机器学习流程(三)-特征工程
目录
一、数据预处理
1.异常值处理
2.缺失值处理
3.不均衡样本-数据采样
1.欠采样(undersampling)
2.过采样(oversampling)
3.阈值移动
4.基于聚类的过采样方法
4.时间类型数据处理
5.文本类型数据处理
6.数据有偏分布处理
1.Box-Cox
2.使倾斜分布对称
3.非线性关系转换成线性
二、特征处理
1.标准化、归一化处理
1.标准化
2.区间缩放法
3.归一化
2.连续特征离散化
1.定量特征二值化
2.数据分桶
3.基于聚类分析的方法
4.使用GDBT
3.离散特征连续化
1.定性特征哑编码
2.特征嵌入
4.数据转换
(1)多项式转换
(2)对数变换
总结
三、特征构造
四、特征选择(也属于特征降维)
1.特征选择的定义
2.特征选择的方法
过滤式
包裹式
嵌入式
3.特征选择在python中的实现方法
1)VarianceThreshold
2)SelectKBest
3)RFE
4)SelectFromModel
五、特征降维
1.线性降维
1.主成分分析法(PCA)
2.线性判别分析法(LDA)
3.矩阵分解(SVD)
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程一般包括特征使用、特征获取、特征处理、特征选择和特征监控。
特征工程的处理流程为首先去掉无用特征,接着去除冗余特征,如共线特征,并利用存在的特征、转换特征、内容中的特征以及其他数据源生成新特征,然后对特征进行转换(数值化、类别转换、归一化等),最后对特征进行处理(异常值、最大值、最小值、缺失值等),以符合模型的使用。
一、数据预处理
1.异常值处理
一般采用删除、转换、填充、区别对待等方法进行处理。
- 删除:如果是由输入误差、数据处理误差引起的异常值,或者异常值很小,则可以直接删除
- 转换:数据转换可以消除异常值,如对数据取对数会减轻由极值引起的变化
- 填充:一般采用平均值、中值、预测模型填充等等
- 区别对待:如果存在大量的异常值,则应该在统计模型中区别对待。其中一个方法是将数据分为两个不同的组,异常和非异常的分别归为一组,且两组分别建立模型,最终将两组的输出合并
2.缺失值处理
1.不处理(针对类似 XGBoost 等树模型,有些模型有处理缺失的机制,所以可以不处理);
2.删除(缺失数据太多);
3.插值补全,包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等;
4.分箱,缺失值一个箱;
下面介绍具体方法:
- fillna填充
#分组均值补充
age_group_mean = combined.groupby(['Sex', 'Pclass', 'Title'])['Age'].mean().reset_index()
#使用平均值填充。
combined['Fare'].fillna(combined['Fare'].mean(), inplace=True)
#Embarked:只有两个缺失值,使用众数填充。
combined['Embarked'].fillna(combined['Embarked'].mode(), inplace=True)# 删除重复值
data.drop_duplicates()
# dropna()可以直接删除缺失样本,但是有点不太好
# 填充固定值
train_data.fillna(0, inplace=True) # 填充 0
data.fillna({0:1000, 1:100, 2:0, 4:5}) # 可以使用字典的形式为不用列设定不同的填充值
train_data.fillna(train_data.mean(),inplace=True) # 填充均值
train_data.fillna(train_data.median(),inplace=True) # 填充中位数
train_data.fillna(train_data.mode(),inplace=True) # 填充众数
train_data.fillna(method='pad', inplace=True) # 填充前一条数据的值,但是前一条也不一定有值
train_data.fillna(method='bfill', inplace=True) # 填充后一条数据的值,但是后一条也不一定有值
"""插值法:用插值法拟合出缺失的数据,然后进行填充。"""
for f in features:
train_data[f] = train_data[f].interpolate()
train_data.dropna(inplace=True)
"""填充KNN数据:先利用knn计算临近的k个数据,然后填充他们的均值"""
from fancyimpute import KNN
train_data_x = pd.DataFrame(KNN(k=6).fit_transform(train_data_x), columns=features)
# 还可以填充模型预测的值- SimpleImputer类处理缺失值
3.不均衡样本-数据采样
采集、清洗过数据以后,正负样本是不均衡的,采取措施:负样本过采样、训练多个模型后求平均、调整模型的损失函数样本比例的权重等。
采样的方法有随机采样和分层抽样。但是随机采样会有隐患,因为可能某次随机采样得到的数据很不均匀,更多的是根据特征采用分层抽样。
正负样本不平衡处理办法:
正样本 >> 负样本,且量都挺大 => 采用下采样(downsampling)的方法
正样本 >> 负样本,量不大 => 可以采用以下方法采集更多的数据:
1)上采样(oversampling),比如图像识别中的镜像和旋转
2)修改损失函数(loss function)设置样本权重
不平衡数据集介绍和处理方法
1.欠采样(undersampling)
