朴素贝叶斯(Naive Bayes)= Naive + Bayes 。(特征条件独立 + Bayes定理)的实现。
零、贝叶斯定理(Bayes' theorem)
所谓的贝叶斯方法源于他生前为解决一个“逆概”问题写的一篇文章,而这篇文章是在他死后才由他的一位朋友发表出来的。在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有N个白球,M个黑球,你伸手进去摸一把,摸出黑球的概率是多大”。而一个自然而然的问题是反过来:“如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测”。这个问题,就是所谓的逆概问题。
1)条件概率
条件概率(英语:conditional probability)就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”。
联合概率表示两个事件共同发生的概率。A与B的联合概率表示为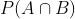 或者
或者![]() 或者
或者![]() 。
。
边缘概率是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
需要注意的是,在这些定义中A与B之间不一定有因果或者事件序列关系。A可能会先于B发生,也可能相反,也可能二者同时发生。A可能会导致B的发生,也可能相反,也可能二者之间根本就没有因果关系。
定义
设 A 与 B 为样本空间 Ω 中的两个事件,其中 P(B)>0。那么在事件 B 发生的条件下,事件 A 发生的条件概率为:
条件概率有时候也称为:后验概率。
独立性: 当且仅当两个随机事件A与B满足 ![]() 的时候,它们才是统计独立的,这样联合概率可以表示为各自概率的简单乘积。同样,对于两个独立事件A与B有
的时候,它们才是统计独立的,这样联合概率可以表示为各自概率的简单乘积。同样,对于两个独立事件A与B有 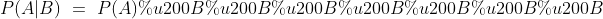 以及
以及 ![]() 。
。
换句话说,如果A与B是相互独立的,那么A在B这个前提下的条件概率就是A自身的概率;同样,B在A的前提下的条件概率就是B自身的概率。
互斥性: 当且仅当A与B满足且, 的时候,A与B是互斥的。因此,
。
换句话说,如果B已经发生,由于A不能和B在同一场合下发生,那么A发生的概率为零;同样,如果A已经发生,那么B发生的概率为零。
2)贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率的一则定理。
其中P(A|B)是指在事件B发生的情况下事件A发生的概率。
在贝叶斯定理中,每个名词都有约定俗成的名称:
- P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
- P(A)是A的先验概率(或边缘概率)。之所以称为"先验"是因为它不考虑任何B方面的因素。
- P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
- P(B)是B的先验概率或边缘概率。
从条件概率推导贝叶斯定理
根据条件概率的定义。在事件B发生的条件下事件A发生的概率是:
其中 A与B的联合概率表示为或者或者。
同样地,在事件A发生的条件下事件B发生的概率
整理与合并这两个方程式,我们可以得到
这个引理有时称作概率乘法规则。上式两边同除以P(B),若P(B)是非零的,我们可以得到贝叶斯定理:
![]()
3)吸毒者检测
下面展示贝叶斯定理在检测吸毒者时的应用。假设一个常规的检测结果的敏感度与可靠度均为99%,即吸毒者每次检测呈阳性(+)的概率为99%。而不吸毒者每次检测呈阴性(-)的概率为99%。从检测结果的概率来看,检测结果是比较准确的,但是贝叶斯定理却可以揭示一个潜在的问题。假设某公司对全体雇员进行吸毒检测,已知0.5%的雇员吸毒。请问每位检测结果呈阳性的雇员吸毒的概率有多高?
