机器学习概述
1 机器学习概述
1. 什么是机器学习?
机器学习其实是用数据回答问题,可理解为使用数据,回答问题。
使用数据是指训练系统,回答问题是指依据训练的系统做出预测与分类。训练是指使用数据了解用户习惯,并不断完善预测模型,而预测模型则可以对未知的数据进行预测并回答一系列问题。
数据越多,模型则会被训练的越好,预测的结果越准确,所以在机器学习中最重要的就是数据,不管是机器学习还是大数据,所有的内容均与数据息息相关。数据并不局限于数字,还包括文本,图像,视频等。
简单来说,机器学习就是从历史数据中学习规律,然后将规律应用到未来中。
2. 机器学习流程
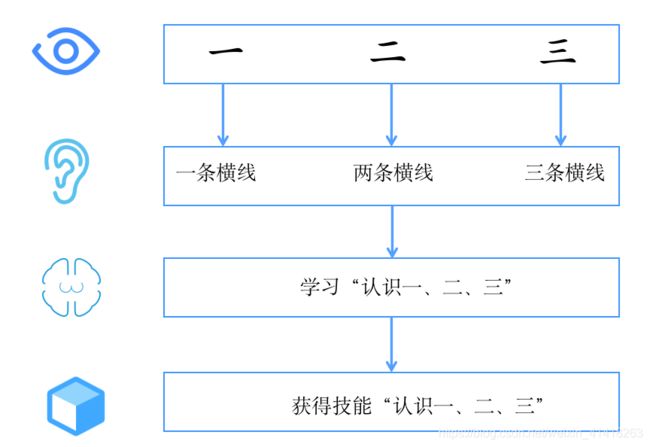
假如我们正在教小朋友识字(一、二、三)。我们首先会拿出3张卡片,然后便让小朋友看卡片,一边说“一条横线的是一、两条横线的是二、三条横线的是三”。不断重复这个过程,小朋友的大脑就在不停的学习。当重复的次数足够多时,小朋友就学会了一个新技能——认识汉字:一、二、三。
我们用上面人类的学习过程来类比机器学习。机器学习跟上面提到的人类学习过程很相似。
- 认字的卡片在机器学习中叫——训练集
- “一条横线,两条横线”这种区分不同汉字的属性叫——特征
- 小朋友不断学习的过程叫——建模
- 学会了识字后总结出来的规律叫——模型
通过训练集,不断识别特征,不断建模,最后形成有效的模型,这个过程就叫“机器学习”
3. 机器学习发展历程
机器学习的起源应该追溯到17世纪,贝叶斯,拉普拉斯关于最小二乘法的推导和马尔科夫链构成了机器学习被广泛使用的工具和基础,从1950年(艾伦.图灵提出建立学习机器)到2000年初(深度学习的广泛应用),机器学习有了很大的进展。从20世纪50年代以来,由于机器学习所应用的时期与领域的不同,可以划分为四个阶段。

3.1. 第一阶段
20世纪50年代中期到60年代中期,这个时期主要研究“有无知识的学习”。这类方法主要是研究系统的执行能力。这个时期,主要通过对机器的环境及其相应性能参数的改变来检测系统所反馈的数据,就好比给系统一个程序,通过改变它们的自由空间作用,系统将会受到程序的影响而改变自身的组织,最后这个系统将会选择一个最优的环境生存。在这个时期最具有代表性的研究就是Samuel的下棋程序。

3.2. 第二阶段
20世纪60年代中期到70年代中期,这个时期主要研究将各个领域的知识植入到系统里,在本阶段的目的是通过机器模拟人类学习的过程。在这一研究阶段,主要是用各种符号来表示机器语言。在这一阶段具有代表性的工作有Hayes-Roth和Winson的对结构学习系统方法。

3.3. 第三阶段
1980 年,在美国的卡内基梅隆(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。此后,机器学习开始得到了大量的应用。1984 年,Simon等20多位人工智能专家共同撰文编写的Machine Learning文集第二卷出版,国际性杂志Machine Learning创刊,更加显示出机器学习突飞猛进的发展趋势。这一阶段代表性的工作有Mostow的指导式学习、Lenat的数学概念发现程序、Langley的BACON程序及其改进程序。
3.4. 第四阶段
20世纪80年代中期,是机器学习的最新阶段。这个时期的机器学习具有如下特点:
- 机器学习成为新的学科,融合了各种学习方法,且形式多样的集成学习系统研究正在兴起。
- 机器学习与人工智能各种基础问题的统一性观点正在形成。
- 各种学习方法的应用范围不断扩大,部分应用研究成果已转化为产品。
- 与机器学习有关的学术活动空前活跃。


4. 应用现状
机器学习应用广泛,无论是在军事领域还是民用领域,都有机器学习算法施展的机会,主要包括:
- 数据分析与挖掘
- 模式识别
- 虚拟助手
- 交通预测
- 过滤垃圾邮件和恶意软件