欠采样(undersampling)法是去除训练集内一些多数样本,使得两类数据量级接近,然后在正常进行学习。
缺点:放弃了很多反例,这会导致平衡后的训练集小于初始训练集。而且如果采样随机丢弃反例,会损失已经收集的信息,往往还会丢失重要信息。
基本的算法如下:
def undersampling(train, desired_apriori):
# Get the indices per target value
idx_0 = train[train.target == 0].index
idx_1 = train[train.target == 1].index
# Get original number of records per target value
nb_0 = len(train.loc[idx_0])
nb_1 = len(train.loc[idx_1])
# Calculate the undersampling rate and resulting number of records with target=0
undersampling_rate = ((1-desired_apriori)*nb_1)/(nb_0*desired_apriori)
undersampled_nb_0 = int(undersampling_rate*nb_0)
print('Rate to undersample records with target=0: {}'.format(undersampling_rate))
print('Number of records with target=0 after undersampling: {}'.format(undersampled_nb_0))
# Randomly select records with target=0 to get at the desired a priori
undersampled_idx = shuffle(idx_0, n_samples=undersampled_nb_0)
# Construct list with remaining indices
idx_list = list(undersampled_idx) + list(idx_1)
# Return undersample data frame
train = train.loc[idx_list].reset_index(drop=True)
return train
因为对应具体的project,所以里面欠采样的为反例,如果要使用的话需要做一些改动。
欠采样改进方法1
但是我们可以更改抽样方法来改进欠抽样方法,比如把多数样本分成核心样本和非核心样本,非核心样本为对预测目标较低概率达成的样本,可以考虑从非核心样本中删除而非随机欠抽样,这样保证了需要机器学习判断的核心样本数据不会丢失。
举例来说依然是预测用户注册这个目标,我们可以将跳出率为100%的用户名下的所有会话都可以划分为非核心样本,因为跳出用户包含的信息量非常少(其他行为特征为空),将此部分用户样本排除可以最大可能的保留更多原始数据信息。
欠采样改进方法2
欠采样法若随机丢弃反例,可能会丢失一些重要信息。为此,周志华实验室提出了欠采样的算法EasyEnsemble:利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息。其实这个方法可以再基本欠采样方法上进行些许改动即可:
def easyensemble(df, desired_apriori, n_subsets=10):
train_resample = []
for _ in range(n_subsets):
sel_train = undersampling(df, desired_apriori)
train_resample.append(sel_train)
return train_resample
PS: 对于类别不平衡的时候采用CV进行交叉验证时,由于分类问题在目标分布上表现出很大的不平衡性。如果用sklearn库中的函数进行交叉验证的话,建议采用如StratifiedKFold 和 StratifiedShuffleSplit中实现的分层抽样方法,确保相对的类别概率在每个训练和验证折叠中大致保留。
2.过采样(oversampling)
过采样(oversampling)是对训练集内的少数样本进行扩充,既增加少数样本使得两类数据数目接近,然后再进行学习。
简单粗暴的方法是复制少数样本,缺点是虽然引入了额外的训练数据,但没有给少数类样本增加任何新的信息,非常容易造成过拟合。
过采样改进方法1
通过抽样方法在少数类样本中加入白噪声(比如高斯噪声)变成新样本一定程度上可以缓解这个问题。如年龄,原年龄=新年龄+random(0,1)
过采样代表算法:SMOTE 算法
SMOTE[Chawla et a., 2002]是通过对少数样本进行插值来获取新样本的。比如对于每个少数类样本a,从 a最邻近的样本中选取 样本b,然后在对 ab 中随机选择一点作为新样本。
3.阈值移动
这类方法的中心思想不是对样本集合做再平衡设置,而是对算法的决策过程进行改进。
举个简单的例子,通常我们对预测结果进行分类时,当预测 y( y 代表正类可能性) 值>0.5时,判定预测结果为正,反之为负。规定决策规则

不难发现,只有当样本中正反比例为1:1时,阈值设置为0.5才是合理的。如果样本不平衡决策规则需要进行变更,另 m+ 代表正例个数, m- 代表负例个数,改进决策规则:
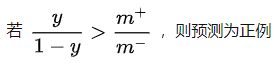
因为训练集是总体样本的无偏采样,观测几率就代表真实几率,决策规则中 ![]() 代表样本中正例的观测几率,只要分类器中的预测几率高于观测几率达到改进判定结果的目标。
代表样本中正例的观测几率,只要分类器中的预测几率高于观测几率达到改进判定结果的目标。
4.基于聚类的过采样方法