令“D”为雇员吸毒事件,“N”为雇员不吸毒事件,“+”为检测呈阳性事件。可得
- P(D)代表雇员吸毒的概率,不考虑其他情况,该值为0.005。因为公司的预先统计表明该公司的雇员中有0.5%的人吸食毒品,所以这个值就是D的先验概率。
- P(N)代表雇员不吸毒的概率,显然,该值为0.995,也就是1-P(D)。
- P(+|D)代表吸毒者阳性检出率,这是一个条件概率,由于阳性检测准确性是99%,因此该值为0.99。
- P(+|N)代表不吸毒者阳性检出率,也就是出错检测的概率,该值为0.01,因为对于不吸毒者,其检测为阴性的概率为99%,因此,其被误检测成阳性的概率为1 - 0.99 = 0.01。
- P(+)代表不考虑其他因素的影响的阳性检出率。该值为0.0149或者1.49%。我们可以通过全概率公式计算得到:此概率 = 吸毒者阳性检出率(0.5% x 99% = 0.495%)+ 不吸毒者阳性检出率(99.5% x 1% = 0.995%)。P(+)=0.0149是检测呈阳性的先验概率。用数学公式描述为:
根据上述描述,我们可以计算某人检测呈阳性时确实吸毒的条件概率P(D|+):
尽管吸毒检测的准确率高达99%,但贝叶斯定理告诉我们:如果某人检测呈阳性,其吸毒的概率只有大约33%,不吸毒的可能性比较大。假阳性高,则检测的结果不可靠。
3)全概率公式
如果事件组B1,B2,.... 满足
- B1,B2...两两互斥,即 Bi ∩ Bj = ∅ ,i≠j , i,j=1,2,....,且P(Bi)>0,i=1,2,....;
- B1∪B2∪....=Ω ,则称事件组 B1,B2,...是样本空间Ω的一个划分
设 B1,B2,...是样本空间Ω的一个划分,A为任一事件,则:

上式即为全概率公式(formula of total probability)
全概率公式的意义在于,当直接计算P(A)较为困难,而P(Bi),P(A|Bi) (i=1,2,...)的计算较为简单时,可以利用全概率公式计算P(A)。思想就是,将事件A分解成几个小事件,通过求小事件的概率,然后相加从而求得事件A的概率,而将事件A进行分割的时候,不是直接对A进行分割,而是先找到样本空间Ω的一个个划分B1,B2,...Bn,这样事件A就被事件AB1,AB2,...ABn分解成了n部分,即A=AB1+AB2+...+ABn, 每一Bi发生都可能导致A发生相应的概率是P(A|Bi),由加法公式得
P(A)=P(AB1)+P(AB2)+....+P(ABn) = P(A|B1)P(B1)+P(A|B2)P(B2)+...+P(A|Bn)P(PBn)
实例:某车间用甲、乙、丙三台机床进行生产,各台机床次品率分别为5%,4%,2%,它们各自的产品分别占总量的25%,35%,40%,将它们的产品混在一起,求任取一个产品是次品的概率。
解: P(A)=25%*5%+4%*35%+2%*40%=0.0345
一、朴素贝叶斯算法(naive bayes algorithm)
1)基本算法流程
输入:训练集![]() ,其中
,其中 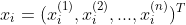 ,
,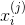 是第i个样本的第j个特征,
是第i个样本的第j个特征,![]() ,
,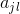 是第j个特征可能取得第
是第j个特征可能取得第 个值,
个值, ![]()
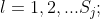
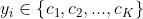 属于K类中的一类;实例
属于K类中的一类;实例  ;
;
输出:实例x的分类。
(1)计算先验概率及条件概率 ( 其中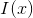 为指示函数,若括号内成立,则计1,否则为0)
为指示函数,若括号内成立,则计1,否则为0)
![]()
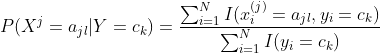
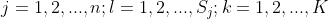
(2)对于给定的实例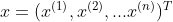 ,计算 (对所有的类来说,公式(2)中分母的值都相同,所以只计算分子部分即可)
,计算 (对所有的类来说,公式(2)中分母的值都相同,所以只计算分子部分即可)
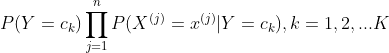
