分享 7 个 AI 优质开源项目!文本生成、自动化数据搜集...
项目一:nanodet 超快速轻量级无锚物体检测模型
项目地址:
https://github.com/RangiLyu/nanodet
项目特点:
超轻量:模型文件只有 980KB(INT8) 或 1.8MB(FP16)。
超快:在移动 ARM CPU 上为 97fps(10.23ms)。
训练友好:比其他模型低得多的 GPU 内存成本。Batch-size=80 在 GTX1060 6G 上可用。
易于部署:提供各种后端的C++实现和基于ncnn推理框架的Android演示。
Android 演示:

模型基准:
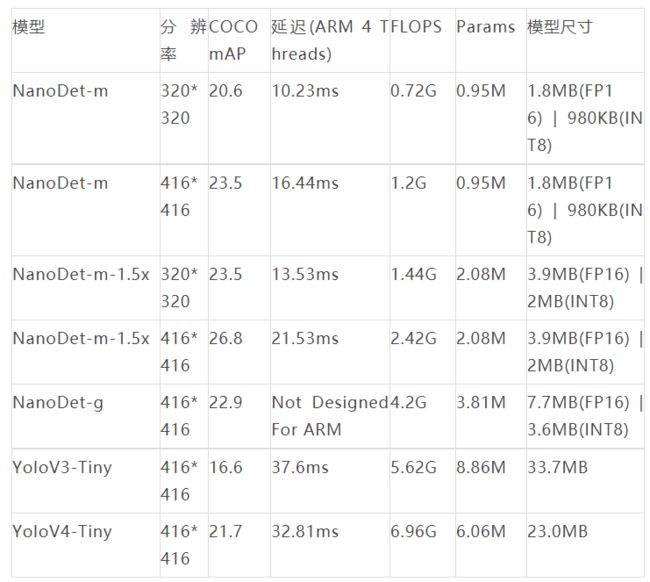
NanoDet 是一种 FCOS 风格的单阶段无锚物体检测模型,它使用 ATSS 进行目标采样,使用 Generalized Focal Loss 进行分类和框回归。
配置环境:
Linux or MacOS
CUDA >= 10.0
Python >= 3.6
Pytorch >= 1.6
项目二:graph-notebook 扩展 Jupyter 笔记本轻松查询和可视化图形
项目地址:
https://github.com/aws/graph-notebook
图形笔记本(graph notebook)提供了一种使用 Jupyter 笔记本与图形数据库进行交互的简单方法。使用这个开源 Python 包,您可以连接到任何支持 Apache TinkerPop 或 RDF SPARQL 图形模型的图形数据库。这些数据库可以在您的桌面或云中本地运行。图数据库可用于探索各种用例,包括知识图和身份图。

连接到以下图形数据库的说明:

配置环境:
Python 3.6.1-3.6.12
Jupyter Notebook 5.7.10
Tornado 4.5.3
A graph database that provides a SPARQL 1.1 Endpoint or a Gremlin Server
项目三:maskdetection mask detection technology
项目地址:
https://github.com/didi/maskdetection
为了进一步帮助抗击冠状病毒,滴滴出行决定免费向公众开放其口罩检测技术。该口罩检测技术由滴滴AI团队研发,基于DFS人脸检测算法和滴滴平台采用的人脸属性识别算法。该模型克服了一天中复杂的光照变化、人脸姿势变化、人脸尺度等多个难点,采用加权损失函数和数据增强方法来处理白天和夜间不同的口罩类型和不均匀的口罩数据。
该系统可以通过上传的图像识别不戴口罩的司机,准确率达到99.5%,滴滴在车载摄像头的现场检查中准确率达到98%。该模型在包含 200,000 张人脸的数据集上进行了训练,以确保其稳健性。
该快速检测系统可广泛应用于旅游场景,手机拍照、监控画面等,24小时不间断工作。
配置环境:
google/protobuf
openblas or atlas
opencv
cuda/cudnn(if GPU is used)
Caffe
模型:
模型由公共 ResNet50-caffemodel 预训练。
通过收集的私有数据进行训练。
引入注意力机制。
注意:
滴滴的口罩识别服务旨在更好地保护用户免受公共卫生风险。该技术内置了注意力学习机制,专注于识别面具的存在,同时弱化对其他面部区域的识别。该服务受各种误差源的影响,包括亮度、姿势或部分图像捕获。
项目四:MetalCamera iOS 上基于 Swift、Metal 的图像和视频处理
项目地址:
https://github.com/jsharp83/MetalCamera

