【自然语言处理与文本分析】文本特征提取方法总结。关键词提取方法。公认效果较好的IDF,RCF。
-
-
- 关键词提取方法
-
关键词是文章想表达的主要画图,能反映文本语料主题的词语或者短语。
关键词具有的特定:
关键词在特点的语料里频繁出现,,在其他语料里出现较少:IDF
针对一些有结构的文本,比如新闻之类的,经常使用总分总的格式。一般关键词出现在标题,首部,尾部,的词语。出现关键词的概率,比其他地方出现关键词概论大的多。
词语在文本中反复出现,且该词附件还有其他关键词,那么该词语是关键词的概率就很大了。
根据TF、DF、IDF提取关键词
当然,我们也可以用其他指标RCF

人为提取关键词的效果。我们可以发现加势大周虽然看起来只出现一次,所以我们要对代名词处理。不然对TF DF IDF有影响。
机器是只能透过公式来提取关键词比如
IDF=log(N/n)
N是文章的总数,n=DF
IDF代表信息量,越大信息量越高,前提是文章数够多。
出现越多文本,idf的值就会越低。

这里我们就可以提取到
因为IDF不了解关键词在文章内出现次数TF,所以我们可以加入这个指标TF加强权重。TF*IDF=Weight 代表的重要性,值越大,代表这个值越重要。Weight值越小,说明这个值没啥索引价值。
| Weight |
K1 |
K2 |
K3 |
Kn |
|
| D1 |
1 |
||||
| D2 |
2 |
||||
| D3 |
3 |
D代表文章 K代表关键词,因为我们会设定一个阈值,如果该值大于这个范围,那么我们就可以把它选取进去,但是我们发现,由于TF的存在,每个文件中的Weigt值就不同,所以规定,主要在一篇文章中大于阈值,我们就将这个词保留下来。也就是说只要有一次被选中,就会被我们保留,负责就变成停用词。
之后会有算法的实操。
TF我们有时会进行一个标准化,它代表一个词在一个文章的出现次数,但是每批文章的词数不同。有些文章有100个词,有些的是有30个词,但是它们K出现的次数都是10次,TF=10,是不合理。要考虑文章的长短程度。
所以我们

不同情况下也可以进行调整。结果也是一样的,TF*IDF
IDF也不一定是以2为底:

一个格外说明:

我们收到了两个文章,如果用IDF去直接计算IDF,那波斯湾和原油都有出现,IDF的值不就是0,那它就不重要了。这时我们就要回到原先的定义,我们选择的是大量的文章,一个关键词的分布程度,越集中,那么它就越重要。但是这个时候,我们只选取了2篇文章,内容很少。
所以你也可以从大量文章中先计算出IDF的值,然后再进行使用。如果是自己直接使用,一定要有大量的文章
这个必须按照目标字段来选择指标。
就像之前说的证券交易所的案例,我们用的指标就是,RCF
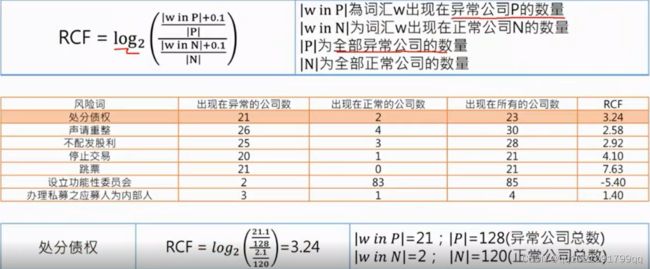
这时分母是关键词w出现在异常公司的数量p加0.1后除以p(标准化)
分子是关键词w出现在正常公司的数量N加0.1,然后除以N(标准化)
这个值如果是正的,就很可能是正常公司的关键词
这个值如果是负的,就很可能是正常公司的关键词。
我们再回头看表格。设立功能性委员会,就是很可能是正常常公司会出现的关键词。
所以我们完全可以根据我们的目标字段,来调整IDF或者RDF或者*DF
根据词性标注的关键词提取方法

你可以保留某类词性,再进行IDF等等处理。
根据文章结构提取方法
关键词具有的特定:
关键词在特点的语料里频繁出现,,在其他语料里出现较少:IDF
针对一些有结构的文本,比如新闻之类的,经常使用总分总的格式。一般关键词出现在标题,首部,尾部,的词语。出现关键词的概率,比其他地方出现关键词概论大的多。
词语在文本中反复出现,且该词附件还有其他关键词,那么该词语是关键词的概率就很大了。
关键词的可视化:文字云(词云)
关键词出现频率越大,大小就越大,还可以搭配一些形状颜色。

总结
1:根据该领域的专家来挑选影响力的特征,根据这个分析词,在根据数据来评估是否重要
2:用数学的方法在数据中挑出最具有分类信息的特征。这种方法比较精确,没有人为因素的干扰,非常适合文本自动分类挖掘系统的应用。词的含义还在。
3:如果特征(关键词)太少,或者同义词太多的情况。就可以用映射的方法,把原始特征转化为比较少的新特征。
比如词嵌入,词袋。关键词可能从100个就变成20个,它代表的是全面的特征,但是它的意义可能就消失。如果是为了结果的判断好,也是可以使用这个方法