- One
- Two
- Three
- Four
初入python01之爬虫小蜘蛛
Contens
-
- 第四周
-
- 1、爬虫的基本流程有:
-
- 1.1、Request(请求)
- 1.2、Response(响应):
- 第五周:
-
- *知识拓展:*
-
- 1、HTML(超文本标记语言)
- 2、XHTML是更纯净更严格的HTML代码
- 第六周:
-
- 1、Xpath:
-
-
-
- 1、Xpath术语
- 2、节点关系
- 3、Xpath语法:
- 4、Xpath轴
- 5、Xpath的用法
- 6、Xpath实例
-
-
- 2、XSLT(扩展样式表语言)
第四周
要学习爬虫,那么就先理解一下爬虫到底是什么。
首先我们作为用户获取网络数据的方式:
方式1:浏览器提交请求—>下载网页代码—>解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
而爬虫要做的便就是方式2,爬虫,正如它的英文名字一般Web Spider(网络蜘蛛),指爬在互联网这张大网上的一只小蜘蛛吧!这只小蜘蛛沿着网络不断的抓取自己想吃的猎物(数据),即不断地向网站发起请求,获取资源后,进行分析并提取有用的数据。
1、爬虫的基本流程有:

(1)、发送请求:通过HTTP库(这个概念不太清楚)向目标站点发起请求,即发送一个Request,然后等待服务器接受并响应。
(去网站上搜索了HTTP的相关知识,虽然看不懂,但是总会用到的,嘿嘿
网站链接为:http://www.runoob.com/http/http-messages.html)
(2)、获取响应内容:如果服务器能正常响应,我们将得到一个Response;即服务器接收客户端的请求,通过解析发送给浏览器网页HTML文件。
(3)、解析内容:
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
这一步相当于浏览器把服务器端的文件获取到本地,再进行解释并且展现出来。(这个东西有点迷糊,现在还接受不了,就暂且复制过来吧。)
(4)、保存数据:
保存方式:可以把数据存为文本,也可以把数据保存到数据库里面或者存为特定的jpg,mp4等格式的文件。相当于我们在浏览网页时,下载了网页上的图片、视频、网页文本等数据。
1.1、Request(请求)
Request:浏览器—>>服务器。
模拟用户使用浏览器向服务器发送搜索信息
浏览器向该网站服务器发送信息的过程,叫做HTTP Request
请求方式:主要类型GET、OST(这个不太理解)
请求URL:URL 全称是统一资源定位符,也就是我们说的网址。比如一张图片,一个音乐文件,一个网页文档等都可以用唯一URL来确定,它包含的信息指出文件的位置以及浏览器应该怎么去处理它。
请求头(Request Headers):请求头包含请求时的头部信息,如User-Agent(指定浏览器的请求头)信息。模拟用户使用浏览器向服务器发送搜索信息
1.2、Response(响应):
Response:服务器—>>浏览器。
当用户发送搜索信息之后,服务亲根据用户所需作出回应,发送相关信息
服务器收到浏览器发送的信息后,能够根据浏览器发送信息的内容,做出相应的处理,然后把消息回传给浏览器(返回一个包含HTTP状态码的信息头用以响应浏览器的要求),这个过程就叫做HTTP Response。
响应状态:多种响应状态。(HTTP状态码主要是为了表示此次HTTP请求的运行状态)
这个是在学习HTML是看见的关于状态码的相关解释:https://www.runoob.com/tags/html-httpmessages.html
例如:200代表成功,301 跳转页面,表示资源(网页等)被永久转移到其他URL(永久重定向),302表示资源(网页等)被临时转移到其他URL(临时重定向),304资源(网页等)没有更新,403表示无权限访问,404 表示找不到页面,502(也有说502) 表示服务器错误,503由于临时的服务器维护或者过载,服务器当前无法处理请求
响应头(Response Headers):比如内容类型,内容长度,服务器信息,设置Cookie等;(这边不了解)
响应体:响应体最主要的部分,包含了请求资源的内容,比如网页 HTML 代码,图片二进制数据等。