MetalCamera 是一个开源项目,用于在 Mac 和 iOS 上执行 GPU 加速的图像和视频处理。使用 GPU 的方法有很多,包括 CIFilter,但它并不开放或难以扩展功能和贡献。这个存储库的主要目标是提供一个接口和测试性能,当您对 iOS 环境中的图像处理和机器学习有想法时,可以更轻松地开发并将其应用于实际服务。
在这个阶段,正在开发以简单地提供以下功能。
相机输入/输出处理
将图像帧保存到视频
基本的图像处理和过滤器
下载和处理 CoreML 模型
可视化 CoreML 模型的结果
基准算法。
配置环境:
Swift 5
Xcode 11.5 or higher on Mac
iOS: 13.0 or higher
项目五:TNSCUI2020-Seg-Rank1st 在MICCAI 2020 TN-SCUI 挑战中排名第一的解决方案
项目地址:
https://github.com/WAMAWAMA/TNSCUI2020-Seg-Rank1st
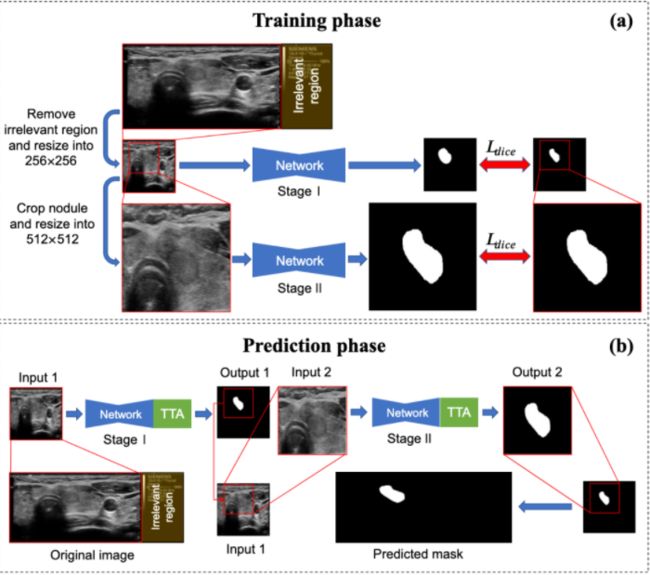
数据预处理:
由于不同的采集协议,部分甲状腺超声图像有不相关区域(如图1所示)。首先,我们采用阈值法去除这些可能带来冗余特征的区域。特别地,我们对像素值从0到255的原始图像进行沿x轴和y轴平均的操作,分别去除均值小于5的行和列。然后将处理后的图像大小调整为256x256像素作为第一个分割网络的输入。
级联分割框架:
利用骰子损耗函数对两个具有相同编码解码器结构的网络进行训练。事实上,我们选择DeeplabV3+ with efficientnet-B6 encoder作为第一网络和第二网络。训练第一个分割网络(级联的I阶段)提供结节的粗略定位,在粗定位的基础上,训练第二次分割网络(级联的II阶段)进行精细分割。我们的初步实验表明,在第一个网络中提供的上下文信息可能不会对第二个网络的细化起到显著的辅助作用。因此,我们只使用ground truth(GT)获得的感兴趣区域(region of interest,ROI)内的图像来训练第二个网络。(在训练这两个网络的过程中,输入数据是唯一的区别。)

当训练第二个网络时,我们将GT得到的结节ROI展开,然后将扩大的ROI中的图像裁剪出来,并将其大小调整为512x512像素,以供第二个网络使用。我们观察到,在大多数病例中,大结节一般边界清楚,而且小结节的灰度值与周围正常的甲状腺组织的灰度值差异较大(如图所示)。因此,背景信息(结节周围组织)对于小结节的分割具有重要意义。如下图所示,在预处理后大小为256x256像素的图像中,首先得到结节感兴趣区域的最小外平方,然后若正方形边长n大于80,则外扩m为20,否则m为30。
数据增强和测试时间增强:
在这两个任务中,以下方法在数据增强中执行:1) 水平翻转, 2) 垂直翻转, 3) 随机剪切, 4)随机仿射变换 ,5) 随机检尺,6) 随机翻译, 7) 随机旋转, 和 8) 随机剪切变换。此外,随机选择以下方法之一进行额外的增强:1) 锐磨, 2)局部辨析, 3) 调整对比, 4) 模糊(高斯,平均值,中值), 5) 高斯噪声的加法,和 6)擦除。
TTA(Test time augmentation)通常提高分割模型的泛化能力。在我们的框架中,TTA包括用于分割任务的垂直翻转,水平翻转和180度旋转。
通过规模和类别平衡策略进行交叉验证:
我们使用五折交叉验证来评估我们所提出的方法的性能。我们的观点是,有必要保持训练集和验证集中结节的大小和类别分布相似。实际上,结节的大小是将预处理后的图像统一为256x256像素后,结节的像素数量。我们将规模分为三个等级:1) 小于1722像素,2) 小于5666像素大于1722像素,和 3)大于5666像素。这两个阈值,1722像素和5666像素, 很接近三分位数,通过卡方独立检验,大小分层与良、恶性分类有统计学意义(p<0.01)。我们将每个尺寸等级组的图像分为5个等级,并将不同等级的单次折叠合成新的单次折叠。这一策略确保了最后五次折叠具有类似的大小和种类分布。
基于2020 TN-SCUI训练数据集和DDTI数据集的分割结果:

配置环境:
segmentation_models_pytorch == 0.1.0
ttach == 0.0.3
torch >=1.0.0
torchvision
imgaug
项目六:fastseq 用于文本生成、摘要和翻译任务的流行序列模型的有效实现
项目地址:
https://github.com/WAMAWAMA/TNSCUI2020-Seg-Rank1st
FastSeq 为文本生成、摘要、翻译任务等提供了流行序列模型(例如 Bart、ProphetNet)的高效实现。它基于流行的 NLP 工具包(例如 FairSeq 和 HuggingFace-Transformers)自动优化推理速度,而不会损失准确性。所有这些都可以轻松完成(如果使用我们的命令行工具,则无需更改任何代码/模型/数据,如果使用源代码,则只需添加一行代码 import fastseq)。
特点:
EL-Attention:用于生成的内存高效无损注意力
基于 GPU 的块 N-Gram 重复
用于后处理的异步管道
速度增益:
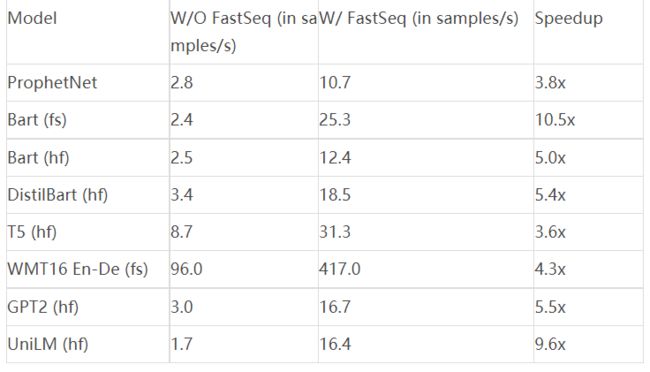
FastSeq 开发了多种加速技术,包括注意力缓存优化、检测重复 n-gram 的有效算法以及具有并行 I/O 的异步生成管道。这些优化支持各种基于 Transformer 的模型架构,例如编码器-解码器架构、仅解码器架构和仅编码器架构。FastSeq 中更高效的实现将自动修补以替换现有 NLP 工具包(例如 HuggingFace-Transformers 和 FairSeq)中的实现,因此无需大的代码更改即可将 FastSeq 与这些工具包集成。
配置环境:
Python version >= 3.6
torch >= 1.4.0
fairseq == 0.9.0
transformers == 3.0.2
requests >= 2.24.0
absl-py >= 0.9.0
rouge-score >= 0.0.4
项目七:Rath 自动化数据探索分析和智能可视化设计应用
项目地址:
https://github.com/Kanaries/Rat
Rath是新一代的可视化分析工具,它提供了自动化的数据探索分析能力与自动可视化设计能力。Rath既可以在你对数据无从下手时提供分析入口的建议,也可以在你的分析过程中提供实时的分析辅助和建议。Rath会帮你完成大部分数据探索分析的工作,使得你可以专注于领域问题本身。
Rath 可能帮助你快速完成对一个数据集的自动化可视化分析。它既可以帮助你在自助分析时提供实时的建议,也可以直接根据数据实时的特征生成数据报表。
相比于tableau、Congos Analytics等可视化分析工具,Rath可以大幅降低数据分析的门槛,使用户可以关注于实际的问题。
相比于PowerBI、帆软等报表搭建工具,Rath可以制作动态的可视化报表。使得你的报表可以针对数据的特性实时变化,始终把重要的问题暴露出来。
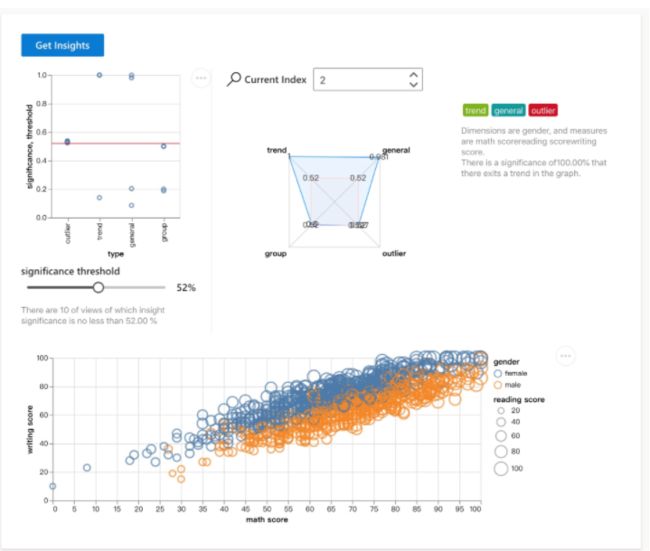
主要组件:
数据源面板 数据源面板用于数据上传、采样(目前支持流数据,即上传的文件大小没有限制)、清理和定义字段类型(维度、度量)。在视觉洞察中,我们将维度视为自变量或特征,将度量视为因变量或目标。
Notebook Notebook 是一个让用户了解自动分析过程中发生了什么以及 Rath 如何使用视觉洞察力的面板。它显示了应用程序如何做出决策,并提供交互式界面来调整算法使用的一些参数和运算符。
Gallery Gallery显示了具有有趣发现的可视化部分。在图库中,您可以找到有趣的可视化并使用关联功能找到更多相关的可视化。您还可以在图库中搜索特定信息。这里有一些设置可以调整图表中的一些视觉元素。
仪表板 为您自动生成仪表板。rath 会找出一组可视化的内容,哪些内容是相互联系的,可以用来分析一个特定的问题。