(3)确定实例x的类
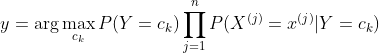
2)推导以及解释
朴素贝叶斯方法是基于贝叶斯定理的一组有监督学习算法,即“简单”地假设每对特征之间相互独立。 给定一个类别 和一个从 到 的相关的特征向量, 贝叶斯定理阐述了以下关系:
使用简单(naive)的假设-每对特征之间都相互独立:
对于所有的 :math: i ,这个关系式可以简化为
由于在给定的输入中 是一个常量,我们使用下面的分类规则:
我们可以使用最大后验概率(Maximum A Posteriori, MAP) 来估计 和 ; 前者是训练集中类别 的相对频率。
各种各样的的朴素贝叶斯分类器的差异大部分来自于处理 分布时的所做的假设不同。
尽管其假设过于简单,在很多实际情况下,朴素贝叶斯工作得很好,特别是文档分类和垃圾邮件过滤。这些工作都要求 一个小的训练集来估计必需参数。
相比于其他更复杂的方法,朴素贝叶斯学习器和分类器非常快。 分类条件分布的解耦意味着可以独立单独地把每个特征视为一维分布来估计。这样反过来有助于缓解维度灾难带来的问题。
3)更一般的推导(易懂)
从条件概率开始:
P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
贝叶斯定理便是基于条件概率,通过P(A|B)来求P(B|A):
顺便提一下,上式中的分母P(A),可以根据全概率公式分解为:
特征条件独立假设:
这一部分开始朴素贝叶斯的理论推导,从中你会深刻地理解什么是特征条件独立假设。
给定训练数据集(X,Y),其中每个样本 x 都包括 n 维特征,即
,类标记集合含有k种类别,即
。
如果现在来了一个新样本x,我们要怎么判断它的类别?从概率的角度来看,这个问题就是给定x,它属于哪个类别的概率最大。那么问题就转化为求解
中最大的那个,即求后验概率最大的输出:
那
怎么求解?答案就是贝叶斯定理:
根据全概率公式,可以进一步地分解上式中的分母:
【公式1】
先不管分母,分子中的
是先验概率,根据训练集就可以简单地计算出来。
而条件概率
,它的参数规模是指数数量级别的,假设第i维特征
可取值的个数有
个,类别取值个数为k个,那么参数个数为:
这显然不可行。针对这个问题,朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征
互相独立,在这个假设的前提上,条件概率可以转化为:
【公式2】
这样,参数规模就降到
以上就是针对条件概率所作出的特征条件独立性假设,至此,先验概率
的求解问题就都解决了,那么我们就可以求解我们所要的后验概率
将【公式2】代入【公式1】得到:
于是朴素贝叶斯分类器可表示为:
因为对所有的
,上式中的分母的值都是一样的(为什么?注意到全加符号就容易理解了),所以可以忽略分母部分,朴素贝叶斯分类器最终表示为:
下面只需要对
求解。

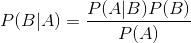
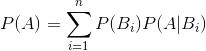

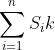
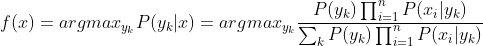
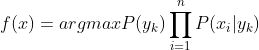
4)三种求解模型
(1)多项式模型
当特征是离散的时候,使用多项式模型。多项式模型在计算先验概率和条件概率时,会做一些平滑处理,具体公式为:
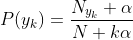
N是总的样本个数,k是总的类别个数,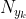 是类别为 的样本个数,
是类别为 的样本个数, 是平滑值。
是平滑值。
![]()
是类别为的样本个数,n是特征的维数,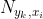 是类别为的样本中,第i维特征的值是的样本个数,是平滑值。
是类别为的样本中,第i维特征的值是的样本个数,是平滑值。
当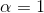 时,称作Laplace平滑,当0<<1时,称作Lidstone平滑,
时,称作Laplace平滑,当0<<1时,称作Lidstone平滑,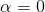 时不做平滑。
时不做平滑。
如果不做平滑,当某一维特征的值没在训练样本中出现过时,会导致![]() ,从而导致后验概率为0。加上平滑就可以克服这个问题。