4.1 数据分析与挖掘
“数据挖掘”和"数据分析”通常被相提并论,但无论是数据分析还是数据挖掘,都是帮助人们收集、分析数据,使之成为信息,并做出判断,因此可以将这两项合称为数据分析与挖掘。数据分析与挖掘技术是机器学习算法和数据存取技术的结合,利用机器学习提供的统计分析、知识发现等手段分析海量数据,同时利用数据存取机制实现数据的高效读写。机器学习在数据分析与挖掘领域中拥有无可取代的地位,2012年Hadoop进军机器学习领域就是一个很好的例子。

4.2 模式识别
模式识别的应用领域广泛,包括计算机视觉、医学图像分析、光学文字识别、自然语言处理、语音识别、手写识别、生物特征识别、文件分类、搜索引擎等,而这些领域也正是机器学习大展身手的舞台,因此模式识别与机器学习的关系越来越密切。




4.3 虚拟助手
Siri,Alexa,Google Now都是虚拟助手。顾名思义,当使用语音发出指令后,它 们会协助查找信息。对于回答,虚拟助手会查找信息,回忆我们的相关查询,或向其他资源(如电话应用程序)发送命令以收集信息。我们甚至可以指导助手执行某些任务,例如“设置7点的闹钟”等。

4.4 交通预测
生活中我们经常使用GPS导航服务,机器学习有助于根据估计找到拥挤的区域。当前高德地图,腾讯地图等都有助于找到拥挤的路段,规划最优的路线。
4.5 过滤垃圾邮件与恶意软件
电子邮件客户端使用了许多垃圾邮件过滤方法。为了确保这些垃圾邮件过滤器能够不断更新 ,它们使用了机器学习技术。由机器学习驱动的系统安全程序,可以轻松检测到2%~10%变异的新恶意软件,并提供针对它们的保护。
5. 机器学习实操步骤
机器学习包括七个步骤:
- 收集数据
- 数据准备
- 选择模型
- 训练模型
- 模型评估
- 参数调整
- 预测

举例说明
首先要求创建一个系统回答饮料是啤酒还是葡萄酒,而这个问答系统被称为模型,而这个系统需要通过训练模型创建,训练模型的目标是创建一个在大多数情况下会正确回答我们提出问题的模型,但是训练模型就需要通过数据训练模型,所以:
- 收集数据:收集葡萄酒与啤酒的数据,颜色、酒精含量、价格。
- 数据准备:在实际情况中,我们收集到的数据会有很多问题,所以会涉及到数据清洗等工作。当数据本身没有什么问题后,我们将数据分成3个部分:训练集(60%)、验证集(20%)、测试集(20%),用于后面的验证和评估工作。
- 选择模型:研究人员和数据科学家多年来创造了许多模型。有些非常适合图像数据,有些非常适合于序列(如文本或音乐),有些用于数字数据,有些用于基于文本的数据。在我们的例子中,由于我们只有2个特征,颜色和酒精度,我们可以使用一个小的线性模型,这是一个相当简单的模型。
- 训练模型:在训练模型阶段,使用数据逐步提高问答系统的准确度,类似于一个3岁小孩子不认识“一,二,三”,通过不断的看,写,练,认识并学会了“一,二,三”的过程,同时不断进步,可以认识到十。
- 模型评估:使用测试集评估模型的准确度,代表着问答系统对未来所有位置数据判断的准确率。
- 参数调整:当我们进行训练时,我们隐含地假设了一些参数,我们可以通过认为的调整这些参数让模型表现的更出色。
- 预测:我们上面的6个步骤都是为了这一步来服务的。这也是机器学习的价值。这个时候,当我们买来一瓶新的酒,只要告诉机器他的颜色和酒精度,他就会告诉你,这时啤酒还是红酒了。
6. 小故事-“机器学习”名字由来
1953年,阿瑟.萨缪尔(Arthur Samuel,1901-1990)在IBM公司研制出一个西洋跳棋程序,这个程序具有自我学习能力,可通过大量棋局的分析逐渐辨识出当前棋局是“好棋”还是“坏棋”,不断提高弈棋水平,并很快便打败了萨缪尔自己。1956年,萨缪尔应约翰.麦卡锡(“人工智能之父”)之邀,在标志着人工智能学科诞生的达特茅斯会议上介绍了西洋跳棋程序,提出了“机器学习”这个词,并将此定义为“不显式编程地赋予计算机能力的研究领域”,1961年,爱德华.费根鲍姆(“知识工程之父”)邀请萨缪尔提供一个跳棋程序中最好的对弈实例,于是萨缪尔借机向康涅狄格州的跳棋冠军,当时全美排名第四的棋手发起挑战,并大获全胜。
