一个变量赋给空接口。
10.8.7 课堂练习
以下代码,有没有错误,你能得出哪些结论?
type A interface{
test01()
test02{}
}
type B interface{
test01()
test03()
}
type stu struct{
}
func (stu Stu) test01{
}
func (stu Stu) test02{
}
func (stu Stu) test03{
}
func main(){
stu := Stu{}
var a A = stu
var b B = stu
fmt.Println(a,b)
}
答案:以上代码正确
type A interface{
test01()
test02{}
}
type B interface{
test01()
test03()
}
type C interface{
A
B
}
func main{
}
结论:以上代码正确
10.8.8 接口最佳实践
实现对Hero结构体切片的排序:sort.Sort(data Interface)
代码:
package main
import (
"fmt"
"math/rand"
"sort"
)
/***
接口最佳实践
*/
//1.声明Hero结构体
type Hero struct {
Name string
Age int
}
//2.定义一个Hero结构体切片类型
type HeroSlice []Hero
//3.实现Interface接口
func (hs HeroSlice) Len() int {
return len(hs)
}
//排序标准 less方法就是决定你使用声明标准进行排序
//按age从小到大排序
func (hs HeroSlice) Less(i,j int) bool {
return hs[i].Age < hs[j].Age
}
func (hs HeroSlice) Swap(i,j int) {
temp := hs[i]
hs[i] = hs[j]
hs[i] = temp
}
//测试
func main() {
var heroes HeroSlice
for i:= 0;i<10;i++{
hero := Hero{
Name : fmt.Sprintf("英雄%d",rand.Intn(100)),
Age : rand.Intn(100),
}
//将hero append到heroes切片
heroes = append(heroes,hero)
}
//排序前顺序
fmt.Println("排序前")
for _,v := range heroes{
fmt.Println(v)
}
//调用sort.Sort
sort.Sort(heroes)
//排序后顺序
fmt.Println("排序后")
for _,v := range heroes{
fmt.Println(v)
}
}
运行结果:
排序前
{英雄81 87}
{英雄47 59}
{英雄81 18}
{英雄25 40}
{英雄56 0}
{英雄94 11}
{英雄62 89}
{英雄28 74}
{英雄11 45}
{英雄37 6}
排序后
{英雄56 0}
{英雄37 6}
{英雄94 11}
{英雄81 18}
{英雄25 40}
{英雄11 45}
{英雄47 59}
{英雄28 74}
{英雄81 87}
{英雄62 89}
10.8.9 接口和继承的比较
实现接口 VS 继承
大家听到现在,可能会对实现接口和继承比较迷茫了,这个问题,那么他们究竟有什么区别呢?

总结: 实现接口 可以理解为 继承 的一种补充 想有一个功能的扩展(实现接口)
扩展功能,但又没有破坏原来的继承关系
代码:
package main
import "fmt"
/**
继承 和 接口
*/
//Monkey 结构体
type Monkey struct {
Name string
}
func (monkey *Monkey) climbing(){
fmt.Println(monkey.Name,"生来会爬树...")
}
//SmallMonkey结构体
type SmallMonkey struct {
Monkey //继承
}
//定义接口 鸟飞翔
type BirdAble interface {
Flying()
}
//定义接口 鱼 游泳
type FishAble interface {
Swimming()
}
//SmallMonkey 实现 BirdAble 接口
func (smallMonkey *SmallMonkey) Flying(){
fmt.Println(smallMonkey.Name,"通过学习,会飞翔")
}
//SmallMonkey 实现 FishAble 接口
func (smallMonkey *SmallMonkey) Swimming(){
fmt.Println(smallMonkey.Name,"通过学习,会游泳")
}
func main() {
//创建 SmallMonkey 实例
smallMoney := SmallMonkey{Monkey{"悟空"}}
smallMoney.climbing()
smallMoney.Flying()
smallMoney.Swimming()
}
运行结果:
悟空 生来会爬树...
悟空 通过学习,会飞翔
悟空 通过学习,会游泳
小结:
1.当A结构体继承了B结构体后,那么A结构体就自动的继承了B结构体的字段和方法,可以直接使用
2.当A结构体需要某个功能,同时又不希望去破坏继承关系,则可以去实现某个接口接口。因此我们可以认为,实现接口是对继承机制的补充。
接口的优点:
1.不破坏原来的继承关系
2.让公共的功能写到一起,不会每个地方都一份,导致相同的功能多份代码
接口和继承解决的问题不同:
。继承的价值主要在于:解决代码的复用性和可维护性
。接口的价值主要在于:设计,设计好各种规范(方法),让其他自定义类型去实现这些方法
接口比继承更加灵活
继承是is -a 的关系,而接口只需满足 like -a 觉得关系
10.9 多态
10.9.1 基本介绍
变量(实例)具有多种形态。面向对象的第三大特征,在Go语言,多态特征是通过接口来实现的。可以按照统一的接口来调用不同的实现。这时接口变量就呈现不同的形态。
10.9.2 快速入门
在前面的Usb接口案例,Usb usb,既key接收手机变量,有可以接收相机变量,就体现了Usb接口多态.
代码:
package main
import "fmt"
/**
接口快速入门
*/
//定义一个接口
type Usb interface {
//定义了2个没有实现的方法
Start()
Stop()
}
//手机
type Phone struct {
}
//让phone 实现Usb接口方法
func (p Phone) Start(){
fmt.Println("手机开始工作...")