Request和Response

import requests #导入requests库,运行前需要进行安装
#模拟成浏览器访问的头,注意 ‘ 单引号 ’ ,内容应该都在单引号里面,否则会报错
#关于具体的模拟方法目前对于网站内容还是有点难理解
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
resp = requests.get('https://www.baidu.com',headers=headers)
print(resp.text) # 打印出网页源代码
print(resp.status_code) # 打印出状态码
运行成功后可以看到打印出来的 html 源代码和 200 状态码了。这就基本上实现了爬虫的Request和Response的过程
注PS:偶然看见到urllib.requests.Requests( )的知识,虽然我只能看出来和这个程序有点关,但是也算一点收获啦。内容见下:
(1)、HTTP头部信息:有众多的头域组成,每个头域=一个域名+冒号(:)+域值
域名是大小写无关的,域值前可以添加任何数量的空白符,头域可以被扩展为多行,在每行开始处只用至少一个空格或制表符。
Request Header:在请求头中可能包含以下内容:
GET代表的是请求方式(常用请求方式为:GET和POST,虽然百度讲了一大段,然而我依旧不知道他讲了啥)
U-ser-Agent头域,里面包含发出请求的用户信息,其中有使用浏览器的型号,版本,和操作系统的信息。这个头域经常用来做反爬虫的措施。
Host头域,Accept请求报头域,Accept-Language,Accept-Encoding,Connection这些头域等于到了再仔细研究吧。
urllib.request.Request( url[ ,date ][,headers] [ ,oringin-req-host ] [ ,unverifiable ] )这是一个urllib的抽象类,用于构造一个http请求对象实例。
url参数必须是一个有效的url字符串,header参数就是发送给网页服务器的请求头信息,也是用字典来创建的请求报头,但是不需要转换,直接赋值即可。
geturl()返回资源所在的url
info( )返回响应头的信息,返回响应状态码
getcode( )返回响应状态码
第五周:
想试着按照网站上的代码爬取一些东西,便在网站上找了一个爬取小说的视频去爬取赶集网,前面的步骤以及得出的结果,是一样的,但是到利用正则表达式的时候却不一样了,如下:
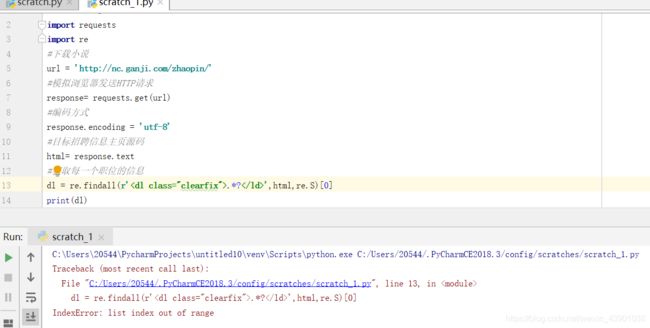 由于之前没有接触过关于正则表达式的东西,同学给我解释错误原因的时候,有点蒙圈了,然后他就建议我去看一下Xpth。
由于之前没有接触过关于正则表达式的东西,同学给我解释错误原因的时候,有点蒙圈了,然后他就建议我去看一下Xpth。
首先,Xpth定义:
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
XPath 标准函数
XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。
在查询的时候遇到了很多的知识点,在此先列出来吧,怕以后忘了。
知识拓展:
1、HTML(超文本标记语言)
(1)、定义:用来描述网业的一种标记语言,即它是一套标记标签。
(2)、标记标签:由尖括号包围的关键词例如:
通常成对出现,例如和,并且这一对标签对中,第一个是开始标签,第二个是结束标签,也说开放标签和闭合标签
(3)、HTML文档:包含HTML标签和纯文本,用来描述网页,但也被称作网页。
(4)、HTML统一资源定位器:URL(即网址的地址),Web浏览器通过URL从web服务器请求页面
所遵守的规则:
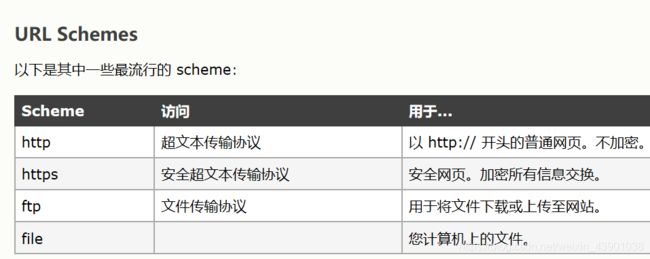
scheme://host.domain:port/path/filename
解释:
scheme - 定义因特网服务的类型。最常见的类型是 http
host - 定义域主机(http 的默认主机是 www)
domain - 定义因特网域名,比如 w3school.com.cn