4.时间类型数据处理
1.连续的时间差值法
即计算出所有样本的时间到某一个未来时间之间的数值差距,这样这个差距是UTC的时间差,从而将时间特征转化为连续值。
2.将一个时间转化为离散特征
根据时间所在的年,月,日,星期几,小时数,将一个时间特征转化为若干个离散特征,这种方法在分析具有明显时间趋势的问题比较好用。
5.文本类型数据处理
参看文本预处理
(1)词袋
直接把文本数据丢给模型,模型是无法解释的,因此需要把文本型的数据用数值表示。去掉停用词,标点符号,留下表达实际含义的词组成列表,在词库中映射稀疏向量。
from sklearn.feature_extraction.text import CountVectorizer(2)把词袋中的词扩充到 n-gram
它的思想是:在整个语言环境中,句子T的出现概率是由组成T的N个词组成的。
(3)使用TF-IDF方法 参看TF-IDF算法
from sklearn.feature_extraction.text import TfidfVectorizer(4)word2vec将词转化为词向量(NLP)
6.数据有偏分布处理
1.Box-Cox
当连续型变量不满足正态分布时,可以使用Box-Cox变换。这一变换可以使线性回归模型在满足线性、正态性、独立性及方差齐性的同时,又不丢失信息。
Box-Cox变换的一般形式为:


boxcox变换的应用必须先分析输入X的分布是哪一种偏斜: X分布左偏,则应该应用lambda = 0的变换; X分布右偏,则应该应用lambda > 1的变换.
Box-Cox变换实现两项工作:做变换、确定lambda的值(也就是boxcox()函数返回的前两个参数)
boxcox是将数据分布正态化,使其更加符合后续对数据分布的假设。
boxcox可以降低skewness值,达到接近正态分布的目标。
注意:在使用Box-Cox变换之前,需要对数据做归一化处理
具体实现:
from scipy.stats import boxcox
boxcox_transformed_data = boxcox(original_data)2.使倾斜分布对称
对于向右倾斜的分布,对变量取平方根或立方根或对数
对于向左倾斜的分布,对变量取平方或立方或指数
(说明:向右倾斜的分布,是右边的尾部偏长)
(1)对数变换:对变量取对数,可以更改变量的分布形状。其通常应用于向右倾斜的分布,缺点是不能用于含有零或负值的变量
(2)取平方根或立方根:变量的平方根和立方根对其分布有波形的影响。取平方根可用于包括零的正值,取立方根可用于取值中有负值(包括零)的情况
3.非线性关系转换成线性
将非线性变量的关系转换为线性关系更容易理解,其中对数变换是最常用的一种方式
二、特征处理
1.标准化、归一化处理
1.标准化
零 - 均值标准化(Z - score)
from sklearn.preprocessing import StandardScaler
公式:x =(x - )/
具体的方法是求出样本特征x的均值mean和标准差std,然后用(x-mean)/std来代替原特征。这样特征就变成了均值为0,方差为1。该方法是当前用的最多的数据标准化方法。
适用于:如果数据的分布本身就服从正态分布,就可以用这个方法。
2.区间缩放法
区间缩放法的思路有多种,常见的一种是利用两个最值(最大、最小值)进行缩放。
最小 - 最大标准化(min - max)
from sklearn.preprocessing import MinMaxScaler
公式:x = (x-min)/(max-min)
最小 - 最大标准化也成为离差标准化,是对原始数据的线性变换,将数值映射到[0,1]之间。
具体的方法是求出样本特征x的最大值max和最小值min,然后用(x-min)/(max-min)来代替原特征。如果我们希望将数据映射到任意一个区间[a,b],而不是[0,1],那么也很简单。用(x-min)(b-a)/(max-min)+a来代替原特征即可。
缺陷:当有新数据加入时,可能导致max和min的变化,需要重新定义。
注意:这种方法对于outlier非常敏感,因为outlier影响了max或min值,所以这种方法只适用于数据在一个范围内分布的情况
3.归一化
归一化是将样本的特征值转换到同一量纲下,把数据映射到[0, 1]或者[a, b]区间内,由于其仅由变量的极值决定,因此区间缩放法是归一化的一种。
from sklearn.preprocessing import Normalizer
归一区间会改变数据的原始距离、分布和信息,但标准化一般不会。
归一化和标准化的使用场景:
- 如果对输出结果范围有要求,则用归一化。
- 如果数据较为稳定,不存在极端的最大值或最小值,则用归一化。
- 如果数据存在异常值和较多噪声,则用标准化,这样可以通过中心化间接避免异常值和极端值的影响。
- 支持向量机(SVM)、K近邻(KNN)、主成分分析(PCA)等模型都必须进行归一化或标准化操作。
- 决策树模型一般不需要归一化处理
2.连续特征离散化
离散化是指将一个数值型的特征分成多个小的区间。然后将每个区间作为一个特征(one-hot)进行表示。
1.定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。
from sklearn.preprocessing import Binarizer
2.数据分桶
连续值经常离散化或者分离成“箱子”进行分析, 为什么要做数据分桶呢?
-
离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
-
离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
-
LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
-