}
func (p Phone) Stop(){
fmt.Println("手机停止工作...")
}
//相机
type Camera struct {
}
//让Camera实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作...")
}
func (c Camera) Stop(){
fmt.Println("相机停止工作....")
}
//计算机
type Computer struct {
}
//编写一个方法 working
//方法接收usb接口类型变量,只要是实现了Usb接口
//所谓实现了Usb接口,就是指实现了Usb接口定义的所有方法
func (c Computer) Working(usb Usb){ //这里体现的是 多态的概念
//通过usb接口变量来调用start和stop方法
usb.Start()
usb.Stop()
}
//主方法
func main() {
//先创建结构体变量
computer := Computer{}
phone := Phone{}
camera := Camera{}
//关键点
computer.Working(phone)
computer.Working(camera)
}
运行结果:
手机开始工作...
手机停止工作...
相机开始工作...
相机停止工作....
usb接口变量就体现出多态的特点
10.9.3 接口体现多态特征
1.多态参数
在前面的Usb接口案例,Usb usb,即可以接收手机变量,又可以接收相机变量,就体现了Usb接口多态
2.多态数组
演示一个案例:给Usb数组中,存放Phone结构体和Camera结构体变量
代码:
package main
import "fmt"
/**
多态数组
*/
//定义一个接口
type Usb interface {
//定义了2个没有实现的方法
Start()
Stop()
}
//手机
type Phone struct {
}
//让phone 实现Usb接口方法
func (p Phone) Start(){
fmt.Println("手机开始工作...")
}
func (p Phone) Stop(){
fmt.Println("手机停止工作...")
}
//相机
type Camera struct {
}
//让Camera实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作...")
}
func (c Camera) Stop(){
fmt.Println("相机停止工作....")
}
//计算机
type Computer struct {
}
//编写一个方法 working
//方法接收usb接口类型变量,只要是实现了Usb接口
//所谓实现了Usb接口,就是指实现了Usb接口定义的所有方法
func (c Computer) Working(usb Usb){
//通过usb接口变量来调用start和stop方法
usb.Start()
usb.Stop()
}
//主方法
func main() {
fmt.Println("接口数组多态性......")
//定义一个接口数组,可以存放Phone和camera的结构体变量
//这里就体现出多态数组
var usbArr [3]Usb //接口数组
usbArr[0] = Phone{}
usbArr[1] = Phone{}
usbArr[2] = Camera{}
for i := 0;i < len(usbArr);i++{
computer.Working(usbArr[i])
}
}
运行结果:
接口数组多态性......
手机开始工作...
手机停止工作...
手机开始工作...
手机停止工作...
相机开始工作...
相机停止工作....
当数组元素是Phone类型时,调用Phone类型的start()和stop(),
当数组元素是Camera类型时,调用Camera类型的start()和stop().
利用接口,可以实现接口里面放不同的类型元素。
11.Go并发
11.1 goroutine引入
需求:要求统计1-20000(如果900000万呢)的数字中,哪些是素数?
分析思路:
1.传统的方法,就是使用一个循环,循环的判断各个数是不是素数。 -----很慢
2.使用并发或者并行的方式,将统计素数的任务分配给多个goroutine去完成,这时就会使用到goroutine。
11.2 goroutine基本介绍
协程 goroutine
11.2.1 进程和线程说明
1.进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
打开迅雷,就启动 迅雷线程
下载 封神榜,就是一个线程,一个下载任务。
2.线程是进程的一个执行实例,是程序执行的最小单位,它是比进程更小的能独立运行的基本单位
3.一个进程可以创建和销毁多个线程,同一个进程中的多个线程可以并发执行。
4.一个程序至少有一个进程,一个进程至少有一个线程
11.2.2 示意图

11.2.3 并发和并行
1.并发:多线程程序在单核上运行
2.并行:多线程程序在多核上运行
并发:因为是在一个cpu上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),从人的角度看,好像这10个线程都在运行,但是从微观上看,在某一个时间点看,其实只有一个线程在执行,这就是并发。
并行:因为是多个cpu上(比如有10个cpu),比如有10个线程,每个线程执行10毫秒(各自在不同的cpu上执行),从人的角度看,这10个线程都在运行,但是从微观上看,在某一个时间点看,也同时有10个线程在执行,这就是并行。
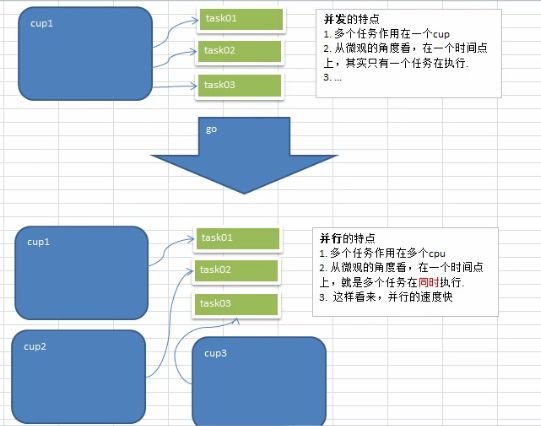
传统的编程语言,并发也是在一个cpu上执行的。
11.2.4 Go主线程和Go协程
1.Go主线程(Java中的进程),一个Go主线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程。