:port - 定义主机上的端口号(http 的默认端口号是 80)
path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
filename - 定义文档/资源的名称
(5)、HTML小结:
把HTML的所有内容大致看了一遍,感觉它似乎就是网页版的Word,word有界面提供给我们编辑,而HTML是利用代码进行编辑,从而得到我们想要的界面。在此先列出一些主要的知识吧,以免以后又忘记了。
- HTML基础标签,文本格式化,表格、框架、列表、超链接、图像、背景
当你需要输入一篇文章时,可以利用HTML基础标签给文章进行排版;例如首先给主题进行标注,并且居中;如果需要的话,它还可以进行横线标注;之后,对于段落,进行排版,折行、空行、换行等等都是可以的;对于某些重要的知识点还可以进行添加背景色。为了方便编写者检查代码,它还可以隐藏标注而不显示出来。当遇到特殊的文本时(如计算机代码),可以用文本格式化进行特殊编码,达到突出效果;对于某些好的图片,及网站资源参考,可以利用连接的方式进行插入(图片还可以直接插入);
框架、表格、列表分别是指当你写一个界面时,如果需要把他划分成几个模块,便可以利用框架进行划分,而表格所指的和excel中的表格基本相同。并且,当需要对内容进行分点时,便可利用列表进行编码。
大致的基本就这么多了,额,其他的等用到的时候再添加吧。
2、XHTML是更纯净更严格的HTML代码
定义:可扩展的超文本标签语言
他的目标是取代HTML,作为XML应用,通过把 HTML 和 XML 各自的长处加以结合,我们得到了在现在和未来都能派上用场的标记语言 - XHTML,
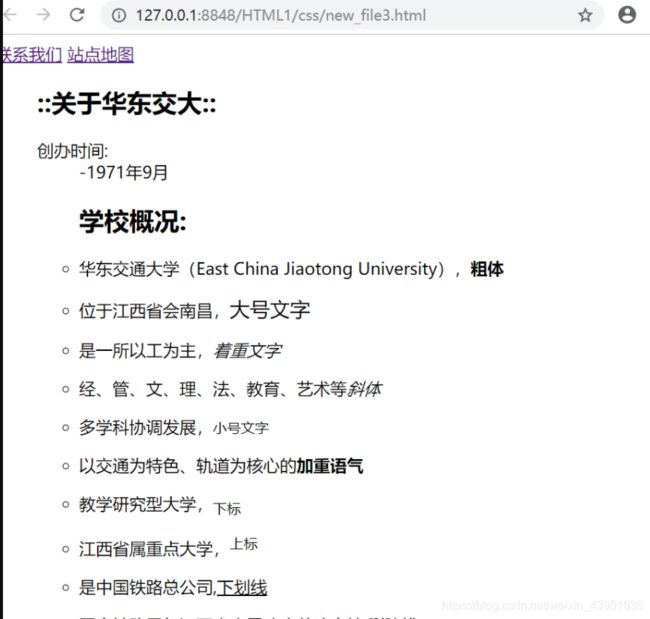
下面是刚刚编写的一段小代码,颜色框架之类的还有不太清楚,所以没有加上去,目前只能下到这了,稍复杂一点比如登入界面等后续慢慢编写吧,今天就先编这个吧。
华东交通大学简介
::关于华东交大::
- 创办时间:
- -1971年9月
学校概况:
华东交通大学(East China Jiaotong University),粗体
位于江西省会南昌,大号文字
是一所以工为主,着重文字
经、管、文、理、法、教育、艺术等斜体
多学科协调发展,小号文字
以交通为特色、轨道为核心的加重语气
教学研究型大学,下标
江西省属重点大学,上标
是中国铁路总公司,下划线
国家铁路局与江西省人民政府共建高校.删除线
编译界面:
第六周:
1、Xpath:
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
1、Xpath术语
(1)、节点:
在Xpath中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(又被称之为根节点)。XML文档又被作为节点树来对待。
**(2)、基本值(**或称原子值,Atomic value)
基本值是无父或无子节点。
(3)、项目(Item):项目是基本值或者节点
2、节点关系
(1)、父:每个元素都有一个父
(2)、子:元素节点可能有零个、一个或多个子
(3)、同胞:拥有相同父的节点
(4)、先辈(Ancestor):某节点的父、父的父,等等
(5)、后代(Descendant):某节点的子、子的子等等
3、Xpath语法:
(1)、选取节点:Xpath:使用路径表达式来选取XML文档中的节点或者节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。

(2)、谓语(Predicates):位于用来查找某个特定的节点或者包含某个指定的值的节点。(谓语被嵌在方括号中)
(3)、选取未知的节点:xpath通配符可用来选取位置的XML元素。

(4)、选取若干路径:通过路径表达式中使用 “|” 运算符,可以选取若干个路径。

4、Xpath轴
(1)、轴可定义相对于当前节点的节点集。

(2)、位置路径表达式:可以是绝对的也可以是相对的。
5、Xpath的用法
(下面为引用百度上的模板,由于对于路径的了解得不够深入,所以就先把方法复制下来,以便日后有料可寻)
1、XPATH使用方法
使用XPATH有如下几种方法定位元素(相比CSS选择器,方法稍微多一点):
a、通过绝对路径定位元素(不推荐!)