,从而导致后验概率为0。加上平滑就可以克服这个问题。
举例
有如下训练数据,15个样本,2维特征
,2种类别-1,1。给定测试样本
,判断其类别。
解答如下:
运用多项式模型,令
- 计算先验概率
- 计算各种条件概率
- 对于给定的
由此可以判定y=-1。

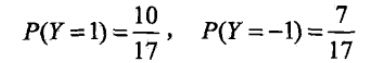
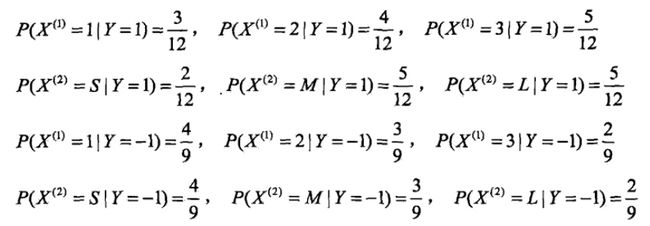
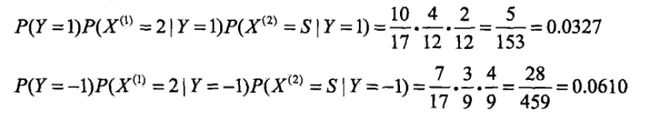
(2)高斯模型
下面是一组人类身体特征的统计资料。
| 性别 | 身高(英尺) | 体重(磅) | 脚掌(英寸) |
|---|---|---|---|
| 男 | 6 | 180 | 12 |
| 男 | 5.92 | 190 | 11 |
| 男 | 5.58 | 170 | 12 |
| 男 | 5.92 | 165 | 10 |
| 女 | 5 | 100 | 6 |
| 女 | 5.5 | 150 | 8 |
| 女 | 5.42 | 130 | 7 |
| 女 | 5.75 | 150 | 9 |
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?
根据朴素贝叶斯分类器,计算下面这个式子的值。
P(身高|性别) x P(体重|性别) x P(脚掌|性别) x P(性别)
这里的困难在于,由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办?
这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值。
比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的值,只用来反映各个值的相对可能性)。
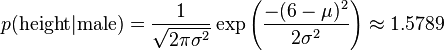
对于脚掌和体重同样可以计算其均值与方差。有了这些数据以后,就可以计算性别的分类了。
P(身高=6|男) x P(体重=130|男) x P(脚掌=8|男) x P(男)
= 6.1984 x e-9
P(身高=6|女) x P(体重=130|女) x P(脚掌=8|女) x P(女)
= 5.3778 x e-4可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
高斯模型假设每一维特征都服从高斯分布(正态分布):
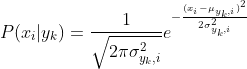
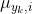 表示类别为的样本中,第i维特征的均值。
表示类别为的样本中,第i维特征的均值。 ![]() 表示类别为的样本中,第i维特征的方差。
表示类别为的样本中,第i维特征的方差。
(3)伯努利模型
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).
伯努利模型中,条件概率的计算方式是:
当特征值为1时,![]() ;
;
当特征值为0时,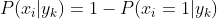 ;
;
https://en.wikipedia.org/wiki/Bayes%27_theorem
https://zh.wikipedia.org/wiki/%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%AE%9A%E7%90%86
http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/
http://norvig.com/spell-correct.html
http://sklearn.apachecn.org/cn/0.19.0/modules/naive_bayes.html
http://www.cs.unb.ca/~hzhang/publications/FLAIRS04ZhangH.pdf
https://www.cnblogs.com/ohshit/p/5629581.html
https://blog.csdn.net/u012162613/article/details/48323777
https://www.letiantian.me/2014-10-12-three-models-of-naive-nayes/