2.==Go协程(Java中的线程)==的特点:
。有独立的栈空间
。共享程序堆空间
。调度由用户控制
。协程是轻量级的线程
示意图:
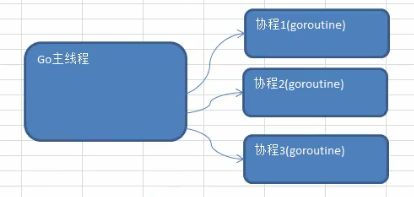
11.3 goroutine快速入门
11.3.1 案例说明
请编写一个程序,完成如下功能:
1.在主线程(可以理解为进程)中,开启一个goroutine,该协程每隔1秒输出“hello world”
2.在主线程中也每隔1秒输出“hello,golang”,输出10次后,退出程序
3.要求主线程和goroutine同时执行
4.画出主线程和协程执行流程图
代码:
package main
import (
"fmt"
"strconv"
"time"
)
/**
协程 goroutine
*/
//编写一个函数,每隔1秒输出 "hello,world"
func test2(){
for i := 0;i< 10;i++{
fmt.Println("hello,world "+strconv.Itoa(i))
time.Sleep(time.Second) //休眠1秒
}
}
func main() {
go test2(); //开启了协程
for i := 0;i< 10;i++{
fmt.Println("hello,golang "+strconv.Itoa(i))
time.Sleep(time.Second) //休眠1秒
}
}
运行结果:
hello,golang 0
hello,world 0
hello,world 1
hello,golang 1
hello,golang 2
hello,world 2
hello,golang 3
hello,world 3
hello,golang 4
hello,world 4
hello,golang 5
hello,world 5
hello,golang 6
hello,world 6
hello,golang 7
hello,world 7
hello,golang 8
hello,world 8
hello,golang 9
hello,world 9
主线程和协程流程图:

11.3.2 快速入门小结
1.主线程是一个物理线程,直接作用在cpu上的。是重量级的,非常耗费cpu资源。
2.协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。
3.Golang的协程机制是重要的特点,可以轻松的开启上万个协程。其他编程语言的并发机制是一般基于线程的,开启过多的线程,资源耗费大,这里就突显Golang在并发上的优势了。
Java中的线程老贵了,花不起那个钱,所以Go发明了goroutine.
11.4 goroutine调度模型
11.4.1 MPG模式基本介绍

-
M:操作系统的主线程(是物理线程)
-
P:协程执行需要的上下文
-
G:协程
11.4.2 MPG模式运行的状态1

(1)当前程序由3个M,如果3个M都在一个cpu运行,就是并发,如果在不同的cpu运行就是并行
(2)M1,M2,M3正在执行一个G,M1的协程队列有3个,M2的协程队列有3个,M3协程队列有2个
(3)从上图可以看到:Go的协程是轻量级的线程,是逻辑态的,Go可以容易的起上万个协程
(4)其他程序C、Java的多线程,往往是内核态的,比较重量级,几千个线程可能耗光cpu
11.4.3 MPG模式运行的状态2

(1)分成两个部分来看
(2)原来的情况是M0主线程正在执行G0协程,另外有3个协程在队列等待
(3)如果G0协程阻塞,比如读取文件或者数据库等
(4)这时就会创建M1主线程(也可能是从已有的线程池中取出M1),并且将等待的3个协程挂到M1下开始执行,M0的主线程下的G0仍然执行文件IO的读写
(5)这样的MPG调度模式,可以既让G0执行,同时也不会让队列的其他协程一直阻塞,仍然可变并发/并行执行
(6)等到G0不阻塞了,M0会被放到空闲的主线程继续执行(从已有的线程池中取),同时G0又会被唤醒。
炒海鲜(洗海鲜) 的等待期 炒个鱼香肉丝
11.5 设置Golang运行的cpu数
介绍:为了充分利用多CPU的优势,在Golang程序中,设置运行的cpu数目。
package main
import (
"fmt"
"runtime"
)
/**
设置cpu个数
*/
func main() {
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=",cpuNum)
//可以自己设置使用多个cpu
runtime.GOMAXPROCS(cpuNum-1)
}
运行结果:
cpuNum= 4
(1)go1.8后,默认让程序运行在多个核上,可以不用设置了,默认认为你,用Go语言,就是为了多核
(2)go1.8前,还是要设置一下,可以更高效的利用cpu
11.6 channel管道
需求:现在需要计算1-200的各个数的阶乘,并且把各个数的阶乘放入到map中。最后显示出来。要求使用goroutine完成。
分析思路:
(1)使用goroutine来完成,效率高,但是会出现并发/并行安全问题
(2)这里就提出了不同的goroutine如何通信的问题
代码实现:
package main
import (
"fmt"
"time"
)
//思路
//1.编写一个函数,来计算各个数的阶层,并放入到map中
//2.我们启动多个协程,统计的结果放入到map中
//3.map应该做一个全局的
var (
myMap = make(map[int]int ,10)
)
//test 函数就是计算n! 然后将这个数的阶层放入map中
func test4(n int){
result := 1
for i := 1;i<=n;i++{
result = result * i
}
myMap[n] = result //concurrent map writes?
}
func main() {
//我们这里开启多个协程完成这个任务(200个)
for i := 1;i<= 200;i++{
go test4(i)
}
time.Sleep(time.Second*10) //等多久?