WebElement ele = driver.findElement(By.xpath("html/body/div/form/input"));
b、通过相对路径定位元素
WebElement ele = driver.findElement(By.xpath("//input"));
c、使用索引定位元素
WebElement ele = driver.findElement(By.xpath("//input[4]"));
d、使用XPATH及属性值定位元素
WebElement ele = driver.findElement(By.xpath("//input[@id='fuck']"));
//其他方法(看字面意思应该能理解吧)
WebElement ele = driver.findElement(By.xpath("//input[@type='submit'][@name='fuck']"));
WebElement ele = driver.findElement(By.xpath("//input[@type='submit' and @name='fuck']"));
WebElement ele = driver.findElement(By.xpath("//input[@type='submit' or @name='fuck']"));
e、使用XPATH及属性名称定位元素
元素属性类型:@id 、@name、@type、@class、@tittle
//查找所有input标签中含有type属性的元素
WebElement ele = driver.findElement(By.xpath("//input[@type]"));
f、部分属性值匹配
WebElement ele = driver.findElement(By.xpath("//input[start-with(@id,'fuck')]"));//匹配id以fuck开头的元素,id='fuckyou'
WebElement ele = driver.findElement(By.xpath("//input[ends-with(@id,'fuck')]"));//匹配id以fuck结尾的元素,id='youfuck'
WebElement ele = driver.findElement(By.xpath("//input[contains(@id,'fuck')]"));//匹配id中含有fuck的元素,id='youfuckyou'
g、使用任意值来匹配属性及元素
WebElement ele = driver.findElement(By.xpath("//input[@*='fuck']"));//匹配所有input元素中含有属性的值为fuck的元素
元素定位总结
步的语法:
轴名称::节点测试[谓语]
6、Xpath实例
以下内容转自:https://blog.csdn.net/qq_33472765/article/details/80672281
(感觉之前虽然看过一遍了,但似乎依旧记不住,还老是忘记了)
HTML文件:
html = """
"""
将一个HTML文件解析为对象
(1)、首先导入
# element tree: 文档树对象
from lxml.html import etree
(2)、将HTML解析为对象
#方式一:使用较多
obj= etree.HTML("index.html")
#方式二:
obj = etree.parse('index.html')
print(type(obj))
(3)、开始查找元素或数据:
注意:
1、 //ul: 从obj中查找ul,不考虑ul所在的位置。【// 定向查找某一个标签】
2、/li: 找到ul下边的直接子元素li,不包含后代元素。【/查找某一个标签对应的子节点】
list1 = html.xpath('//ul//a') #[ //xx//yy 查找xx标签的yy子孙 ] 显然并没有
list2 = html.xpath('//li/a')
#[ / 查找某一个标签对应的子节点] 定向查找所有 标签下的 标签
3、 [@class=“one”]: 给标签设置属性,用于过滤和筛选
4、xpath()返回的是一个列表:比如
one_li = obj.xpath('//ul/li[@class="one"]')[0]
- 获取 one_li 的文本内容
one_li = obj.xpath('//ul/li[@class="one"]')[0] #shu'xing'guo'lü
print(one_li.xpath('text()')[0]) #打印文本
# 上述写法的合写方式
print(obj.xpath('//ul/li[@class="one"]/text()')[0])
- 获取所有 li 文本的内容:
all_li = obj.xpath('//ul/li/text()')
- 获取所有li的文本内容以及class属性的值:
all_li = obj.xpath('//ul/li')
for li in all_li:
class_value = li.xpath('@class')[0]
text_value = li.xpath('text()')[0]
print(class_value, text_value)
list0 = html.xpath('//a[@href="link4.html"]/../@class')
#[@xxxx]用于指定属性,满足属性的才能被查找到
#第二个@是 取出结果的 @属性,如果没这个'@class',得到的直接是一个父亲标签
#/../和/parent::*/ 用于向父节点回查
- 获取div标签内所有文本
注意 :
//text():获取所有后代元素的文本内
/text():获取直接子元素的文本,不包含后代元素
print(obj.xpath('//div[@id="inner"]//text()'))
- 获取第一个li [1] ([1]:第一个 li )中的文本
print(obj.xpath('//ul/li[1]/text()'))
- 查找类名中包含four的li的文本内容:
print(obj.xpath('//ul/li[contains(@class, "four")]/text()'))
- xpath 获取标签内的 text , href
/li/a/@herf 这样取的应该是herf的内容
/li/a/text() 这样取得是text内容