离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
-
特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
数据分桶的方式:
- 等频分桶;
等频划分:将某个特征的数据按照从小到大的顺序排列好,假如要分成4份,那么从小到大,总数的25%组成第一份,总数的25%-50%组成第二份,总数的50%-75%组成第三份,剩下的组成第四份。这样可以保证每个划分区间内样本的数量基本一致。但是容易造成数值相近的样本被分到不同区间的情况。
- 等距分桶;
等距划分:找出该特征的最大值和最小值,然后平均分成n份。这种方法潜在的问题在于:如果数据在某个区间内很集中,那么会导致划分的结果中存在某个区间中样本数量很多,而某些区间中样本数量很少的情况。比如说,一件衣服的价格在50-1000元之间,但是大部分衣服的价格在100-300之间,这时候如果进行等距划分,就会造成不同区间中样本数量不一致的情形。
- Best-KS 分桶(类似利用基尼指数进行二分类);
- 卡方分桶;
数据分箱参考:数据分箱之pd.cut()
3.基于聚类分析的方法
4.使用GDBT
3.离散特征连续化
1.定性特征哑编码
哑变量(Dummy Variable),也被称为虚拟变量,通常是人为虚设的变量,取值为0或1,用来反映某个变量的不同属性。将类别变量转换为哑变量的过程就是哑编码。
引入哑变量的目的是把原本不能定量处理的变量进行量化,从而评估定性因素对因变量的影响。
from sklearn.preprocessing import OneHotEncoder
方法1: OneHotEncoder
方法2: pandas.get_dummies (原理同上,都是独热)
参考:pandas.get_dummies 的用法
方法3: 先聚类,再独热
关于高势集特征model,也就是类别中取值个数非常多的, 一般可以使用聚类的方式,然后独热
举例:
from sklearn.cluster import KMeans
ac = KMeans(n_clusters=3)
ac.fit(model_price_data)
model_fea = ac.predict(model_price_data)
plt.scatter(model_price_data[:,0], model_price_data[:,1], c=model_fea)
cat_data_hot['model_fea'] = model_fea
cat_data_hot = pd.get_dummies(cat_data_hot, columns=['model_fea'])2.特征嵌入
4.数据转换
常见的数据转换有基于多项式的、指数函数的和对数函数的转换方式。
(1)多项式转换
from sklearn.preprocessing import PolynomialFeatures
相当于特征构造。比如特征数有2个,a、b,需要转换成阶数degree=2的数据,则经过转换后的特征为:a^0*b^0、a^1*b^0、a^0*b^1、a^2*b^0、a^1*b^1、a^0*b^2
(2)对数变换
基于单变元函数的数据转换可以使用一个统一的方法完成。
from sklearn.preprocessing import FunctionTransformer
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer
# 自定义转换函数为对数函数的数据转换
# 第一个参数是单变元函数
FunctionTransformer(log1p, validate=False).fit_transform(iris.data)总结
对于特征处理中使用的sklearn类进行总结:
| 类 | 功能 | 说明 |
| StandardScaler | 无量纲化 | 标准化,基于特征矩阵的列,将特征值转换为服从标准正态分布 |
| MinMaxScaler | 无量纲化 | 区间缩放,基于最大值或最小值,将特征值转换到[0,1]区间内 |
| Normalizer | 归一化 | 基于特征矩阵的行,将样本向量转换为单位向量 |
| Binarizer | 定量特征二值化 | 基于给定阈值,将定量特征按阈值划分 |
| OneHotEncoder | 定性特征哑编码 |
将定性特征编码为定量特征 |
| Imputer | 缺失值处理 | 计算缺失值,缺失值可填充为均值等 |
| PolynomialFeatures | 多项式数据转换 | 多项式数据转换 |
| FunctionTransformer | 自定义单元数据转换 | 使用单变元函数转换数据 |
| LabelEncoder | 标签编码 | |
三、特征构造
在特征构造的时候,需要借助一些背景知识,遵循的一般原则就是需要发挥想象力,尽可能多的创造特征,不用先考虑哪些特征可能好,可能不好,先弥补这个广度。特征构造的时候需要考虑数值特征,类别特征,时间特征。
-
对于数值特征,一般会尝试一些它们之间的加减组合(当然不要乱来,根据特征表达的含义)或者提取一些统计特征
-
对于类别特征,我们一般会尝试之间的交叉组合,embedding也是一种思路
-
对于时间特征,这一块又可以作为一个大专题来学习,在时间序列的预测中这一块非常重要,也会非常复杂,需要就尽可能多的挖掘时间信息,会有不同的方式技巧。
四、特征选择(也属于特征降维)
1.特征选择的定义
特征选择是常用的特征降维手段。比较简单粗暴,即映射函数直接将不重要的特征删除,不过这样会造成特征信息的丢失,不利于模型精度。
| 特征选择的目标 | 说明 |
| 特征是否发散 | 如果一个特征不发散,如方差接近于0,就说明样本在这个特征上基本没有差异,这个特征对于样本的区分没有作用(选择方差大的) |
| 特征与目标的相关性 | 与目标相关性高的特征应当优先选择 |
2.特征选择的方法