//在这里我们输出结果
for i,v := range myMap {
fmt.Printf("map[%d]=%d",i,v)
}
}
运行结果:
报错
fatal error: concurrent map writes
示意图:
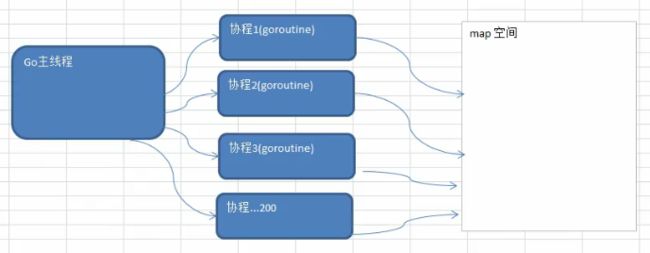
11.6.1 不同的goroutine之间如何通讯
(1)全局变量的互斥锁
(2)channel管道
使用全局变量加锁同步改进程序
。因为没有对全局变量map加锁,因此会出现资源争夺问题,代码会出现错误,提示concurrent map writes
。解决方案:加入互斥锁
。我们的数的阶乘很大,结果会越界,可以将求阶乘改成sum += unit64(i)
11.6.2 全局变量的互斥锁
锁 —> 钥匙 有钥匙 才能访问
别人在用的时候,会挂上锁,
别人用完了,会把锁拿掉,好比古代皇帝就寝。 办公室排队上厕所

代码改进:全局变量的互斥锁
package main
import (
"fmt"
"sync"
"time"
)
//思路
//1.编写一个函数,来计算各个数的阶层,并放入到map中
//2.我们启动多个协程,统计的结果放入到map中
//3.map应该做一个全局的
var (
myMap = make(map[int] float64 ,10)
lock sync.Mutex //lock是一个全局的互斥锁 Mutex:互斥
)
//test 函数就是计算n! 然后将这个数的阶层放入map中
func test4(n int){
result := 1.0
for i := 1;i<=n;i++{
result = result * float64(i)
}
lock.Lock() //上锁
myMap[n] = result //concurrent map writes?
lock.Unlock() //解锁
}
func main() {
//我们这里开启多个协程完成这个任务(200个)
for i := 1;i<= 20;i++{
go test4(i)
}
time.Sleep(time.Second*10) //等多久?
//在这里我们输出结果
lock.Lock()
for i,v := range myMap {
fmt.Printf("map[%d]=%f \n",i,v)
}
lock.Unlock()
}
运行结果:
map[4]=24.000000
map[12]=479001600.000000
map[13]=6227020800.000000
map[3]=6.000000
map[10]=3628800.000000
map[17]=355687428096000.000000
map[16]=20922789888000.000000
map[18]=6402373705728000.000000
map[19]=121645100408832000.000000
map[1]=1.000000
map[5]=120.000000
map[6]=720.000000
map[7]=5040.000000
map[9]=362880.000000
map[2]=2.000000
map[8]=40320.000000
map[11]=39916800.000000
map[14]=87178291200.000000
map[15]=1307674368000.000000
map[20]=2432902008176640000.000000
11.6.3 为什么需要channel
前面使用全局变量加锁同步来解决goroutine的通讯,但不完美
(1)主线程在等待所以goroutine全部完成的时间很难确定,我们这里设置10秒,进阶是估算
(2)如果主线程休眠时间长了,会加长等待时间,如果等待时间短了,可能还有goroutine还处在工作状态,这时也会随主线程的退出而销毁
(3)通过全局变量加锁同步来实现通讯,也并不利于多个协程对全局变量的读写操作
(4)上面种种分析都在呼唤一个新的通讯机制-channel管道
11.6.4 channel的基本介绍
(1)channel本质就是一个数据结构–队列
(2)数据是先进先出,
(3)线程安全,多个goroutine访问时,不需要加锁,就是说channel本身就是线程安全的
(4)channel有类型的,一个string的channel只能存放string类型数据
(5)示意图:

11.6.5 定义/声明channel
var 变量名 chan 数据类型
举例:
var intChan chan int (intChan用于存放int数据)
var mapChan chan map[int]string (mapChan用于存放map[int]string类型)
var perChan chan Person
var perChan chan *Person
说明:
(1)channel是引用类型
(2)channel必须初始化才能写入数据,即make后才能使用
(3)管道是有类型的,intChan只能写入整数int
11.6.6 管道的操作
package main
import "fmt"
/**
管道的定义 写入 取数
*/
func main() {
//演示一下管道的使用
//1.创建一个可以存放3个int类型的管道
var intChan chan int //定义管道
intChan = make(chan int,3)
//2.看看intChan是什么
fmt.Println(intChan)
//3.向管道写入数据
intChan <- 10 //写入数据到管道
num := 211
intChan <- num
//注意点:当我们给管道写入数据时,不能超过其容量
intChan <- 50
//4.看看管道的长度和cap容量
fmt.Println("len=",len(intChan)) //3
fmt.Println("cap=",cap(intChan)) //3
//5.从管道中,读取数据
num2 := <- intChan //从管道取数据
fmt.Println(num2)
fmt.Println("len=",len(intChan)) //2
fmt.Println("cap=",cap(intChan)) //3
//6.在没有使用协程的情况下,如果我们的管道数据以及全部取出,再取就会报告deadlock
num3 := <- intChan
num4 := <- intChan
//num5 := <- intChan //已经全部取出
fmt.Println("num3=",num3)
fmt.Println("num4=",num4)
//fmt.Println("num5=",num5)
}
运行结果:
0xc000150080
len= 3
cap= 3
10
len= 2
cap= 3
num3= 211
num4= 50
11.6.7 channel使用的注意事项
1.channel中只能存放指定的数据类型
2.channel的数据放满后,就不能再放入了
3.如果从channel取出数据后,就可以继续放入
4.在没有使用协程的情况下,如果channel数据取完了,再取,就会报dead lock
11.6.8 案例演示
1.创建一个mapChan,最多可以存放10个map[string]string的key-val,演示写入和读取
func main(){
var mapChan chan map[string]string
mapchan = make(chan map[string]string,10)
m1 := make(map[string]string,20)
m1["city1"] = "北京"
m1["city2"] = "天津"
m2 := make(map[string]string,20)
m2["hero1"] = "宋江"
m2["hero2"] = "武松"
mapChan <- m1
mapChan <- m2
}
2.管道类型为接口 可以存放任意类型的数
package main
import "fmt"
/**
接口管道 可以存放任意类型的数据
*/
type Cat struct {
Name string
Age int
}
func main() {
//定义一个存放任意数据类型的管道 3个数据
//var allChan chan interface{}
allChan := make(chan interface{},3)
allChan <- 10
allChan <- "tom jack"
cat := Cat{"小花猫",4}
allChan <- cat
//我们希望获得到管道的第3个元素,则先将前2个推出
<- allChan
<- allChan
newCat := <- allChan
fmt.Printf("newCat=%T,newCat=%v \n",newCat,newCat)
//下面的写法是错误的!编译不通过
//fmt.Fprintf("newCat.Name=%v",newCat.Name)
//使用 类型断言
a := newCat.(Cat)
fmt.Println("newCat.Name=%v",a.Name)
}
运行结果:
newCat=main.Cat,newCat={小花猫 4}
newCat.Name=%v 小花猫
11.6.9 channel的关闭
使用内置函数close可以关闭channel,当channel关闭后,就不能再向channel写数据了,但是仍然可以从该channel读取数据。好比买火车票排队,到点了,把后面门关上。
代码:
package main
import "fmt"
/**
管道的关闭
*/
func main() {
intChan := make(chan int ,3)
intChan <- 100
intChan <- 200
close(intChan)
//关闭后,不能再写入 panic: send on closed channel
//intChan <- 300
//关闭后,仍然可以读取
n1 := <- intChan
fmt.Println(n1)
}
运行结果:
100
11.6.10 channel的遍历
channel支持for-range的方式进行遍历,请注意两个细节
(1)在遍历时,如果channel没有关闭,则会出现deadlock的错误
(2)在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
代码:
package main
import "fmt"
/**
管道的遍历
*/
func main() {
//遍历管道
intChan2 := make(chan int,100)
for i := 0;i<100;i++{
intChan2 <- i*2 //放入100个数据到管道中
}
//遍历管道时,不能使用普通的for循环结构(因为len会变小)
//如果在遍历时,管道没有关闭,则会出现deadlock错误
close(intChan2)
for v := range intChan2{
fmt.Println(v)
}
}
运行结果:
0
2
4
6
...
198
11.6.11 协程配合channel案例
应用实例:
请完成goroutine和channel协同工作的案例,具体要求:
(1)开启一个writeData协程,向管道intChan中写入50个整数
(2)开启一个readData协程,从管道intChan中读取writeData写入的数据
(3)注意:writeData和readData操作的是同一个管道
(4)主线程需要等待writeData和readData协程都完成工作才能退出
思路分析:
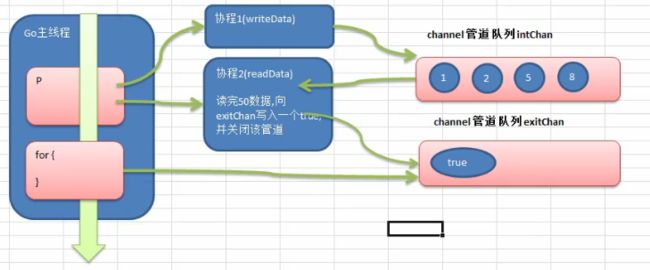
代码:
package main
import (
"fmt"
)
/**
协程 + 管道 综合案例
*/
//写数据协程
func writeData(intChan chan int){
for i := 1;i<=50;i++{
//放入数据
intChan <- i
fmt.Printf("writeData写入%v \n",i)
//time.Sleep(time.Second)
}
close(intChan)
}
//读数据协程
func readData(intChan chan int,exitChan chan bool){
for{
v,ok := <- intChan
if(!ok){
break
}
fmt.Printf("readData 读到数据=%v \n",v)
}
//readData 读取完数据后,即任务完成
exitChan <- true
close(exitChan)
}
func main() {
//创建2个管道
intChan := make(chan int,50)
exitChan := make(chan bool,1)
go writeData(intChan)
go readData(intChan,exitChan)
for{
flag := <- exitChan
if(flag){
break
}
}
}
运行结果:
writeData写入1
writeData写入2
writeData写入3
writeData写入4
readData 读到数据=1
readData 读到数据=2
readData 读到数据=3
readData 读到数据=4
readData 读到数据=5
...