主要功能:
单变量总结 第一步,独立分析数据集中的所有字段。它获取场的分布并计算其熵。此外,它将为每个字段定义语义类型(数量、顺序、时间、名义)。将鼠标悬停在字段上时,将显示该字段的更多详细信息。然后,它会找到具有高熵的字段并尝试通过对字段进行分组来减少它(例如)。只有维度参与这个过程。
相关性分析
聚类分析 它可以帮助您根据相关性对所有度量进行聚类。它将所有强相关的变量放在一起以形成特定视图(具有指定维度)。
评论区回复 “121”,七月在线干货组最新升级的《2021大厂最新AI面试题 [含答案和解析, 更新到前121题]》,免费送! 持续无限期更新大厂最新面试题,AI干货资料,目前干货组汇总了今年3月-6月份,各大厂面试题。
除此之外,小编还给大家带来一个福利!现在扫描下方二维码,即可限时免费试听第十四期「机器学习集训营」课程!

迄今为止,专为就业或转行AI量身定做的「机器学习集训营」已经举办了十四期。
每一期都涌现出了很多offer,或应届研究生高薪就业,或从Java等传统IT行业成功转型AI…

第十五期在前十四期的基础上,继续维持着:
第一:直播教学面试辅导就业推荐并重,且提供CPU和GPU双云平台并布置作业考试竞赛”为代表的十二位一体的教学模式;
第二:以及六大企业项目:大规模行人重识别(RelD)、人体姿态识别、智能问答系统、聊天机器人、商品推荐系统、电影推荐系统
且为再次提升大家的Al项目经验和工程能力,本期新增部分实训项目,具体见下图。

本期集训营拥有超豪华讲师团队,讲师大多数为国内外知名互联网公司技术骨干或者顶尖院校的专业大牛,学员将在这些顶级讲师的手把手指导下完成学习。

且完成项目进入就业阶段后,BAT等大厂技术专家会一对一进行简历优化(比如将集训营项目整理到简历中)、面试辅导(比如面试常见考点/模型/算法),且和就业老师一起进行就业推荐等等就业服务。
机会永远留给提前做好准备的人!如果你想从事机器学习相关的工作,想在最短时间内成长为行业中高级人才,进入知名互联网公司,立即扫描二维码,参与课程试听吧!