-
过滤法(Filter):按照发散性或者相关性对各个特征进行评分,通过设定阈值或者待选择阈值的个数来选择特征
-
包装法(Wrapper):根据目标函数(通常是预测效果评分)每次选择若干特征,或者排除若干特征
-
嵌入法(Embedded):使用机器学习的某些算法和模型进行训练,得到各个特征的权值系数,并根据系数从大到小选择特征。这一方法类似过滤法,区别在于它通过训练来确定特征的优势。
参考:零基础入门数据挖掘系列之「特征工程」-天池技术圈-天池技术讨论区
过滤式
主要思想: 对每一维特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该特征的重要性,然后依据权重排序。先进行特征选择,然后去训练学习器,所以特征选择的过程与学习器无关。相当于先对特征进行过滤操作,然后用特征子集来训练分类器。
主要方法:
-
移除低方差的特征;
-
相关系数排序,分别计算每个特征与输出值之间的相关系数,设定一个阈值,选择相关系数大于阈值的部分特征;
-
利用假设检验得到特征与输出值之间的相关性,方法有比如卡方检验、t检验、F检验等。
-
互信息,利用互信息从信息熵的角度分析相关性。
tricks:
对于数值型特征,方差很小的特征可以不要,因为太小没有什么区分度,提供不了太多的信息,对于分类特征,也是同理,取值个数高度偏斜的那种可以先去掉。
根据与目标的相关性等选出比较相关的特征(当然有时候根据字段含义也可以选)
卡方检验一般是检查离散变量与离散变量的相关性,当然离散变量的相关性信息增益和信息增益比也是不错的选择(可以通过决策树模型来评估来看),person系数一般是查看连续变量与连续变量的线性相关关系。
pearson相关系数,皮尔森相关系数是一种最简单的,比较常用的方式。能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。
Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的pearsonr方法能够同时计算相关系数和p-value, 当然pandas的corr也可以计算。
直接根据pearson系数画出图像:
corr = select_data.corr('pearson') # .corr('spearman')
plt.figure(figsize=(25, 15))
corr['price'].sort_values(ascending=False)[1:].plot(kind='bar')
plt.tight_layout()结果如下:

包裹式
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。
主要思想:包裹式从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。包裹式特征选择直接针对给定学习器进行优化。
主要方法:递归特征消除算法, 基于机器学习模型的特征排序
优缺点:
优点:从最终学习器的性能来看,包裹式比过滤式更好;
缺点:由于特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择要大得多。
嵌入式
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别。而嵌入式特征选择在学习器 训练过程中自动地进行特征选择。嵌入式选择最常用的是L1正则化与L2正则化。在对线性回归模型加入两种正则化方法后,他们分别变成了岭回归与Lasso回归。
主要思想:在模型既定的情况下学习出对提高模型准确性最好的特征。也就是在确定模型的过程中,挑选出那些对模型的训练有重要意义的特征。
主要方法:简单易学的机器学习算法–岭回归(Ridge Regression),就是线性回归过程加入了L2正则项。
L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择
L2正则化在拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参 数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性 回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移 得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』
3.特征选择在python中的实现方法
| 类 | 所属方法 | 具体方法 |
| VarianceThreshold | Filter | 方差选择法 |
| SelectKBest | Filter | 将可选相关系数、卡方检验或最大信息系数作为得分计算的方法 |
| RFE | Wrapper | 递归消除特征法 |
| SelectFromModel | Embedded | 基于模型的特征选择法 |
1)VarianceThreshold
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import load_iris
iris = load_iris()
# 方差选择法,返回值为特征选择后的数据
# 参数threshold为方差的阈值
VarianceThreshold(threshold=3).fit_transform(iris.data)2)SelectKBest
1.相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值,然后根据阈值筛选特征。
用feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下:
import numpy as np
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