11.6.12 协程配合channel阻塞
func main() {
//创建2个管道
intChan := make(chan int,50)
exitChan := make(chan bool,1)
go writeData(intChan)
// go readData(intChan,exitChan)
for{
flag := <- exitChan
if(flag){
break
}
}
}
问题:如果注销掉go readData(intChan,exitChan),程序会怎么样?
答:如果只是向管道写入数据,而没有读取,就会出现阻塞而dead lock,原因是intChan容量是10,而代码writedata会写入50个数据,因此会阻塞在writeData的 intChan <- i
如果编译器(运行),发现一个管道,只有写,而没有读,则该管道会阻塞
写管道和读管道的速度不一致,无所谓。
11.6.13 协程求素数
需求:要求统计1-8000的数字中,哪些是素数?这个问题在本章开篇就提出了,现在我们用goroutine和channnel的知识完成。
分析思路:
。传统的方法:就是使用一个for循环,循环的判断各个数是不是素数
。使用并发/并行的方式,将统计素数的任务分配给多个(4个)goroutine去完成,完成任务时间短。
1.画出分析思路:

2.代码实现:
package main
import (
"fmt"
"time"
)
/**
需求:要求统计1-8000的数字中,哪些是素数?这个问题在本章开篇就提出了,
现在我们用goroutine和channnel的知识完成
*/
func putNum(intChan chan int){
for i := 0;i<200000;i++{
intChan <- i
}
//关闭
close(intChan)
}
//从initChan取出数据,并判断是否为素数,
//如果是,就放入到primeChan
func primeNum(intChan chan int ,primeChan chan int,exitChan chan bool){
//使用for循环
var flag bool
for{
num,ok := <- intChan
if !ok{ //intChan取不到了
break
}
flag = true
//判断num是不是素数
for i:=2;i<num;i++{
if num%i ==0{ //说明该num不是素数
flag = false
break
}
}
if flag {
//将这个数放入到primeChan
primeChan <- num
}
}
fmt.Println("有一个primeNum协程因为取不到数据退出了")
//这里我们还不能关闭primeChan
//向 exitChan 写入 true
exitChan <- true
}
func main() {
intChan := make(chan int,1000) //存放要判断的数字 的管道
primeChan := make(chan int,10000) //存放素数的管道 结果
exitChan := make(chan bool,4) //4个协程的标志位 管道
start := time.Now().Unix()
//开启一个协程,向initChan写入1-8000个数
go putNum(intChan)
//开启4个协程,从intChan取出数据,并判断是否为素数,
//如果是,就放入到primeChan
for i := 0; i < 4; i++{
go primeNum(intChan,primeChan,exitChan)
}
//这里我们主线程 进行处理
//直接 匿名协程
go func(){
for i := 0;i<4;i++{
<- exitChan
}
end := time.Now().Unix()
fmt.Println("使用协程耗时=",end-start)
//当我们从exitChan取出4个结果,就可以放心的关闭primeChan
close(primeChan)
}()
//遍历我们的primeChan,把结果取出
for{
_,ok := <- primeChan
if !ok {
break
}
//将结果输出
//fmt.Printf("素数=%d \n",res)
}
fmt.Println("主线程退出")
}
运行结果:
有一个primeNum协程因为取不到数据退出了
有一个primeNum协程因为取不到数据退出了
有一个primeNum协程因为取不到数据退出了
有一个primeNum协程因为取不到数据退出了
使用协程耗时= 9
主线程退出
package main
import (
"fmt"
"time"
)
/**
不使用协程
*/
func main() {
start := time.Now().Unix()
for num :=0;num<200000;num++{
var flag bool
//判断num是不是素数
for i:=2;i<num;i++{
if num%i ==0{ //说明该num不是素数
flag = false
break
}
}
if flag {
//将这个数放入到primeChan
//primeChan <- num
}
}
end := time.Now().Unix()
fmt.Println("使用普通方法耗时=",end-start)
}
运行结果:
使用普通方法耗时= 25
结论:200000,使用协程需要9s,使用普通方法需要25s,
使用go协程后,执行的速度,比普通方法提高了至少4倍。
11.6.14 channel使用细节
1.channel可以声明为只读,或者只写性质
ch <-chan int 只读管道
ch chan<- int 只写管道
2.channel只读和只写的最佳实践案例
//ch chan<- int 这样ch就只能写操作了
func send(ch chan<- int,exitChan chan struct{}){
for i:=0;i<10;i++{
ch <- i
}
close(ch)
var a struct{}
exitChan<- a
}
//ch <-chan int 这样ch就只能读操作了
func recv(ch <-chan int,exitChan chan struct{}){
for{
v,ok := <-ch
if !ok{
break
}
fmt.Println(v)
}
var a struct{}
exitChan <- a
}
func main(){
var ch chan int
ch = make(chan int,10)
exitChan := make(chan struct{},2)
go send(ch,exitChan) //只读管道
go recv(ch,exitChan) //只写管道
var total = 0
for _ = range exitChan{
total++
if total == 2{
break
}
}
fmt.Println("结束......")