from sklearn.datasets import load_iris
iris = load_iris()
# 选择K个最好的特征,返回选择特征后的数据
# 第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
# 参数k为选择的特征个数
SelectKBest(
lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T,
k=2).fit_transform(iris.data, iris.target)2.卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量: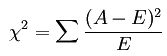
这个统计量的含义简而言之就是自变量对因变量的相关性。
用feature_selection库的SelectKBest类结合卡方检验来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# 选择K个最好的特征,返回选择特征后的数据
SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)3.最大信息系数法
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下: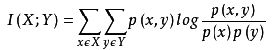
为了处理定量数据,最大信息系数法被提出,使用feature_selection库的SelectKBest类结合最大信息系数法来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from minepy import MINE
# 由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
# 选择K个最好的特征,返回特征选择后的数据
SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)3)RFE
和filter method 相比, wrapper method 考虑到了feature 之间的相关性, 通过考虑feature的组合对于model性能的影响. 比较不同组合之间的差异,选取性能最好的组合. 比如recursive feature selection。
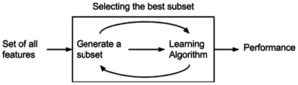
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# 递归特征消除法,返回特征选择后的数据
# 参数estimator为基模型
# 参数n_features_to_select为选择的特征个数
RFE(estimator=LogisticRegression(multi_class='auto',
solver='lbfgs',
max_iter=500), n_features_to_select=2).fit_transform(iris.data, iris.target)4)SelectFromModel
结合前面二者的优点, 在模型建立的时候,同时计算模型的准确率. 最常见的embedded method 是 regularization methods(简单来说就是通过增加penalization coefficients来约束模型的复杂度)。

- 基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
# 带L1惩罚项的逻辑回归作为基模型的特征选择
SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)L1惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,所以没选到的特征不代表不重要。故,可结合L2惩罚项来优化。具体操作为:若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值,故需要构建一个新的逻辑回归模型:
from sklearn.linear_model import LogisticRegression
class LR(LogisticRegression):
def __init__(self, threshold=0.01, dual=False, tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1):
#权值相近的阈值
self.threshold = threshold
LogisticRegression.__init__(self, penalty='l1', dual=dual, tol=tol, C=C,
fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight=class_weight,
random_state=random_state, solver=solver, max_iter=max_iter,
multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
#使用同样的参数创建L2逻辑回归
self.l2 = LogisticRegression(penalty='l2', dual=dual, tol=tol, C=C, fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight = class_weight, random_state=random_state, solver=solver, max_iter=max_iter, multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