}
2.使用select可以解决从管道取数据的阻塞问题
//实际开发中,可能我们不好确定是吗时候关闭该通道
//可以使用select方式解决
for{
select{
//注意:这里如果intChan一直没有关闭,不会一直阻塞而deadlock
//,会自动到下一个case匹配
case v := <-intChan :
fmt.Println("从intChan读取的数据%d\n",v)
case v := <-stringChan :
fmt.Println("从stringChan读取的数据%d\s",v)
default:
fmt.Println("都取不到了,不玩了,程序员可以加入业务逻辑\n")
break
}
}
3.goroutine中使用recover,解决协程中出现的panic,导致程序崩溃问题
说明:如果我们起一个协程,但是这个协程出现了panic,如果我们没有捕获这个panic,就会造成整个程序崩溃,这时我们可以在goroutine中使用revover来捕获panic进行处理,这样即使这个协程发生了问题,但是主线程仍然不受影响,可以继续执行。
package main
import (
"fmt"
"time"
)
func sayHello(){
for i := 0;i<5;i++{
fmt.Println("hello,world")
}
}
//函数
func test5(){
//这里我们可以使用 defer + recover
defer func(){
//捕获test抛出的panic
if err:=recover();err!=nil{
fmt.Println("test()发生了错误",err)
}
}()
//定义了一个map
var myMap map[int] string
myMap[0] = "golang"
}
func main() {
go sayHello()
go test5()
for i:=0;i<5;i++{
fmt.Println("main() ok=",i)
time.Sleep(time.Second)
}
}
运行结果:
hello,world
hello,world
hello,world
main() ok= 0
hello,world
hello,world
test()发生了错误 assignment to entry in nil map
main() ok= 1
main() ok= 2
main() ok= 3
main() ok= 4
port “fmt”
/**
管道的关闭
*/
func main() {
intChan := make(chan int ,3)
intChan <- 100
intChan <- 200
close(intChan)
//关闭后,不能再写入 panic: send on closed channel
//intChan <- 300
//关闭后,仍然可以读取
n1 := <- intChan
fmt.Println(n1)
}
运行结果:
100
### 11.6.10 channel的遍历
channel支持for-range的方式进行遍历,请注意两个细节
(1)在遍历时,如果channel没有关闭,则会出现deadlock的错误
(2)在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
代码:
```go
package main
import "fmt"
/**
管道的遍历
*/
func main() {
//遍历管道
intChan2 := make(chan int,100)
for i := 0;i<100;i++{
intChan2 <- i*2 //放入100个数据到管道中
}
//遍历管道时,不能使用普通的for循环结构(因为len会变小)
//如果在遍历时,管道没有关闭,则会出现deadlock错误
close(intChan2)
for v := range intChan2{
fmt.Println(v)
}
}
运行结果:
0
2
4
6
...
198
11.6.11 协程配合channel案例
应用实例:
请完成goroutine和channel协同工作的案例,具体要求:
(1)开启一个writeData协程,向管道intChan中写入50个整数
(2)开启一个readData协程,从管道intChan中读取writeData写入的数据
(3)注意:writeData和readData操作的是同一个管道
(4)主线程需要等待writeData和readData协程都完成工作才能退出
思路分析:
[外链图片转存中…(img-9QX4aWAS-1639223522807)]
代码:
package main
import (
"fmt"
)
/**
协程 + 管道 综合案例
*/
//写数据协程
func writeData(intChan chan int){
for i := 1;i<=50;i++{
//放入数据
intChan <- i
fmt.Printf("writeData写入%v \n",i)
//time.Sleep(time.Second)
}
close(intChan)
}
//读数据协程
func readData(intChan chan int,exitChan chan bool){
for{
v,ok := <- intChan
if(!ok){
break
}
fmt.Printf("readData 读到数据=%v \n",v)
}
//readData 读取完数据后,即任务完成
exitChan <- true
close(exitChan)
}
func main() {
//创建2个管道
intChan := make(chan int,50)
exitChan := make(chan bool,1)
go writeData(intChan)
go readData(intChan,exitChan)
for{
flag := <- exitChan
if(flag){
break
}
}
}
运行结果:
writeData写入1
writeData写入2
writeData写入3
writeData写入4
readData 读到数据=1
readData 读到数据=2
readData 读到数据=3
readData 读到数据=4
readData 读到数据=5
...
11.6.12 协程配合channel阻塞
func main() {
//创建2个管道
intChan := make(chan int,50)
exitChan := make(chan bool,1)
go writeData(intChan)
// go readData(intChan,exitChan)
for{
flag := <- exitChan
if(flag){
break
}
}
}
问题:如果注销掉go readData(intChan,exitChan),程序会怎么样?