def fit(self, X, y, sample_weight=None):
#训练L1逻辑回归
super(LR, self).fit(X, y, sample_weight=sample_weight)
self.coef_old_ = self.coef_.copy()
#训练L2逻辑回归
self.l2.fit(X, y, sample_weight=sample_weight)
cntOfRow, cntOfCol = self.coef_.shape
#权值系数矩阵的行数对应目标值的种类数目
for i in range(cntOfRow):
for j in range(cntOfCol):
coef = self.coef_[i][j]
#L1逻辑回归的权值系数不为0
if coef != 0:
idx = [j]
#对应在L2逻辑回归中的权值系数
coef1 = self.l2.coef_[i][j]
for k in range(cntOfCol):
coef2 = self.l2.coef_[i][k]
#在L2逻辑回归中,权值系数之差小于设定的阈值,且在L1中对应的权值为0
if abs(coef1-coef2) < self.threshold and j != k and self.coef_[i][k] == 0:
idx.append(k)
#计算这一类特征的权值系数均值
mean = coef / len(idx)
self.coef_[i][idx] = mean
return self使用feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的逻辑回归模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
#带L1和L2惩罚项的逻辑回归作为基模型的特征选择
#参数threshold为权值系数之差的阈值
SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(iris.data, iris.target)-
基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
#GBDT作为基模型的特征选择
SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)五、特征降维
参考:机器学习 | 特征工程(三)- 特征降维 - eo_will - 博客园
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。降维(dimensionality reduction)是指通过对原有的feature进行重新组合,形成新的feature,选取其中的principal components。
降维作用:
1)降低时间复杂度和空间复杂度
2)节省了提取不必要特征的开销
3)去掉数据集中夹杂的噪
4)较简单的模型在小数据集上有更强的鲁棒性
5)当数据能有较少的特征进行解释,我们可以更好 的解释数据,使得我们可以提取知识。
6)实现数据可视化
数据降维方法主要分为线性方法和非线性方法,其中前者主要有PCA、LDA、矩阵分解SVD等多种方式,后者则包括ISOMAP,t-SNE以及UMAP等。
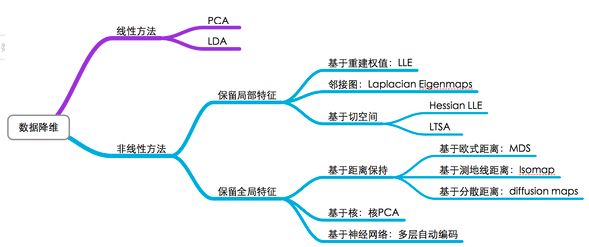
本文主要介绍常用的线性降维方法:主成分分析法(PCA)和线性判别分析(LDA)。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
1.线性降维
1.主成分分析法(PCA)
如果数据特征维度太高,首先计算很麻烦,其次增加了问题的复杂程度,分析起来也不方便。这时候就会想是不是再去掉一些特征就好了呢?但是这个特征也不是凭自己的意愿去掉的,因为盲目减少数据的特征会损失掉数据包含的关键信息,容易产生错误的结论,对分析不利。
所以想找到一个合理的方式,既可以减少需要分析的指标,而且尽可能多的保持原来数据的信息,PCA就是这个合理的方式之一。 但要注意一点, 特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,而PCA,将已存在的特征压缩,降维完毕后不是原来特征的任何一个,也就是PCA降维之后的特征我们根本不知道什么含义了。
使用decomposition库的PCA类选择特征的代码如下:
from sklearn.decomposition import PCA
# 主成分分析法,返回降维后的数据
# 参数n_components为主成分数目
pca = PCA(n_components=10)
X_new = pca.fit_transform(X)
"""查看PCA的一些属性"""
print(X_new.shape) # (200000, 10)
print(pca.explained_variance_) # 属性可以查看降维后的每个特征向量上所带的信息量大小(可解释性方差的大小)
print(pca.explained_variance_ratio_) # 查看降维后的每个新特征的信息量占原始数据总信息量的百分比
print(pca.explained_variance_ratio_.sum()) # 降维后信息保留量2.线性判别分析法(LDA)
使用lda库的LDA类选择特征的代码如下:
from sklearn.lda import LDA
#线性判别分析法,返回降维后的数据
#参数n_components为降维后的维数
LDA(n_components=2).fit_transform(iris.data, iris.target)