答:如果只是向管道写入数据,而没有读取,就会出现阻塞而dead lock,原因是intChan容量是10,而代码writedata会写入50个数据,因此会阻塞在writeData的 intChan <- i
如果编译器(运行),发现一个管道,只有写,而没有读,则该管道会阻塞
写管道和读管道的速度不一致,无所谓。
11.6.13 协程求素数
需求:要求统计1-8000的数字中,哪些是素数?这个问题在本章开篇就提出了,现在我们用goroutine和channnel的知识完成。
分析思路:
。传统的方法:就是使用一个for循环,循环的判断各个数是不是素数
。使用并发/并行的方式,将统计素数的任务分配给多个(4个)goroutine去完成,完成任务时间短。
1.画出分析思路:
[外链图片转存中…(img-luI2HDff-1639223522809)]
2.代码实现:
package main
import (
"fmt"
"time"
)
/**
需求:要求统计1-8000的数字中,哪些是素数?这个问题在本章开篇就提出了,
现在我们用goroutine和channnel的知识完成
*/
func putNum(intChan chan int){
for i := 0;i<200000;i++{
intChan <- i
}
//关闭
close(intChan)
}
//从initChan取出数据,并判断是否为素数,
//如果是,就放入到primeChan
func primeNum(intChan chan int ,primeChan chan int,exitChan chan bool){
//使用for循环
var flag bool
for{
num,ok := <- intChan
if !ok{ //intChan取不到了
break
}
flag = true
//判断num是不是素数
for i:=2;i<num;i++{
if num%i ==0{ //说明该num不是素数
flag = false
break
}
}
if flag {
//将这个数放入到primeChan
primeChan <- num
}
}
fmt.Println("有一个primeNum协程因为取不到数据退出了")
//这里我们还不能关闭primeChan
//向 exitChan 写入 true
exitChan <- true
}
func main() {
intChan := make(chan int,1000) //存放要判断的数字 的管道
primeChan := make(chan int,10000) //存放素数的管道 结果
exitChan := make(chan bool,4) //4个协程的标志位 管道
start := time.Now().Unix()
//开启一个协程,向initChan写入1-8000个数
go putNum(intChan)
//开启4个协程,从intChan取出数据,并判断是否为素数,
//如果是,就放入到primeChan
for i := 0; i < 4; i++{
go primeNum(intChan,primeChan,exitChan)
}
//这里我们主线程 进行处理
//直接 匿名协程
go func(){
for i := 0;i<4;i++{
<- exitChan
}
end := time.Now().Unix()
fmt.Println("使用协程耗时=",end-start)
//当我们从exitChan取出4个结果,就可以放心的关闭primeChan
close(primeChan)
}()
//遍历我们的primeChan,把结果取出
for{
_,ok := <- primeChan
if !ok {
break
}
//将结果输出
//fmt.Printf("素数=%d \n",res)
}
fmt.Println("主线程退出")
}
运行结果:
有一个primeNum协程因为取不到数据退出了
有一个primeNum协程因为取不到数据退出了
有一个primeNum协程因为取不到数据退出了
有一个primeNum协程因为取不到数据退出了
使用协程耗时= 9
主线程退出
package main
import (
"fmt"
"time"
)
/**
不使用协程
*/
func main() {
start := time.Now().Unix()
for num :=0;num<200000;num++{
var flag bool
//判断num是不是素数
for i:=2;i<num;i++{
if num%i ==0{ //说明该num不是素数
flag = false
break
}
}
if flag {
//将这个数放入到primeChan
//primeChan <- num
}
}
end := time.Now().Unix()
fmt.Println("使用普通方法耗时=",end-start)
}
运行结果:
使用普通方法耗时= 25
结论:200000,使用协程需要9s,使用普通方法需要25s,
使用go协程后,执行的速度,比普通方法提高了至少4倍。
11.6.14 channel使用细节
1.channel可以声明为只读,或者只写性质
ch <-chan int 只读管道
ch chan<- int 只写管道
2.channel只读和只写的最佳实践案例
//ch chan<- int 这样ch就只能写操作了
func send(ch chan<- int,exitChan chan struct{}){
for i:=0;i<10;i++{
ch <- i
}
close(ch)
var a struct{}
exitChan<- a
}
//ch <-chan int 这样ch就只能读操作了
func recv(ch <-chan int,exitChan chan struct{}){
for{
v,ok := <-ch
if !ok{
break
}
fmt.Println(v)
}
var a struct{}
exitChan <- a
}
func main(){
var ch chan int
ch = make(chan int,10)
exitChan := make(chan struct{},2)
go send(ch,exitChan) //只读管道
go recv(ch,exitChan) //只写管道
var total = 0
for _ = range exitChan{
total++
if total == 2{
break
}
}
fmt.Println("结束......")
}
2.使用select可以解决从管道取数据的阻塞问题
//实际开发中,可能我们不好确定是吗时候关闭该通道
//可以使用select方式解决
for{
select{
//注意:这里如果intChan一直没有关闭,不会一直阻塞而deadlock
//,会自动到下一个case匹配
case v := <-intChan :
fmt.Println("从intChan读取的数据%d\n",v)
case v := <-stringChan :
fmt.Println("从stringChan读取的数据%d\s",v)
default:
fmt.Println("都取不到了,不玩了,程序员可以加入业务逻辑\n")
break
}
}
3.goroutine中使用recover,解决协程中出现的panic,导致程序崩溃问题
说明:如果我们起一个协程,但是这个协程出现了panic,如果我们没有捕获这个panic,就会造成整个程序崩溃,这时我们可以在goroutine中使用revover来捕获panic进行处理,这样即使这个协程发生了问题,但是主线程仍然不受影响,可以继续执行。
package main
import (
"fmt"
"time"
)
func sayHello(){
for i := 0;i<5;i++{
fmt.Println("hello,world")
}
}
//函数
func test5(){
//这里我们可以使用 defer + recover
defer func(){
//捕获test抛出的panic
if err:=recover();err!=nil{
fmt.Println("test()发生了错误",err)
}
}()
//定义了一个map
var myMap map[int] string
myMap[0] = "golang"
}
func main() {
go sayHello()
go test5()
for i:=0;i<5;i++{
fmt.Println("main() ok=",i)
time.Sleep(time.Second)
}
}
运行结果:
hello,world
hello,world
hello,world
main() ok= 0
hello,world
hello,world
test()发生了错误 assignment to entry in nil map
main() ok= 1
main() ok= 2
main() ok= 3
main() ok= 4